@zhoujj2013
2017-09-14T05:16:49.000000Z
字数 1426
阅读 1158
G008 Weighted Gene Co-expression Network Analysis (WGCNA)加权基因网络表达分析
service
基因表达列表
加权基因网络表达分析需要多个样品的数据,从而对基因在多样品中的表达规律进行总结,所以对样品数有一定的要求(>10)。
多样品表达列表如下:
| 基因id | 样品1 | 样品2 | ... | 样品N |
|---|---|---|---|---|
| Myod1 | 20 | 50 | ... | 80 |
| Myog | 5 | 70 | ... | 130 |
| ... | ... | ... | ... | ... |
加权基因网络构建
此部分包括两步:
- 基因表达数据过滤。满足以下条件的基因或样品会被过滤:a. 所有样品中表达量为零的基因; b. 一个样品中>50%的基因表达量为零;c. 数据标为NA的,会采用邻近法进行数据补足。
- 选择正确的参数进行加权网络构建;
数据过滤后,对每一个样品的基因表达普进行聚类,查看各个样品的差异性:
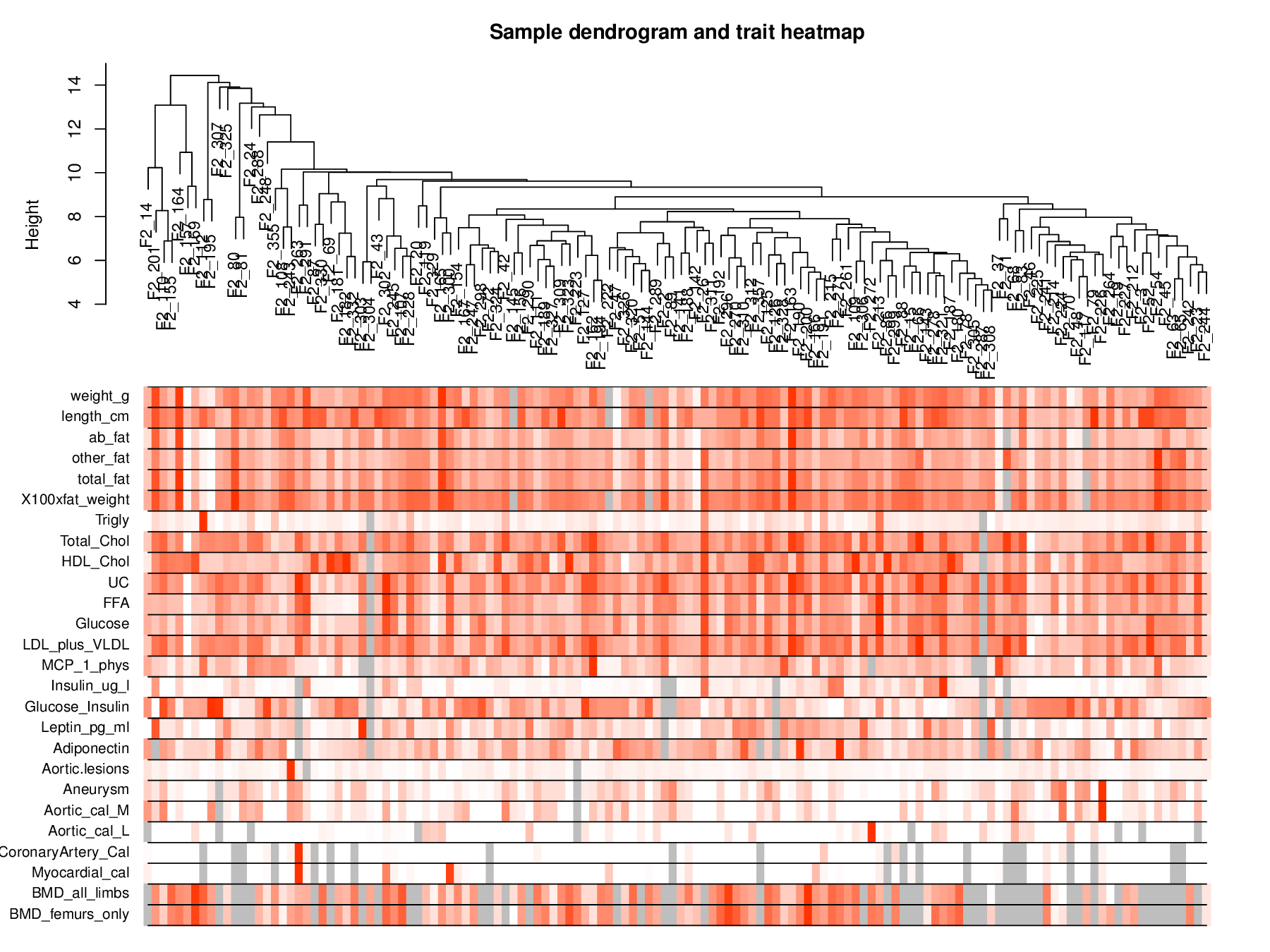
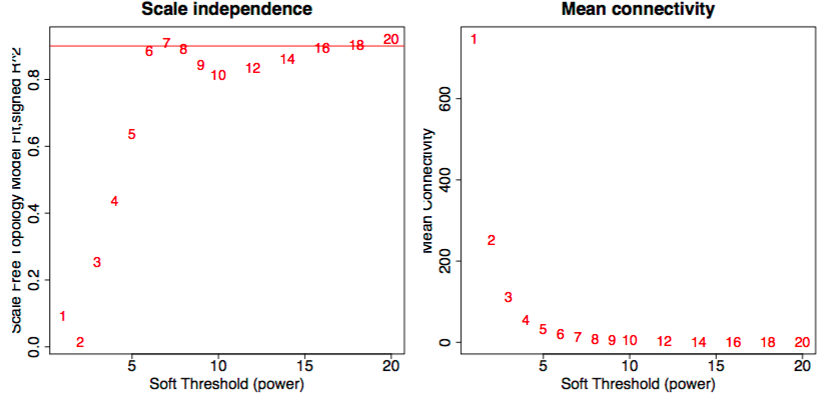
