@zhuanxu
2018-01-31T09:55:35.000000Z
字数 2839
阅读 2700
进击算法:字符串匹配的 BM 算法
BM
BM 算法介绍
各种文本编辑器的 "查找" 功能(Ctrl+F),大多采用 Boyer-Moore 算法。

Boyer-Moore 算法不仅效率高,而且构思巧妙,容易理解。1977 年,德克萨斯大学的 Robert S. Boyer 教授和 J Strother Moore 教授发明了这种算法。
下面我根据书籍 Algorithms on Strings, Trees, and Sequences 的第2章 Chapter 2 - Exact Matching: Classical Comparison-Based Methods 来介绍 BM 算法。
好后缀
假设匹配过程中发现x[i]=a 和 y[i+j] = b 不同,此时当前匹配的信息有:
x[i+1 .. m-1]=y[i+j+1 .. j+m-1]=u
x[i] != y[i+j]
此时我们假设能找到u在x中的最右出现位置,则可以直接将x向右滑动shift距离。
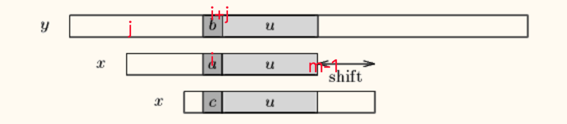
but,如果我们没在x中找到u,则我们尝试去找到y[i+j+1 .. j+m-1]的最长后缀v,同时v也是x的前缀。
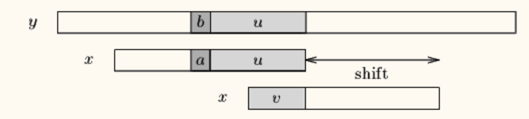
总结下上面两种情况:
- u可以完整的再次出现在x中
- u的后缀是x的前缀
坏字符
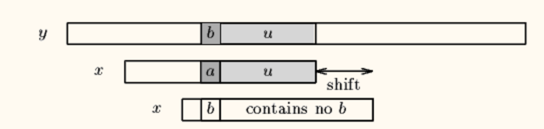
我们找到 y[i+j]=b 在x中最右出现的位置,如果没找到直接左对齐y[i+j+1]:
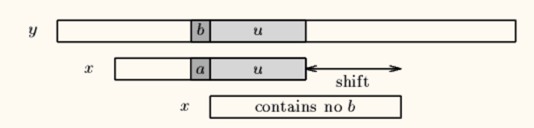
我们可以发现,坏字符的情况中,有可能shift是负数。
移动
我们可以根据上面的 好后缀和坏字符分别计算出 shift(好后缀) 和 shift(坏字符) ,我们最后真正移动的shift则是 max(shift(好后缀),shift(坏字符))。
