@hadoopMan
2019-03-25T14:33:48.000000Z
字数 935
阅读 1504
IDEA创建spark工程及源码导入
spark
想学习spark,hadoop,kafka等大数据框架,请加群459898801,满了之后请加2群224209501。后续文章会陆续公开。
1,首先启动
cd /opt/modules/idea-IC-141.178.9/bin/idea.sh
2,导入scala插件

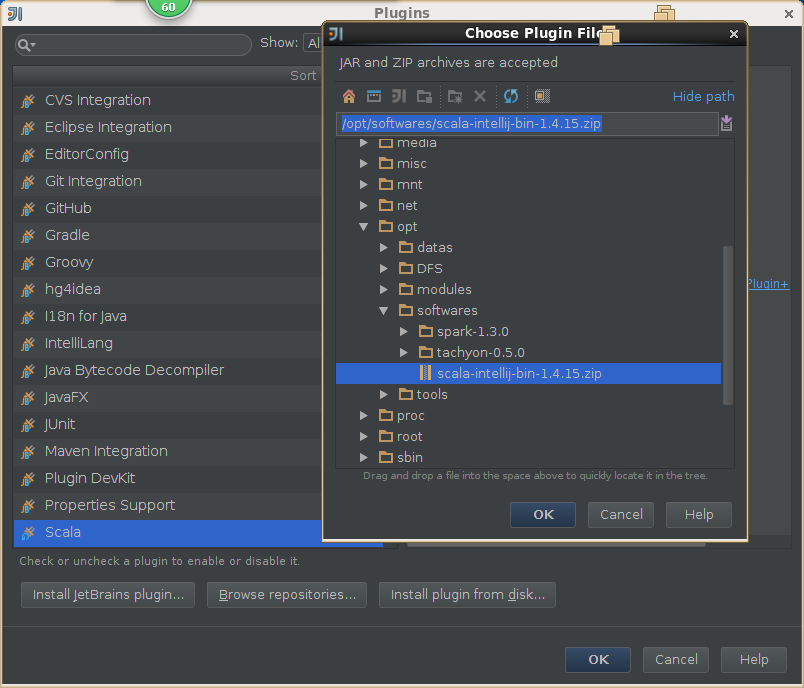
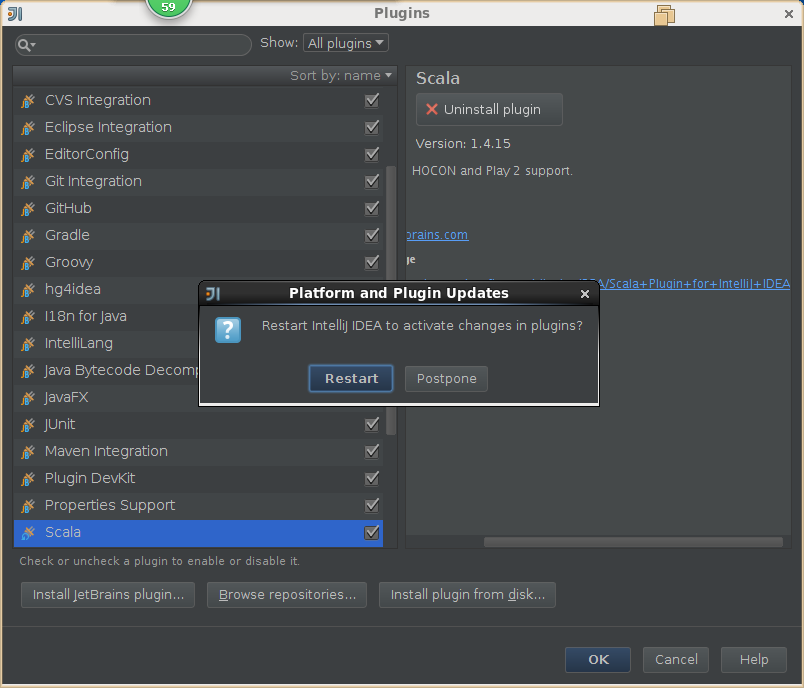
3,导入spark源码

