@hadoopMan
2017-03-04T14:28:59.000000Z
字数 5988
阅读 2346
flume详解
flume
想学习spark,hadoop,kafka等大数据框架,请加群459898801,满了之后请加2群224209501。后续文章会陆续公开
本节内容:
针对实时数据抽取框架Flume,掌握如下几点内容:
1) Flume 功能、Agent概念及Agent三个组成部分和常见组件功能
2) 完成课程中的所有Demo案例
3) 理解Flume如何在企业项目中的使用及【实时抽取监控目录数据】案例编写与理解
4) 针对HDFS Sink中几点注意,进行测试,整理记录
1,flume的相关概念
1.1 flume的角色
flume只有一个角色agent,agent里都有三部分构成:source、channel和sink。就相当于source接收数据,通过channel传输数据,sink把数据写到下一端。这就完了,就这么简单。其中source有很多种可以选择,channel有很多种可以选择,sink也同样有多种可以选择,并且都支持自定义。同时,agent还支持选择器,就是一个source支持多个channel和多个sink,这样就完成了数据的分发。
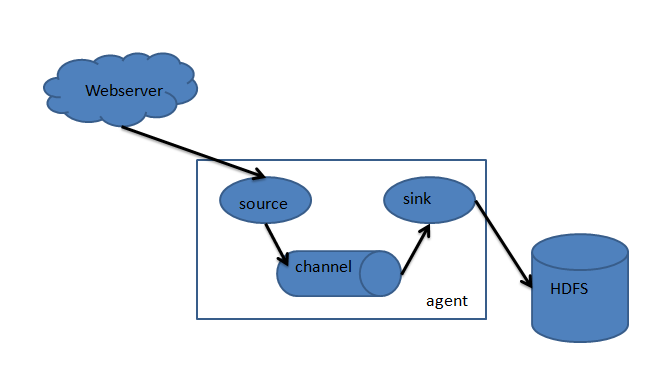
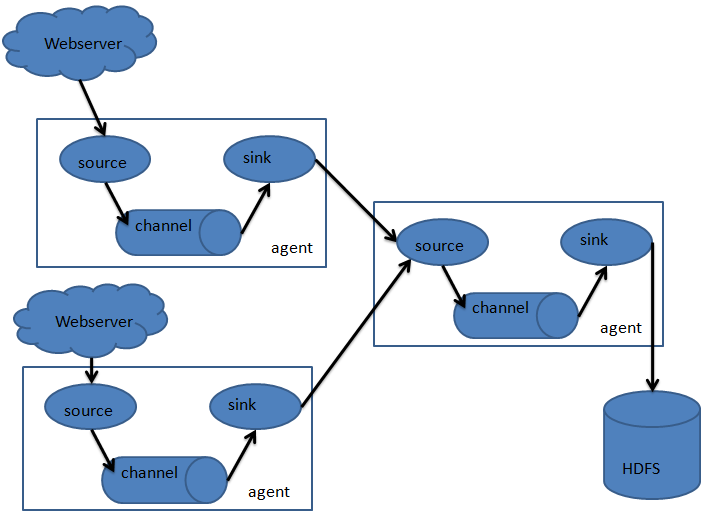
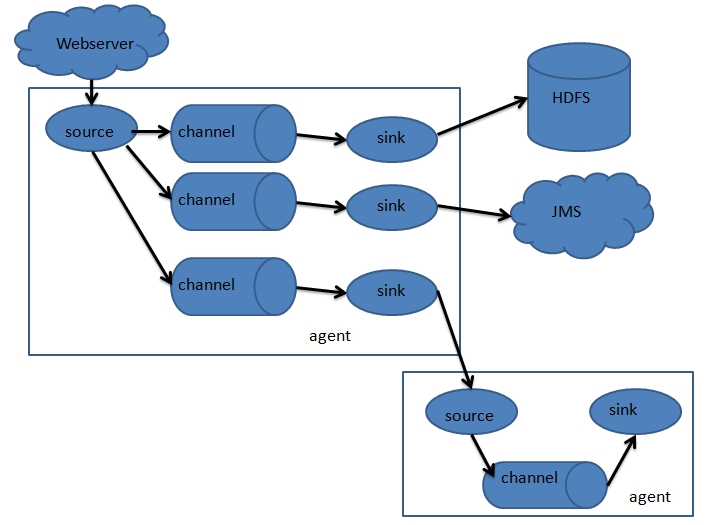
1.2 flume的event
Event是flume数据传输的基本单元
flume以时间的形式将数据从源头传输到目的地
Event由可选的header和载有数据的一个byte array构成:
1,载有数据对flume是不透明的
2,header是容纳了key-value字符串对的无序集合,key在集合内是唯一的。

2,flume的相关配置
2.1,flume下载
flume-ng-1.5.0-cdh5.3.6.tar.gz
2.2,添加配置
造flume的配置文件中添加java路径:
export JAVA_HOME=/opt/modules/jdk1.7.0_67
2.3,测试是否配置成功
2.3.1 编写一个agent
# The configuration file needs to define the sources,# the channels and the sinks.## define agenta1.sources = s1a1.channels = c1a1.sinks = k1## define sourcesa1.sources.s1.channels = c1a1.sources.s1.type = netcata1.sources.s1.bind = miaodonghua1.hosta1.sources.s1.port = 5555## define channelsa1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100## define sinksa1.sinks.k1.channel = c1a1.sinks.k1.type = logger
2.3.2 安装telnet
sudo yum install telnet
2.3.3 启动flume
bin/flume-ng agent \--conf conf \--name a1 \--conf-file conf/test.conf \-Dflume.root.logger=INFO,console
参数说明:-c或者--conf后跟配置目录-f或者--conf-file 后跟配置文件-n或者--name指定agent的名称
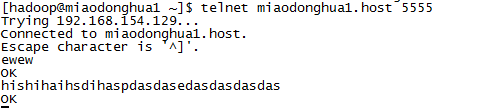