加权网络构建的参数图,当所构建的网络符合powerlaw分布的时候,参数最为合适;从右图中,可以看到选择不一样的参数,节点的度的平均数:
基因网络modular的检测
依据已经构建好的加权基因网络,用层次聚类算法对所有基因进行聚类,并计算每一个类对于每一个表型的关联重要性。
不同的颜色表示不一样的modular,聚类结果表示不同modular间的距离,检测结果如下图:
(加一个modular检测的图)

每一个modular对每一个表型的贡献是不一样的,通过分析加权网络聚类与表型的关联性,通过基因的共有性,可以计算modular与每一个表型间的关联显著性(p-value)。

基因网络module的功能注释
采用超几何检验对每一个modular的基因进行功能富集分析,用多重检验较正pvalue。
(加一个top5 modular的GO柱形图)
功能富集结果: gene_enrichment.xlsx
全局网络的heatmap和局部网络的heatmap
我们的网络分析采用两种方法对网络进行可视化:
- heatmap聚类分析图
- 网络图
通过heatmap聚类图可以查看整体网络,并查看相互关系紧密的基因modular。如下图所示,横轴和纵轴不同的颜色表示不同的modular,树型图表示不同的modular间的距离,图内的颜色越深表示相互作用越强。
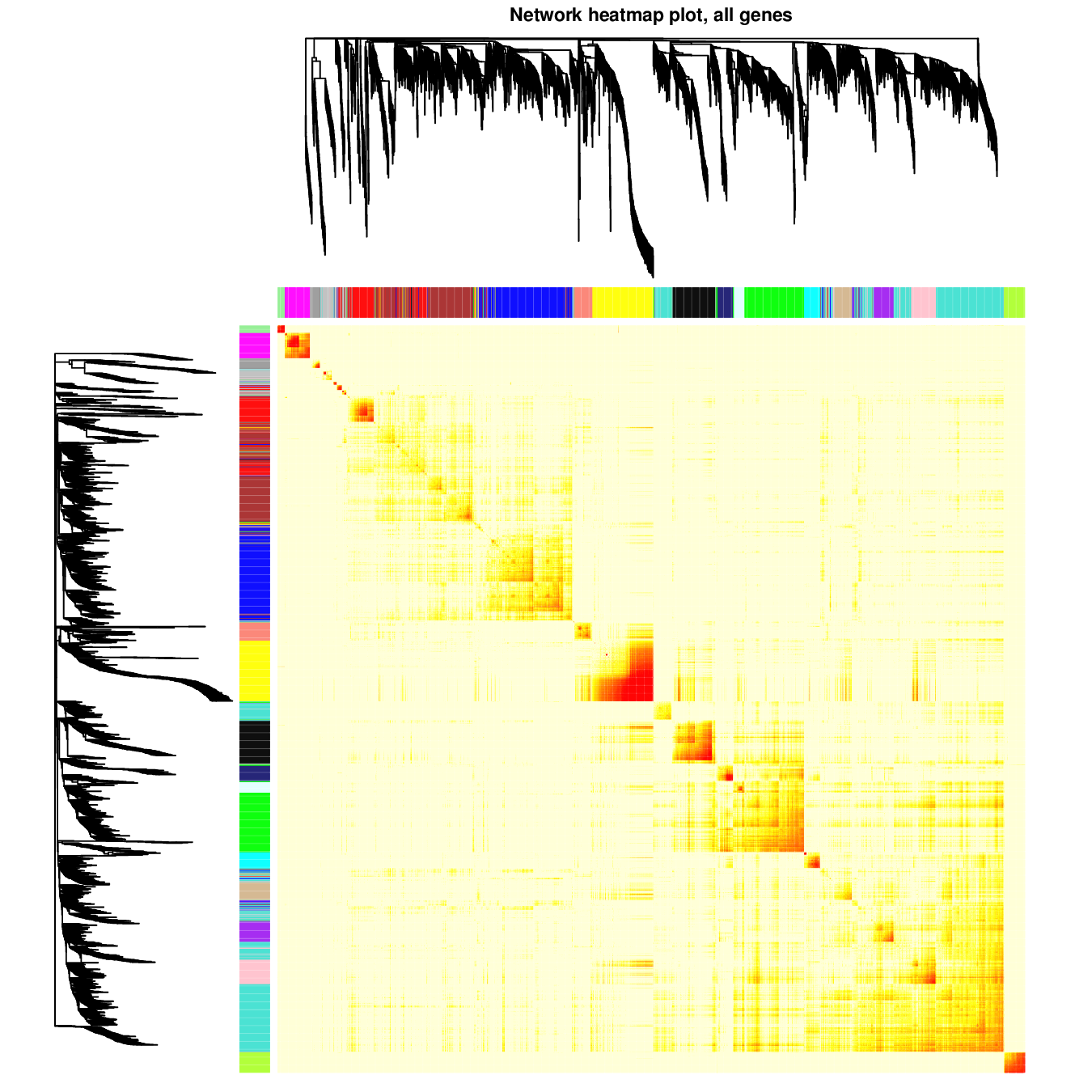