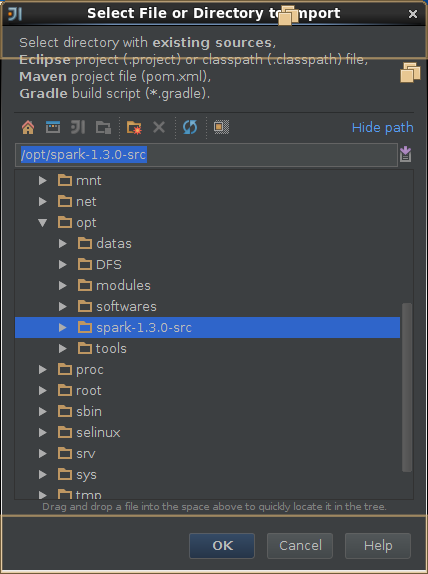
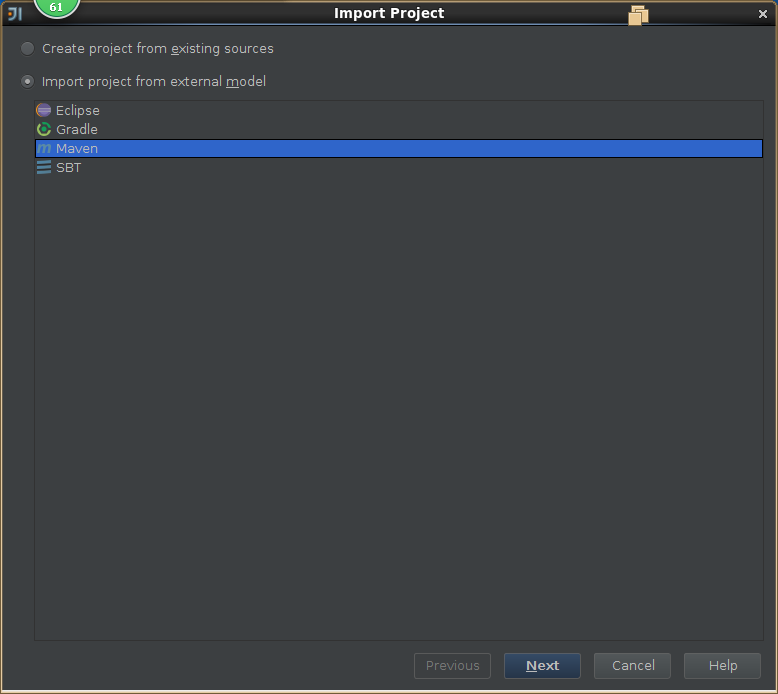
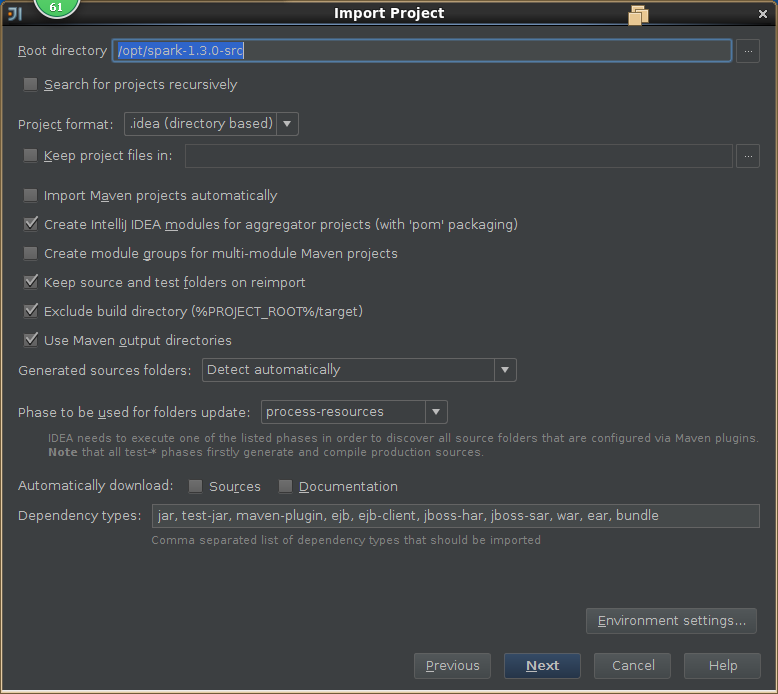
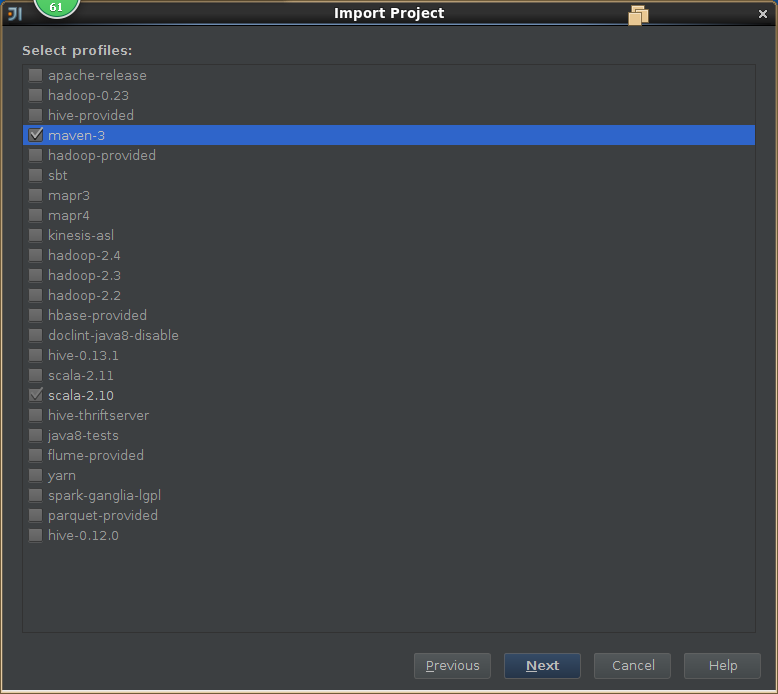
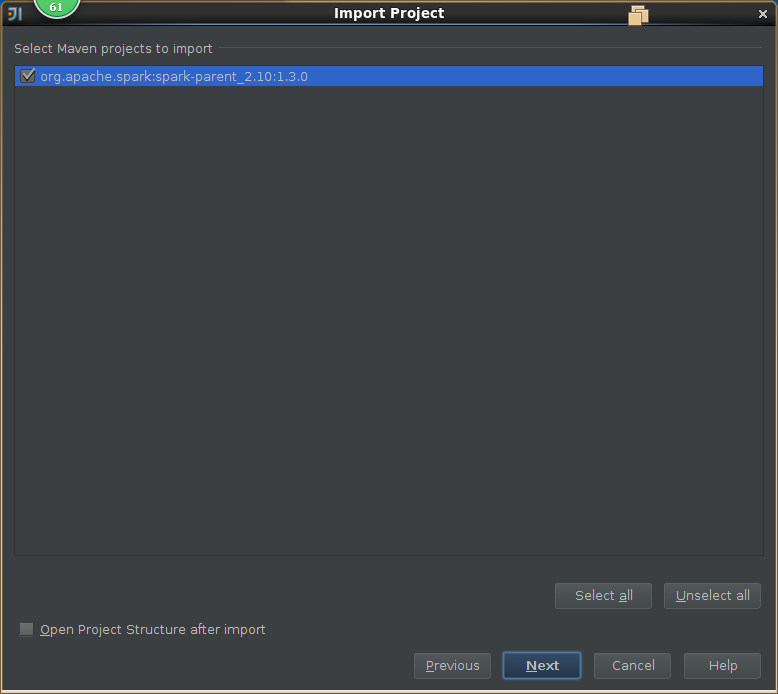
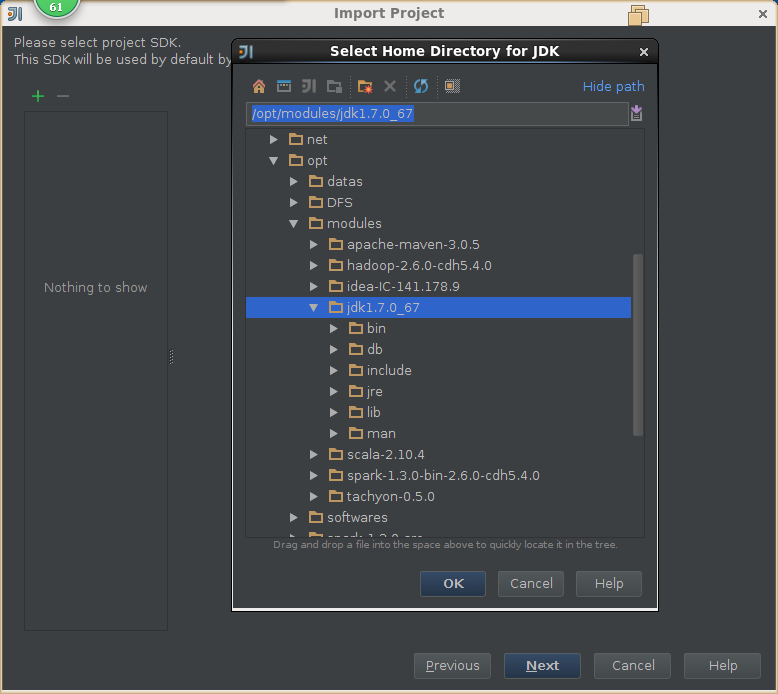
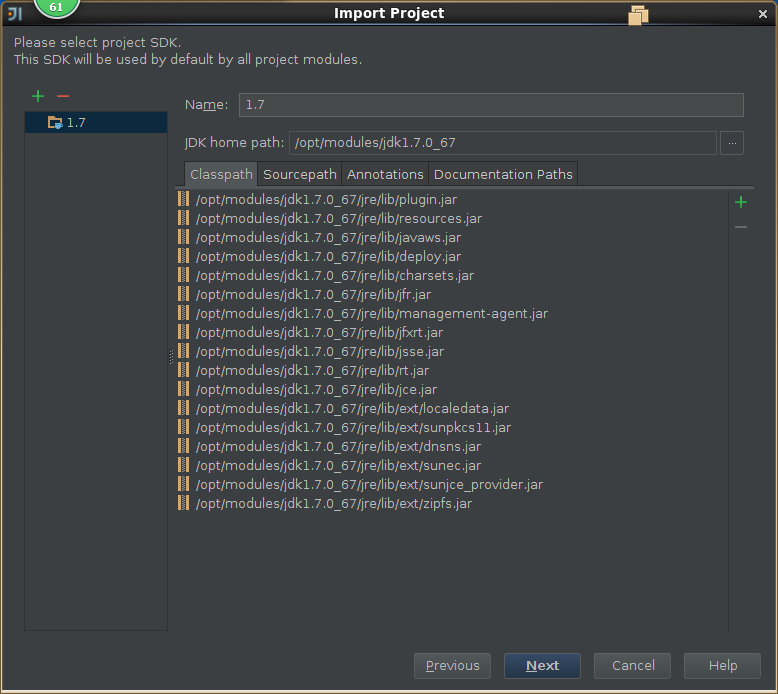
