@hadoopMan
2015-12-03T23:04:32.000000Z
字数 5408
阅读 1419
Hive表的创建及测试
Hive表的创建及测试
本文主要完成如下内容:
1) Hive中创建表的三种方式,应用场景说明及练习截图
2) 内部表和外部表的区别,练习截图
3) 分区表的功能 、创建,如何向分区表中加载数据、如何检索分区表中的数据区表中的数据 ,练习截图
1,创删数据库
1,创建数据库
create database IF NOT EXISTS db_1128 ;

2,删除数据库
drop database IF EXISTS db_1128 ;
2,创建表
创建表的语法
##CREATE TABLE [IF NOT EXISTS] [db_name.]table_name[(col_name data_type [COMMENT col_comment], ...)][COMMENT table_comment][[ROW FORMAT row_format][STORED AS file_format]][LOCATION hdfs_path][AS select_statement];
2.1 Create直接创建
CREATE TABLE IF NOT EXISTS db_1128.bf_log_1128(ip string COMMENT 'remote ip address',user string ,req_url string)COMMENT 'BeiFeng Web Access Logs'ROW FORMAT DELIMITED FIELDS TERMINATED BY ' 'STORED AS textfile ;
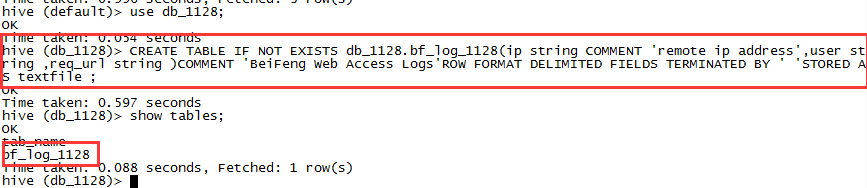
查看表信息:
desc [formatted] bf_log_1128;
加载数据:
load data local inpath '/opt/datas/bf_log.txt' into table db_1128.bf_log_1128 ;
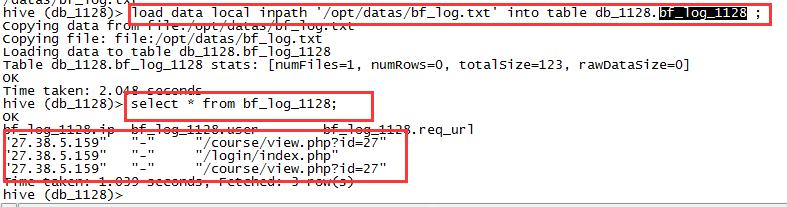
该种方法主要应用于:
创建一个新的表。
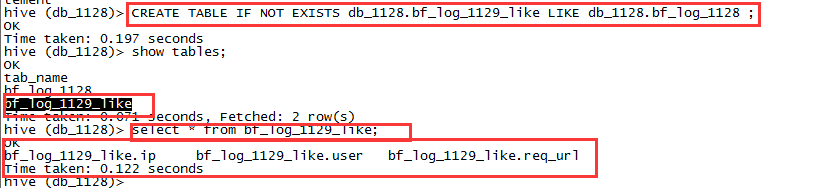
2.2 使用like关键字创建表
创建的表与已有的表一致
CREATE TABLE IF NOT EXISTS db_1128.bf_log_1129_likeLIKE db_1128.bf_log_1128 ;
