@zhuanxu
2018-03-26T07:29:44.000000Z
字数 4482
阅读 3318
GFS 原理深入浅出
分布式系统
GFS的需求来源
GFS设计需求来源于如何保存一个文件?
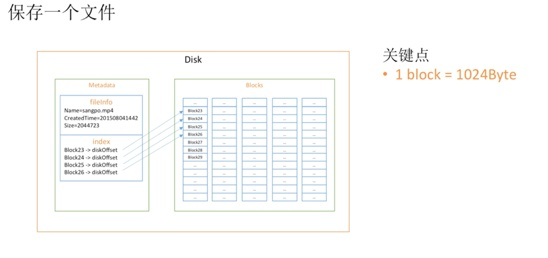
先来看上图,Linux文件系统中一个文件存储会分为两部分:
- metadata:存储文件元信息,如名字,创建时间等,另外就是index,存储文件真正内容的索引
- 文件内容:一个block=1024Byte
现在如果我们需要保存大文件,如果还是按照block=1024Byte,则会需要大量index数据,会有大量元数据,于是一个自然想法就是增加block大小。
我们新定义一个chunk的概念:
1 chunk = 64MB = 64 * 1024 = 65536 blocks
我们使用chunk后带来的影响就是小文件会浪费大量空间。
于是我们可以给出GFS的架构了:

上图中,有几个概念需要说明:
- master:存储 metadata
- chunkServer:存储具体的文件内容
下面是hdfs中一个文件的存储示例:

