@zhuanxu
2017-12-18T07:31:27.000000Z
字数 1246
阅读 5941
推荐系统算法之surprise实战
机器学习 推荐系统
上一篇推荐系统之用户行为分析介绍了一些基本推荐算法,本文将通过surprise库来深入分析这些算法。
NormalPredictor
第一种预测方法是假设评分数据来自于一个正态分布,下面对这个问题进行建模。
问题:若给定一组样本x 1 ,x 2 …x n ,已知它们来自于 高斯分布N(μ,σ),试估计参数μ,σ。
高斯分布的概率密度函数:
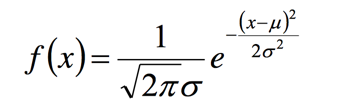
将X i 的样本值x i 带入,得到:

我们将L(x)求log,并且化简式子:
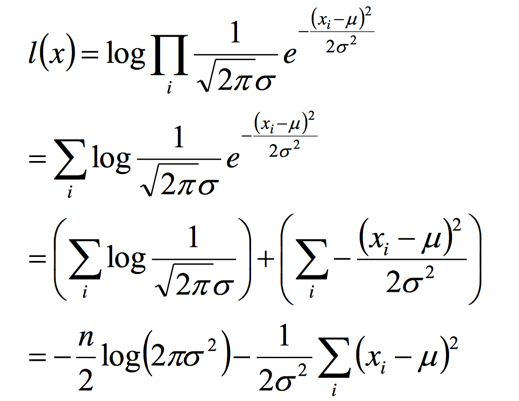
最后我们对式子求导求,就能得到μ,σ:
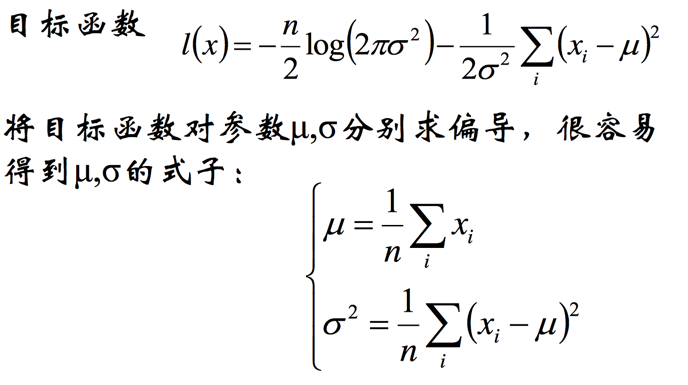
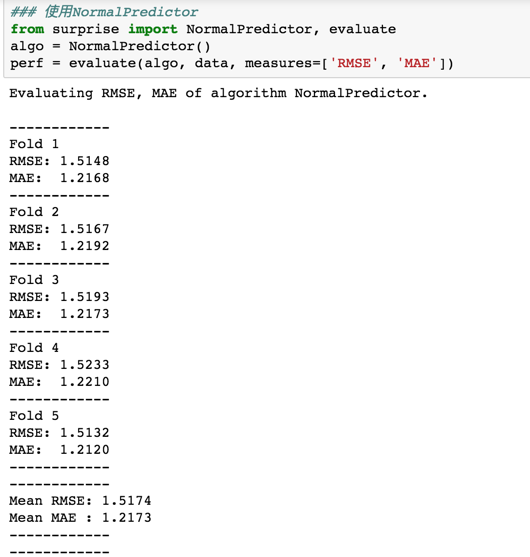
看代码:
BaselineOnly
第二个算法是根据 Factor in the neighbors: scalable and accurate collaborative filtering所得到,算法发现传统CF方法的一些问题:
- 不同item的评分不同
- 不同用户的评分也不同
- 评分随着时间一直在变化
于是提出了下面的baseline model:
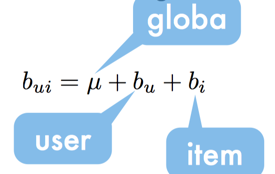
其中u是平均得分,bu是用户的偏置,bi是item的偏置,等价于求下面的极值问题:
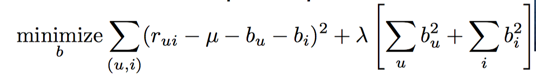
可以求得下面的bu和bi:
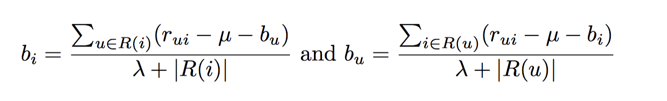
我们可以再看surprise中代码,里面的实现是:

运行代码可得:
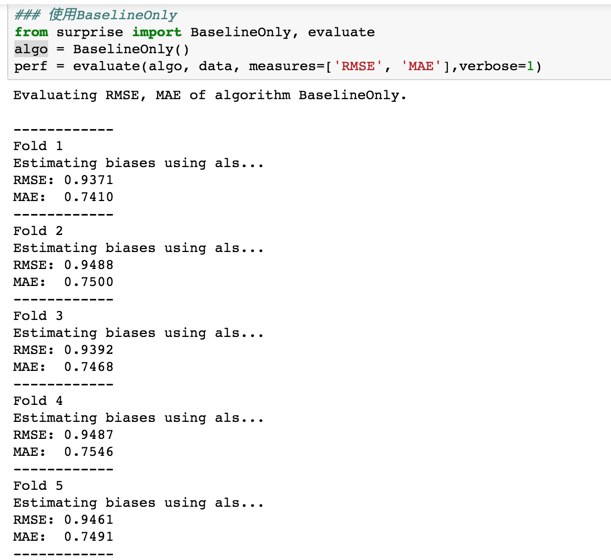
可以发现结果是好于NormalPredictor的。
KNNBasic
KNNBasic是基本的CF算法,user-based或者item-based
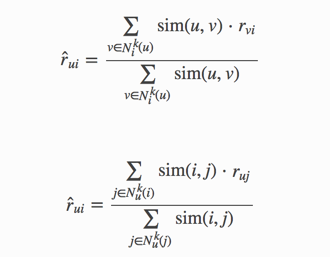
计算user-user的相似性,或者计算item-item的相似性。
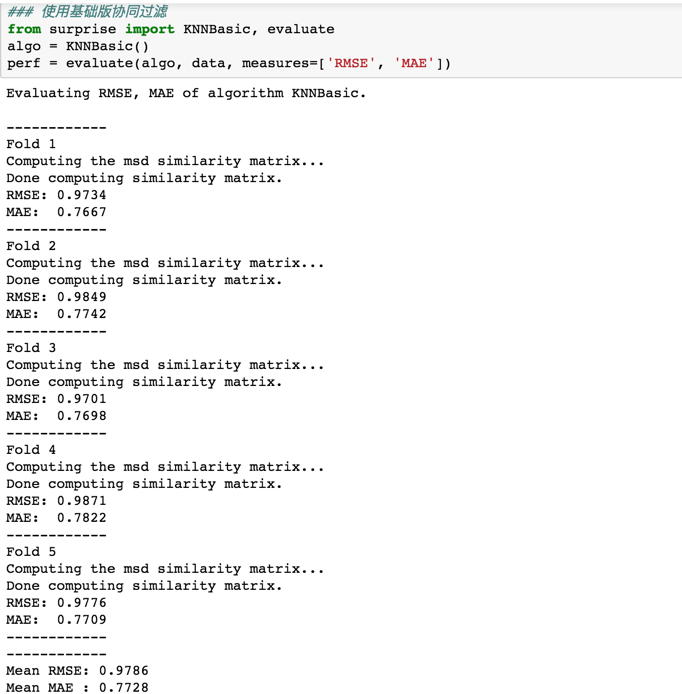
可以看到这个结果略差于BaselineOnly
KNNWithMeans
KNNWithMeans 基于的一个假设也是用户和item的评分有高低,去除一个平均值后再计算。

通过均值的方法来计算结果略优于KNNBasic

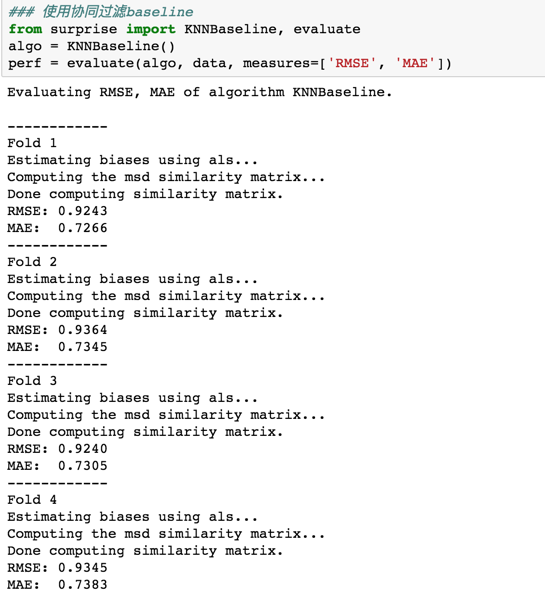
KNNBaseline
KNNBaseline 是在 KNNWithMeans 基础上,用baseline的值来替换均值,计算公式如下:

可以看到使用 KNNBaseline 方法是目前最好的结果。
SVD
从这个算法开始是使用矩阵分解算法来做了,先是最基本的svd方法。
先定义预估值:
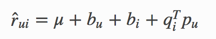
在定义loss

最后是更新方式:
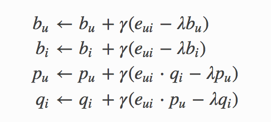
其中eui是残差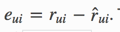
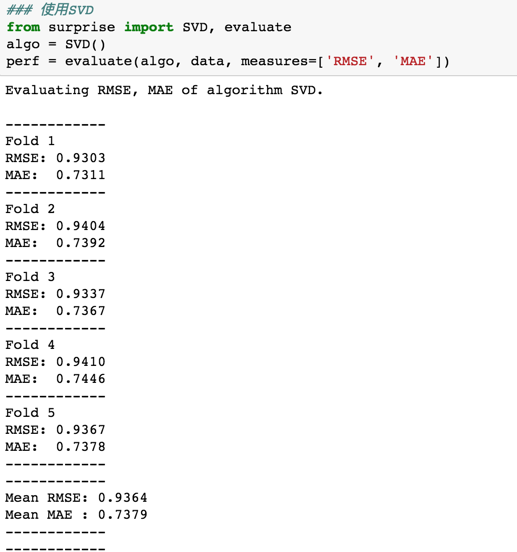
核心代码:

svd++
预测的精度不仅要考虑显示的反馈,也需要考虑一些隐反馈
- 显性反馈行为包括用户明确表示对物品喜好的行为:主要方式就是评分和喜欢 / 不喜欢;
- 隐性反馈行为指的是那些不能明确反应用户喜好的行为:最具代表性的隐性反馈行为就是页面浏览行为;
更详细的内容可以看之前的文章推荐系统之用户行为分析。
将这种隐反馈考虑进来,特别适合当一直浏览,但是不怎么进行评价的用户。
此时我们建模得到下面的式子:
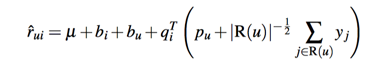
其中R(u)是用户u有隐性行为的item集合,y则是对item隐性行为的向量建模,如果用户有多个隐性行为,我们同样可以再加上一个隐向量:
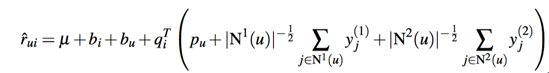
此时参数更新方法:
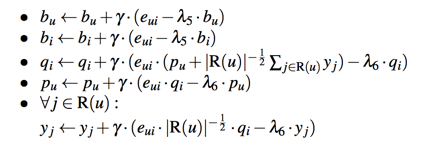
代码实现:

代码执行效果:

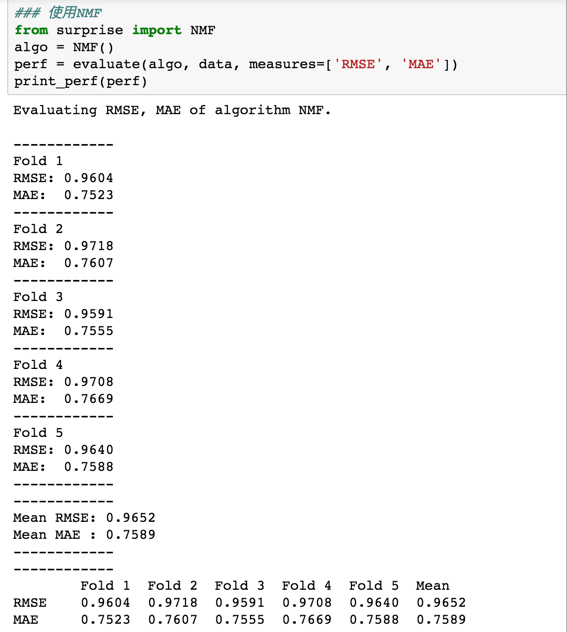
NMF
非负矩阵分解(NMF)和svd都是做矩阵分解,不多做解释,看代码执行效果:
总结
本文通过 surprise 中的方法介绍了两大类推荐算法:隐语义模型和基于邻域的算法,下一篇文章将介绍一些基于神经网络的推荐算法,尽请期待。