2.3 使用AS关键字创建一张表
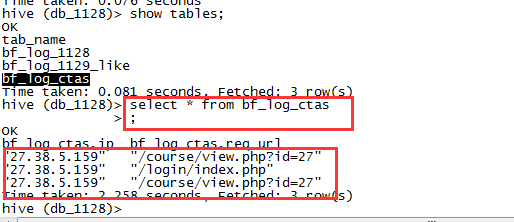
CREATE TABLE IF NOT EXISTS db_1128.bf_log_ctasAS select ip, req_url from db_1128.bf_log_1128 ;
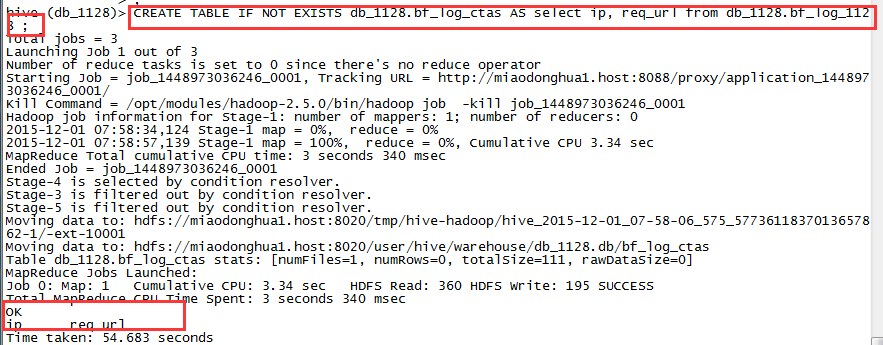
hive分析的数据结果存放位置
1,存储在hdfs
2,存储在hive表中,临时表
drop table if exists db_1128.bf_log_ctas;CREATE TABLE db_1128.bf_log_ctasAS select ip, req_url from db_1128.bf_log_1128 ;
注:创建一张表,只保留SELECT语句查询出来的字段,并加载数据到表中。
2.4 删除表
drop table mytable [purge] ;
purge参数用于删除元数据丢失的表。
3,创建雇员表和部门表
3.1 创建雇员表
CREATE TABLE IF NOT EXISTS db_1128.emp(empno int,ename string,job string,mgr int,hiredate string,sal double,comm double,deptno int)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS textfile ;
3.2 创建部门表
CREATE TABLE IF NOT EXISTS db_1128.dept(deptno int,dname string,loc string)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS textfile ;
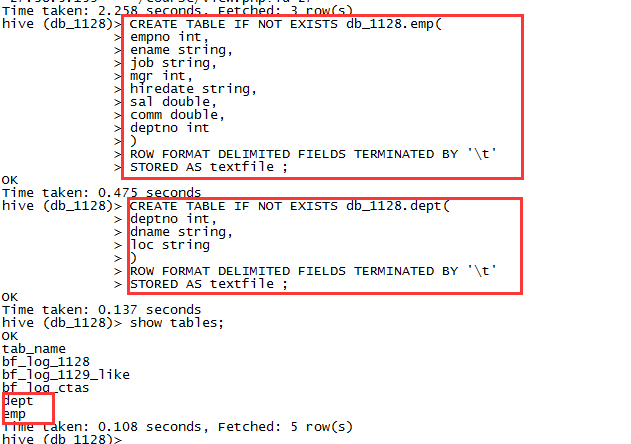
3.3 为两个表导入数据
load data local inpath '/opt/datas/emp.txt' overwrite into table emp ;load data local inpath '/opt/datas/dept.txt' overwrite into table dept ;

3.4 清空表里面的数据
实际是删除了对应目录下的数据存储文件而保存了目录
truncate table emp ;select * from emp ;