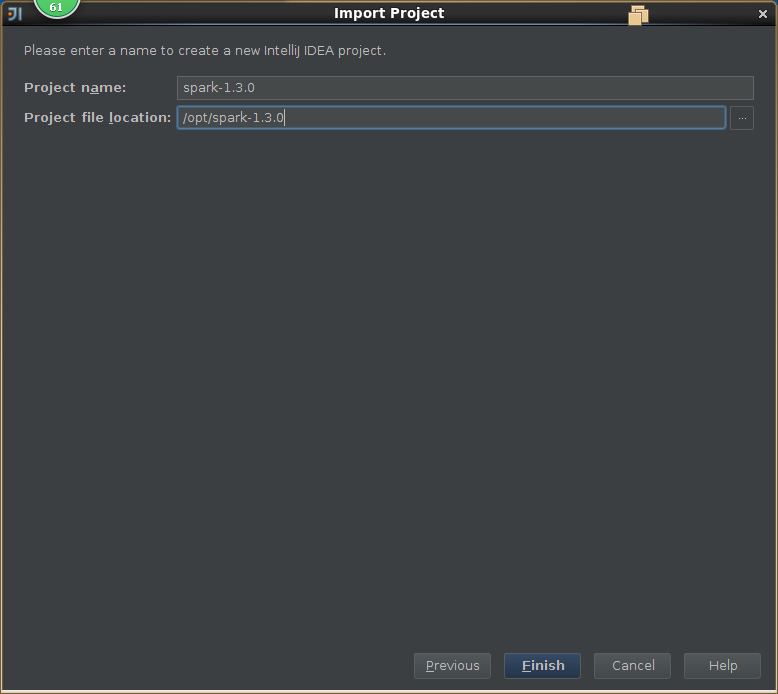
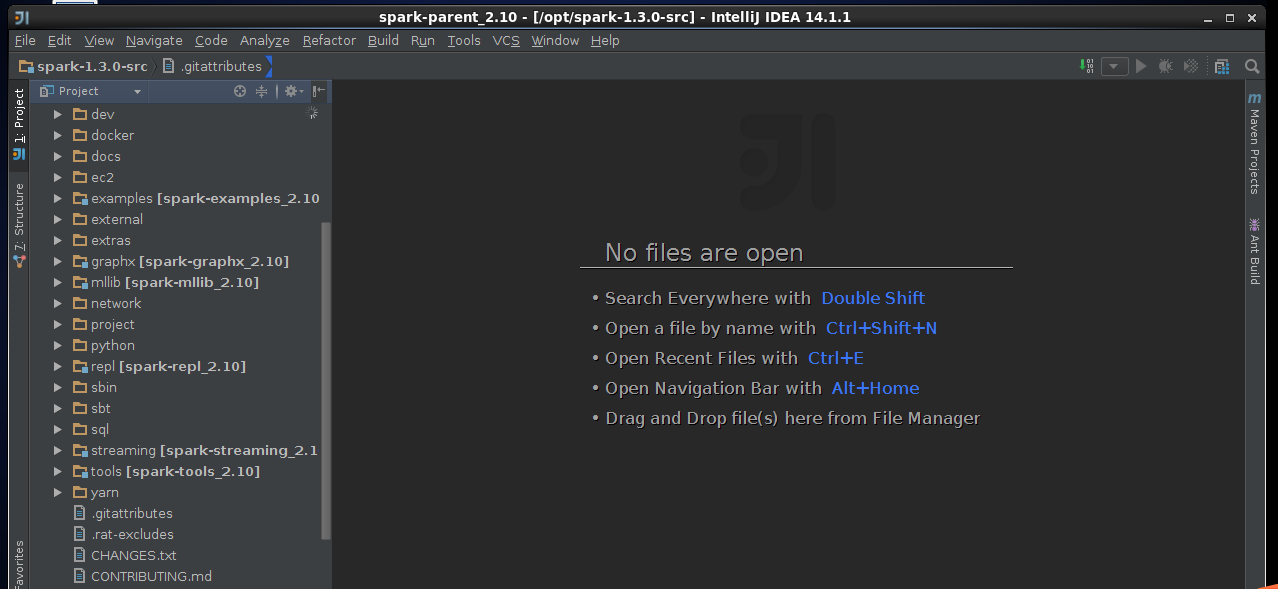
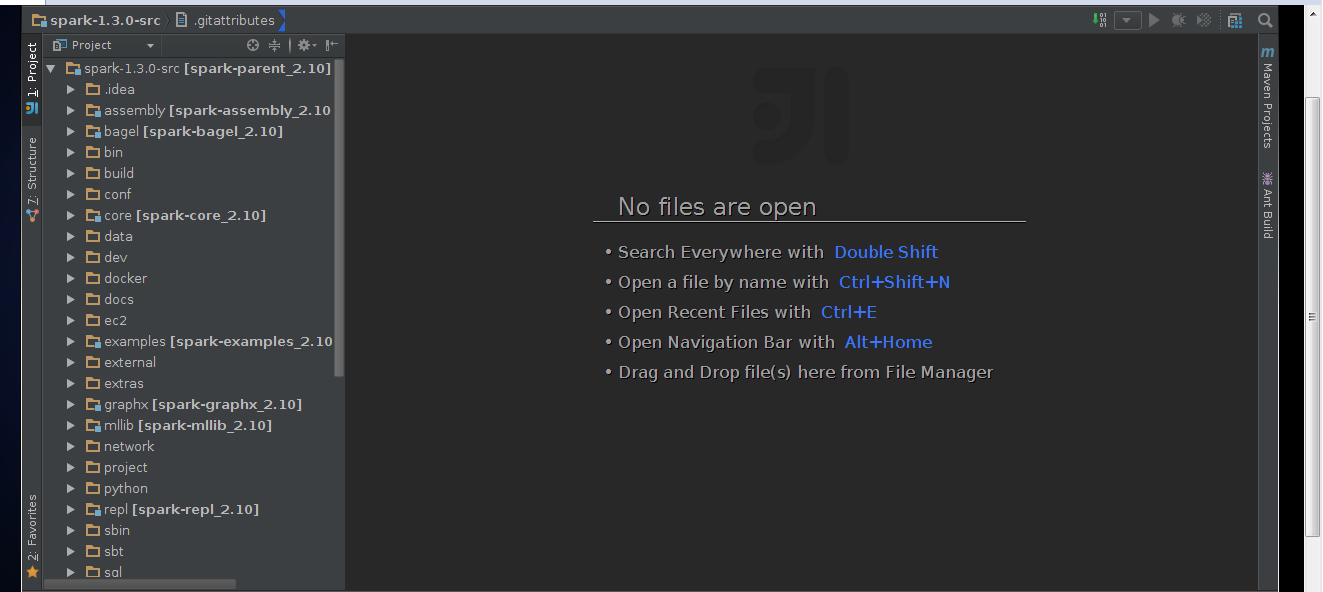
4,创建scala工程
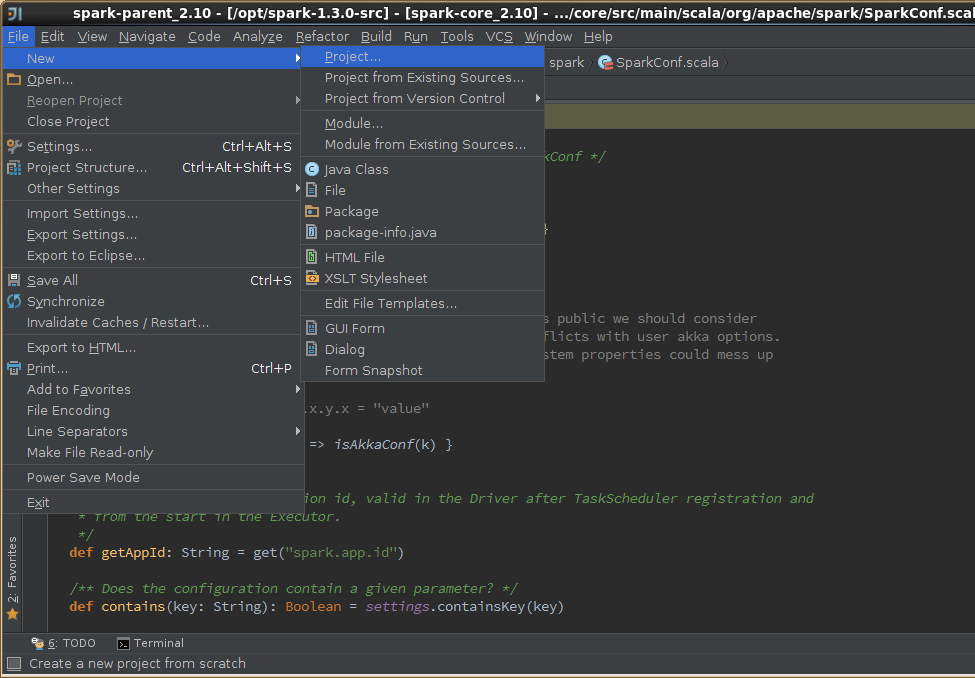
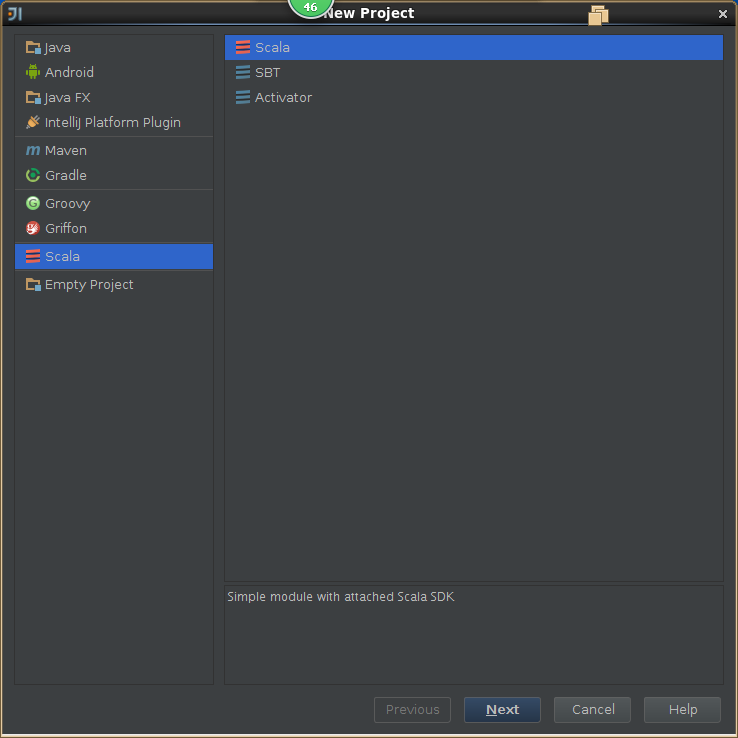
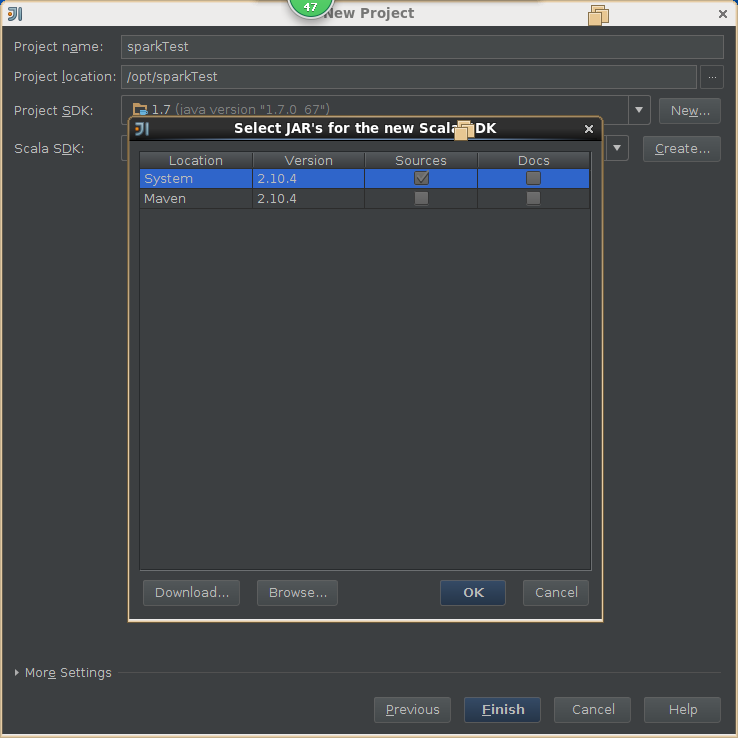
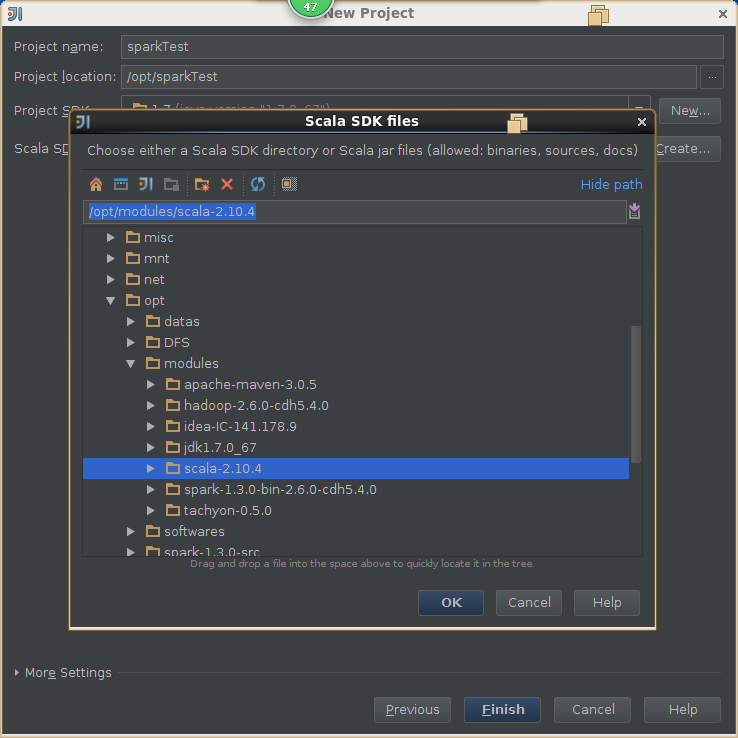
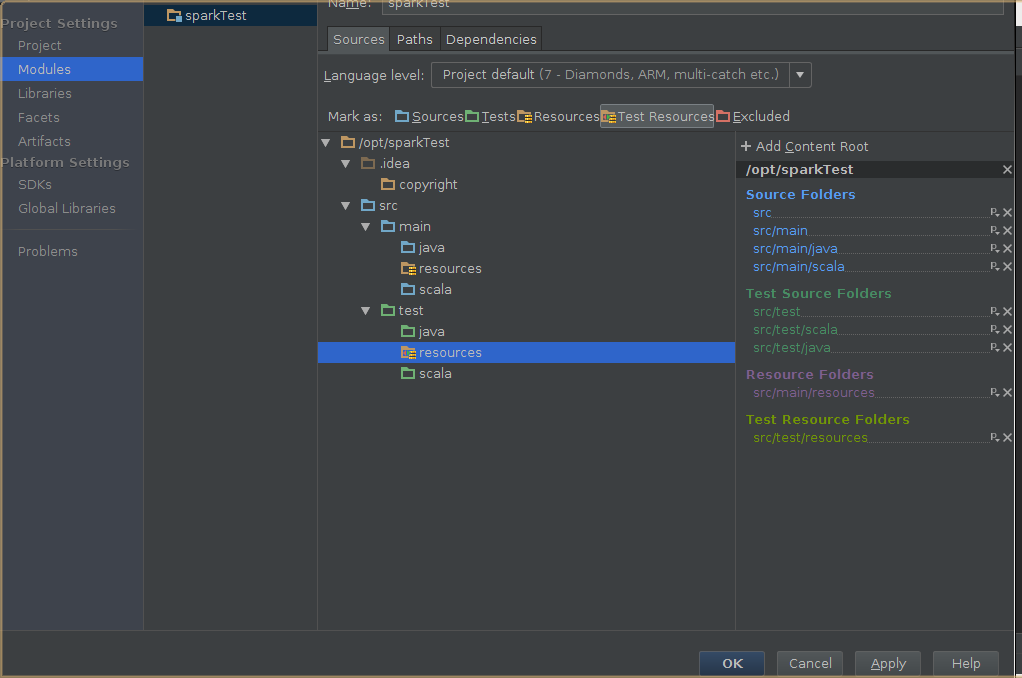
