@hadoopMan
2017-03-04T14:29:55.000000Z
字数 16461
阅读 1756
Hbase进阶
hbase
想学习spark,hadoop,kafka等大数据框架,请加群459898801,满了之后请加2群224209501。后续文章会陆续公开
1,HBase 功能架构
1,hbase是hadoop的数据库
hbase是Hadoop 数据库,因为它具有存储数据和检索数据的功能。而且数据存储是基于HDFS,主要原因依赖hdfs存储数据量大,数据安全性高,而且硬件平台要求低,只需要商用PCServer就可以等特性。与RDBMS 相比hbase可以存储海量数据,而且检索速度可以达到准实时,最迟是秒级别。
打架hbase集群至少需要三个框架Hbase,zookeeper,HDFS。三个环节任意一个环节出问题将导致hbase集群不可用。
hbase是列式存储数据库,即nosql数据库,列数据可以十多版本的。
Cell:{rowkey + cf + column + version(timestamp)} : value
table,分为多个region,region按照rowKey进行管理,[startRowKey,stopRowKey),四个key分为5个Region。不在范围内的便于插入region头和尾部。
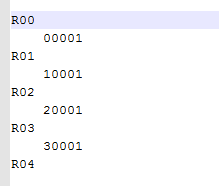
在默认的情况下,创建一个表时,会给一个表创建一个Region
2,hbase架构
1,hbase结构图
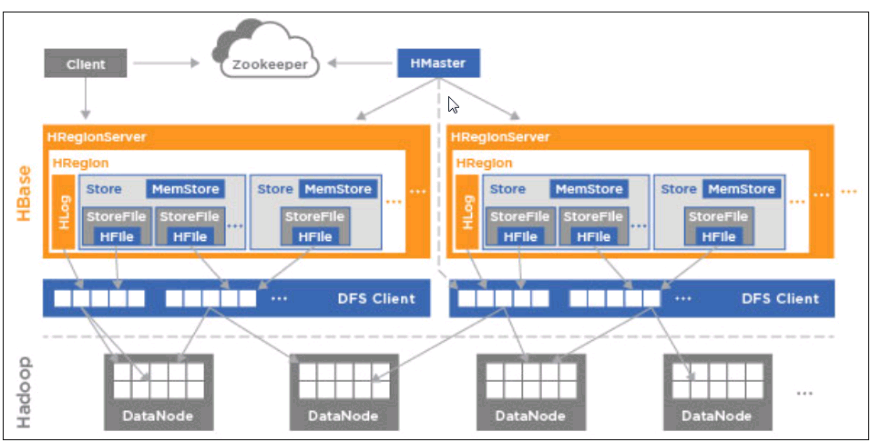
hbase客户端存储和检索数据直接是通过zookeeper来实现的。依据rowkey在zookeeper上找到对应的region,然后根据region通过zookeeper找到对应的regionserver,这个过程并没有经过Hmaster。最后找到regionserver去检索数据。
2,HBase 写数据
client 会先写入 hlog 文件(WAL:Write Head Log) 再写入memStore(Memroy)达到一定阈值的时候flush到StoreFile。这样可以保证数据完整性。
3,hbase数据存储
hbase中所有数据文件都存储在hadoopHDFS文件系统上,主要包括两种文件类型:
1,HFile:hbase中kevalue数据的存储格式,HFile是hadoop的二进制格式文件,实际上StoreFile就是对HFile做了轻量级的包装,进行数据存储。
2,HLogFile:hbase中WAL(Write Ahead Log)的存储格式,物理上是Hadoop的SequenceFile。
4,HRegion Server
1,HRegionServer内部管理了一系列HRegion对象,每个HRegion对应了tables中的一个region,HRegion中由多个HStroe组成。每个HStore对应于Table中的一个column family的存储,可以看出每个columnfamily其实就是一个集中的存储单元,因此最好将具备共同IO特性的column放在一个columnfamily中,这样最高效。
2,HStore存储是Hbase存储的核心,由两部分组成,一部分是MemStore,一部分是StoreFile。MemStore是Sorted Memory Buffer,用户写入的数据首先会放入Memstore,当MemsTore满了以后会flush成一个storeFile(底层是现实HFile)。
5,MemStore&storeFile
1,用户写入数据流程
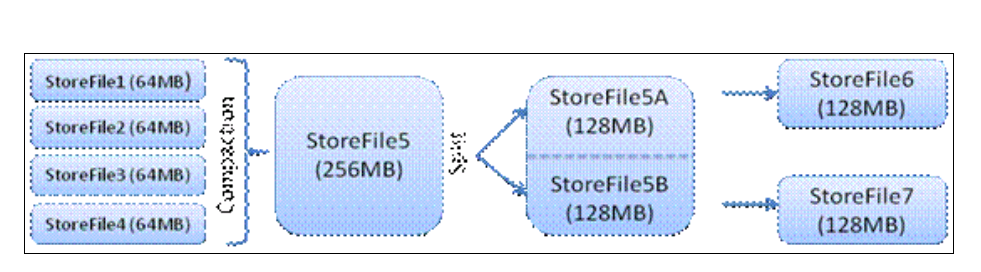
2,Client写入数据首先写入到MemStore,一直到MemStore
满,就会flush成一个StoreFile,直至增长到一定阈值,就会触发Compact合并操作,多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除,当StoreFilesCompact后,逐步形成越来越大的StoreFile,单个StoreFile大小超过一定阈值之后,触发Split操作,把当前Regio Split成两个Region,父region会下线,新的split出的两个孩子region会被HMaste分配到相应的HRegionServer上,使得原先1个region的压力得以分流到2个region上。
3,HBase只是增加数据,有所得更新和删除操作,都是在Compact阶段做的,所以用户写操作只需要进入到内存即可立即返回,从而保证IO高性能。
6,HLog文件结构
1,WAL意为Write ahead log,类似Mysql中的binlog,用来做灾难恢复。Hlog记录数据的所有变更,一旦数据修改,就可以从log中进行数据恢复。每个HRegionServer维护一个HLog而不是一个Hregion一个。这样不同region(来自不同tables)的日志就会混在一起,这样做的目的是不断追加单个文件相对于同时写多个文件而言,可以减少按值寻址次数,因此可以提高对table的写性能,带来的麻烦事,如果一台HRegionServer下线,为恢复其上的region,需要将HRegionServer上的log进行拆分,然后分发到其他hregionServer上进行数据恢复。
3,深入hbase架构
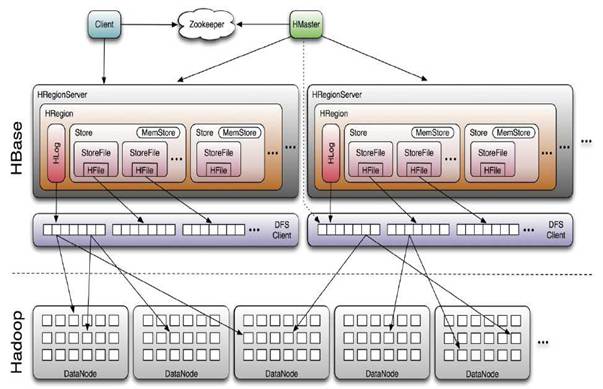
1,client
1,整个hbase集群访问入口;
2,使用HBase RPC机制与HMaster和HRegionServer进行通信;
3,与HMaster进行通信管理类操作
4,与HRegionServer进行数据读写操作
5,包含访问HBase的接口,并维护cache来加快对HRegion的访问。
2,zookeeper
1,保证任何时候,集群中只有一个HMaster
2,存储所有HRegion的寻址入口;
3,实时监控HRegionServer的上线和下线信息,并实时通知给HMaster;
4,存储HBase的schema和table元数据;
5,zookeeper Quorum存储-ROOT-表地址、HMaster地址
3,HMaster
1,HMaster没有单点问题,HBase中可以启动多个HMaster,通过zookeeper的Master Election机制保证总有一个Master在运行主要负责Table和Region的管理工作。
2,管理用户对table的增删改查操作;
3,管理HRegionServer的负载均衡,调整Region分布;
