@zhoujj2013
2017-07-08T15:16:13.000000Z
字数 1454
阅读 1022
A001测序数据质量控制
service
1. 测序数据质量分布
如果测序错误率用e表示, Illumina HiSeq 2000/Miseq的碱基质量值用表示,则有:。Illumina Casava 1.8版本碱基识别与Phred分值之间的简明对应关系见下表:
| Phred分值 | 不正确的碱基识别 | 碱基正确识别率 | Q-score |
|---|---|---|---|
| 10 | 1/10 | 90% | Q10 |
| 20 | 1/100 | 99% | Q20 |
| 30 | 1/1000 | 99.9% | Q30 |
| 40 | 1/10000 | 99.99% | Q40 |
对于第二代测序技术,测序错误率分布具有两个特点,具体见图 1:
(1) 测序错误率会随着测序序列(Sequenced Reads)的长度的增加而升高,这是由于测序过程中化学试剂的消耗而导致的,并且为Illumina高通量测序平台都具有的特征。
(2) 前6个碱基的位置也会发生较高的测序错误率,而这个长度也正好等于在RNA-seq建库过程中反转录所需要的随机引物的 长度。所以推测这部分碱基的测序错误率较高的原因为随机引物和RNA模版的不完全结合所致。一般情况下,单个碱基位置的测序错误率应该低于1%。(只适用于RNAseq)
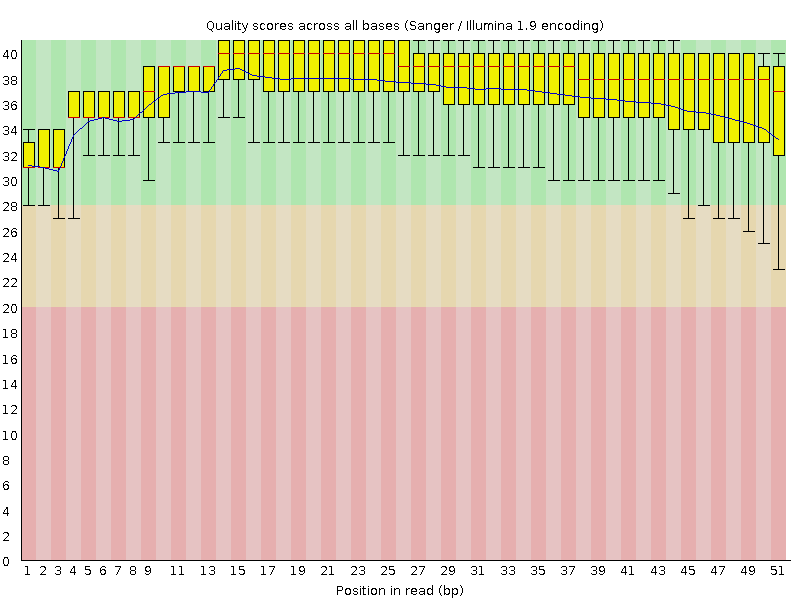
图1 测序错误率分布图
横坐标为reads的碱基位置, 纵坐标为单碱基错误率
2. clean fastq统计数据
样品测序产出数据质量评估情况详见表1。
表1 数据产出质量情况一览表
| Sample | Raw Reads | Clean Paired reads | Clean reads | Filtered reads | Clean reads(%) | GC(%) |
|---|---|---|---|---|---|---|
| Con_1 | 7448520 | NA | 7425666 | 22854 | 31 | 36 |
| Con_2 | 7448520 | NA | 7425666 | 22854 | 31 | 36 |
Sample: 样品名。
Raw reads: 统计原始序列数据,以四行为一个单位,统计每个文件的测序序列的个数。
Clean Paired reads: 达到质量标准的Paried-end测序片段。
Clean reads: 计算方法同 Raw Reads, 只是统计的文件为过滤后的测序数据。后续的生物信息分析都是基于Clean reads。
Filtered reads: 未能达到质量标准的测序序列个数。
Clean reads (%): 达到质量标准测序数据的百分比。
GC content: 计算碱基G和C的数量总和占总的碱基数量的百分比。
3. 重复reads统计 (DNA会省去此部分,例如:ChIP-seq, Exome-seq, 重测序)
样品测序产出数据重复测序片段评估情况详见表2。
表2 重复测序片段情况一览表
| Sample | Clean reads | Dup. reads | Uniq. reads | Dup. rate(%) |
|---|---|---|---|---|
| Con_1 | 7448520 | 1425666 | 6022854 | 19.1 |
| Con_2 | 7448520 | 1425666 | 6022854 | 19.1 |
Sample: 样品名。
Clean reads: 统计质量过滤后序列数据, 以四行为一个单位,统计每个文件的测序序列的个数。
Dup. reads: 在测序数据中的,来自PCR及测序过程optical的重复序列,这部分序列是人工造成的,不会用到后续分析。
Uniq. reads: 在测序文库中,序列唯一的测序序列个数。
Dup. rate (%): PCR及测序过程optical的重复序列占总序列的百分比。
注意:对于双端测序(paired-end sequencing),此分析只包含过滤后双端符合质量要求的数据。
4. 分析方法
分析方法包括3部分:方法描述(中文版),方法描述(英文版)和引用文献。这部分会正式数据分析报告提供。