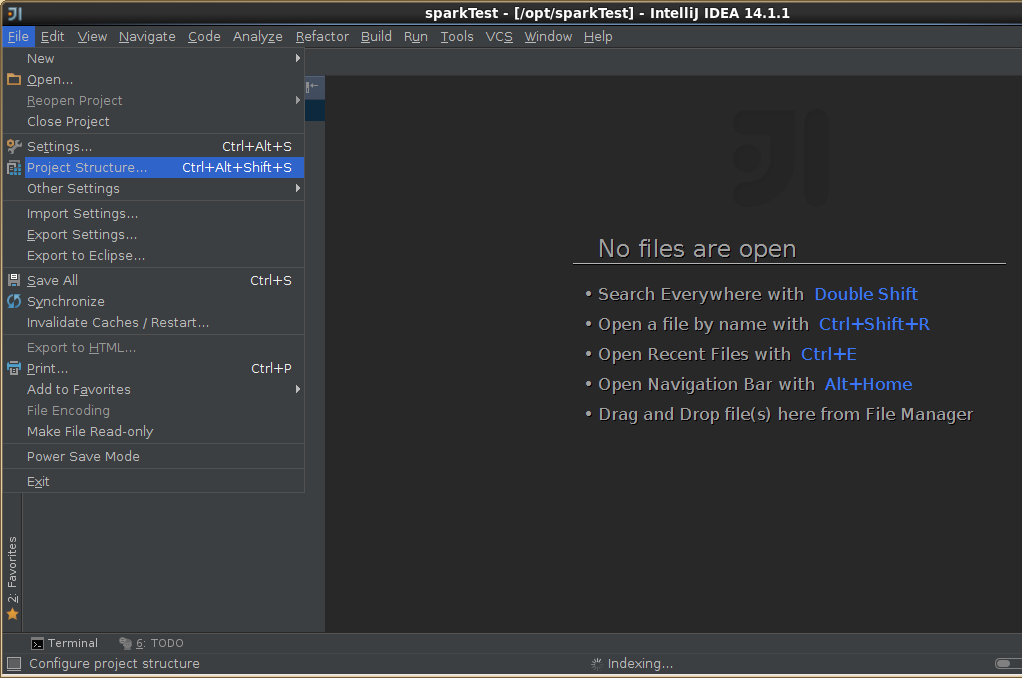
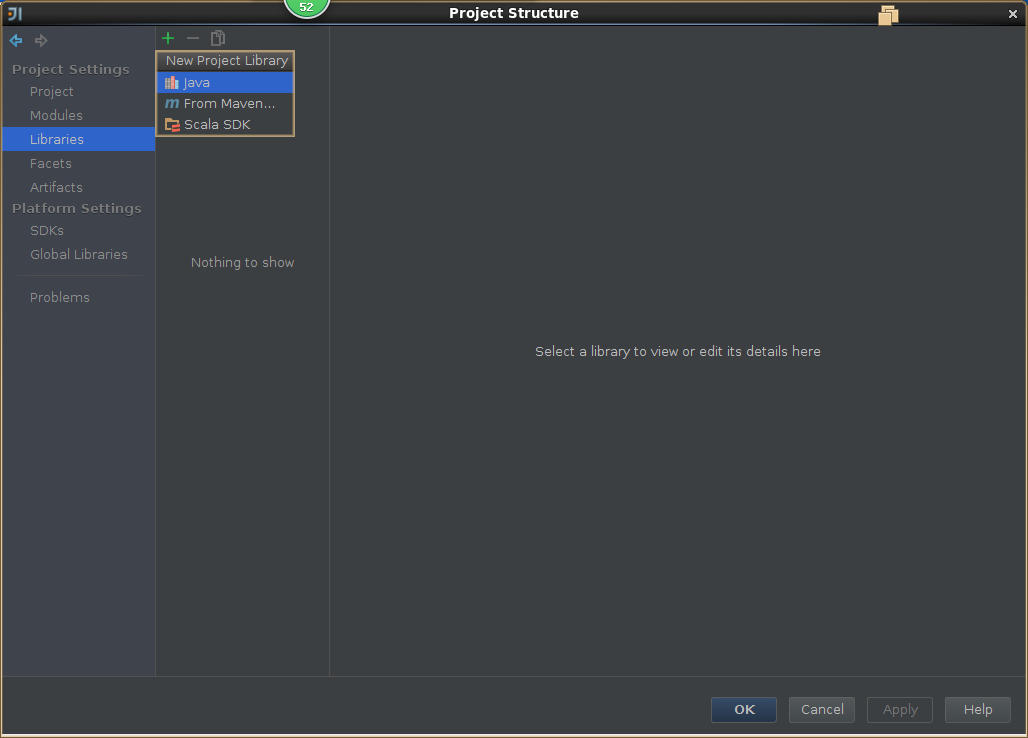
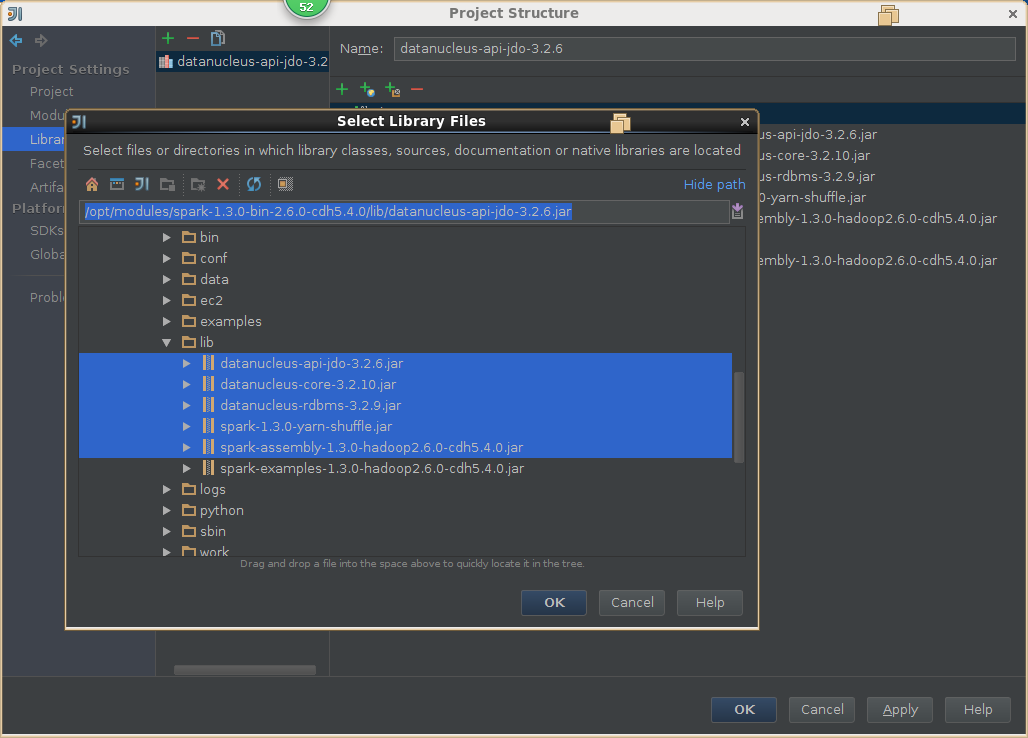
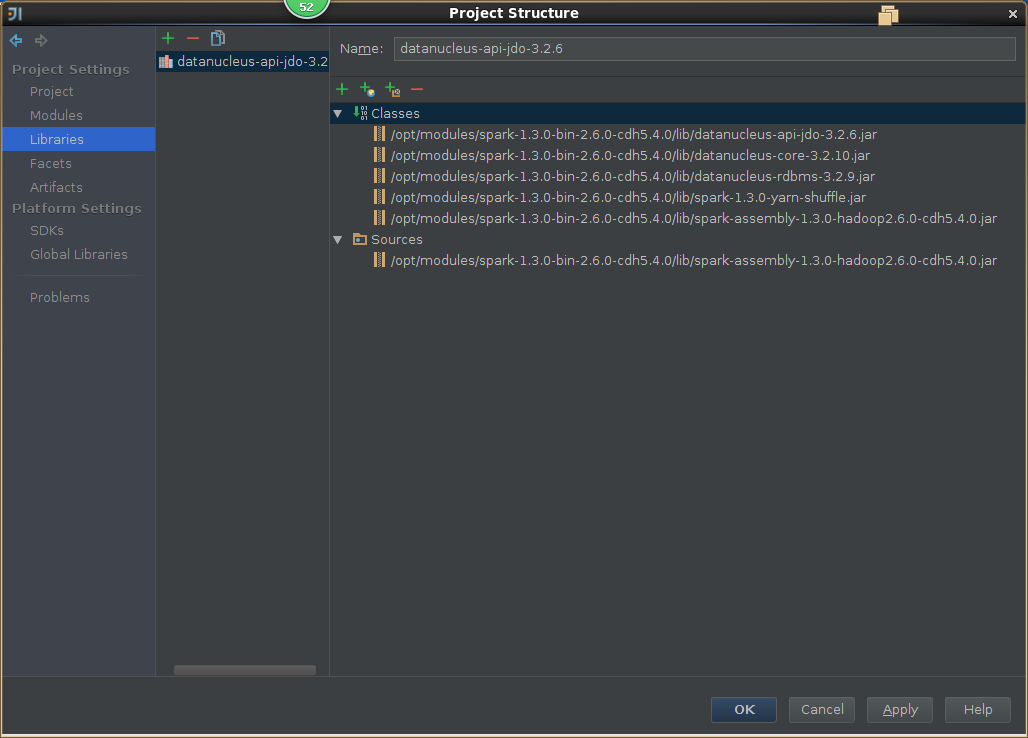
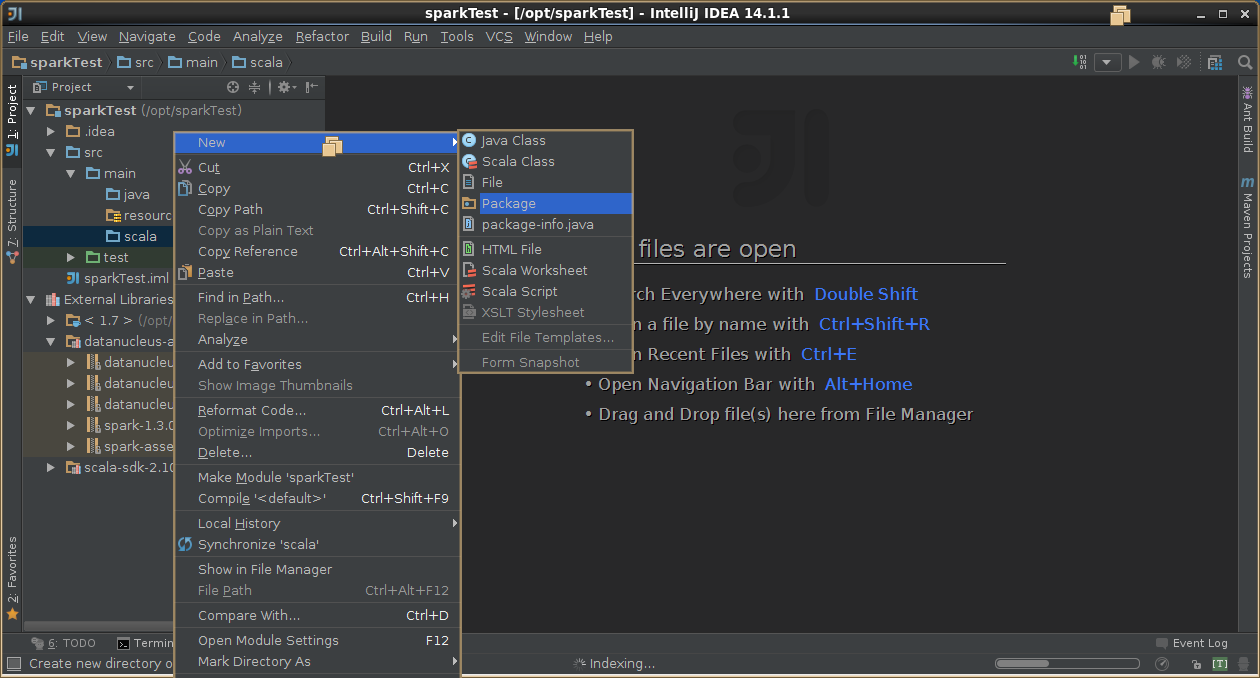
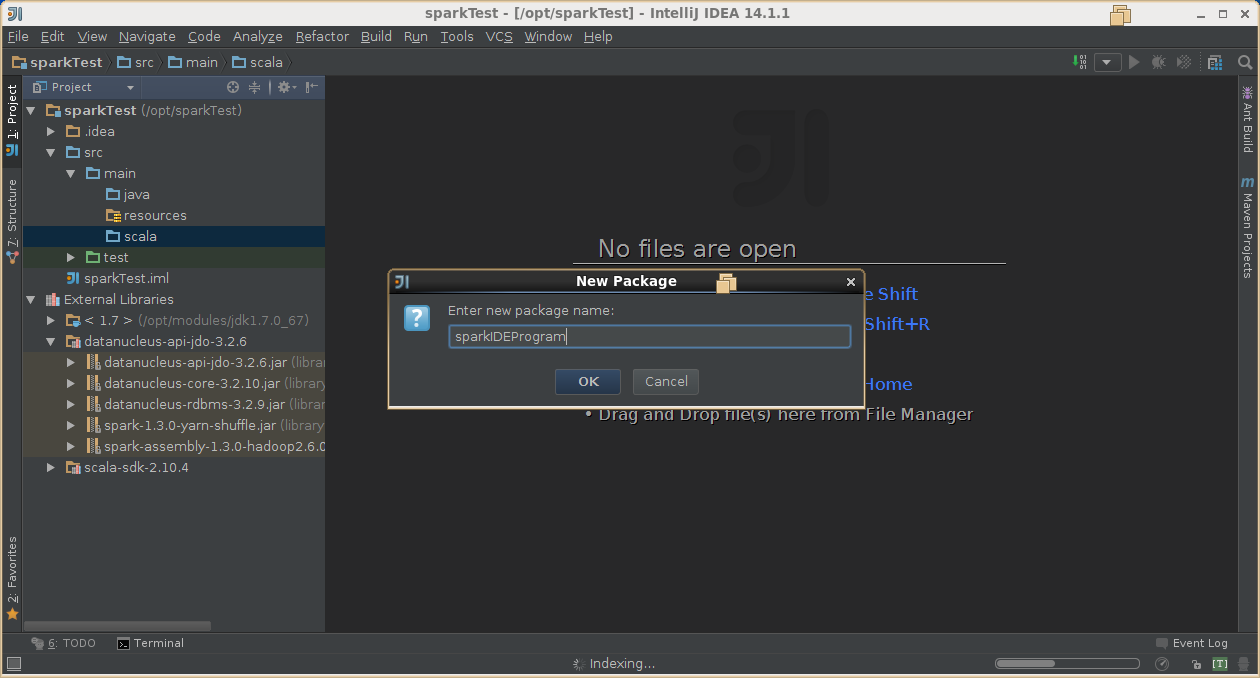
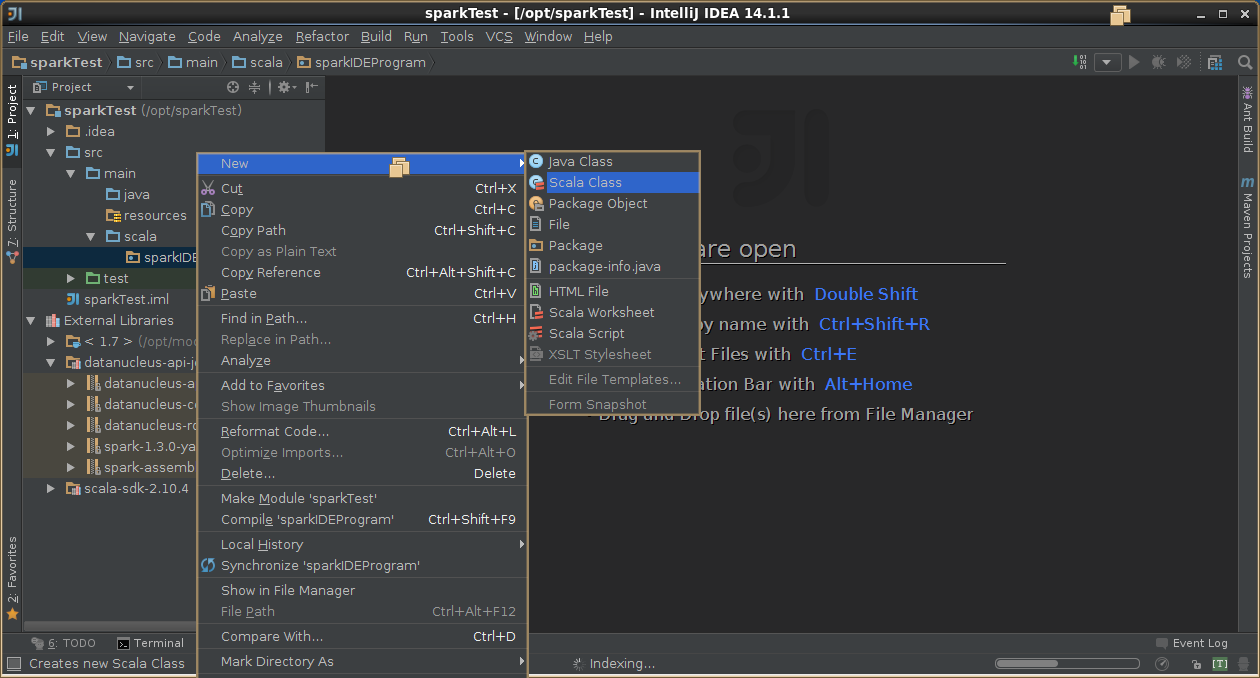