从上图我们可以很清晰的看到存储的过程:
- 将文件按128M block进行切块
- master记录metadata:文件包含的块,每个块在哪个datanode上
- 每个datanode上记录block在磁盘上的位置
注意:此处block和磁盘的关系维护在slave上,可以让文件位置改变的信息对master透明
上面架构设计的一个关键点:单master,单master的架构大大简化了我们的设计。
- 所有的关键信息由master维护,保证了数据的一致性。例如:不会存在每个客户端读取到的文件所在chunkServer的不同。
- 所有写经过master,可以通过master来实现全局操作的有序,避免了多master的写乱序问题
元数据
下面我们来看master中保存的元数据有哪些?主要有下面的3类:
- the file and chunk namespaces:文件和chunk的命名空间
- the mapping from files to chunks:文件到chunk的映射
- the locations of each chunk’s replicas:每个chunk所处的节点位置
上面3类信息都是直接保存在内存中的,其中第一和第二是信息是会通过记录变更日志的方式来保证可靠性,第三个信息则是在每个chunkserver启动的时候将chunk信息告知给master。
我们来分别看下上面两个决策的原因。
- the file and chunk namespaces 和 the mapping from files to chunks 的操作都需要记录日志。
- 记录操作日志是这两个信息持久化记录的方式,通过日志我们能够将整个内存中的状态恢复出来;
- 通过日志来保证操作的全局有效性
- chunk对应的server信息由chunkServer保存,并在启动或者新加入集群的时候主动上报给master。
因为只有chunkServer才能确认一个chunk在磁盘上的位置。我们不通过master来维护这样一个全局信息,因为chunkServer可能随时会fail,导致chunk对应信息失效,这样子就减少了master和chunkServer之间的数据同步的问题。
一致性模型
分布式系统一个关键就是看系统提供了什么样的一致性模型。
我们可以知道操作有读、写两种类型,那意味着我们需要考虑的操作排列有:
- 读写
- 读读
- 写读
- 写写
上面可能有一致性问题的操作是:写读、写写,并且只有在并发情况下我们讨论一致性才有意义。
以下一致性内容来自:GFS一致性总结
接着我们讨论有一致性问题的操作有哪些:
- 元数据修改
- 写数据:向一个文件块中写数据,客户端指定要写的数据和要写的数据在一个文件中的偏移量。
- 追加数据:客户端指定要将哪些数据追加到哪个文件后,系统返回追加成功的数据的起始位置。
元数据一致性
那我们先来看元数据的一致性问题。
元数据只在master上保存,并且会先写日志,然后再更新内存,这就意味着我们通过日志将所有的操作都串行了,并且在操作内存的时候会加锁,保证元数据一致性。
文件块的一致性
这里只讨论 一个chunk ,也就是 一个文件块 的写操作,不涉及整个文件的写流程中数据和元数据的流程,原论文里好像也没介绍文件的写流程。
每个chunk默认有3个副本,不同副本会存在不同节点上,master会设置1个主副本(primary),2个二级(secondary)副本。
当写操作和追加操作失败,数据会出现部分被修改的情况,于是肯定会出现副本不一致的情况,这时就依赖master的重备份来将好的副本备份成N份。以下只考虑操作成功的情况。
写一个chunk+无并发
写一个chunk时,客户端向primary发送写请求(一个chunk对应几个写请求不确定,这里不影响理解,当做一个看就可以了)。primary确定写操作的顺序,由于没有并发,只有一个写请求,直接执行这个写请求,然后再命令secondary副本执行这个写请求。其他secondary都按照这个顺序执行写操作,保证了全局有序,并且只有当所有副本都写成功,才返回成功,用系统延迟保证了数据强一致,即 consistent(所有副本的值都一样) 。
这个强一致指每个写成功后,所有客户端都能看到这个修改。即论文中说的 defined 。defined 的意思是知道这个文件是谁写的(那么谁知道呢?肯定是自己知道,其他客户端看不到文件的创建者)。也就是当前客户端在写完之后,再读数据,肯定能读到刚才自己写的。
写一个chunk+并发
这时primary可能同时接受到多个客户端对自己的写操作。举个例子,两个客户端同时写一个chunk。w1或w2代表(写操作+数据)。下边表示client1想将这个chunk写成w1,client2想将这个chunk写成w2。
client1:w1
client2:w2
于是primary要将这些写操作按某个机制排个顺序:
primary:w2,w1
然后在primary本地执行,于是这个chunk首先被写成w2,之后被覆盖成w1。
之后所有secondary副本都会按照这个顺序来执行操作,于是所有副本都是w1,这时数据是 consistent 的,也就是副本一致的。因为所有操作都正确执行了,所以两个client都收到写成功了。但是谁也不能保证数据一定是自己刚才写的,也就是 undefined 。这与最终一致性有点像(系统保证所有副本最终都一样,但是不保证是什么值)。
追加数据+无并发
追加数据时,会追加到最后一个chunk,其实和写一个chunk+无并发基本一样。
但由于追加操作和写文件不一样,追加操作不是幂等的,当一次追加操作没有成功,客户端重试时,不同副本可能被追加了不同次数。
假设追加了一个数据a
client:追加a。
第一次追加请求执行了一半失败了,这个chunk的所有副本现在是这样:
primary:原始数据,offset1:a
second1:原始数据,offset1:a
second2:原始数据
于是客户端重新发送追加请求,因为primary会先执行操作再将请求发给secondary,所以primary当前文件是最长的(先不考虑primary改变的情况)。primary继续往offset2(当前文件末尾)追加,并通知所有secondary往offset2追加,但是secondary2的offset2不是末尾,所以会先补空。如果这次追加操作成功,数据最终会是这样:
primary:原始数据,offset1:a,offset2:a
second1:原始数据,offset1:a,offset2:a
second2:原始数据,offset1:*,offset2:a
并且给客户端返回 offset2 。
于是数据中间一部分是 inconsistent。但是对于追加的数据是 defined 。客户端再读offset2,不管从可以确定读到a。
这就是追加操作的defined interspersed with inconsistent。
追加数据+并发
两个客户端分别向同一个文件追加数据a和b
client1:追加a
client2:追加b
最后一个文件块的primary接收到追加操作后进行序列化
primary:b,a
然后执行,b失败了一次,于是client2再发送一次追b。primary再追加一次。
primary:原始数据,off1:b,off2:a,off3:b
second1:原始数据,off1:b,off2:a,off3:b
second2:原始数据,off1: ,off2:a,off3:b
client1收到GFS返回的off2(表示a追加到了文件的off2位置),client2收到off3
也满足off2和off3是 defined ,off1是 inconsistent ,所以总体来说是 defined interspersed with inconsistent
可以看到,不管有没有并发,追加数据都不能保证数据全部 defined,只能保证有 defined ,但是可能会与 inconsistent 相互交叉。
系统交互
先来看数据写入流程:
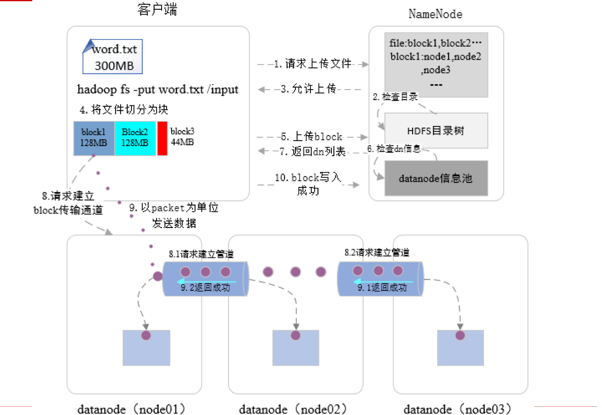
0. hadoop fs -put word.txt /input
1. 创建rpc调用请求上传文件
2. namenode 检查目录是否已经存在,文件是否已经上传,是否有写入权限
3. 返回结果,允许上传
4. 客户端读取配置(block大小,副本数等),将文件切分为block
5. 上传第一个block请求
6. namenode 检查datanode信息
7. namenode 返回datanode位置(3副本则返回3个datanode地址)
8. 请求建立block传输通道,主datanode根据副本信息与其他datanode建立传输通道
9. 以packet为单位发送数据,只有当所有副本都写入成功后才返回客户端【注意:此处通过主datanode保证了各个副本之间的数据一致性】
10. 当所有block都写入成功后,客户端通知namenode文件写入成功,此时namenode将数据应用到内存中,该文件对所有客户端可见。
文件读取流程

此处需要考虑的是怎么保证block的数据完整性:通过计算checksum

如果数据损坏的话呢,Chunk Server就找Master恢复数据

同时发送心跳检查Chunk Server是否运行正常。如果有服务器挂掉的话就向Master申请恢复

总结
本文首先介绍了Linux文件系统存储文件的方案,指出了如果要存储大文件,需要将block大小提升,于是有了Chunk,1chunk=64MB=64 * 1024 = 65536 blocks,同时我们将文件的metadata存储在master,而chunk存储在chunkServer上,为了保证数据的高可用,我们对一个chunk保存了3个副本,每个副本尽量分布在不同的机器上,接着我们指出了gfs的架构:单master,多slave,并且我们指出了萱蕚单master的架构的原因:可以大大的简化系统设计,所有的事务操作通过master就能保证有序;最后我们介绍了文件读和写的流程,所有的数据交互都让client和slave直接交互。
你的鼓励是我继续写下去的动力,期待我们共同进步。