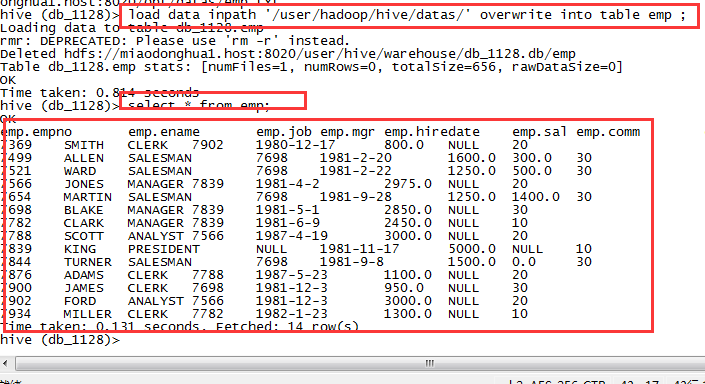
3.5 从HDFS文件系统上导入数据
创建目录并上传数据
dfs -mkdir -p /user/hadoop/hive/datas;dfs -put /opt/datas/emp;
加载数据
load data inpath '/user/hadoop/hive/datas/' overwrite into table emp ;
这种方式,会删除源文件。
4,Hive的外部表
4.1,创建外部表
CREATE EXTERNAL TABLE IF NOT EXISTS db_1128.emp_ext(empno int,ename string,job string,mgr int,hiredate string,sal double,comm double,deptno int)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS textfile ;
4.2,往外部表中加载数据
load data local inpath '/opt/datas/emp.txt' overwrite into table emp_ext ;
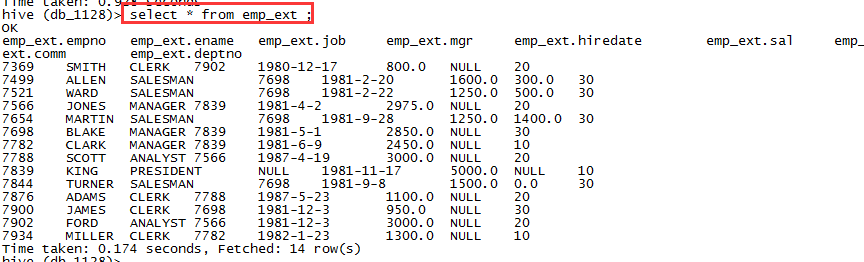
4.3,对比外部表与内部表的差异
删除表
drop table emp ;drop table emp_ext ;
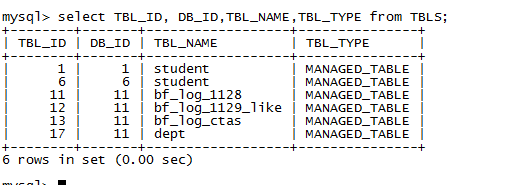
4.4,到Hive表在mysql的元数据查看
show databases;use metastore;show tables;desc TBLS;select TBL_ID, DB_ID,TBL_NAME,TBL_TYPE from TBLS;
4.5,在HDFS上查看表的数据
在浏览器中输入
miaodonghua1.host:50070

4.6,外部表与内部表的结果
内部表:
内部表也称之为MANAGED_TABLED;
默认存储在/use/hive/warehouse下,也可以通过location指定。
删除表时,会删除表数据以及元数据。
外部表:
外表称之为EXTERNAL_TABLE
在创建表时,可以自己指定目录位置(LOCATION)
删除表时只会删除表的元数据不会删除表的数据。
应用
日志存储文件可以用外部表存储。
4.7,外部表可以直接指定路径
创建目录并上传文件