4,RegionSplit后,负责新Region的分布;
5,在HRegionServer停机后,负责将失效HRegionServer上Region迁移工作。
4,HRegionServer
1,维护HRegion,处理对这些HRegion的IO请求,向HDFS文件系统中读写数据;
2,负责切分在运行过程中变得过大的HRegion
3,Client访问HBase上数据的过程并不需要master参与(寻址访问zookeeper和HRegionServer,数据读写访问HRegionServer),HMaster仅仅维护者table和Region的元数据信息,负载很低。
5,HBase & zookeeper
1,HBase依赖zookeeper;
2,默认情况下,HBase管理zookeeper实例,比如,启动或者停止zookeeper;
3,HMaster与RegionServers启动时会向zookeeper注册;
4,zookeeper的引入使得HMaster不再是单点故障。
4,hbase的eclipse编程环境搭建
首先在pom.xml文件中添加如下内容
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><hbase.version>0.98.6-hadoop2</hbase.version></properties><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>${hbase.version}</version></dependency>
然后再resource目录下添加
hbase-site.xml文件
5,JAVA API的使用
1,hbase表的java api基本使用
package hbase.learn.com;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.Cell;import org.apache.hadoop.hbase.CellUtil;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.client.Delete;import org.apache.hadoop.hbase.client.Get;import org.apache.hadoop.hbase.client.HTable;import org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.client.Result;import org.apache.hadoop.hbase.client.ResultScanner;import org.apache.hadoop.hbase.client.Scan;import org.apache.hadoop.hbase.util.Bytes;import org.apache.hadoop.io.IOUtils;public class hbaseJAVAAPI {public static HTable getHTableByTableName(String tableName) //throws Exception {// Get instance of ConfigurationConfiguration configuration = HBaseConfiguration.create();// Get table instanceHTable table = new HTable(configuration, tableName);System.out.println(table);return table;}/** Get Data From Table By Rowkey*/public void getData()throws Exception {String tableName = "user";// Get table instanceHTable table = getHTableByTableName(tableName);// Create Get with rowkeyGet get = new Get(Bytes.toBytes("1001")) ;//=======================================get.addColumn(//Bytes.toBytes("info"),//Bytes.toBytes("age")//);//=======================================// Get DataResult result = table.get(get) ;// System.out.println(result);/*** Key:* rowkey + cf + c + version** Value :* value*/for(Cell cell : result.rawCells()){System.out.println(Bytes.toString(CellUtil.cloneRow(cell)));System.out.println(//Bytes.toString(CellUtil.cloneFamily(cell))+ ":" //+ Bytes.toString(CellUtil.cloneQualifier(cell)) //+ " -> " //+ Bytes.toString(CellUtil.cloneValue(cell)) //+ " " //+ cell.getTimestamp());System.out.println("--------------------------------");}// closetable.close();}/*** Put Data into Table* @throws Exception** Map<String,Object>**/public void putData() throws Exception {String tableName = "user";// Get table instanceHTable table = getHTableByTableName(tableName);// create put instancePut put = new Put(Bytes.toBytes("1001")) ;// Add a column with