@yangfch3
2015-09-10T05:57:43.000000Z
字数 3263
阅读 3592
字符编码
coder科普
字符编码
你是否认为 ASCII 码就是一个字符,一个字节就是一个字符,一个字符就是 8 比特?你是否认为 UTF-8 就是用 8 比特表示一个字符?如果真的是这样认为这篇文章就很适合你。
为什么要有编码?
首先大家需要明确的是在计算机里所有的数据都是字节的形式存储和处理的。我们需要用字节来表示计算机里的信息,但是这些字节本身又是没有任何意义的。我们需要对这些字节赋予实际的意义,制定各种编码标准。
编码模型
首先需要知道的是存在两种编码模型
简单字符集
在这种编码模型里,一个字符集定义了这个字符集里包含什么字符,同时把每个字符如何对应成计算机里的比特也进行了定义。例如 ASCII,在 ASCII 里直接定义了 A -> 0100 0001。
现代编码模型
在现代编码模型里要知道一个字符如何映射成计算机里比特,需要经过如下几个步骤:
- 知道一个系统需要支持哪些字符,这些字符的集合被称为
字符表(Character repertoire) - 给字符表里的抽象字符编上一个数字,也就是字符集合到一个整数集合的映射。这种映射称为编码字符集(
CCS:Coded Character Set),unicode是属于这一层的概念,unicode跟计算机里的什么进制啊没有任何关系,它是完全数学的抽象的。 - 将
CCS里字符对应的整数转换成有限长度的比特值,便于以后计算机使用一定长度的二进制形式表示该整数。这个对应关系被称为字符编码表(CEF:Character Encoding Form)UTF-8,UTF-16都属于这层。 - 对于
CEF得到的比特值具体如何在计算机中进行存储,传输。因为存在大端小端的问题,这就会跟具体的操作系统相关了。这种解决方案称为字符编码方案(CES:Character Encoding Scheme)。
平常我们所说的编码都在第三步的时候完成了,并没有涉及到 CES。所以 CES 并不在本文的讨论范围之内。
现在也许有人会想为什么要有现代的编码模型?为什么在现在的编码模型要拆分出这么多概念?直接像原始的编码模型直接都规定好所有的信息不行吗?这些问题在下文的编码发展史中都会有所阐述。
编码的发展史
ASCII
ASCII 出现在上个世纪 60 年代的美国,ASCII 一共定义了 128 个字符,使用了一个字节的 7 位。定义的这些字符包括英文字母 A-Z,a-z,数字 0-9,一些标点符号和控制符号。在 Shell 里输入man ASCII,可以看到完整的 ASCII 字符集。ASCII 采用的编码模型是简单字符集,它直接定义了一个字符的比特值表示。里例如上文提到的A -> 0100 0001。也就是 ASCII 直接完成了现代编码模型的前三步工作。
在英语系国家里 ASCII 标准很完美。但是不要忘了世界上可有好几千种语言,这些语言里不仅只有这些符号啊。如果使用这些语言的人也想使用计算机,ASCII 就远远不够了。所以到这里编码进入了混乱的时代。
混乱时代
人们知道计算机的一个字节是 8 位,可以表示 256 个字符。ASCII 却只使用了 7 位,所以人们决定把剩余的一位也利用起来。这时问题出现了,人们对于已经规定好的128个字符是没有异议的,但是不同语系的人对于其他字符的需求是不一样的,所以对于剩下的128个字符的扩展会千奇百怪。而且更加混乱的是,在亚洲的语言系统中有更多的字符,一个字节无论如何也满足不了需求了。例如仅汉字就有10万多个,一个字节的256表示方式怎么能够满足呢。于是就又产生了各种多字节的表示一个字符方法(gbk就是其中一种),这就使整个局面更加的混乱不堪。(希望看到这里的你不再认为一个字节就是一个字符,一个字符就是8比特:因为根本表示不够)。每个语系都有自己特定的编码页(code pages)的状况,使得不同的语言出现在同一台计算机上,不同语系的人在网络上进行交流都成了痴人说梦。这时 Unicode 出现了。