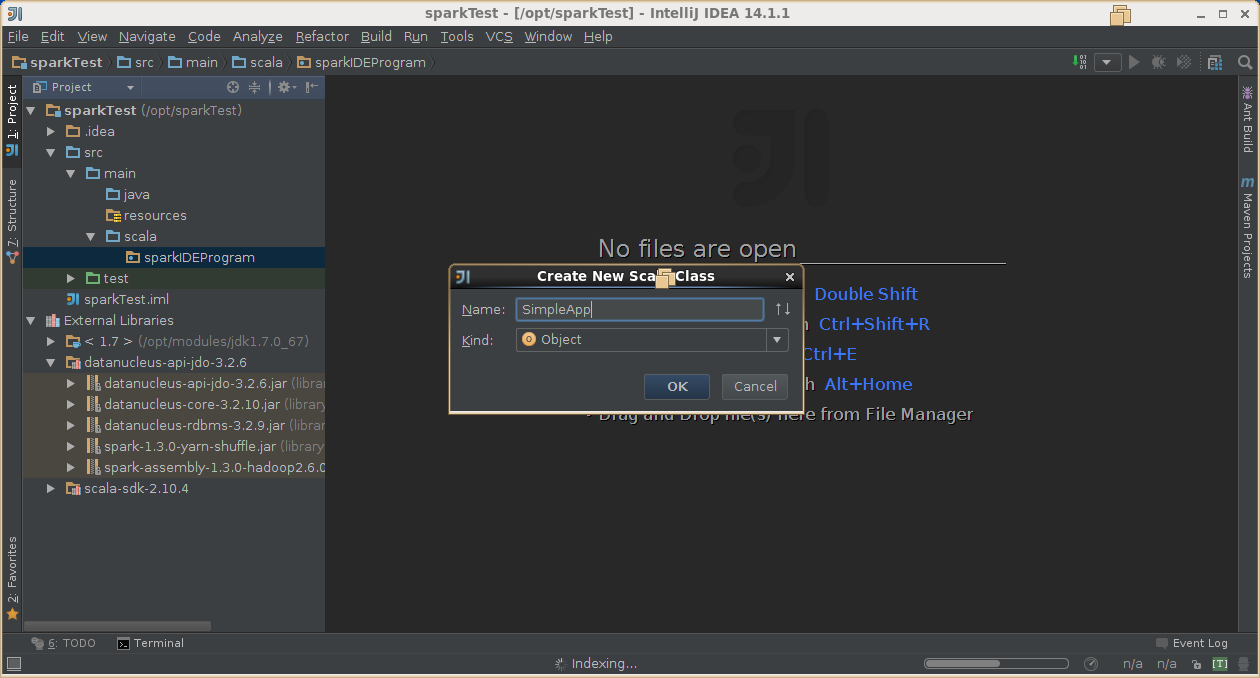
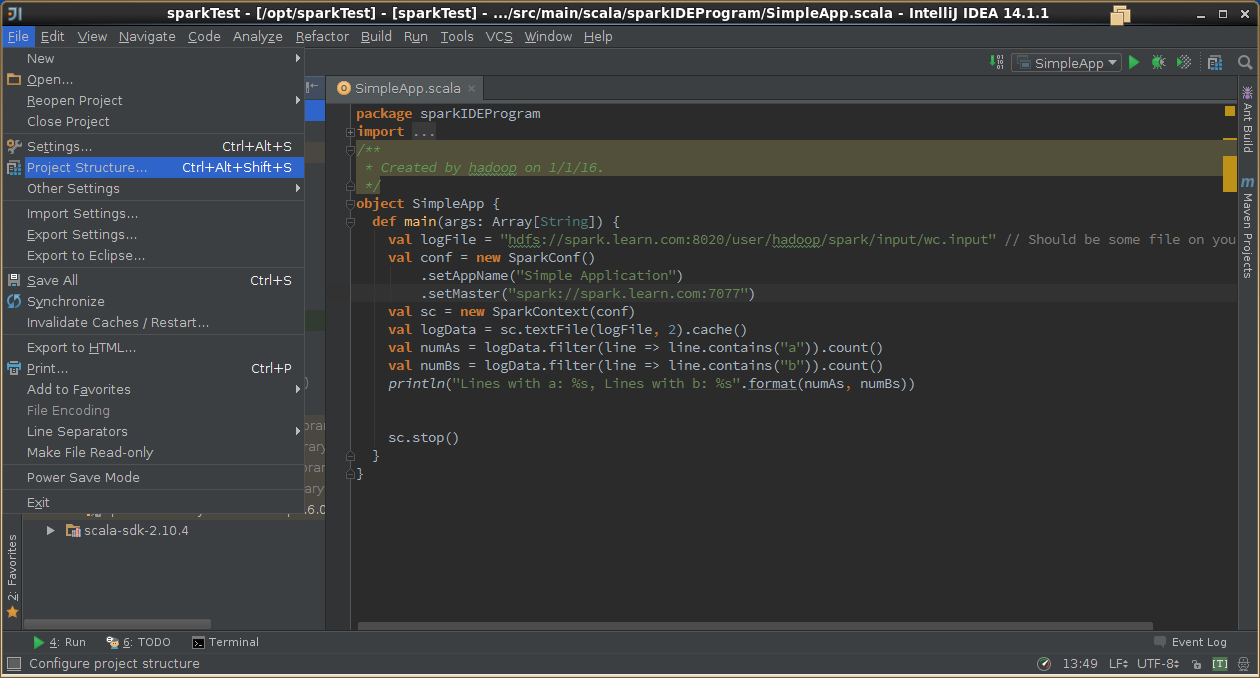
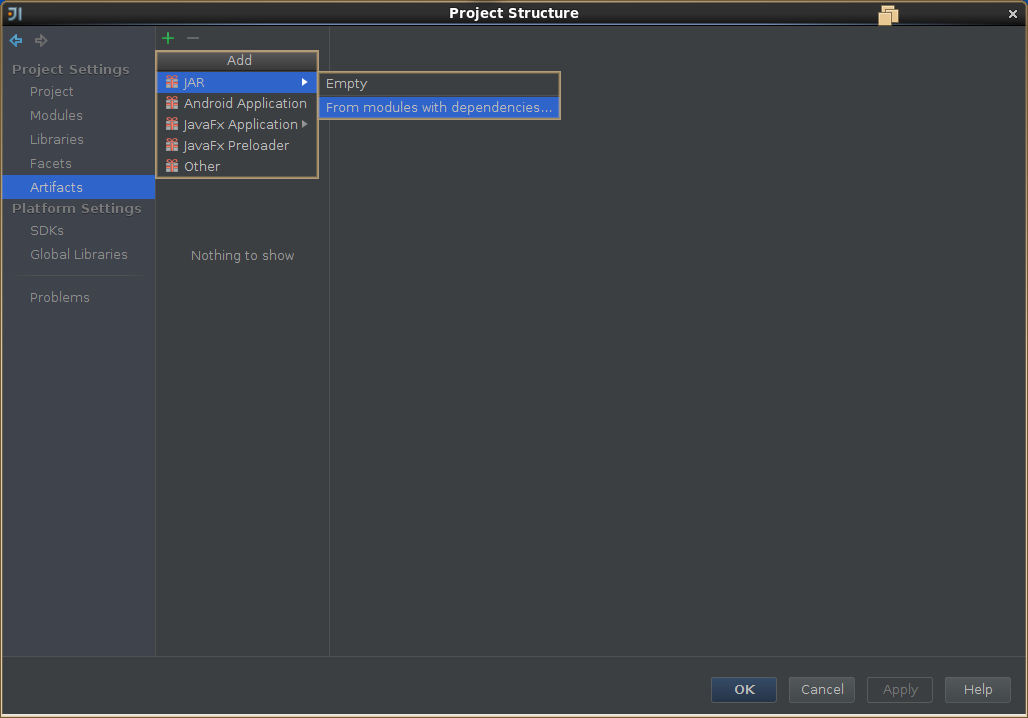
5,导出jar包
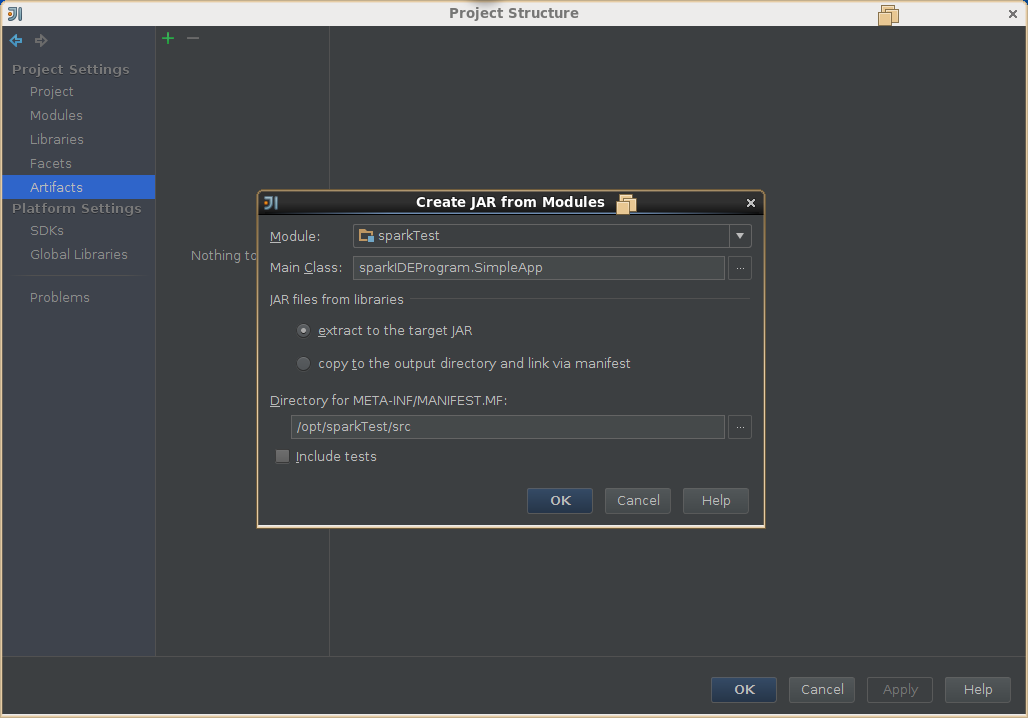
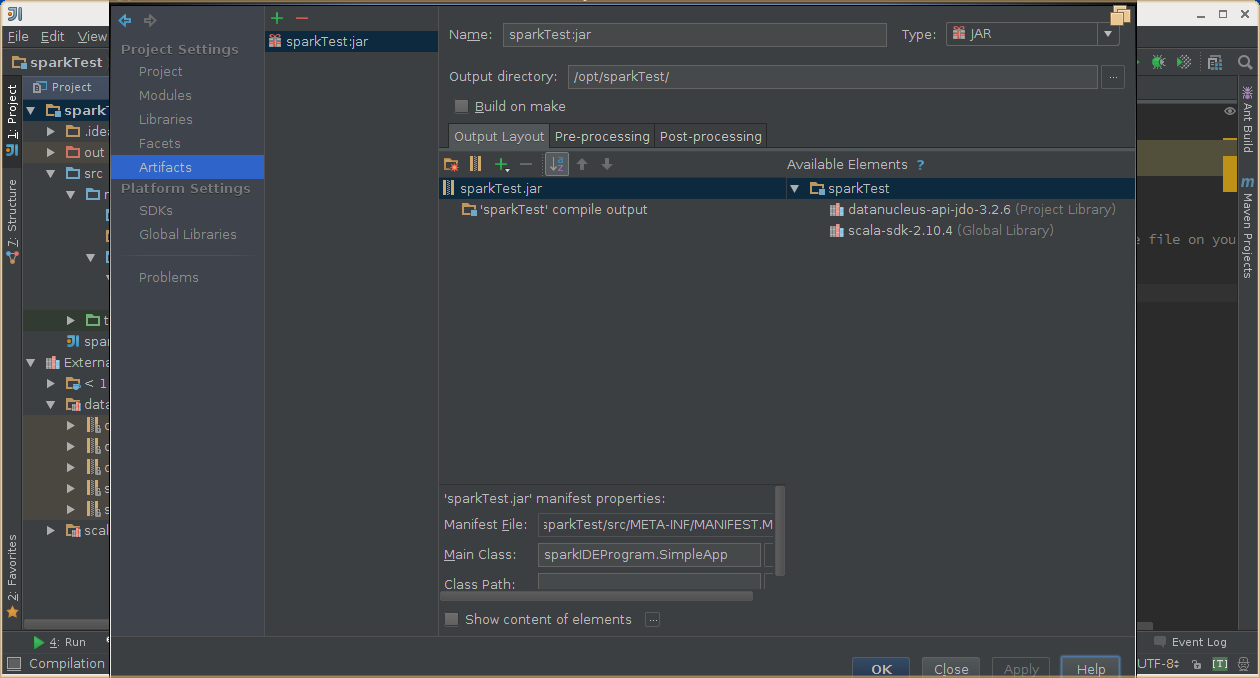
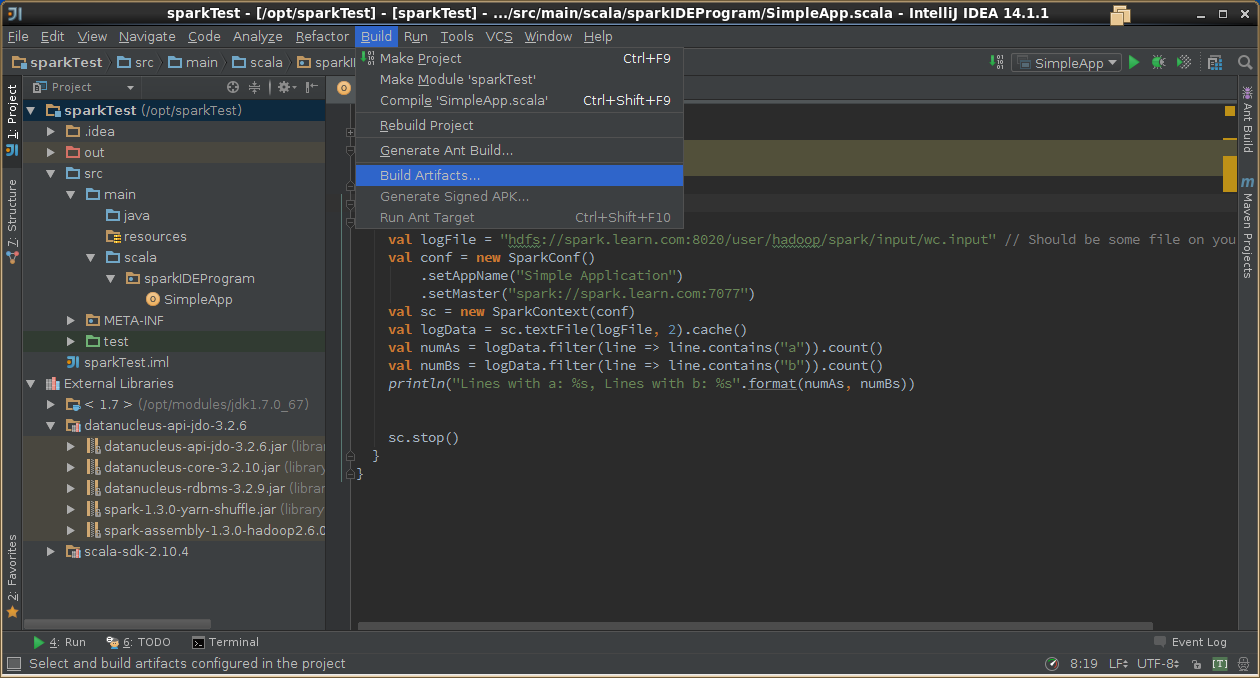
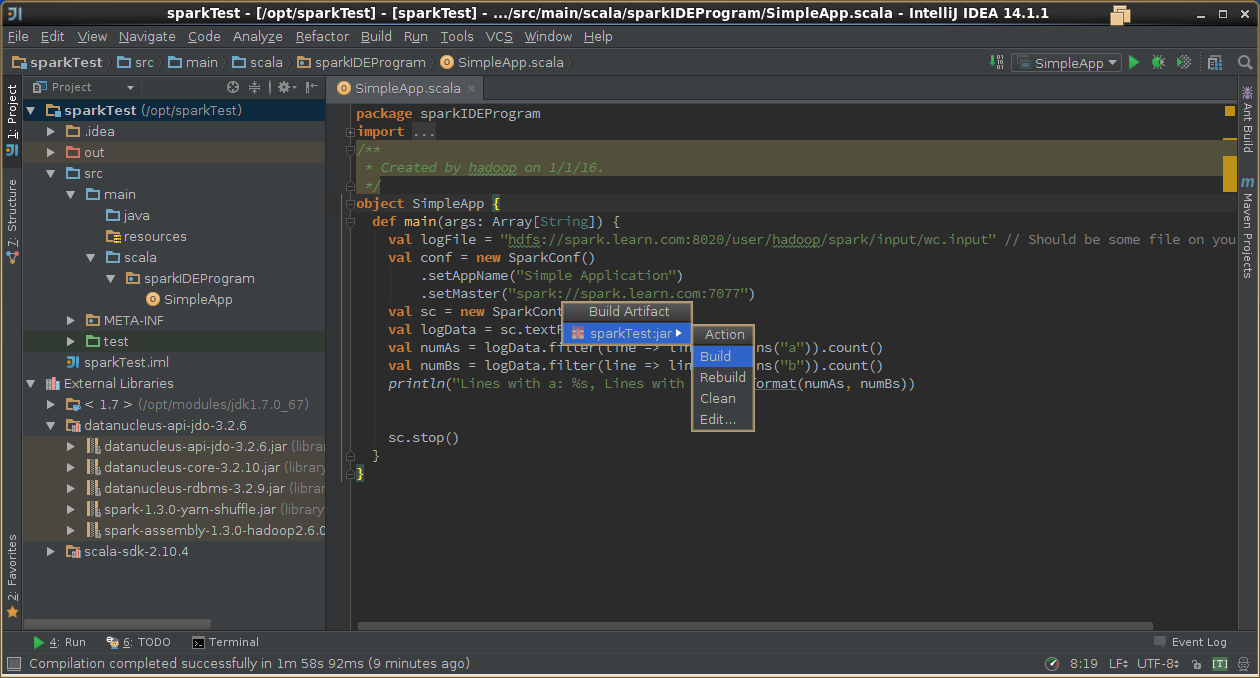