valueput.add(//Bytes.toBytes("info"), //Bytes.toBytes("sex"), //Bytes.toBytes("male") //) ;put.add(//Bytes.toBytes("info"), //Bytes.toBytes("tel"), //Bytes.toBytes("010-876523423") //) ;put.add(//Bytes.toBytes("info"), //Bytes.toBytes("address"), //Bytes.toBytes("beijing") //) ;/*Map<String,Object> kvs = new HashMap<String,Object>() ;for(String key : kvs.keySet()){put.add(//HBaseTableConstant.HBASE_TABLE_USER_CF, //Bytes.toBytes(key), //Bytes.toBytes(kvs.get(key)) //) ;}*/// put data into tabletable.put(put);// closetable.close();}public void deleteData() throws Exception {String tableName = "user";// Get table instanceHTable table = getHTableByTableName(tableName);Delete delete = new Delete (Bytes.toBytes("1001")) ;delete.deleteFamily(Bytes.toBytes("info")) ;// delete.deleteColumn(//// Bytes.toBytes("info"), //// Bytes.toBytes("sex") //// ) ;// delete.deleteColumns(family, qualifier) ;// delete datatable.delete(delete);// closetable.close();}public void scanData()throws Exception {String tableName = "user";// Get table instanceHTable table = null;ResultScanner resultScanner = null ;try{table = getHTableByTableName(tableName);Scan scan = new Scan() ;//===========================================================//Range// scan.setStartRow(startRow);// scan.setStopRow(stopRow) ;//Scan// Scan scan2 = new Scan(startRow,stopRow) ;//add Column// scan.addColumn(family, qualifier) ;// scan.addFamily(family) ;//Filter// Filter filter = new PrefixFilter(prefix) ;// scan.setFilter(filter) ;// page// PageFilter//Cache// scan.setCacheBlocks(cacheBlocks);// scan.setCaching(caching);//===========================================================resultScanner = table.getScanner(scan) ;// iteratorfor(Result result : resultScanner){for(Cell cell : result.rawCells()){System.out.println(Bytes.toString(CellUtil.cloneRow(cell)));System.out.println(//Bytes.toString(CellUtil.cloneFamily(cell))+ ":" //+ Bytes.toString(CellUtil.cloneQualifier(cell)) //+ " -> " //+ Bytes.toString(CellUtil.cloneValue(cell)) //+ " " //+ cell.getTimestamp());}System.out.println("##################################");}}catch(Exception e ){e.printStackTrace();}finally {IOUtils.closeStream(resultScanner);IOUtils.closeStream(table);}}public static void main(String[] args) throws Exception {hbaseJAVAAPI hbase=new hbaseJAVAAPI();System.out.println("==================get table name===================");hbase.getHTableByTableName("user");System.out.println("==================put data===================");hbase.putData();System.out.println("==================get data===================");hbase.getData();System.out.println("==================scan data===================");hbase.scanData();System.out.println("==================delete data===================");hbase.deleteData();System.out.println("==================scan data===================");hbase.scanData();}}
2,输出结果如下
