@Bruce1Tone
2022-03-13T06:32:59.000000Z
字数 29726
阅读 683
电子科技大学
实 验 报 告
学生姓名:唐智崴
学号:2017110801028
指导教师:邵俊明
数据挖掘实验
目录
实验一
实验二
实验三
实验四
附录
实验一代码
数据归一化
缺失值处理
特征筛选
实验二代码
关联规则挖掘
实验三代码
KNN分类
决策树分类
实验四代码
K-Means聚类算法
实验一
一、实验项目名称:
认识数据与数据预处理
二、实验原理:
- 数据属性归一化:将数据属性观测值按照一定规则映射到规定的区间(如[0,1])
- 缺失值处理:利用属性均值填补缺失值
- 特征筛选:计算属性的信息增益,过滤掉低信息增益的特征,留下高信息增益的特征
三、实验目的:
了解Weka工具包及Eclipse平台;认识和了解数据,并且能对其进行简单的预处理
四、实验内容:
该实验我选择用两种方法实现:利用Weka实现和自行python编程实现。
首先是利用Weka中现成的功能直接完成上述操作,然后自己再利用python手动实现上述功能,以便对该过程有更深的了解。
五、实验步骤:
Weka实现:
- 数据归一化:
Weka GUI->Explorer->Open file-> 选择数据文件data1.xlsx
然后在Filter选择weka->filters->unsupervised->attribute->Normalize
最后将实验结果存储在data1.xlsx文件的另一列中 - 缺失值处理:
数据集为data2.xlsx,同上一步操作,这一步改用Filter->ReplaceMissingValues,即缺失值填补的滤波器 - 特征筛选:
数据集为data3.xlsx,同上一步操作,这一步改用Filter->AttributeSelection,参数evaluator选择InfoGainAtrributeEval,Ranker设置为6
Python实现:
1-数据归一化:
完整代码见附录:点此跳转
实验流程是:
- 首先使用
get_data()函数将data_1.xlsx中的数据集读入并存储在Data类的ori_data中- 然后使用
GetMinAndMax()函数将ori_data中的最大值和最小值找到并存储在Data类中- 最后使用
Normalize()函数将数据映射到[0,1]区间,由RecordNormalizedData()函数将归一化后的数据写入原文件中
上述函数由下列代码给出:
class Data():def __init__(self,sheet_data):self.maxA = 0self.minA = 0self.ori_data = self.get_data(sheet_data)self.normalized_data = self.ori_dataself.length = len(self.ori_data)self.GetMinAndMax()def get_data(self,sheet_data):#获取excel中存储的数据data = []i = 0while True:try:data.append(sheet_data.cell(i+1,0).value)i += 1except IndexError:breakreturn datadef GetMinAndMax(self):#获取数据中的最大值和最小值temp_min = self.ori_data[0]temp_max = self.ori_data[0]for i in range(self.length):if self.ori_data[i] <= temp_min:temp_min = self.ori_data[i]if self.ori_data[i] >= temp_max:temp_max = self.ori_data[i]self.maxA = temp_maxself.minA = temp_mindef Normalize(self):#数据归一化操作for i in range(self.length):self.normalized_data[i] = (self.ori_data[i] - self.minA)/(self.maxA - self.minA)def RecordNormalizedData(self,sheet):#记录归一化的数据sheet.write(0,1,'Normalized Data')for i in range(self.length):sheet.write(i+1,1,round(self.normalized_data[i],2))
2-数据缺失值处理:
完整代码见附录:点此跳转
该操作的核心在于FillBlank()函数,即将数据的均值求出并填回缺失值,函数由如下代码定义:
def FillBlank(self):count = 0data_sum = 0blank_index = []for i in range(self.length):if self.ori_data[i] is not '':count += 1data_sum += self.ori_data[i]else:blank_index.append(i)aver = data_sum / countfor i in blank_index:self.filled_data[i] = round(aver,2)
3-特征筛选:
完整代码见附录:点此跳转
该实验的重点在于,统计每一个属性的信息与标签,并进行信息熵和信息增益的计算
信息熵的计算方法由下式给出:
代码实现是:
def get_Ent_D(self):#获取根节点的信息熵Ent_Dcount_true = 0count_false = 0for i in self.table[self.ncols-1]:if i == '是':count_true += 1elif i == '否':count_false += 1p_true = count_true/(count_true + count_false)p_false = count_false/(count_true + count_false)Ent_D = 0 - (p_true * math.log(p_true,2) + p_false * math.log(p_false,2))return Ent_D
然后计算每个属性的信息增益Gain:
代码实现是:
def get_information_gain(self):#获取该属性的信息增益Ent_D_i = [] #存储该属性各个状态的信息熵p_D_i = [] #存储该属性各个状态的比例sample_quantity = 0result = 0for i in self.dict_True:sample_quantity += self.dict_True[i]for i in self.dict_False:sample_quantity += self.dict_False[i]for i in self.status:total = self.dict_True[i] + self.dict_False[i]if self.dict_True[i] != 0:if self.dict_False[i] != 0:temp_Ent_D_i = 0 - ((self.dict_True[i]/total) * math.log(self.dict_True[i]/total,2) + (self.dict_False[i]/total) * math.log(self.dict_False[i]/total,2))else:temp_Ent_D_i = 0 - self.dict_True[i]/total * math.log(self.dict_True[i]/total,2)else:temp_Ent_D_i = 0 - self.dict_False[i]/total * math.log(self.dict_False[i]/total,2)temp_p = total/sample_quantityEnt_D_i.append(temp_Ent_D_i)p_D_i.append(temp_p)for i in range(len(Ent_D_i)):result += Ent_D_i[i] * p_D_i[i]result = self.Ent_D - resultreturn result
六、实验数据及结果分析:
数据归一化结果:
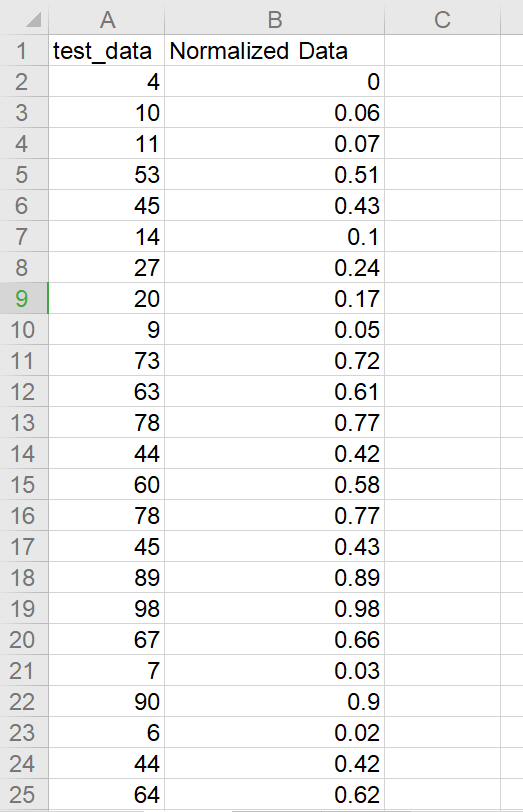
原数据在[0,100]区间,归一化后映射在[0,1]区间,实验结果符合预期
数据缺失值处理结果:
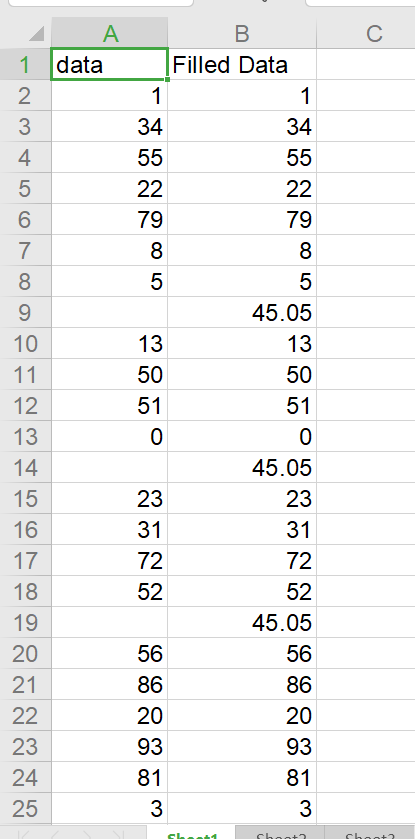
原数据缺失值被填入了保留两位小数的均值,实验结果符合预期
特征筛选处理结果:
原始数据集为:
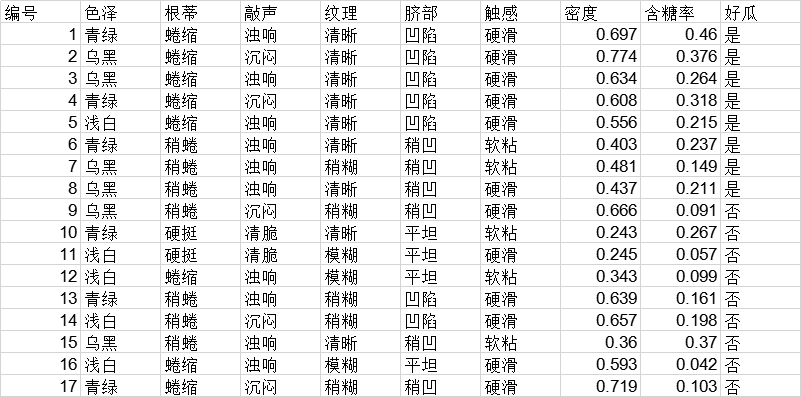
实验结果为:
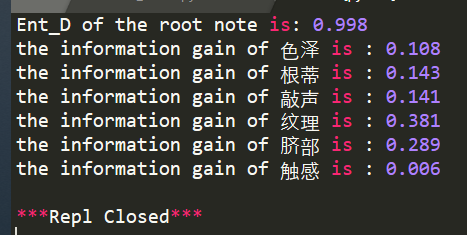
成功计算出各个离散属性的信息增益,实验结果符合预期
七、实验结论:
实验结果符合预期,具体结果见上节
八、总结及心得体会:
在数据挖掘的过程中,第一步也是最重要的一步就是数据预处理,通过实际操作我掌握了数据预处理中的数据归一化、数据缺失值处理、特征筛选等预处理的方法,为后面的数据挖掘学习奠定基础