算法实现
下面我们来分别计算 shift(好后缀) 和 shift(坏字符)。
先来求shift(坏字符),具体算法如下:
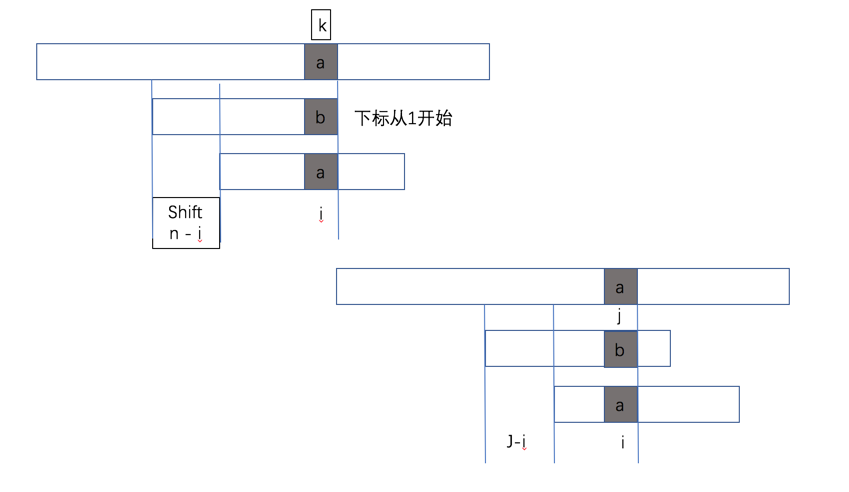
上面图中第一个说明是尾部不匹配的时候,我们查找字符a在pattern中的位置,假设是i,则Pattern shift的距离是 n-i
第二是是说如果失配发生在pattern中第j个位置,此时字符a在pattern中的位置为i,此时shift为j-i,此时意味着,如果的话,此时我们只能取shift=1,下面我们来计算
// 整个下标从1开始void PreBmBc(char *pattern, int n, int bmBc[]){int i;for(i = 0; i < 256; i++){bmBc[i] = 0;}for(i = 1; i <=n ; i++){bmBc[pattern[i]] = i;}}
下面我们来看好后缀怎么算计:
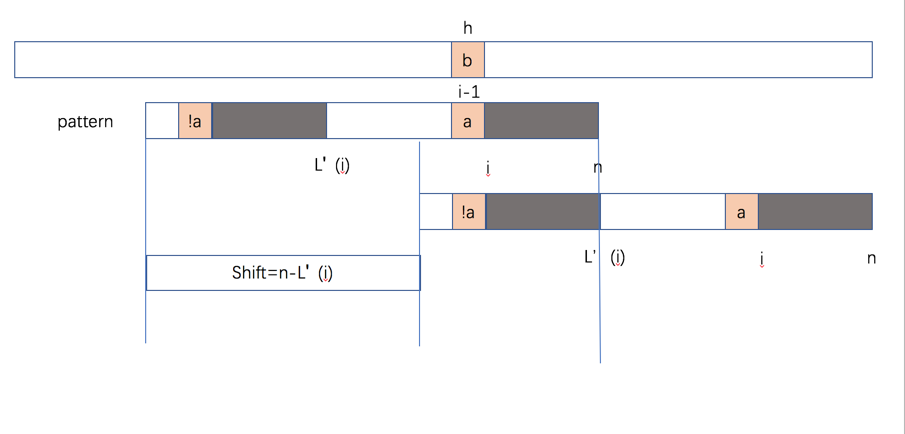
先看上图,我们定义L(i)为最大的小于n的位置,满足 P[i..n] 是 P[1..L(i)] 的后缀。
接着我们定义 L'(i),其含义如上图,我们在L(i)的基础上,定义P[i-1] != P[L'(i)-n+i-1]。
举个例子:
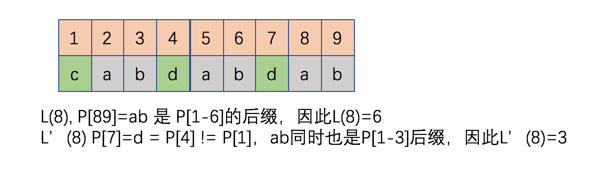
接着我们定义为P[1..j]和P[1..n]最长公共后缀。
我们来看下定义P[1..j],假设存在 i 满足L‘(i)=j,即P[i..n]是同后缀,并且P[i-1]!=P[j-n+i-1]也不同,即,此时L'(i)=j,于是我们就有了下面的算法:
for i=1 to n, do L'(i) = 0for j=1 to n-1, doi = n - Nj(P) + 1L'(i) = j
上面算法中我们是假设已经知道了Nj(P)了,然后通过Nj来计算出L'(i),那我们怎么计算Nj呢?