==================get table name=====================================put data===================user;hconnection-0x3be33bad==================get data===================user;hconnection-0x3be33bad1001info:age -> 18 1451913054898--------------------------------==================scan data===================user;hconnection-0x3be33bad10001info:address -> beijing 145191470688010001info:sex -> male 145191470688010001info:tel -> 010-876523423 1451914706880##################################1001info:address -> beijing 14519151825231001info:age -> 18 14519130548981001info:name -> lisi 14519130490371001info:sex -> male 14519151825231001info:tel -> 010-876523423 1451915182523##################################==================delete data===================user;hconnection-0x3be33bad==================scan data===================user;hconnection-0x3be33bad10001info:address -> beijing 145191470688010001info:sex -> male 145191470688010001info:tel -> 010-876523423 1451914706880##################################
6,hbase和mapreduce
1,代码实现
package hbase.learn.com;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.conf.Configured;import org.apache.hadoop.hbase.Cell;import org.apache.hadoop.hbase.CellUtil;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.client.Result;import org.apache.hadoop.hbase.client.Scan;import org.apache.hadoop.hbase.io.ImmutableBytesWritable;import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;import org.apache.hadoop.hbase.mapreduce.TableMapper;import org.apache.hadoop.hbase.mapreduce.TableReducer;import org.apache.hadoop.hbase.util.Bytes;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.util.Tool;import org.apache.hadoop.util.ToolRunner;public class User2BasicMapReduce extends Configured implements Tool {// step 1 : Mapper/*** Mapper<ImmutableBytesWritable, Result, KEYOUT, VALUEOUT>*/public static class ReadUserMapper extends //TableMapper<Text, Put> {private Text mapOutputKey = new Text();@Overrideprotected void map(ImmutableBytesWritable key, Result value, Context context)throws IOException, InterruptedException {// get rowkeyString rowkey = Bytes.toString(key.get());// set map output keymapOutputKey.set(rowkey);// ==============================================================// create PutPut put = new Put(key.get());// iteratorfor (Cell cell : value.rawCells()) {// add family : infoif ("info".equals(Bytes.toString(CellUtil.cloneFamily(cell)))) {// add column : nameif ("name".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))) {put.add(cell);}// add column : ageelse if ("age".