Unicode
Unicode就是给计算机中所有的字符各自分配一个代号。Unicode通俗来说是什么呢?就是现在实现共产主义了,各国人民不在需要自己特定的国家身份证,而是给每人一张全世界通用的身份证。Unicode是属于编码字符集(CCS)的范围。Unicode所做的事情就是将我们需要表示的字符表中的每个字符映射成一个数字,这个数字被称为相应字符的码点(code point)。例如“严”字在Unicode中对应的码点是U+0x4E25。
到目前为止,我们只是找到了一堆字符和数字之间的映射关系而已,只到了CCS的层次。这些数字如何在计算机和网络中存储和展示还没有提到。
字符编码
前面还都属于字符集的概念,现在终于到CEF的层次了。为了便于计算的存储和处理,现在我们要把那些纯数学数字对应成有限长度的比特值了。最直观的设计当然是一个字符的码点是什么数字,我们就把这个数字转换成相应的二进制表示,例如“严”在Unicode中对应的数字是0x4E25,他的二进制是100 1110 0010 0101,也就是严这个字需要两个字节进行存储。
按照这种方法大部分汉字都可以用两个字节来表示了。但是还有其他语系的存在,没准儿他们所使用的字符用这种方法转换就需要4个字节。这样问题又来了到底该使用几个字节表示一个字符呢?如果规定两个字节,有的字符会表示不出来,如果规定较多的字节表示一个字符,很多人又不答应,因为本来有些语言的字符两个字节处理就可以了,凭什么用更多的字节表示,多么浪费。
这时就会想可不可以用变长的字节来存储一个字符呢?如果使用了变长的字节表示一个字符,那就必须要知道是几个字节表示了一个字符,要不然计算机可没那么聪明。下面介绍一下最常用的UTF-8(UTF是Unicode Transformation Format的缩写)的设计。请看下图(来自阮一峰的博客)
x表示可用的位
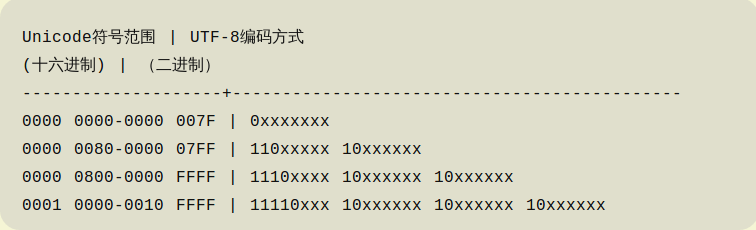
通过UTF-8的对应关系可以把每个字符在Unicode中对应的码点,转换成相应的计算机的二进制表示。可以发现按照UTF-8进行转换是完全兼容原先的ASCII的;而且在多字节表示一个字符时,开头有几个1就表示这个字符按照UTF-8转换后由几个字节表示。下面一个实例子来自阮一峰的博客
已知“严”的unicode是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800-0000 FFFF),因此“严”的UTF-8编码需要三个字节,即格式是“1110xxxx 10xxxxxx 10xxxxxx”。然后,从“严”的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,“严”的UTF-8编码是“11100100 10111000 10100101”,转换成十六进制就是0xE4B8A5。
除了UTF-8这种转换方法,还存在UTF-16,UTF-32等等转换方法。这里就不再多做介绍。(注意UTF后边的数字代表的是码元的大小。码元(Code Unit)是指一个已编码的文本中具有最短的比特组合的单元。对于UTF-8来说,码元是8比特长;对于UTF-16来说,码元是16比特长。换一种说法就是UTF-8的是以一个字节为最小单位的,UTF-16是以两个字节为最小单位的。)
结束语
花了两天时间终于写完了,相信看到这里大家对于字符编码有了较为清楚的认识,当然文章中肯定存在不准确之处,希望大家批评指正。
邮箱:acmerfight圈gmail.com
原文地址
参考资料
字符编码
The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
字符编码笔记:ASCII,Unicode和UTF-8
字符集和字符编码
Windows 记事本的 ANSI、Unicode、UTF-8 这三种编码模式有什么区别?
如何向非技术人员解释 Unicode 是什么
字符编解码的故事(ASCII,ANSI,Unicode,Utf-8)