dfs -mkdir -p /user/hadoop/hivewarehouse/emp;dfs -mv /user/hive/warehouse/db_1128.db/emp_ext/emp.txt /user/hadoop/hivewarehouse/emp;
指定目录的方式创建外部表
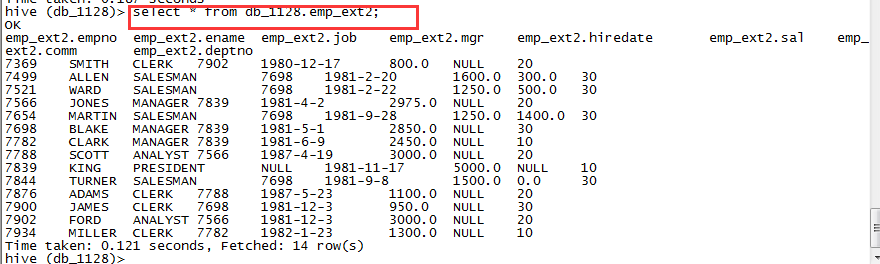
CREATE EXTERNAL TABLE IF NOT EXISTS db_1128.emp_ext2(empno int,ename string,job string,mgr int,hiredate string,sal double,comm double,deptno int)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS textfileLOCATION '/user/hive/warehouse/emp';
查看表信息:
select * from db_1128.emp_ext2;
5,分区表
分区表实际上就是对应一个HDFS文件系统上的独立文件夹,该文件夹下是该分区所有的数据文件。hive中的分区就是分目录,把一个大的数据集根据业务需要分割成更小的数据集。
在查询时通过WHERE子句中的表达式来选择查询所需要的指定分区,这样查询效率会提高很多。
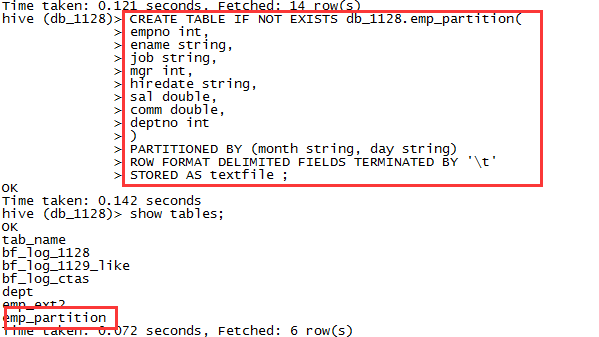
5.1,创建分区表
CREATE TABLE IF NOT EXISTS db_1128.emp_partition(empno int,ename string,job string,mgr int,hiredate string,sal double,comm double,deptno int)PARTITIONED BY (month string, day string)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS textfile ;
5.2,分区表加载数据
load data local inpath '/opt/datas/emp.txt' overwrite into table db_1128.emp_partition partition(month = '201511',day = '28');

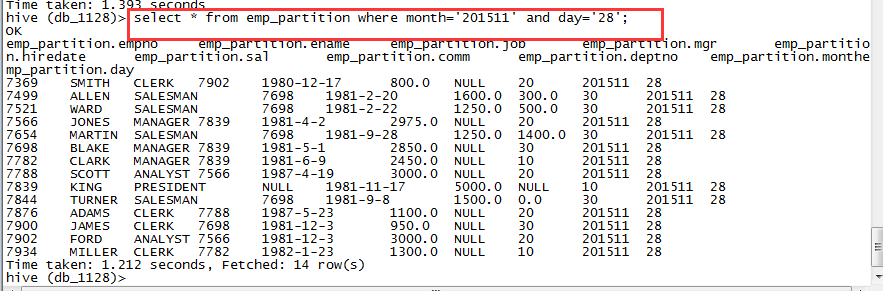
查询分区表的数据
select * from emp_partition where month='201511' and day='28';
6,外分区表