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))) {put.add(cell);}}}// context writecontext.write(mapOutputKey, put);}}// step 2: Reducer/*** Reducer<KEYIN, VALUEIN, KEYOUT, Mutation>*/public static class WriteBasicReducer extends //TableReducer<Text, Put, ImmutableBytesWritable> {@Overrideprotected void reduce(Text key, Iterable<Put> values, Context context)throws IOException, InterruptedException {for(Put put : values){context.write(null, put);}}}// step 3: Driverpublic int run(String[] args) throws Exception {// 1) configurationConfiguration conf = this.getConf();// 2) create jobJob job = Job.getInstance(conf, //this.getClass().getSimpleName());job.setJarByClass(User2BasicMapReduce.class); // class that contains// mapper and reducer// 3) set jobScan scan = new Scan();scan.setCaching(500); // 1 is the default in Scan, which will be bad for// MapReduce jobsscan.setCacheBlocks(false); // don't set to true for MR jobs// set other scan attrsTableMapReduceUtil.initTableMapperJob(//"user", // input tablescan, // Scan instance to control CF and attribute selectionReadUserMapper.class, // mapper classText.class, // mapper output keyPut.class, // mapper output valuejob //);TableMapReduceUtil.initTableReducerJob(//"basic", // output tableWriteBasicReducer.class, // reducer classjob //);job.setNumReduceTasks(1); // at least one, adjust as requiredboolean b = job.waitForCompletion(true);if (!b) {throw new IOException("error with job!");}return b ? 0 : 1;}public static void main(String[] args) throws Exception {// get configurationConfiguration configuration = HBaseConfiguration.create();// run jobint status = ToolRunner.run(//configuration, //new User2BasicMapReduce(), //args //);// exit programSystem.exit(status);}}
2,导出jar包并运行
export HBASE_HOME=/opt/modules/hbase-0.98.6-hadoop2export HADOOP_HOME=/opt/modules/hadoop-2.5.0HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` $HADOOP_HOME/bin/yarn jar /opt/tools/User2BasicMapReduce.jar
执行成功后
3,出现的错误及解决方法
经追查源码查到在Put时,虽然实例化了正确的Put,但是Put中没有KeyValue值,表现出来的状况就是在Put的familyMap中没有任何的值,根本原因还是数据有问题,但从此问题中可以看到,如果一个Put中没有任何的value那么是不会被放入HBase中的。当然这可能也和HBase存储数据的方式有关,在RDBMS中我们可以存储类似“id01,null,null”的数据,但在HBase中,值为空的数据是不会被存储的。put使用的时候,假如为空就会报如下错误。
因为数据中不存在age列。
^C16/01/04 23:38:19 INFO mapreduce.Job: Task Id : attempt_1451912421695_0002_r_000000_2, Status : FAILEDError: java.lang.IllegalArgumentException: No columns to insertat org.apache.hadoop.hbase.client.HTable.validatePut(HTable.java:1304)at org.apache.hadoop.hbase.client.HTable.doPut(HTable.java:941)at org.apache.hadoop.hbase.client.HTable.put(HTable.java:908)at org.apache.hadoop.hbase.mapreduce.TableOutputFormat$TableRecordWriter.write(TableOutputFormat.java:126)at org.apache.hadoop.hbase.mapreduce.TableOutputFormat$TableRecordWriter.write(TableOutputFormat.java:87)at org.apache.hadoop.mapred.ReduceTask$NewTrackingRecordWriter.write(ReduceTask.java:558)at org.apache.hadoop.mapreduce.task.TaskInputOutputContextImpl.write(TaskInputOutputContextImpl.java:89)at org.apache.hadoop.mapreduce.lib.reduce.WrappedReducer$Context.write(WrappedReducer.java:105)at hbase.learn.com.User2BasicMapReduce$WriteBasicReducer.reduce(User2BasicMapReduce.java:77)at