同样,对于每一个modular,我们可以进行同样的分析,一方面通过聚类图查看整体的相互作用,另一方面通过网络图直接查看相关基因的相互作用。
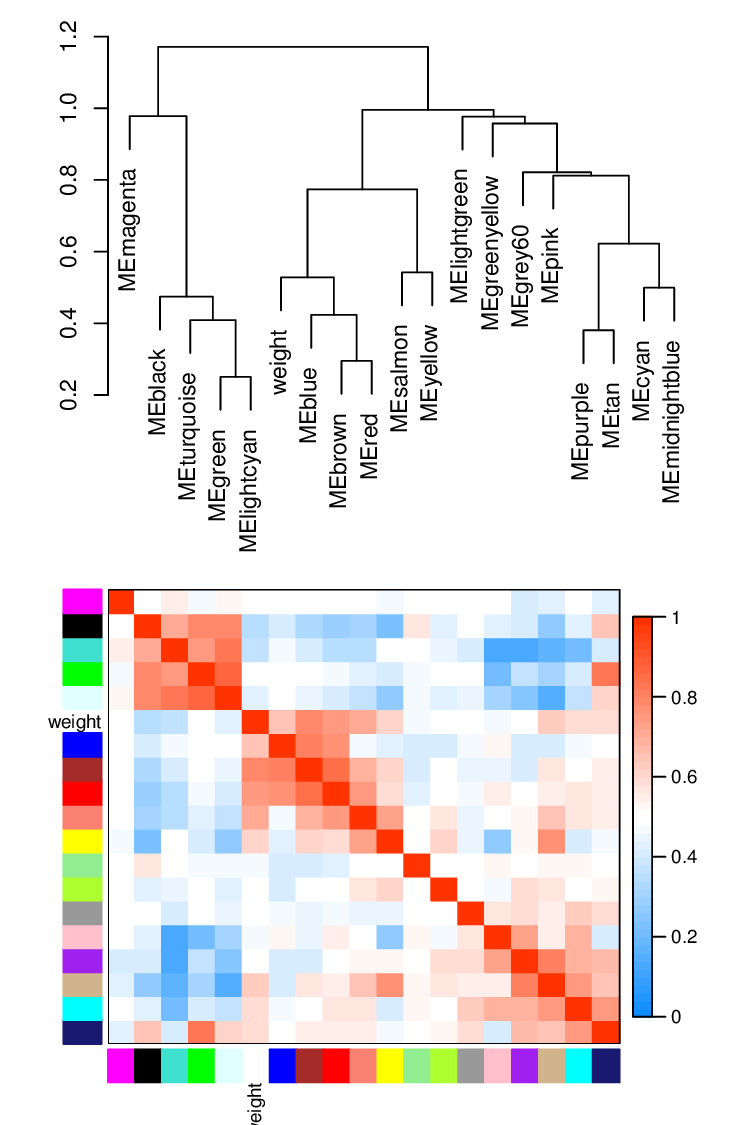
每一个modular对每一个表型的关系。
Cytoscape输出:
1.
2.
3.

参考文献
- Langfelder P, Horvath S (2008) WGCNA: an R package for weighted correlation network analysis. BMC Bioinformatics 2008, 9:559
- Miller JA, Cai C, Langfelder P, Geschwind DH, Kurian SM, Salomon DR, Horvath S (2011) Strategies for aggregating gene expression data: The collapseRows R function. BMC Bioinformatics 12:322.
- Storey JD and Tibshirani R. (2003) Statistical significance for genome-wide experiments. Proceedings of the National Academy of Sciences, 100: 9440-9445.