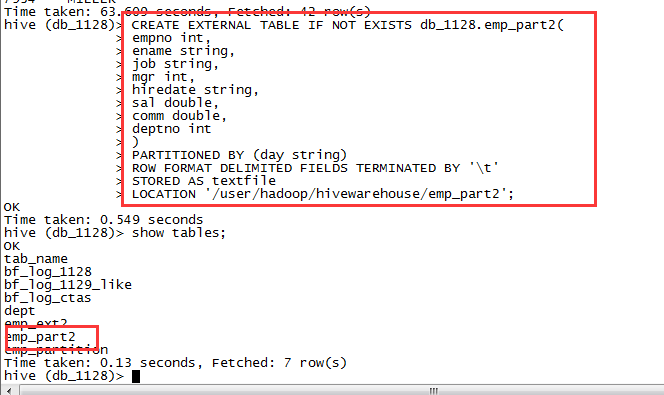
6.1,创建外部分区表
CREATE EXTERNAL TABLE IF NOT EXISTS db_1128.emp_part2(empno int,ename string,job string,mgr int,hiredate string,sal double,comm double,deptno int)PARTITIONED BY (day string)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS textfileLOCATION '/user/hadoop/hivewarehouse/emp_part2';
6.2,创建目录并上传数据
dfs -mkdir /user/hadoop/hivewarehouse/emp_part2/day=28/ ;dfs -put /opt/datas/emp.txt /user/hadoop/hivewarehouse/emp_part2/day=28 ;
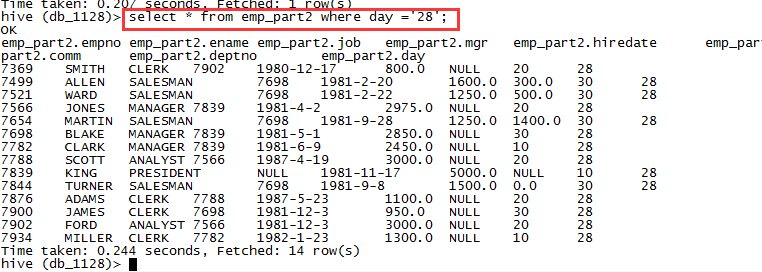
6.3,实现分区数据:
alter table emp_part2 add partition(day = '28');
查看外部分区

7,企业中的应用
7.1,创建分区表
日志文件分区表按三级分区
month/day/time
CREATE EXTERNAL TABLE IF NOT EXISTS db_1128.emp_part_logs(empno int,ename string,job string,mgr int,hiredate string,sal double,comm double,deptno int)PARTITIONED BY (month string,day string,time string)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS textfileLOCATION '/user/hadoop/hivewarehouse/emp_part_logs';
7.2,业务需求分析:
1)创建分区表
2)第二天需要分析统计
3)11-29:00前数据加载到表中
1,写脚本实现数据加载:
写脚本,通过下面指令上传数据到分区表中(不会使用此方式):