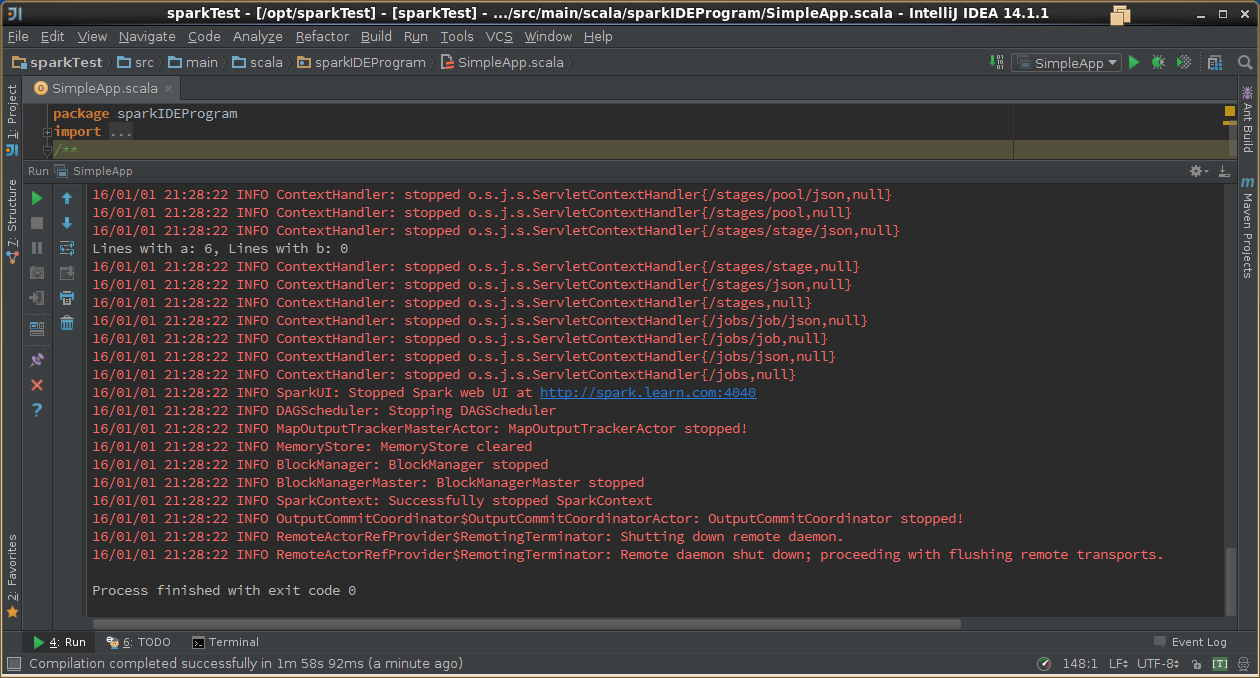
6,示例代码
前提是
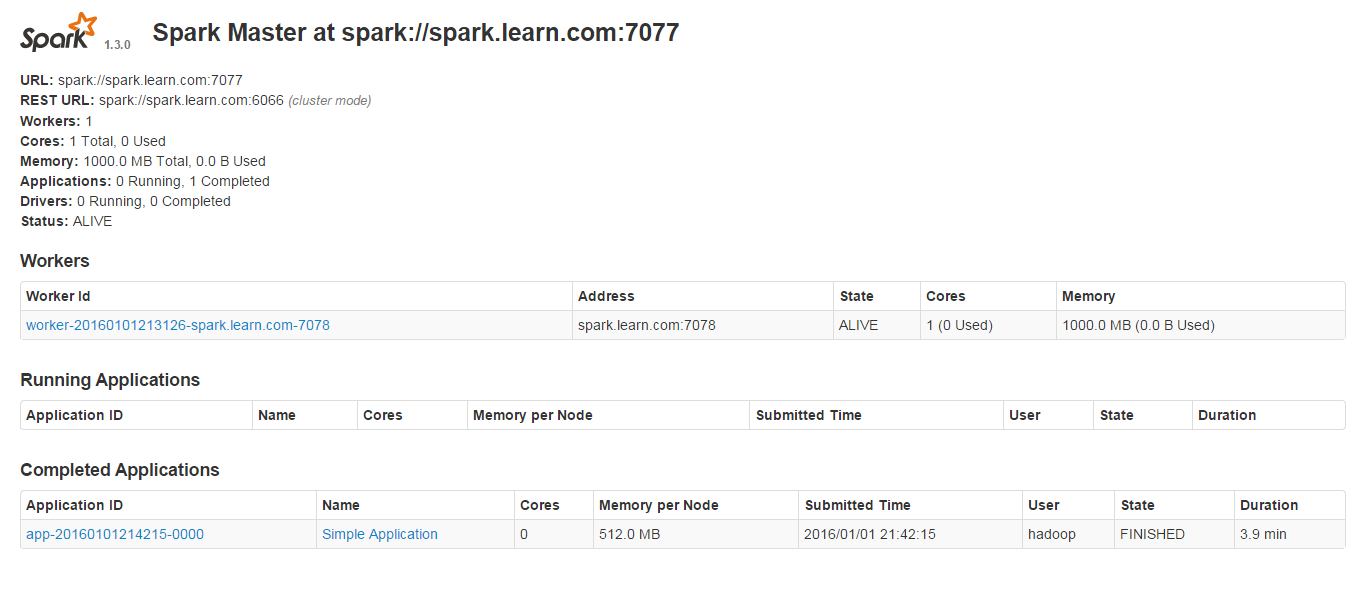
1,启动hdfs的namenode,datanode。
2,启动spark的master和slaves,本地测试无需启动。
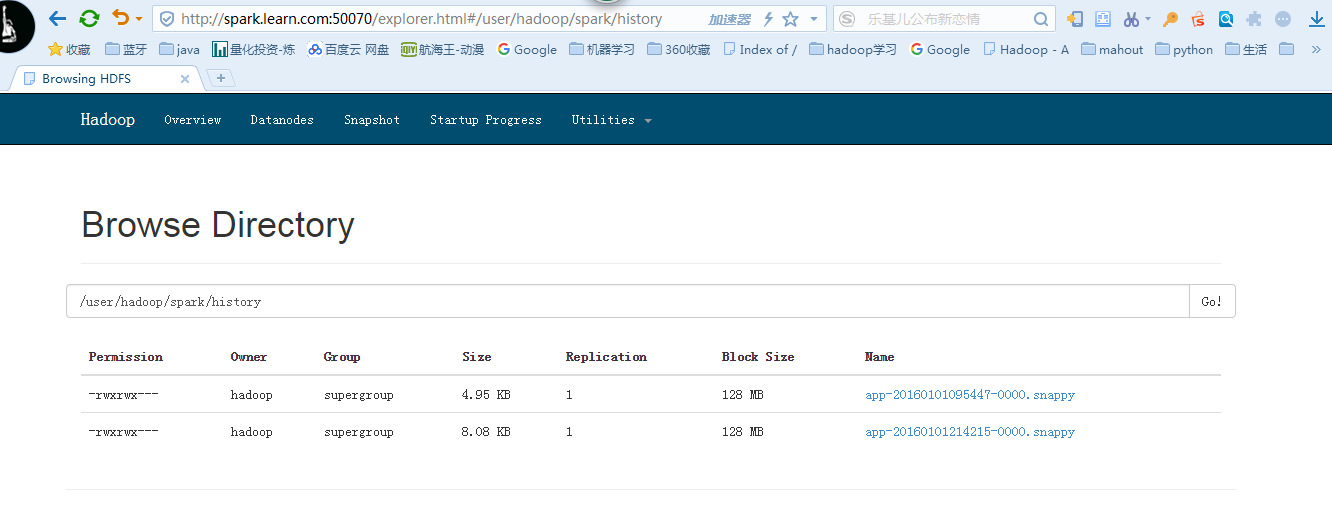
package sparkIDEProgramimport org.apache.spark.SparkContextimport org.apache.spark.SparkConf/*** Created by hadoop on 1/1/16.*/object SimpleApp {def main(args: Array[String]) {val logFile = "hdfs://spark.learn.com:8020/user/hadoop/spark/input/wc.input" // Should be some file on your systemval conf = new SparkConf().setAppName("Simple Application").setMaster("spark://spark.learn.com:7077")//本地测试需要修改为localval sc = new SparkContext(conf)val logData = sc.textFile(logFile, 2).cache()val numAs = logData.filter(line => line.contains("a")).count()val numBs = logData.filter(line => line.contains("b")).count()println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))sc.stop()}}
7,提交打包好的应用
bin/spark-submit /opt/sparkTest/sparkTest.jar