@zhuanxu
2018-01-18T06:52:45.000000Z
字数 2005
阅读 3857
CTR 预估之 FM
点击率预估 CTR
回顾
之前用FM做过CTR预估,然后之前接触了一些推荐算法,没搞明白这推荐和CTR之间的区别。
给出网上的一些回答:
计算广告与推荐系统有哪些区别?
读完后的整体感受是:就推荐系统和CTR所属的计算广告来说,两者确实是不同的,是两个不同的具体业务,而就算法这块,两者是相通的。
下面介绍CTR中的经典算法FM(Factorization Machines 因式分解机)。
先来看一组数据,描述的是用户对电影的评分1-5
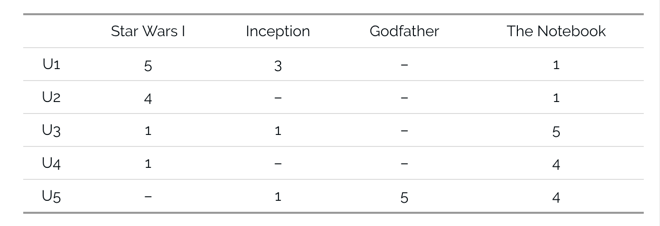
我们针对上面的这组数据,目标是预测出用户未做评价的电影,方法可以看我之前的文章隐语义模型(LFM),此处对于上面的做法,我们可以直接看推荐系统算法之 surprise 实战。
此处关于数据的更新,我们仔细来看下:
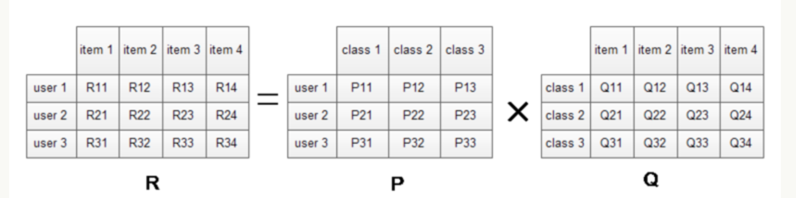
上图中,计算R11=P11*Q11+P12*Q21+P13*Q31,然后计算R11和真实值之间的误差,然后再根据这个误差去更新P11,Q11,P12,Q21,P13,Q31这6个参数,更新规则:
# k = 1 -> 3P[1][k] = P[1][k] + alpha * (2 * e11 * Q[k][3] - beta * P[1][k])Q[k][4] = Q[k][5] + alpha * (2 * e11 * P[1][k] - beta * Q[k][6])
从上面的式子我们就可以知道,要想更新 P11,P12,P13,则我们需要R1k的评分,即第一个用户的评分,那这个带来的问题就是如果某个用户的评分数据少,则其向量就会不准。
这就是冷启动问题:如果一个用户或者item没有任何的行为数据,我们根本无法对其进行预测。
FM
下面再来看一个广告点击的例子。
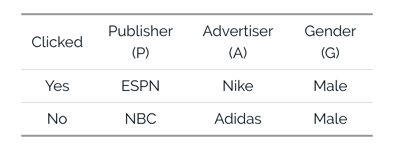
上面有3个特征列,每个特征都是Categorical类型,因此做法就是做one-hot,此处讲个小知识,为什么用one-hot,而不是直接编码1,2,3,4,5呢?为什么要做 one-hot
我们在面对 category 类型的变量的时候,一个常用的方法就是进行 one-hot encoding,但是为什么这么做呢?举个例子,假设有一列叫婚姻状态,可能值有:单身,已婚,离异。我们可以将其直接编码为 0,1,2,这样子的话,我们在一些计算距离的算法中,0 和 1 会比 0 和 2 离的更近,但其实 0,1,2 都是一样的,所有一个解决方法就是将婚姻状态这列转换为 3 列,每列都用 0,1 来表示是否是该值,这样子彼此之间的距离就一样了,保证了语义的一致性。
因此做完one-hot后,上面的输入特征就变为:

绝对是一个高维的稀疏向量,如果我们此时用LR模型来做,则预测如下:
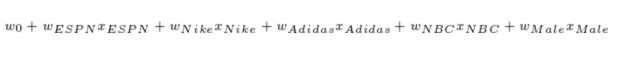
我们将权重w加上了特征名来更清晰的表示权重含义,此时如果想捕捉不同特征之间的联合关系,则要将两个特征一起作为输入,则有如下的式子:
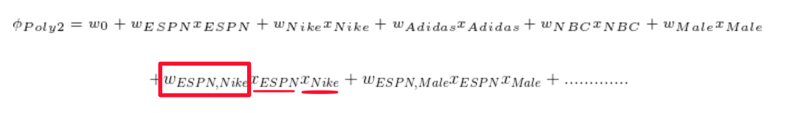
这么做带来的问题是:计算复杂度问题,随着N的增加,其计算量是N^2增加的,而且要想学习联合特征权重w,训练数据中必须要有这个联合分布才行。
此时FM的解决方法是,我们对于联合特征的权重捕捉上,不在采用简单的单权重,而是采用向量内积来表示:
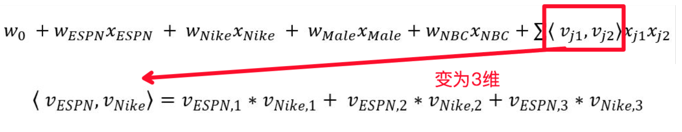
这么做其实相当于给模型增加了容量(因为模型参数变多了),更关键的是我们从原始数据中捕捉到了更多信息。
我们举个例子来说明上面的问题,看一组数据:
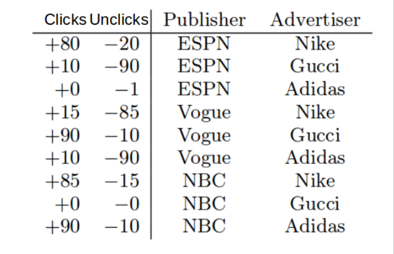
上面数据中,用传统的方法做,我们是学不到w(NBC, Gucci)的,因为没有任何训练数据,但是如果我们用FM呢?在对于联合特征的学习上,我们主要做的是学习每个特征的分布式表示,就像前文NFM中所示:
我们只要有单独的NBC和Gucci的数据即可,我们就能去学习其隐藏含义了即分布式表示。
另外一点FM优于LR的是计算效率,我们可以看FM论文中:
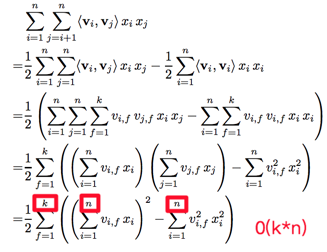
将原先n^2的计算变为了n*k,k一般都小于n,可以说是极大的性能提升。
另外我们可以从神经网络的角度来理解FM,其结构图如下:
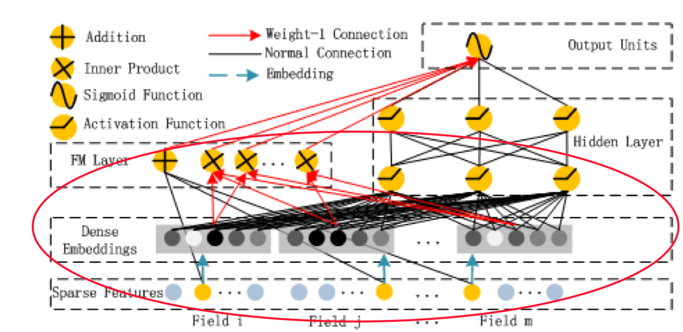
图来自DeepFM: A Factorization-Machine based Neural Network for CTR Prediction,根据FM的公式,可以分为3部分,

w0是全局的,wi是针对每个特征输入的,vik是对每个特征进行embedding后的。
这么说可能不是很清楚,可以看代码,代码是最好的说明:
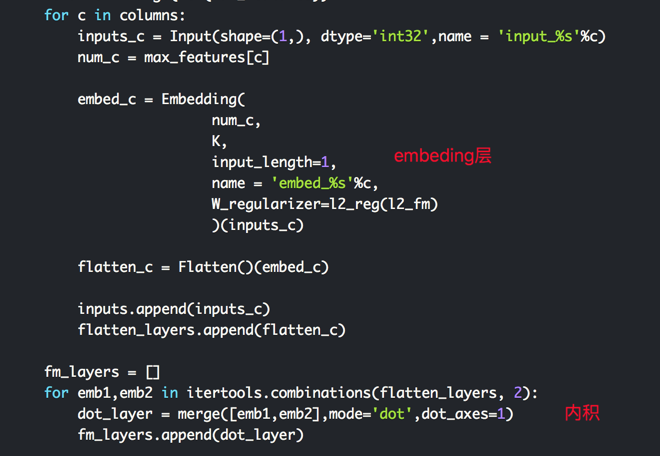

原版代码来自keras-based-fm.
FFM
此处多出来的F指代的是 Field-Aware,举个例子,看数据:

上面的Field指的就是P,A,G,每个Field下面都有好多类别。
在 FM 算法中,每一个特征只有一个隐向量 v,但是同一个Field对不同的Field其作用是不同的,譬如同样是Male,但是当其和Publisher和Advertisor分别求内积的时候,其作用是不同的,因此希望能够将类别信息加进来,变化部分就是在隐向量这块:
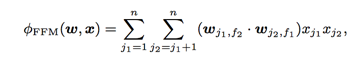
参数个数由原先的nk变为了nfk,n是特征个数,f是field类别个数,k是隐向量个数。
总结
本文主要介绍了FM和FFM的主要思想,下一篇将会是实战篇,使用的库是xLearn。
你的鼓励是我继续写下去的动力,期待我们共同进步。