load data local inpath '/opt/datas/emp00.txt' overwrite into table db_1128.emp_part_logs partition(month = '201511',day = '28',time = '00');
2,写shell脚本
这种方式可每日无需修改直接使用来实现数据加载
1,在hdfs上创建相应目录
dfs -mkdir -p /user/hadoop/hivewarehouse/emp_part_logs/month=201511/day=28/time=00 ;
2,put数据到对应的目录中区
dfs -put /opt/datas/emp.txt/ /user/hadoop/hivewarehouse/emp_part_logs/month=201511/day=28/time=00;
3,分区数据。
alter table emp_part_logs add partition(month='201511',day='28',time='00') ;
shell脚本实现代码如下
#!/bin/bashi=1while [ $i -le 24 ]doexport dmonth=$(date '+%Y%m')#export dmonthecho $dmonthexport dday=$(date '+%d')#export ddaynewpath="/user/hadoop/hivewarehouse/emp_part_logs/month=${dmonth}/day=${dday}/time=${i}"echo $newpath#export newpath/opt/modules/hadoop-2.5.0/bin/hdfs dfs -mkdir -p ${newpath}/opt/modules/hadoop-2.5.0/bin/hdfs dfs -put /opt/datas/emp.txt ${newpath}/opt/modules/hive-0.13.1/bin/hive -S -e "use db_1128;alter table emp_part_logs add partition(month = '${dmonth}',day = '${dday}',time = '${i}') ;"let i++done
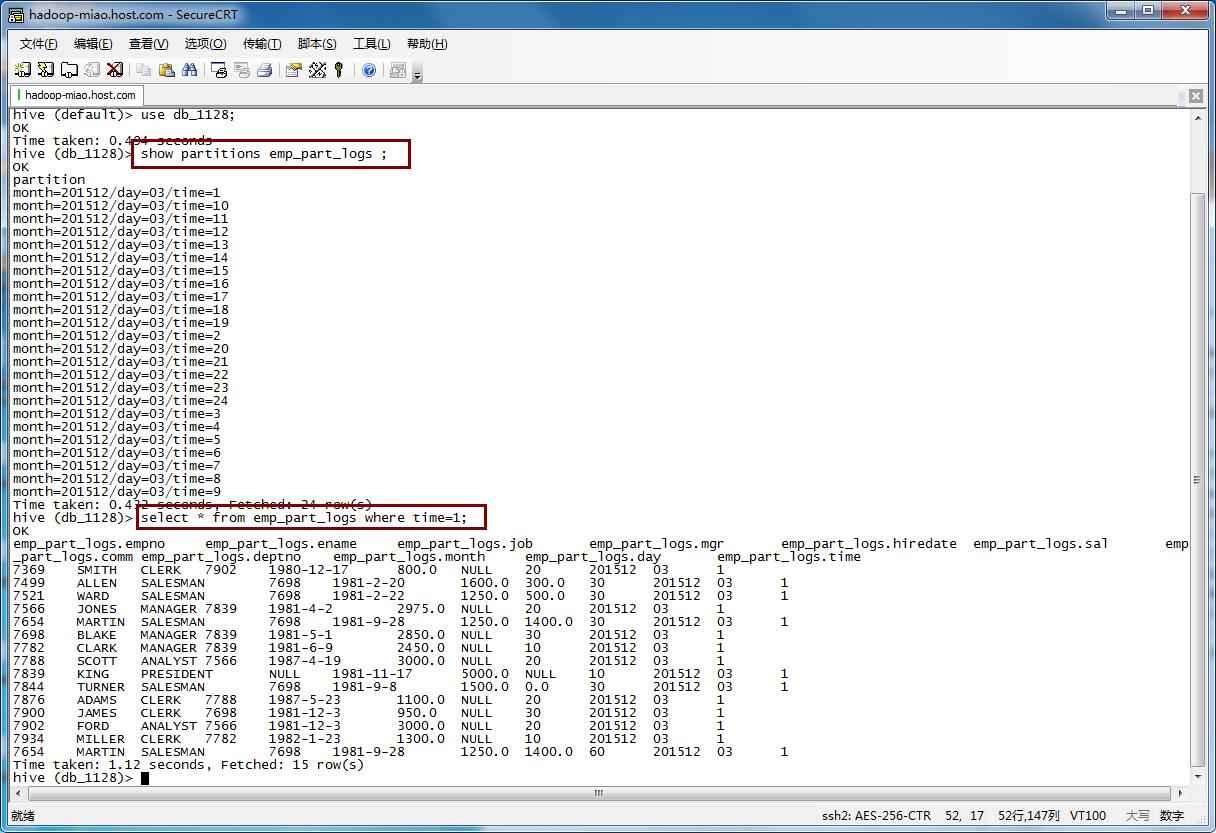
执行成功后:
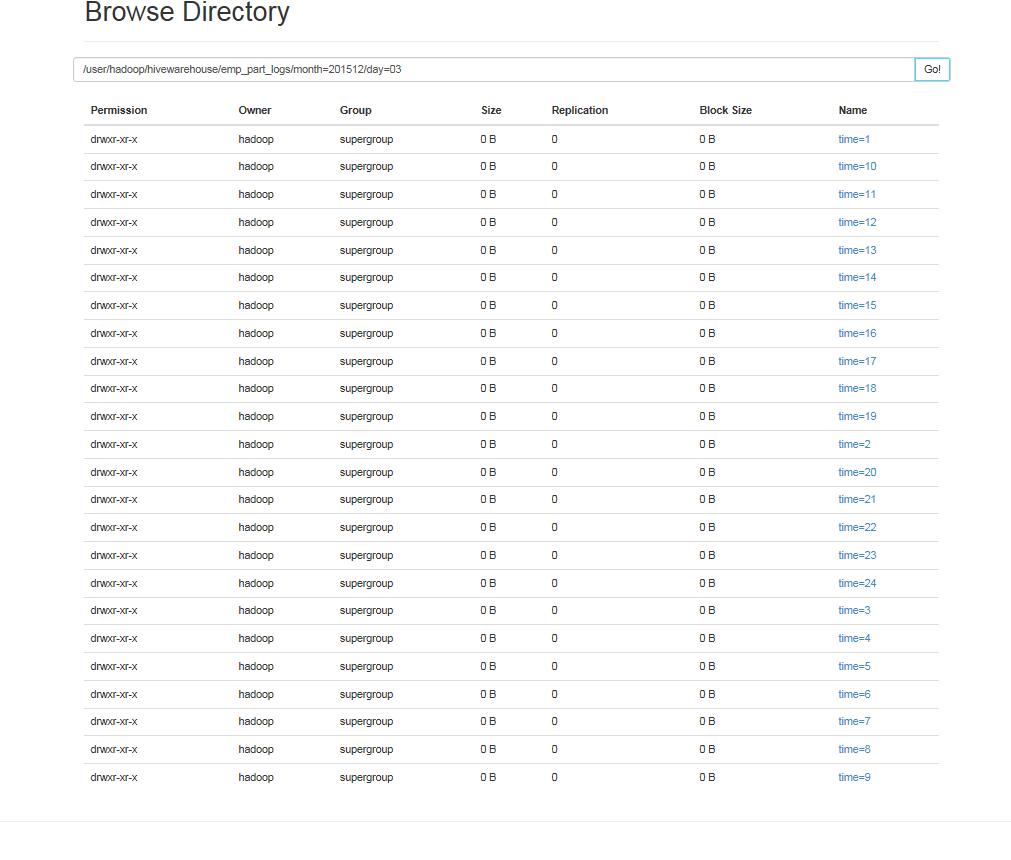
show partitions emp_part_logs ;select * from emp_part_logs where time=1;