// 后缀长度void SuffixLength(const char *pattern, int n, int N[]) {for (int j = 1; j < n; j++) {int i;for (i = 0; pattern[n - i] == pattern[j - i] && i <= j; i++) {}N[j] = i;}N[n] = n;}
计算完Nj,下面计算L':
void CalL(const char* pattern, int n, int L[], const int N[]){for (int i=1;i<=n;i++){L[i] = 0; // L[1] 是没意义的,这里也初始化为0}for (int j=1;j<n;j++){ // N[n] 是没有意义的,或者说 N[n] 一定为 nif (N[j]>0){int i = n - N[j] + 1;L[i] = j;}}}
下面我们看另一种情况,当我们找不到后缀的时候,即L'(i)=0,我们可以退而求其次,求前缀,看下图:
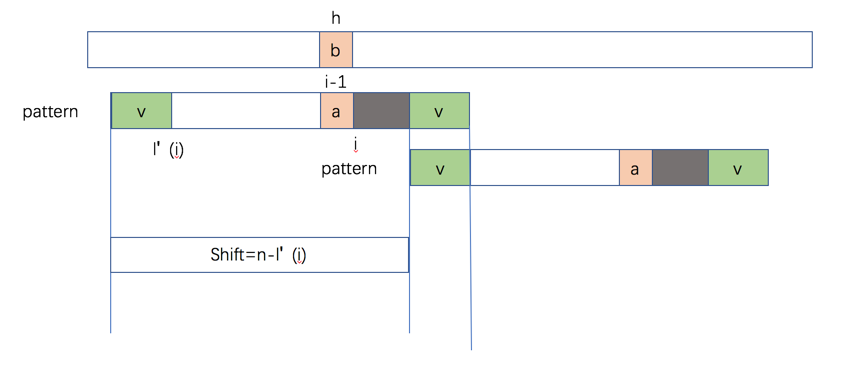
我们定义 l'(i) 是P[i..n]的最长后缀同时也是P[1..n]的前缀,如果不存在这样子的前缀,则l'[i] = 0,此时的含义是说,此时shift=n,为什么移动最大呢?因为我们先去找Patten中是否存在P[i..n],因为如果要匹配,则pattern中必须要存在P[1..L'(i)],但是不幸的是没找到,这个时候我们可以直接先shift i-1,然后在慢慢右移,直到 l'(i),这个过程如下图:
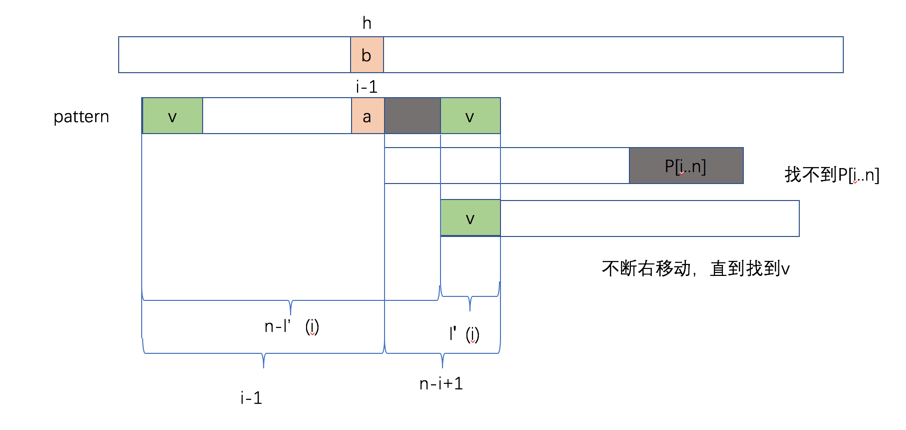
下面就是怎么去计算l'(i)了。
我们如果假设l'(i)存在,即l'(i) = j>0,那么此时Nj(P) = j,并且此时 j 肯定小于等于 |P[i..n]| = n - i + 1,有了这么个洞见以后,我们再来看怎么计算l'(i).
假设N[j] == j, j<=n-i+1 => i<=n-j+1,此时j越大,i越小,因此我们就可以这么做了:
for j=1 to n-1:if Nj == j:for i from 1 to n-j+1l'(i) = j
代码如下:
void Call(const char* pattern, int n, int l[], const int N[]){for (int i=1;i<=n;i++){l[i] = 0; // l[1]其实没有意义,}for(int j=1;j<n;j++){if (N[j] == j){for (int i=1;i<=n-j+1;i++){l[i] = j;}}}l[1] = 0;}
现在我们来看下怎么根据L'(i)和l'(i)来计算shift的距离:当P[i-1] != T[k] 的时候,如果 L'(i) > 0,则移动 n - L'(i),否则移动 n - l'(i),此处需要注意一个特殊情况,即 i=n 的时候,我们需要移动 1 位。
代码如下:
void PreBmGs(const char *pattern, int n, int bmGs[]) {// const char* p = pattern - 1; // 让下标从1开始vector N(0,n+1);vector L(0,n+1);vector l(0,n+1);SuffixLength(pattern, n, N.data());CalL(pattern,n,L.data(),N.data());Call(pattern,n,l.data(),N.data());for (int i=1;i<n;i++){if (L[i]>0){bmGs[i] = n - L[i];}else {bmGs[i] = n - l[i];}}bmGs[n] = 1; // special case}
好了,现在一切就绪,我们开始整个搜索过程了,完整的搜索代码见github地址
另外一个完整搜索过程的图示可以看search examples。
你的鼓励是我继续写下去的动力,期待我们共同进步。