2.3.4 监控5555端口
telnet miaodonghua1.host 5555
2.3.5 收发数据测试

3,flume的agent常见配置
4,flume收集hive的日志信息
4.1 在hive-log4j.properties中设置hive日志目录
hive.log.threshold=ALLhive.root.logger=WARN,DRFAhive.log.dir=/opt/cdh2.3.6/hive-0.13.1-cdh5.3.6/logs/hive.log.file=hive.log
4.2 编写flume的agent
# The configuration file needs to define the sources,# the channels and the sinks.## define agenta2.sources = r2a2.channels = c2a2.sinks = k2## define sourcesa2.sources.r2.type = execa2.sources.r2.command = tail -f /opt/cdh2.3.6/hive-0.13.1-cdh5.3.6/logs/hive.loga2.sources.r2.shell = /bin/bash -c## define channelsa2.channels.c2.type = memorya2.channels.c2.capacity = 1000a2.channels.c2.transactionCapacity = 100## define sinksa2.sinks.k2.type = hdfsa2.sinks.k2.hdfs.path = hdfs://miaodonghua1.host:8020/user/hadoop/flume/hive-logs/a2.sinks.k2.hdfs.filePrefix=cmcca2.sinks.k2.hdfs.minBlockReplicas=1a2.sinks.k2.hdfs.fileType = DataStreama2.sinks.k2.hdfs.writeFormat = Texta2.sinks.k2.hdfs.batchSize = 10a2.sinks.k2.hdfs.rollInterval=0a2.sinks.k2.hdfs.rollSize= 131072a2.sinks.k2.hdfs.rollCount=0tier1.sinks.sink1.hdfs.idleTimeout=6000### bind the sources and sink to the channela2.sources.r2.channels = c2a2.sinks.k2.channel = c2
参数详解:
a2.sinks.k2.hdfs.filePrefix=cmcc:定义文件前缀a2.sinks.k2.hdfs.minBlockReplicas=1:副本数,默认是读取hdfs的副本数a2.sinks.k2.hdfs.fileType = DataStreama2.sinks.k2.hdfs.writeFormat = Texta2.sinks.k2.hdfs.batchSize = 10a2.sinks.k2.hdfs.rollInterval=0 :滚动创建文件的时间间隔,也就是一定时间间隔决定是否创建新的文件,0表时不依据时间来滚动创建文件,秒为单位。a2.sinks.k2.hdfs.rollSize= 131072:配置按文件大小来滚动创建新的文件,0表时不按文件大小来创建,单位是字节。a2.sinks.k2.hdfs.rollCount=0:hdfs有多少条events消息时新建文件,0不基于消息个数
4.3 拷贝flume依赖的hadoop的jar包