hbase.learn.com.User2BasicMapReduce$WriteBasicReducer.reduce(User2BasicMapReduce.java:1)at org.apache.hadoop.mapreduce.Reducer.run(Reducer.java:171)at org.apache.hadoop.mapred.ReduceTask.runNewReducer(ReduceTask.java:627)at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:389)at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:168)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:415)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1614)at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:163)
7,importtsv导入数据
1,创建表student
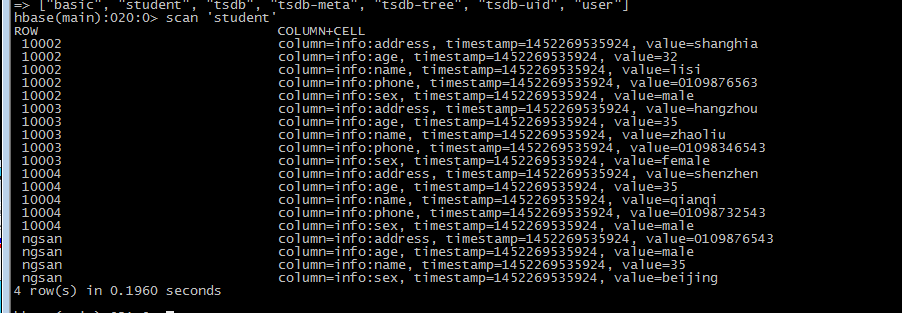
create 'student','info'
2,创建目录并上传数据
/opt/modules/hadoop-2.5.0/bin/hdfs dfs -put /opt/datas/importtsv.tsv /user/hadoop/hbase/importtsv/input
3,创建importtsv.sh脚本
#!/bin/shexport HBASE_HOME=/opt/modules/hbase-0.98.6-hadoop2export HADOOP_HOME=/opt/modules/hadoop-2.5.0HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` \$HADOOP_HOME/bin/yarn jar \$HBASE_HOME/lib/hbase-server-0.98.6-hadoop2.jar \importtsv \-Dimporttsv.columns=HBASE_ROW_KEY,\info:name,info:age,info:sex,info:address,info:phone \student \hdfs://miaodonghua1.host:8020/user/hadoop/hbase/importtsv/input
4,执行脚本
./importtsv.sh
执行成功后

8,completebulkload导入数据
1,创建hfile-importtsv.sh脚本
输入如下内容
#/bin/shexport HBASE_HOME=/opt/modules/hbase-0.98.6-hadoop2export HADOOP_HOME=/opt/modules/hadoop-2.5.0HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` \$HADOOP_HOME/bin/yarn jar \$HBASE_HOME/lib/hbase-server-0.98.6-hadoop2.jar \importtsv \-Dimporttsv.columns=HBASE_ROW_KEY,\info:name,info:age,info:sex,info:address,info:phone \-Dimporttsv.bulk.output=hdfs://miaodonghua1.host:8020/user/hadoop/hbase/importtsv/hfileoutput \student \hdfs://miaodonghua1.host:8020/user/hadoop/hbase/importtsv/input
2,执行脚本生成HFile文件
./hfile-importtsv.sh
执行成功后
3,HFile数据导入到hbase
HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` $HADOOP_HOME/bin/yarn jar \ $HBASE_HOME/lib/hbase-server-0.98.6-hadoop2.jar \ completebulkload \ /user/hadoop/hbase/importtsv/hfileoutput/ student
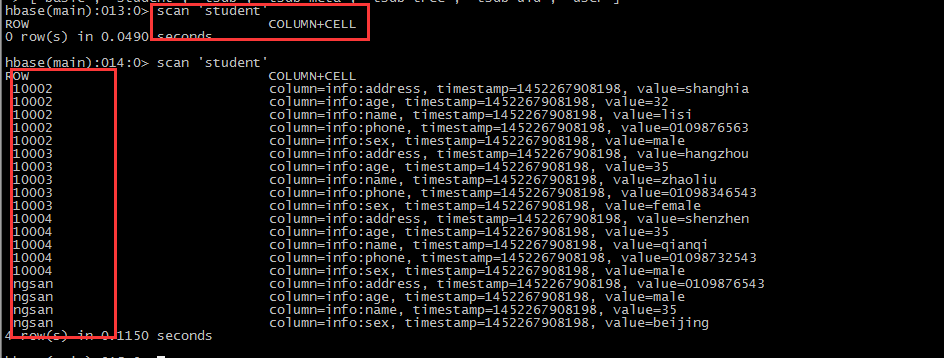
9,指定导入数据分割方式
1,创建csv-hfile-importtsv.sh
#/bin/shexport HBASE_HOME=/opt/modules/hbase-0.98.6-hadoop2export HADOOP_HOME=/opt/modules/hadoop-2.5.0HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` \$HADOOP_HOME/bin/yarn jar \$HBASE_HOME/lib/hbase-server-0.98.6-hadoop2.jar \importtsv \-Dimporttsv.columns=HBASE_ROW_KEY,\info:name,info:age,info:sex,info:address,info:phone \-Dimporttsv.bulk.output=hdfs://miaodonghua1.host:8020/user/hadoop/hbase/importtsv/csvhfileoutput \-Dimporttsv.separator=, \student \hdfs://miaodonghua1.host:8020/user/hadoop/hbase/importtsv/input
2,执行脚本
./csv-hfile-importtsv.sh
hfile数据生成成功
3,导入数据到hbase
HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` $HADOOP_HOME/bin/yarn jar \ $HBASE_HOME/lib/hbase-server-0.98.6-hadoop2.jar \completebulkload \/user/hadoop/hbase/importtsv/csvhfileoutput/ student
数据导入成功