九、对本实验过程及方法的改进建议:
该实验中特征筛选环节,由于没有数据集的限制,所以只做了离散属性的特征筛选。后面有时间可以补上连续属性的信息增益计算和特征筛选
报告评分:
指导老师签字:
实验二
一、实验项目名称:
关联规则挖掘
二、实验原理:
先产生频繁项集,然后再从频繁项集中提取高置信度的规则,即强规则。该过程中利用Apriori算法进行剪枝处理
三、实验目的:
掌握关联规则挖掘的基本概念、原理和一般方法,掌握Apriori算法,了解FP-GROWTH算法
四、实验内容:
根据如下数据集,挖掘商品的关联规则,并返回强规则:
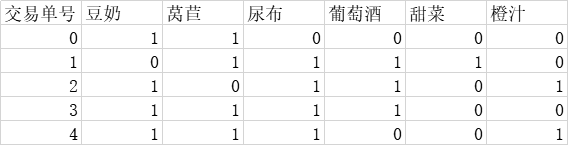
五、实验步骤:
完整代码见附录:点此跳转
读取数据集
首先用ReadData()函数将data.xlsx中的数据集读入到layer1中,如下:
layer1 = ReadData(sheet)def ReadData(sheet):temp_layer = []for i in range(1,sheet.ncols):temp_node = Node(sheet.nrows - 1)temp_node.content.append(sheet.cell(0,i).value)count = 0for j in range(1,sheet.nrows):if sheet.cell(j,i).value == 1:count += 1temp_node.data.append(int(sheet.cell(j,i).value))temp_node.sup = counttemp_layer.append(temp_node)return temp_layer
剪枝
然后根据Apriori算法,非频繁项集的超集一定是非频繁的,所以对所有的非频繁项集进行剪枝操作,然后更新该层的所有结点。以上过程由UpdateLayer()函数实现,代码如下:
#更新当前层,剪枝def UpdateLayer(ori_list,threshold):temp_list = []for i in ori_list:if i.sup > threshold:temp_list.append(i)return temp_list
连接
完成剪枝操作后,将剪枝后的该层各点相互连接,由GenNewLayer()函数构建成新的一层,函数由如下给出:
#连接上层生成下层def GenNewLayer(ori_list):new_list = []for i in ori_list:for j in ori_list:if i != j:new_list.append(Merge(i,j))return new_list#Merge函数合并a,b两个结点def Merge(a,b):temp = Node(a.total)#合并self.content的内容,并去重for i in a.content:temp.content.append(i)for i in b.content:if i not in a.content:temp.content.append(i)#统计data和sup的内容count = 0for i in range(a.total):if a.data[i] == b.data[i] and a.data[i] == 1:count += 1temp.data.append(1)else:temp.data.append(0)temp.sup = countreturn temp
最后控制输出所有的强规则即可
六、实验数据及结果分析:
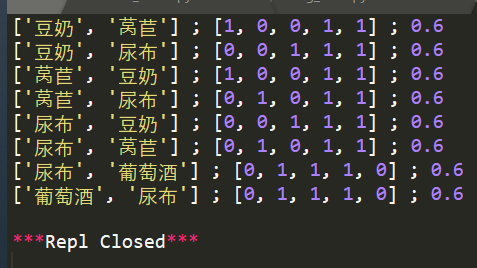
其中,第一项为关联规则;第二项为具体关联的事件,1表示规则为真;第三项表示该规则的置信度。
七、实验结论:
利用Apriori算法可以不用遍历所有数据,即可完成关联规则挖掘。最后输出的强关联规则经过验证,是正确的,实验成功。
八、总结及心得体会:
Apriori算法的关键在于其逆应用,即:所有费频繁项集的超集都是非频繁的。借助此算法,在每次连接形成新的一层(layer)后,可以根据该算法将支持度较低的非频繁项集剪枝处理,大大减少了计算量,是一种常用的关联规则挖掘算法
九、对本实验过程及方法的改进建议:
由于是自己手敲的数据,该实验采用的数据集较小,计算开销的节省效果还不明显。可以换成较大的数据集进行测试,就能明显感受到Apriori算法的优越性能
报告评分:
指导老师签字:
实验三
一、实验项目名称:
分类实验
二、实验原理:
KNN算法即k邻近算法,即将测试数据放入训练集中,选择距离最短的k个数据作为邻居,然后预测它的类别和k个邻居中其所属类别最多的一致,属于一种无监督的lazy learning,不需要对训练样本进行学习
决策树算法即根据数据的每个属性,分别计算其信息熵和信息增益,然后选择信息增益最大的属性作为父节点,在此基础上重复以上过程直到大部分数据能根据该决策树正确分类
三、实验目的:
了解分类的基本概念、原理和一般方法,掌握分类的基本算法,实现KNN或决策树算法
四、实验内容:
KNN算法
首先将训练数据导入,然后遍历测试集,对每一个测试数据求其k个最邻近的邻居,然后按照邻居最多的属性进行预测,并与该数据的实际属性进行对比,实现分类
决策树算法:
首先将训练数据导入,并计算各个属性的信息增益,然后根据信息增益构建决策树。
再遍历测试数据,对每一个测试数据使用该决策树进行分类预测,并与实际的标签进行对比
以上两个实验共用同一个数据集,训练数据集为iris.2D.train.arff,测试数据集为iris.2D.test.arff
五、实验步骤:
KNN算法详解
完整代码见附录:点此跳转
定义数据类型
首先定义一个Node类,用于存放每一行测试数据,定义如下:
class Node():def __init__(self):self.petallength = 0self.petalwidth = 0self.classes =''
利用GetData()函数进行数据读取后,进行上述过程的预测,由Predict()函数实现:
def GetDist(node_a,node_b):#计算两点的距离distance = math.sqrt((node_a.petallength - node_b.petallength)**2 + (node_a.petalwidth - node_b.petalwidth)**2)return distancedef Predict(train_list,node_a,k):#开始预测数据dist_list = [] #存放离各点距离index_list = [] #存放K邻近的点的索引indexfor i in train_list:dist_list.append(GetDist(node_a,i))dist_copy = dist_listfor i in range(k): #寻找k邻近的索引值,并存放在index_list中temp_min = 999temp_index = 0for j in range(len(train_list)):if dist_copy[j] <= temp_min:temp_min = dist_copy[j]temp_index = jdist_copy[temp_index] = 999index_list.append(temp_index)classes = {}#统计k邻近的分类结果,并以字典形式存放在classes中for i in index_list:if train_list[i].classes not in classes:classes[train_list[i].classes] = 1else:classes[train_list[i].classes] += 1result = ''max_times = 0#选取次数最多的分类结果并存放在result中for i in classes:if classes[i] >= max_times:max_times = classes[i]result = ireturn result
最后是主函数RunTest(),其附带的一个功能是统计预测的正确率并输出:
def RunTest(train_list,test_list,k):#开始运行测试count = 0for i in test_list:result = Predict(train_list,i,k)if i.classes == result: #判断预测结果与标签是否相符count += 1print('sample',test_list.index(i),'is correctly classified as',i.classes,'!')rate = float(count / len(test_list))return rate
决策树算法详解
完整代码见附录:点此跳转
首先定义一个Node类,同上,然后定一个Tree类作为决策树的结点:
class Tree():def __init__(self):self.name = ''self.standard = 0self.left = Noneself.right = None
然后用GetEnt()函数计算某属性的信息熵,用GetGain()函数计算某属性的信息增益:
def GetGain(train_list,name):#计算信息增益if name is 'petallength':data_list = []for i in train_list:data_list.append(i.petallength)median = np.median(data_list)ent_d = GetEnt(train_list)d_list = []temp_list = []for i in train_list:if i.petallength >= median:temp_list.append(i)d_list.append(temp_list)gain = ent_dfor i in d_list:gain = gain - len(i)*GetEnt(i)/len(train_list)return gainelif name is 'petalwidth':data_list = []for i in train_list:data_list.append(i.petalwidth)median = np.median(data_list)ent_d = GetEnt(train_list)d_list = []temp_list = []for i in train_list:if i.petalwidth >= median:temp_list.append(i)d_list.append(temp_list)gain = ent_dfor i in d_list:gain = gain - len(i)*GetEnt(i)/len(train_list)return gaindef GetEnt(train_list):#计算信息熵count = {}for i in train_list:if i.classes not in count:count[i.classes] = 1elif i.classes in count:count[i.classes] += 1total = 0for i in count:total += count[i]ent = 0for i in count:ent = ent - count[i]/total * math.log(2,count[i]/total)return ent
以上是对于离散属性的求解,而对于连续属性,则需要求中位数进行二分法,将之转换为离散属性再进行计算,其中求中位数的函数为GetMedian():
def GetMedian(train_list,name):if name is 'petallength':data_list = []for i in train_list:data_list.append(i.petallength)median = np.median(data_list)elif name is 'petalwidth':data_list = []for i in train_list:data_list.append(i.petalwidth)median = np.median(data_list)return median
最后是生成决策树的函数GenTree(),返回决策树的根节点:
def GenTree(train_list):root = Tree()gain = []gain.append(GetGain(train_list,'petallength'))gain.append(GetGain(train_list,'petalwidth'))if gain[0] >= gain[1]:root.name = 'petallength'root.standard = GetMedian(train_list,'petallength')root.left = Tree()root.left.name = 'petalwidth'root.left.standard = GetMedian(train_list,'petalwidth')root.left.left = Tree()root.left.left.name = '1'root.left.right = Tree()root.left.right.name = '2'root.right = Tree()root.right.name = 'petalwidth'root.right.standard = GetMedian(train_list,'petalwidth ')root.right.left = Tree()root.right.left.name = '3'root.right.right = Tree()root.right.right.name = '4'else:root.name = 'petalwidth'root.standard = GetMedian(train_list,'petalwidth')root.left = Tree()root.left.name = 'petallength'root.left.standard = GetMedian(train_list,'petallength')root.left.left = Tree()root.left.left.name = '1'root.left.right = Tree()root.left.right.name = '2'root.right = Tree()root.right.name = 'petallength'root.right.standard = GetMedian(train_list,'petallength')root.right.left = Tree()root.right.left.name = '3'root.right.right = Tree()root.right.right.name = '4'return root
六、实验数据及结果分析:
KNN结果:
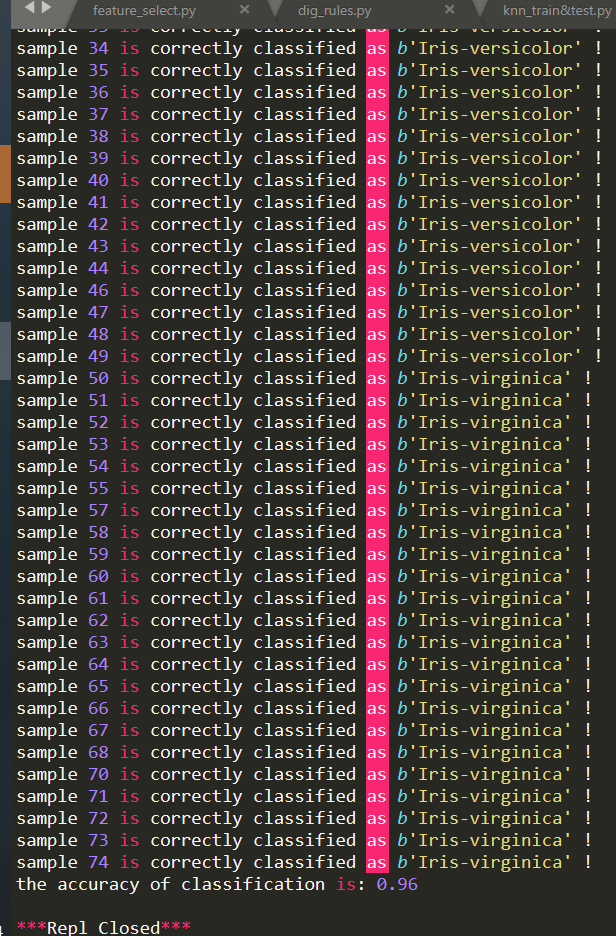
可以看到,knn算法的准确率还是比较高的,准确率高达96%
决策树结果:
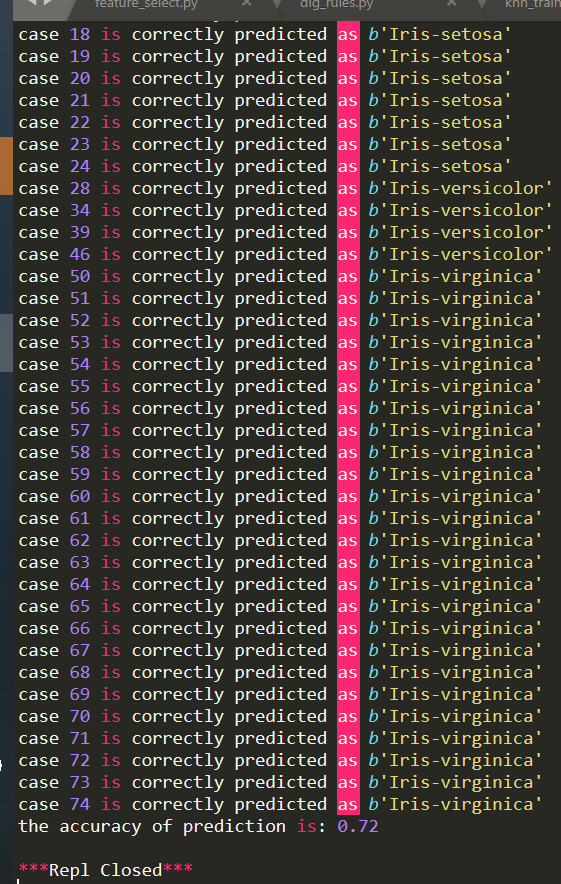
决策树算法的准确率低一点,只有72%,推测可能是因为连续数据离散化的过程中直接找中位数的模型过于简单,准确率还是基本表现不错的。
七、实验结论:
根据以上结果显示,knn的算法有96%的准确率,还是比较高了。而决策树算法的准确率只有72%,应该是连续数据离散化处理的过程中出了问题。然后我尝试使用离散数据集进行测试,发现准确率有92%,证实了我的猜想。总体来说,基本达到实验要求
八、总结及心得体会:
分类是数据挖掘中最常见的一种数据处理,他可以根据现有的数据集预测新数据的属性,有广泛的应用。例如模式识别中,涉及到的最基本的思想就是分类。了解了分类的基本方法后,对数据挖掘又有了更深一步的理解
九、对本实验过程及方法的改进建议:
可以再思考一下连续数据离散化的过程,优化一下决策树算法
报告评分:
指导老师签字:
实验四
一、实验项目名称:
聚类实验
二、实验原理:
K-Means算法即:首先随机在途中取k个点作为聚类中心,然后对途中每所有点求对这K个聚类中心的距离,将该点归到距离最近的聚类中心的簇。
然后更新簇内的聚类中心,再重复以上操作,直到聚类中心不再移动或聚类中心移动的距离小于一个阈值(Threshold),即可停止迭代。最后得到聚类的各个簇。
三、实验目的:
了解聚类的基本概念、原理和一般方法,掌握聚类的基本算法,学会调用WEKA包处理kmeans聚类问题,并自己编程实现K-Means, DBSCAN算法等
四、实验内容:
- 学会调用WEKA包处理kmeans聚类问题:
- 自己编程实现K-Means算法
以下为部分原始数据:
五、实验步骤:
完整代码详见附录:点击跳转
初始化类
首先定义一个KMeans类,用于存放聚类的结果:
class KMeans():#存放kmeans结果的类def __init__(self,data_set,k):self.data_set = data_set #原始数据集self.num = k #聚类self.data_result = self.InitResult(k) #存放聚类结果def InitResult(self,k):result_list = []for i in range(k):temp_list = [[],[]]result_list.append(temp_list)return result_list
分簇、更新聚类中心
然后GetData()读取所需要的数据。在RunTest()中,首先利用随机数初始化k个随机的聚类中心,然后开始GetCluster()将各个点分到各聚类中心的簇、UpdateCenters()更新各个簇的聚类中心:
def RunTest(data_set,k,colors,threshold):new_centers = []centers = []randlist = random.sample(range(0,len(data_set[0])),k)#初始化k个聚类中心for i in randlist:temp_center = [data_set[0][i],data_set[1][i]]new_centers.append(temp_center)result = KMeans(data_set,k)#经过更新后的聚类中心,如果没有变化,就停止迭代count = 0while new_centers != centers:centers = new_centersresult = GetCluster(centers,data_set)new_centers = UpdateCenters(centers,result.data_result,threshold)DrawScatter(result,colors,centers)
其中,用于将点分类到各个簇的GetCluster()函数和用于更新各个簇的聚类中心的UpdateCenters()函数由以下给出:
def GetCluster(centers,data_set):#根据当前的聚类中心centers进行聚类划分,返回聚类结果result = KMeans(data_set,len(centers))for i in range(len(data_set[0])):#遍历每个点min_dist = 99999min_index = 0for j in range(len(centers)):#遍历聚类中心temp_dist = math.sqrt((data_set[0][i] - centers[j][0])**2 + (data_set[1][i] - centers[j][10])**2)if temp_dist <= min_dist:min_dist = temp_distmin_index = jresult.data_result[min_index][0].append(data_set[0][i])result.data_result[min_index][11].append(data_set[1][i])return resultdef UpdateCenters(centers,cluster,threshold):#寻找新的聚类中心new_centers = []for i in range(len(centers)):#遍历每个现有的聚类中心distance = []for j in range(len(cluster[i][0])):#遍历第i类中的每个点,将之作为临时中心temp_center = [cluster[i][0][j],cluster[i][12][j]]dists = 0for m in range(len(cluster[i][0])):#计算以该点作为聚类中心的各点距离temp_dist = math.sqrt((temp_center[0] - cluster[i][0][m])**2 + (temp_center[1] - cluster[i][13][m])**2)dists += temp_distdistance.append(dists)min_dist = distance[0]for n in distance:#找到距离和最小的临时点if n <= min_dist:min_dist = nmin_index = distance.index(min_dist) #存放距离和最小点的索引temp_center = [cluster[i][0][min_index],cluster[i][14][min_index]]#判定,当新老中心点距离delta小于一个阈值时,则认为已经不用继续了delta = (centers[i][0] - temp_center[0])**2 + (centers[i][15] - temp_center[1])**2if delta >= threshold:new_centers.append(temp_center)else:new_centers.append(centers[i])return new_centers
数据可视化
最后由DrawScatter()函数画出各个簇的图像和聚类中心,并用不同颜色标注:
def DrawScatter(result,colors,centers):#转换一下centers的格式centers_trans = []temp_centersx = []temp_centersy = []for i in centers:temp_centersx.append(i[0])temp_centersy.append(i[1])centers_trans = [temp_centersx,temp_centersy]for i in range(len(result.data_result)):plt.scatter(result.data_result[i][0],result.data_result[i][16],c = colors[i],marker = '.')plt.scatter(centers_trans[0],centers_trans[1],c = colors[len(result.data_result) + 1],marker = 'o')plt.show()
参数说明
其中,RunTest()的4个参数分别是data_set k colors threshold,其中data_set代表原始数据集,k代表聚类中心的个数,colors是存放颜色参数的一个列表,threshold则是控制迭代出口的阈值,其越小聚类结果越精确。
由于k是事先给出的,所以我们还得先多尝试几个k,选出最佳的k
六、实验数据及结果分析:
由于聚类中心个数k和迭代阈值threshold需要自行给出,所以先尝试不同参数组合的结果:
k=2,threshold=1
结果如图所示:
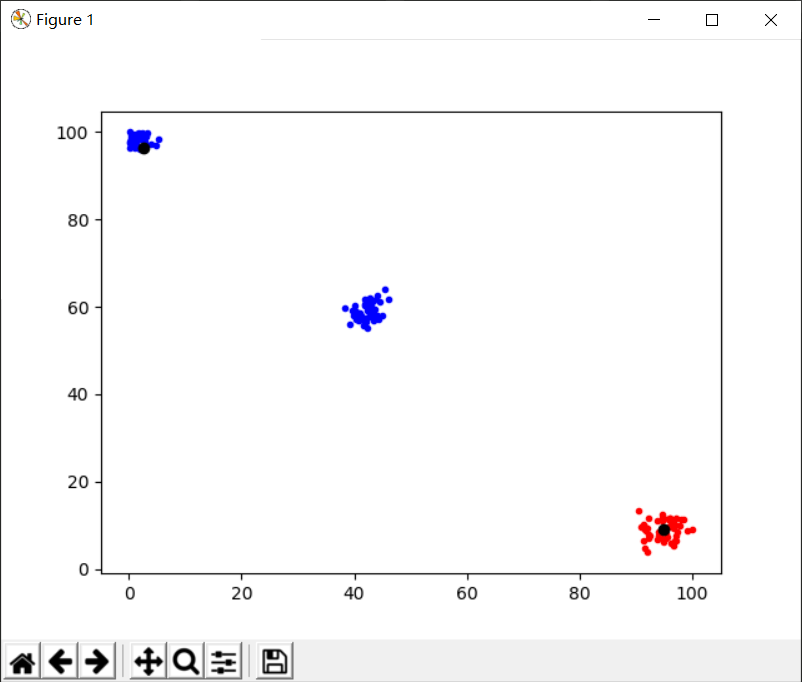
很显然,聚类中心应该为3,所以k取3较为合理
k=3,threshold=1
结果如图所示:
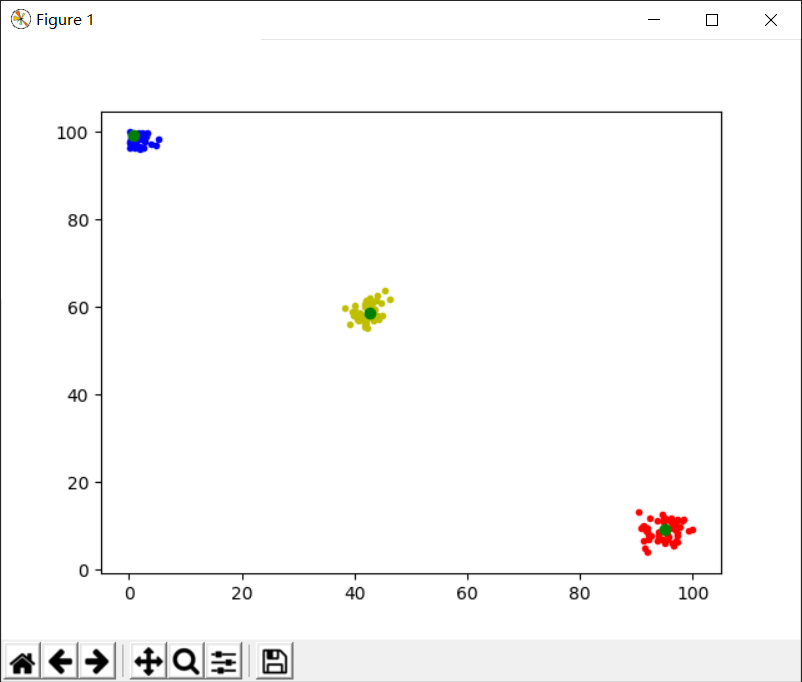
聚类效果明显,黄色和红色的聚类中心效果不错,蓝色簇的聚类中心稍偏,可以适当调小threshold
k=3,threshold=0.01
结果如图所示:
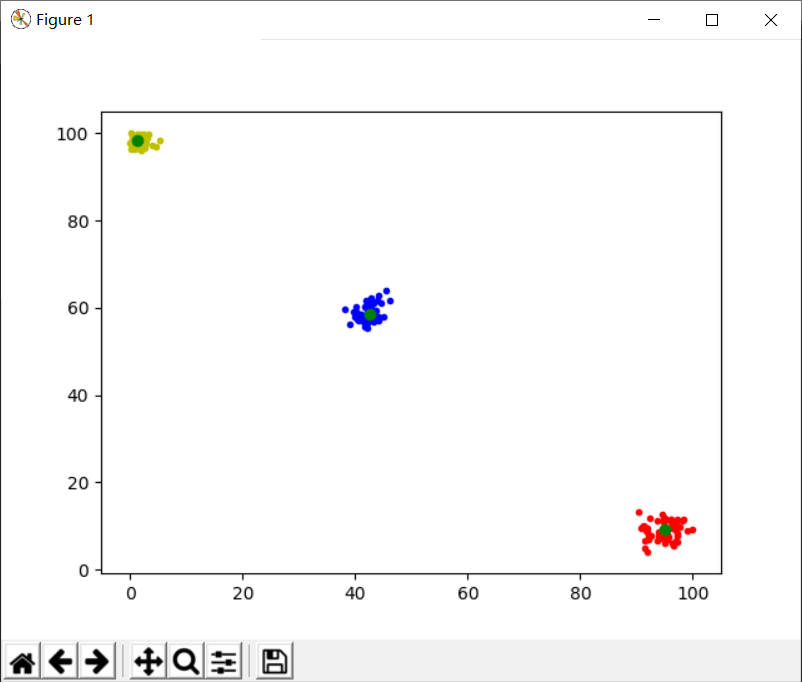
可以看出,聚类和聚类中心的效果明显好了很多,基本达到预期结果
误差分析
由于初始的k个聚类中心是随机的,而聚类结果又与初始的聚类中心是相关的,所以偶尔会出现下图这种情况。可以通过多运行几次取平均值来避免偶然误差的产生:
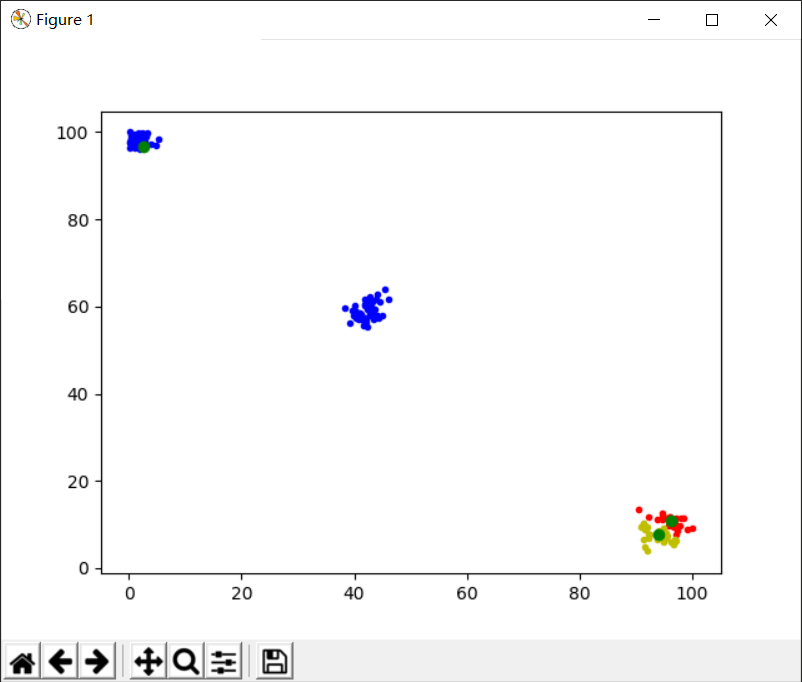
七、实验结论:
K-means算法能够有效地将无标签的数据进行自主聚类,是一种非常实用的无监督学习方式。实验结果如上,基本达到预期效果
八、总结及心得体会:
K-Means算法让人又爱又恨,他虽然十分好用,能够花费很少的计算开销就方便地得到聚类的结果,但是由于其聚类结果与初始随机聚类中心的取值有关,所以不得不多进行几次试验来去除随机误差的影响,而这无形中又增加了计算量
九、对本实验过程及方法的改进建议:
整体的实现过程没有什么问题,可以再研究一下自动调参的功能,让k和threshold这两个参数能够自动得出,效果会更好
报告评分:
指导老师签字:
附录
实验一代码
数据归一化
Normalization.py
#!/user/bin/python3#coding=utf-8import xlwtimport xlrdfrom xlutils.copy import copyclass Data():def __init__(self,sheet_data):self.maxA = 0self.minA = 0self.ori_data = self.get_data(sheet_data)self.normalized_data = self.ori_dataself.length = len(self.ori_data)self.GetMinAndMax()def get_data(self,sheet_data):#获取excel中存储的数据data = []i = 0while True:try:data.append(sheet_data.cell(i+1,0).value)i += 1except IndexError:breakreturn datadef GetMinAndMax(self):#获取数据中的最大值和最小值temp_min = self.ori_data[0]temp_max = self.ori_data[0]for i in range(self.length):if self.ori_data[i] <= temp_min:temp_min = self.ori_data[i]if self.ori_data[i] >= temp_max:temp_max = self.ori_data[i]self.maxA = temp_maxself.minA = temp_mindef Normalize(self):#数据归一化操作for i in range(self.length):self.normalized_data[i] = (self.ori_data[i] - self.minA)/(self.maxA - self.minA)# print(round(self.normalized_data[i],2))def RecordNormalizedData(self,sheet):#记录归一化的数据sheet.write(0,1,'Normalized Data')for i in range(self.length):sheet.write(i+1,1,round(self.normalized_data[i],2))book = xlrd.open_workbook('data1.xlsx')sheet_data = book.sheet_by_index(0)book_wt = copy(book)sheet_wt = book_wt.get_sheet(0)test_1 = Data(sheet_data)#数据归一化test_1.Normalize()test_1.RecordNormalizedData(sheet_wt)book_wt.save('data1.xlsx')
缺失值处理
fill_blank.py
#!/user/bin/python3#coding=utf-8import xlrdimport xlwtfrom xlutils.copy import copyclass Data():def __init__(self,sheet):self.ori_data = self.get_data(sheet)self.length = len(self.ori_data)self.filled_data = self.ori_datadef get_data(self,sheet):#获取excel中存储的数据data = []i = 0while True:try:data.append(sheet.cell(i+1,0).value)i += 1except IndexError:breakreturn datadef FillBlank(self):count = 0data_sum = 0blank_index = []for i in range(self.length):if self.ori_data[i] is not '':count += 1data_sum += self.ori_data[i]else:blank_index.append(i)aver = data_sum / countfor i in blank_index:self.filled_data[i] = round(aver,2)def RcordFilledData(self,sheet):sheet.write(0,1,'Filled Data')for i in range(self.length):sheet.write(i+1,1,self.filled_data[i])data_excel = xlrd.open_workbook('data2.xlsx')data_sheet = data_excel.sheet_by_index(0)data_wt = copy(data_excel)sheet_wt = data_wt.get_sheet(0)data = Data(data_sheet)data.FillBlank()data.RcordFilledData(sheet_wt)data_wt.save('data2.xlsx')
特征筛选
feature_select.py
#!/user/bin/python3#coding=utf-8import xlrdimport xlwtfrom xlutils.copy import copyimport mathclass Data():def __init__(self,sheet):self.nrows = sheet.nrowsself.ncols = sheet.ncolsself.table = self.get_data(sheet)self.Ent_D = self.get_Ent_D()def get_data(self,sheet):temp_table = []for i in range(self.ncols):temp_col = sheet.col_values(i)[0:self.nrows]temp_table.append(temp_col)return temp_tabledef get_feature_information(self,n):#获取第n+1列的相关信息temp_feature = Feature(self.table[n][0],self.Ent_D)dict_True = {}dict_False = {}#将数据统计进dict_True和dict_False中for i in range(1,self.nrows):if self.table[self.ncols-1][i] == '是':if self.table[n][i] in dict_True:dict_True[self.table[n][i]] += 1else:temp_dict = {self.table[n][i]:1}dict_True.update(temp_dict)elif self.table[self.ncols-1][i] == '否':if self.table[n][i] in dict_False:dict_False[self.table[n][i]] += 1else:temp_dict = {self.table[n][i]:1}dict_False.update(temp_dict)#保证两词典的键一致for i in dict_True:if i not in dict_False:temp_dict = {i:0}dict_False.update(temp_dict)for i in dict_False:if i not in dict_True:temp_dict = {i:0}dict_True.update(temp_dict)temp_feature.dict_True = dict_Truetemp_feature.dict_False = dict_False#将属性的每个状态存储在列表status中for i in dict_True:if i not in temp_feature.status:temp_feature.status.append(i)for i in dict_False:if i not in temp_feature.status:temp_feature.status.append(i)temp_feature.information_gain = temp_feature.get_information_gain()return temp_featuredef get_Ent_D(self):#获取根节点的信息熵Ent_Dcount_true = 0count_false = 0for i in self.table[self.ncols-1]:if i == '是':count_true += 1elif i == '否':count_false += 1p_true = count_true/(count_true + count_false)p_false = count_false/(count_true + count_false)Ent_D = 0 - (p_true * math.log(p_true,2) + p_false * math.log(p_false,2))return Ent_Dclass Feature():#对象的其中一个属性,例如'色泽'def __init__(self,name,Ent_D):self.name = nameself.dict_True = {}self.dict_False = {}self.status = []self.Ent_D = Ent_Dself.information_gain = 0def get_information_gain(self):#获取该属性的信息增益Ent_D_i = [] #存储该属性各个状态的信息熵p_D_i = [] #存储该属性各个状态的比例sample_quantity = 0result = 0for i in self.dict_True:sample_quantity += self.dict_True[i]for i in self.dict_False:sample_quantity += self.dict_False[i]for i in self.status:total = self.dict_True[i] + self.dict_False[i]if self.dict_True[i] != 0:if self.dict_False[i] != 0:temp_Ent_D_i = 0 - ((self.dict_True[i]/total) * math.log(self.dict_True[i]/total,2) + (self.dict_False[i]/total) * math.log(self.dict_False[i]/total,2))else:temp_Ent_D_i = 0 - self.dict_True[i]/total * math.log(self.dict_True[i]/total,2)else:temp_Ent_D_i = 0 - self.dict_False[i]/total * math.log(self.dict_False[i]/total,2)#input()temp_p = total/sample_quantityEnt_D_i.append(temp_Ent_D_i)p_D_i.append(temp_p)for i in range(len(Ent_D_i)):result += Ent_D_i[i] * p_D_i[i]result = self.Ent_D - result#print('gain is :',result)return resultbook = xlrd.open_workbook('data3.xlsx')sheet_rd = book.sheet_by_index(0)book_wt = copy(book)sheet_wt = book_wt.get_sheet(0)data = Data(sheet_rd)features = []for i in range(1,data.ncols-3):temp_feature = data.get_feature_information(i)features.append(temp_feature)#print(data.table)sheet_wt2 = book_wt.get_sheet(1)sheet_wt2.write(1,0,'信息增益')for i in range(1,data.ncols-3):sheet_wt2.write(0,i,features[i-1].name)sheet_wt2.write(1,i,round(features[i-1].information_gain,3))book_wt.save('data3.xlsx')print('Ent_D of the root note is:',round(data.Ent_D,3))for i in features:print('the information gain of',i.name,'is :',round(i.information_gain,3))
实验二代码
关联规则挖掘:
dig_rules.py
#!/user/bin/python3#coding=utf-8import xlrdimport xlwtclass Node():def __init__(self,total):self.content = []self.data = []self.sup = 0self.total = total#更新当前层,剪枝def UpdateLayer(ori_list,threshold):temp_list = []for i in ori_list:if i.sup > threshold:temp_list.append(i)return temp_list#连接上层生成下层def GenNewLayer(ori_list):new_list = []for i in ori_list:for j in ori_list:if i != j:new_list.append(Merge(i,j))return new_list#Merge函数合并a,b两个结点def Merge(a,b):temp = Node(a.total)#合并self.content的内容,并去重for i in a.content:temp.content.append(i)for i in b.content:if i not in a.content:temp.content.append(i)#统计data和sup的内容count = 0for i in range(a.total):if a.data[i] == b.data[i] and a.data[i] == 1:count += 1temp.data.append(1)else:temp.data.append(0)temp.sup = countreturn tempdef ReadData(sheet):temp_layer = []for i in range(1,sheet.ncols):temp_node = Node(sheet.nrows - 1)temp_node.content.append(sheet.cell(0,i).value)count = 0for j in range(1,sheet.nrows):if sheet.cell(j,i).value == 1:count += 1temp_node.data.append(int(sheet.cell(j,i).value))temp_node.sup = counttemp_layer.append(temp_node)return temp_layerbook = xlrd.open_workbook('data.xlsx')sheet = book.sheet_by_index(0)layer1 = ReadData(sheet)layer1 = UpdateLayer(layer1,2)layer2 = GenNewLayer(layer1)layer2 = UpdateLayer(layer2,2)for i in layer2:print(i.content,';',i.data,';',i.sup/i.total)
实验三代码
临时锚点
KNN分类
knn_train&test.py
#!/user/bin/python3#coding=utf-8#KNNfrom scipy.io import arffimport pandas as pdimport mathclass Node():def __init__(self):self.petallength = 0self.petalwidth = 0self.classes =''def GetData(df):#读取arff文件,将每一行存成一个Node类,存在data_list列表中data_list = []ptl = df['petallength'].valuesptw = df['petalwidth'].valuesclasses = df['class'].valuesnum = len(ptl)for i in range(num):temp_node = Node()temp_node.petallength = ptl[i]temp_node.petalwidth = ptw[i]temp_node.classes = classes[i]data_list.append(temp_node)return data_listdef GetDist(node_a,node_b):#计算两点的距离distance = math.sqrt((node_a.petallength - node_b.petallength)**2 + (node_a.petalwidth - node_b.petalwidth)**2)return distancedef Predict(train_list,node_a,k):#开始预测数据dist_list = [] #存放离各点距离index_list = [] #存放K邻近的点的索引indexfor i in train_list:dist_list.append(GetDist(node_a,i))dist_copy = dist_listfor i in range(k): #寻找k邻近的索引值,并存放在index_list中temp_min = 999temp_index = 0for j in range(len(train_list)):if dist_copy[j] <= temp_min:temp_min = dist_copy[j]temp_index = jdist_copy[temp_index] = 999index_list.append(temp_index)classes = {}#统计k邻近的分类结果,并以字典形式存放在classes中for i in index_list:if train_list[i].classes not in classes:classes[train_list[i].classes] = 1else:classes[train_list[i].classes] += 1result = ''max_times = 0#选取次数最多的分类结果并存放在result中for i in classes:if classes[i] >= max_times:max_times = classes[i]result = ireturn resultdef RunTest(train_list,test_list,k):#开始运行测试count = 0for i in test_list:result = Predict(train_list,i,k)if i.classes == result: #判断预测结果与标签是否相符count += 1print('sample',test_list.index(i),'is correctly classified as',i.classes,'!')rate = float(count / len(test_list))return ratedata_train = arff.loadarff('iris.2D.train.arff')df_train = pd.DataFrame(data_train[0])train_list = GetData(df_train)data_test = arff.loadarff('iris.2D.test.arff')df_test = pd.DataFrame(data_test[0])test_list = GetData(df_test)'''for i in test_list:print(i.petallength,i.petalwidth,i.classes)'''rate = RunTest(train_list,test_list,3)#输出最后的预测准确率print('the accuracy of classification is:',rate)
决策树分类
decision_tree.py
#!/user/bin/python3#coding=utf-8#KNNfrom scipy.io import arffimport pandas as pdimport numpy as npimport mathclass Node():def __init__(self):self.petallength = 0self.petalwidth = 0self.classes =''class Tree():def __init__(self):self.name = ''self.standard = 0self.left = Noneself.right = Nonedef GetData(df):#读取arff文件,将每一行存成一个Node类,存在data_list列表中data_list = []ptl = df['petallength'].valuesptw = df['petalwidth'].valuesclasses = df['class'].valuesnum = len(ptl)for i in range(num):temp_node = Node()temp_node.petallength = ptl[i]temp_node.petalwidth = ptw[i]temp_node.classes = classes[i]data_list.append(temp_node)return data_listdef GenTree(train_list):root = Tree()gain = []gain.append(GetGain(train_list,'petallength'))gain.append(GetGain(train_list,'petalwidth'))if gain[0] >= gain[1]:root.name = 'petallength'root.standard = GetMedian(train_list,'petallength')root.left = Tree()root.left.name = 'petalwidth'root.left.standard = GetMedian(train_list,'petalwidth')root.left.left = Tree()root.left.left.name = '1'root.left.right = Tree()root.left.right.name = '2'root.right = Tree()root.right.name = 'petalwidth'root.right.standard = GetMedian(train_list,'petalwidth ')root.right.left = Tree()root.right.left.name = '3'root.right.right = Tree()root.right.right.name = '4'else:root.name = 'petalwidth'root.standard = GetMedian(train_list,'petalwidth')root.left = Tree()root.left.name = 'petallength'root.left.standard = GetMedian(train_list,'petallength')root.left.left = Tree()root.left.left.name = '1'root.left.right = Tree()root.left.right.name = '2'root.right = Tree()root.right.name = 'petallength'root.right.standard = GetMedian(train_list,'petallength')root.right.left = Tree()root.right.left.name = '3'root.right.right = Tree()root.right.right.name = '4'return rootdef GetGain(train_list,name):#计算信息增益if name is 'petallength':data_list = []for i in train_list:data_list.append(i.petallength)median = np.median(data_list)ent_d = GetEnt(train_list)d_list = []temp_list = []for i in train_list:if i.petallength >= median:temp_list.append(i)d_list.append(temp_list)gain = ent_dfor i in d_list:gain = gain - len(i)*GetEnt(i)/len(train_list)return gainelif name is 'petalwidth':data_list = []for i in train_list:data_list.append(i.petalwidth)median = np.median(data_list)ent_d = GetEnt(train_list)d_list = []temp_list = []for i in train_list:if i.petalwidth >= median:temp_list.append(i)d_list.append(temp_list)gain = ent_dfor i in d_list:gain = gain - len(i)*GetEnt(i)/len(train_list)return gaindef GetEnt(train_list):#计算信息熵count = {}for i in train_list:if i.classes not in count:count[i.classes] = 1elif i.classes in count:count[i.classes] += 1total = 0for i in count:total += count[i]ent = 0for i in count:ent = ent - count[i]/total * math.log(2,count[i]/total)return entdef GetMedian(train_list,name):if name is 'petallength':data_list = []for i in train_list:data_list.append(i.petallength)median = np.median(data_list)elif name is 'petalwidth':data_list = []for i in train_list:data_list.append(i.petalwidth)median = np.median(data_list)return mediandef print_all(root):if root.left is not None:print('name:',root.name,'standard:',root.standard)print_all(root.left)print_all(root.right)if root.left is None:print('type:',root.name)def RunTest(root,test_list,name):count = 0for i in test_list:if root.name is 'petallength':#petallength -> petalwidthif i.petallength >= root.standard:#leftif i.petalwidth >= root.left.standard:#left.leftpred = root.left.left.nameelse:##left.rightpred = root.left.right.nameelse:#rightif i.petalwidth >= root.right.standard:#right.leftpred = root.right.left.nameelse:#right.rightpred = root.right.right.nameelif root.name is 'petalwidth':#petalwidth -> petallengthif i.petalwidth >= root.standard:#leftif i.petallength >= root.left.standard:#left.leftpred = root.left.left.nameelse:##left.rightpred = root.left.right.nameelse:#rightif i.petallength >= root.right.standard:#right.leftpred = root.right.left.nameelse:#right.rightpred = root.right.right.nameresult = ''if pred is '1':result = name[2]elif pred is '2':result = name[1]elif pred is '3' or pred is '4':result = name[0]# print('i.classes:',i.classes,'; result:',result)if result == i.classes:count += 1print('case',test_list.index(i),'is correctly predicted as',i.classes)rate = float(count/len(test_list))return ratedata_train = arff.loadarff('iris.2D.train.arff')df_train = pd.DataFrame(data_train[0])train_list = GetData(df_train)data_test = arff.loadarff('iris.2D.test.arff')df_test = pd.DataFrame(data_test[0])test_list = GetData(df_test)decision_tree = GenTree(train_list)name = []for i in train_list:if i.classes not in name:name.append(i.classes)#print_all(decision_tree)rate = RunTest(decision_tree,test_list,name)print('the accuracy of prediction is:',rate)
实验四代码
临时锚点2
K-Means聚类算法
k_means.py
#!user/bin/python3#coding=utf-8import xlrdimport xlwtimport matplotlib.pyplot as pltimport mathimport randomclass KMeans():#存放kmeans结果的类def __init__(self,data_set,k):self.data_set = data_set #原始数据集self.num = k #聚类self.data_result = self.InitResult(k) #存放聚类结果def InitResult(self,k):result_list = []for i in range(k):temp_list = [[],[]]result_list.append(temp_list)return result_listdef GetData(sheet):data_set = []col_1 = sheet.col_values(0)[1:]col_2 = sheet.col_values(1)[1:]data_set.append(col_1)data_set.append(col_2)return data_setdef DrawScatter(result,colors,centers):#转换一下centers的格式centers_trans = []temp_centersx = []temp_centersy = []for i in centers:temp_centersx.append(i[0])temp_centersy.append(i[1])centers_trans = [temp_centersx,temp_centersy]for i in range(len(result.data_result)):plt.scatter(result.data_result[i][0],result.data_result[i][1],c = colors[i],marker = '.')plt.scatter(centers_trans[0],centers_trans[1],c = colors[len(result.data_result) + 1],marker = 'o')plt.show()def GetCluster(centers,data_set):#根据当前的聚类中心centers进行聚类划分,返回聚类结果result = KMeans(data_set,len(centers))for i in range(len(data_set[0])):#遍历每个点min_dist = 99999min_index = 0for j in range(len(centers)):#遍历聚类中心temp_dist = math.sqrt((data_set[0][i] - centers[j][0])**2 + (data_set[1][i] - centers[j][1])**2)if temp_dist <= min_dist:min_dist = temp_distmin_index = jresult.data_result[min_index][0].append(data_set[0][i])result.data_result[min_index][1].append(data_set[1][i])return resultdef UpdateCenters(centers,cluster,threshold):#寻找新的聚类中心new_centers = []for i in range(len(centers)):#遍历每个现有的聚类中心distance = []for j in range(len(cluster[i][0])):#遍历第i类中的每个点,将之作为临时中心temp_center = [cluster[i][0][j],cluster[i][1][j]]dists = 0for m in range(len(cluster[i][0])):#计算以该点作为聚类中心的各点距离temp_dist = math.sqrt((temp_center[0] - cluster[i][0][m])**2 + (temp_center[1] - cluster[i][1][m])**2)dists += temp_distdistance.append(dists)min_dist = distance[0]for n in distance:#找到距离和最小的临时点if n <= min_dist:min_dist = nmin_index = distance.index(min_dist) #存放距离和最小点的索引temp_center = [cluster[i][0][min_index],cluster[i][1][min_index]]#判定,当新老中心点距离delta小于一个阈值时,则认为已经不用继续了delta = (centers[i][0] - temp_center[0])**2 + (centers[i][1] - temp_center[1])**2if delta >= threshold:new_centers.append(temp_center)else:new_centers.append(centers[i])return new_centersdef RunTest(data_set,k,colors,threshold):new_centers = []centers = []randlist = random.sample(range(0,len(data_set[0])),k)#初始化k个聚类中心for i in randlist:temp_center = [data_set[0][i],data_set[1][i]]new_centers.append(temp_center)result = KMeans(data_set,k)#经过更新后的聚类中心,如果没有变化,就停止迭代count = 0while new_centers != centers:centers = new_centersresult = GetCluster(centers,data_set)new_centers = UpdateCenters(centers,result.data_result,threshold)DrawScatter(result,colors,centers)book = xlrd.open_workbook('dataset.xlsx')sheet = book.sheet_by_index(0)data_set = GetData(sheet)colors = ['b','r','y','k','g','m','c','w']RunTest(data_set,3,colors,0.01)'''for i in range(10):RunTest(data_set,i,colors)'''