cp share/hadoop/hdfs/hadoop-hdfs-2.5.0-cdh5.3.6.jar /opt/cdh2.3.6/flume-1.5.0-cdh5.3.6-bin/lib/cp share/hadoop/common/hadoop-common-2.5.0-cdh5.3.6.jar /opt/cdh2.3.6/flume-1.5.0-cdh5.3.6-bin/lib/cp share/hadoop/tools/lib/hadoop-auth-2.5.0-cdh5.3.6.jar /opt/cdh2.3.6/flume-1.5.0-cdh5.3.6-bin/lib/cp share/hadoop/tools/lib/commons-configuration-1.6.jar /opt/cdh2.3.6/flume-1.5.0-cdh5.3.6-bin/lib/
4.4 运行flume
bin/flume-ng agent --conf conf --name a2 --conf-file conf/flume_tail.conf -Dflume.root.logger=INFO,console
4.5 运行hive
1,启动hive
bin/hive
2,使用shell命令查看日志
tail -f hive.log
3,flume在控制台的输出
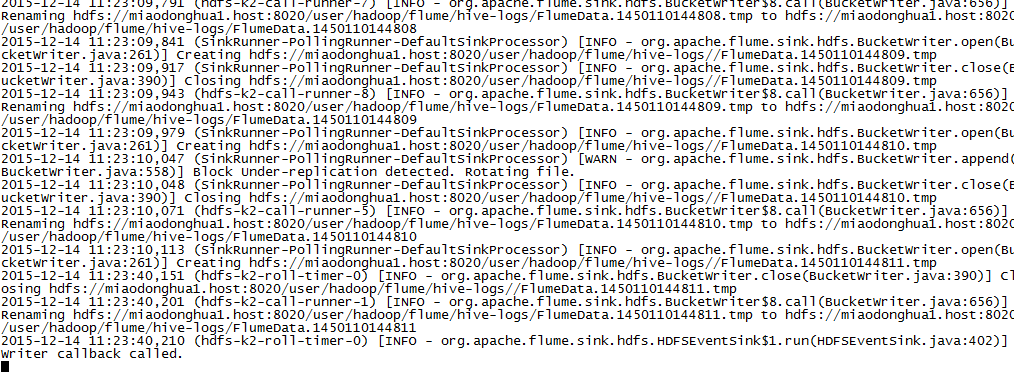
4,在hdfs的存储
4,flume的在企业中的应用
4.1 spooling Directory Source
1,在使用exec来监听数据源虽然实时性较高,但是可靠性较差,当source程序运行异常或者Linux命令中断都会造成数据丢失,在恢复正常运行之前数据的完整性无法得到保障。
2,Spooling Directory Paths通过监听某个目录下的新增文件,并将文件的内容读取出来,实现日志信息的收集。实际生产中会结合log4j来使用。被传输结束的文件会修改后缀名,添加.completed后缀(可修改)。
4.2 监控某热日志文件的目录
·/app/logs/20151212
xx.log.tmp :应用正在向此文件写数据,设定该文件大小为某个值128MB时,会重新生成一个文件
yy.log : 表示一个完整的日志文件,flume可以抽取其中的数据
zz.log.completed:表是flume已经抽取完数据文件
4.3 下面代码
# The configuration file needs to define the sources,# the channels and the sinks.## define agenta3.sources = r3a3.channels = c3a3.sinks = k3## define sourcesa3.sources.r3.type = spooldira3.sources.r3.spoolDir = /opt/cdh5.3.6/flume-1.5.0-cdh5.3.6-bin/spoollogsa3.sources.r3.ignorePattern = ^(.)*\\.tmp$a3.sources.r3.fileSuffix = .delete## define channelsa3.channels.c3.type = memorya3.channels.c3.capacity = 1000a3.channels.c3.transactionCapacity = 100## define sinksa3.sinks.k3.type = hdfsa3.sinks.k3.hdfs.path = hdfs://miaodonghua1.host/user/hadoop/flume/splogs/a3.sinks.k3.hdfs.fileType = DataStreama3.sinks.k3.hdfs.writeFormat = Texta3.sinks.k3.hdfs.batchSize = 10### bind the sources and sink to the channela3.sources.r3.channels = c3a3.sinks.k3.channel = c3
4.4 在flume主目录下执行下面命令:
bin/flume-ng agent --conf conf --name a3 --conf-file conf/flume-app.conf -Dflume.root.logger=INFO,console

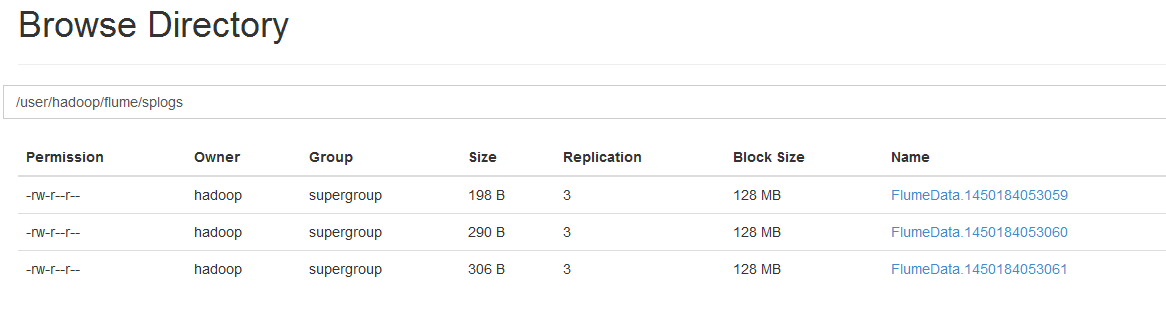
5,完成如下需求
5.1 完成如下需求:
1,监控目录
日志目录,抽取完整的日志文件,写的日志文件不抽取。
2,使用FileChannel
本地文件系统缓冲,比内存安全性高。
3,数据存储HDFS
存储对应hive表的目录或者hdfs目录。
5.2实现代码
# The configuration file needs to define the sources,# the channels and the sinks.## define agenta3.sources = r3a3.channels = c3a3.sinks = k3## define sourcesa3.sources.r3.type = spooldira3.sources.r3.spoolDir = /opt/cdh2.3.6/flume-1.5.0-cdh5.3.6-bin/spoollogsa3.sources.r3.ignorePattern = ^(.)*\\.tmp$a3.sources.r3.fileSuffix = .delete## define channelsa3.channels.c3.type = filea3.channels.c3.checkpointDir = /opt/cdh2.3.6/flume-1.5.0-cdh5.3.6-bin/flume/checkpointa3.channels.c3.dataDirs = /opt/cdh2.3.6/flume-1.5.0-cdh5.3.6-bin/flume/data## define sinksa3.sinks.k3.type = hdfs#a3.sinks.k3.hdfs.path = hdfs://miaodonghua1.host/user/hadoop/flume/splogsa3.sinks.k3.hdfs.fileType = DataStreama3.sinks.k3.hdfs.writeFormat = Texta3.sinks.k3.hdfs.batchSize = 10a3.sinks.k3.hdfs.useLocalTimeStamp=truea3.sinks.k3.hdfs.path = hdfs://miaodonghua1.host/user/hadoop/flume/splogs/%y-%m-%d/a3.sinks.k3.hdfs.filePrefix = events-a3.sinks.k3.hdfs.round = truea3.sinks.k3.hdfs.roundValue = 1a3.sinks.k3.hdfs.roundUnit = hour### bind the sources and sink to the channela3.sources.r3.channels = c3a3.sinks.k3.channel = c3
执行如下命令:
bin/flume-ng agent --conf conf --name a3 --conf-file conf/flume-app.conf -Dflume.root.logger=INFO,console
成功后:

