@Bruce1Tone
2021-12-19T01:16:18.000000Z
字数 13491
阅读 683
操作系统服用手册
计算机
操作系统概述
操作系统的作用:
管理计算机的资源,包括存储、设备等资源
OS的特征
四大特征:并发、共享、虚拟、异步
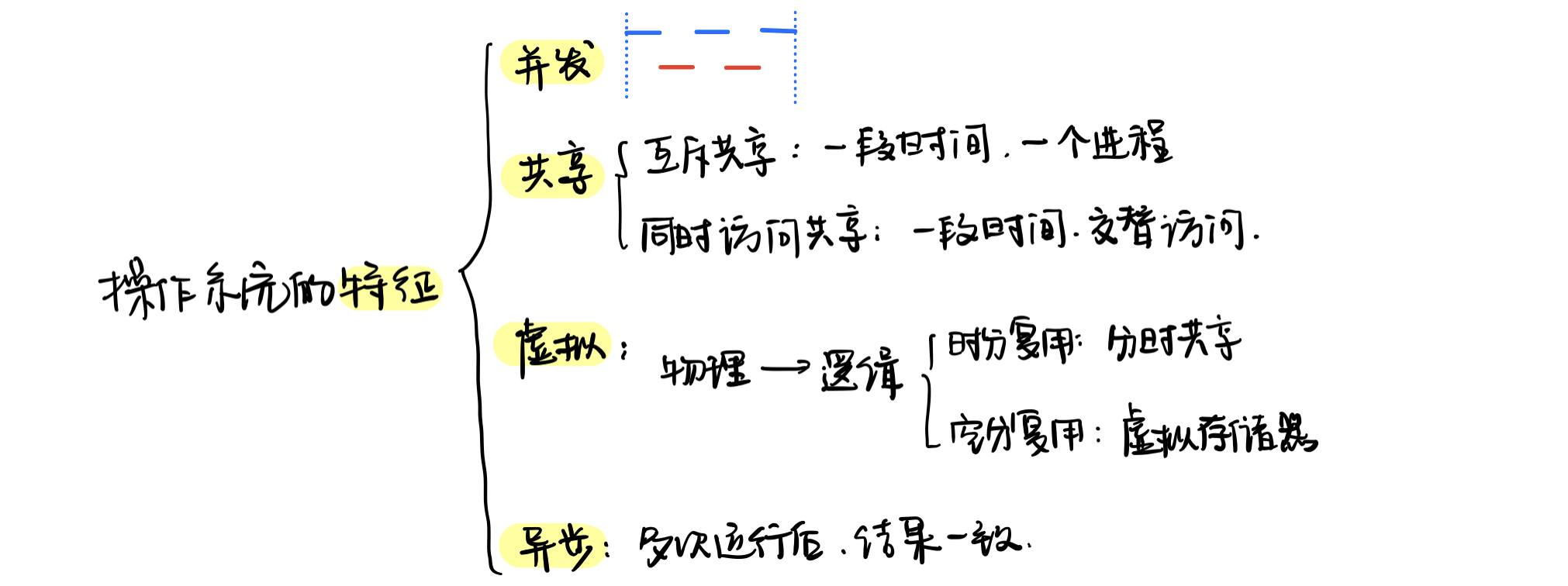
封闭性
指程序的运行只与自己有关,在不同速度下运行结果一致
并发进程将失去封闭性:导致进程在不同速度下运行,结果不一样
接口
操作系统=连接
用户和计算机硬件的接口
操作系统分类
中断和异常
中断:即广义中断,包括外中断(中断)和内中断(异常)
广义中断是让
用户态到内核态的唯一途径,通过硬件实现
中断(外中断)
定义:与当前执行程序无关的中断,
比如:
IO结束中断,时钟中断
异常(内中断)
定义:与当前执行程序有关的中断,也叫
陷入(trap)比如:除以0,地址越界,非法操作码,虚存系统的缺页等
中断处理的过程
【群众】硬件来完成:
a. 【拉警戒线】关中断:保存断点过程中不受打扰
b. 【记录案发地址】保存断点(程序计数器PC):运行到哪个程序了?注意:
PC由硬件自动保存,通用寄存器由操作系统存储c. 【报警】中断服务器寻址:找
中断服务程序让他起来干活了- 【警察】中断程序完成:在内核态中
a. 【记录现场情况】保存现场和屏蔽字:包括程序状态寄存器PSWR和一些通用寄存器
b. 【警察进警戒线】开中断:我要进来啦
c. 【主业务】执行中断服务程序
d. 【重新拉上警戒线】关中断:外面的别打扰,爷要开始恢复断点了
e. 【恢复现场】恢复现场和屏蔽字
f. 【撤警戒线】开中断
g. 【开溜】中断返回
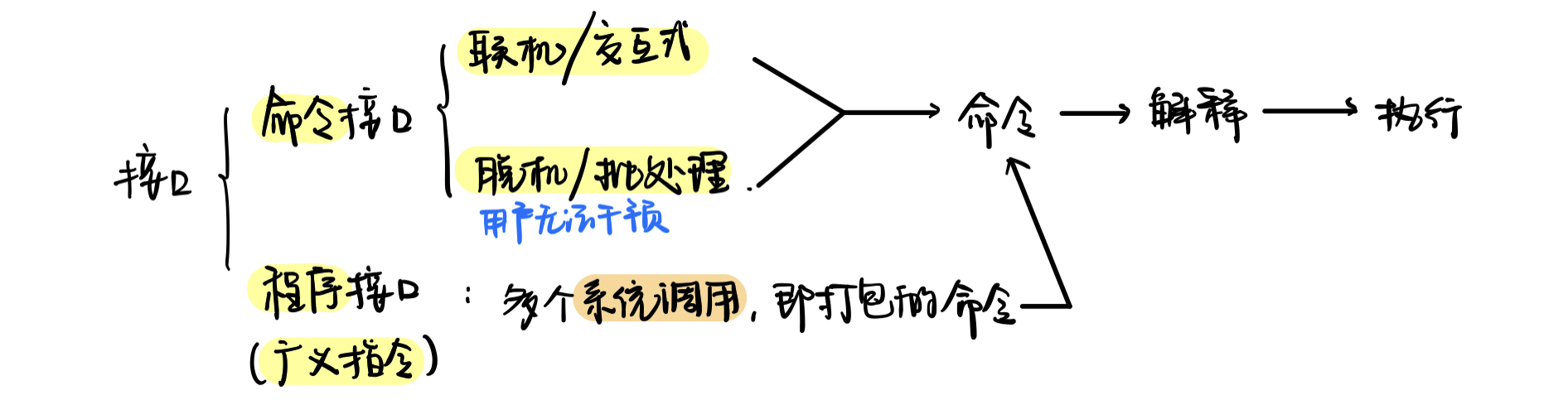
系统调用
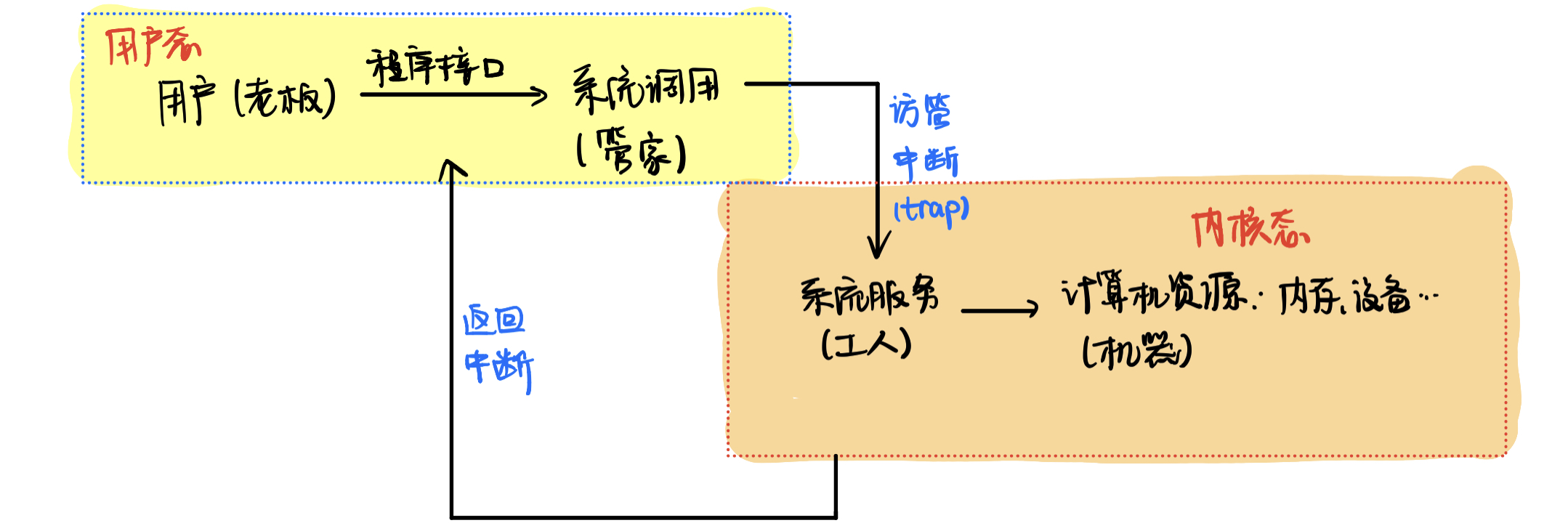
核心态与用户态
- 核心态:可以使用所有指令,除了
访管指令/trap
- 在核心态,处理的事情是:水杯放在哪里?哪里能放?哪里不能放?哪里空着?
- 用户态:不能直接使用
特权指令
- 在用户态:实现运算、赋值、调用数学函数等,即杯子里装了啥玩意
特权指令:
计算机内涉及资源的重要指令,用户不能直接用,得用系统调用来实现:
只能在核心态才能执行
例如:
清内存,置时钟,修改虚存的段表或页表等
访管指令trap
在
用户态时调用,然后将进入内核态
系统调用
应用程序只能通过系统调用来实现对计算机的操作,一系列的系统调用就叫程序接口
系统调用就是个传话的
操作系统的体系结构
大内核
工厂大,系统服务很多,即各种工种的工人都有
优点:性能好
缺点:维护麻烦
小内核
工厂小,系统服务就只有最基本的,即只有基本工种
优点:维护简单,结构清晰,系统稳定,添加系统服务不用修改内核
缺点:执行开销大,效率低,需要在用户态和核心态之间频繁切换
进程管理
进程与线程
进程
进程映像(即进程的实体)的组成:
- 程序段
- 相关数据段
- 进程控制块PCB:进程存在的唯一标志
注意:
进程映像是静态的
进程是动态的
进程的状态
- 运行态:
- 就绪态:
缺CPU(处理机),其他资源全部就位。只差CPU了,来了就可以运行- 阻塞态/等待态:
缺其他资源,哪怕CPU来了也无法运行。
常见的比如:缺内存;等待输入;I/O操作等- 创建态:
a. 申请PCB,并在PCB记录进程相关信息
b. 分配进程所需要的资源
c. 进入就绪- 结束态:
先置于结束态,才能进行资源回收
仅有
运行到阻塞是进程自己能够决定的
唤醒:指阻塞到运行的切换过程
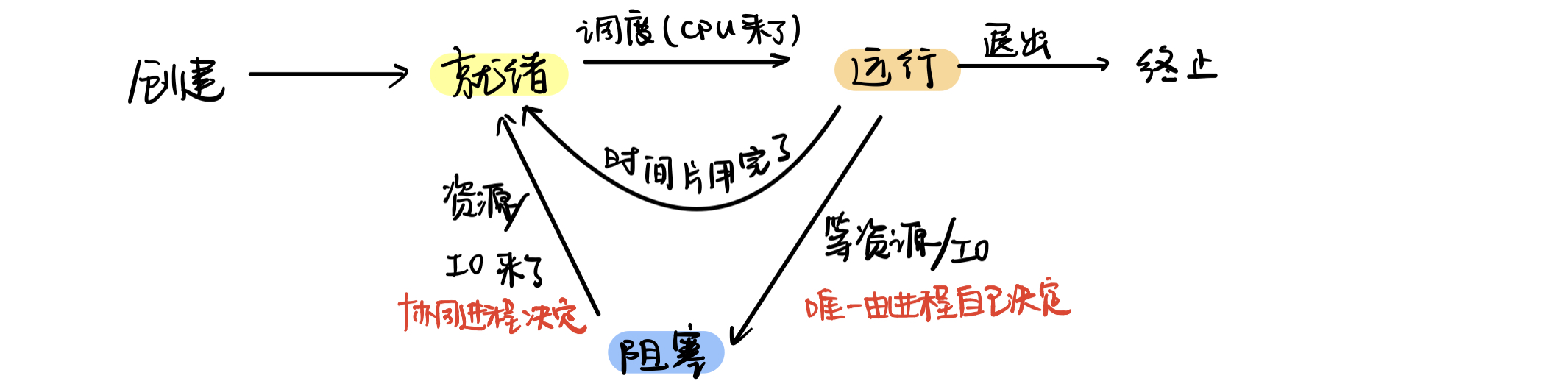
进程的切换
进程切换:处理机(CPU)从一个进程的运行,转到另一个进程的运行
注意区分
调度和切换:
- 调度:决策行为
决策资源该如何分配- 切换:执行行为
先有调度,然后再执行切换
进程间的通信
共享存储
通过
共享空间实现,需要同步互斥工具(P、V)
我放到袋子里,你从袋子里拿。但你不能直接拿我手里的东西消息传递
a. 直接通信:
我把东西扔到你的包里(消息缓冲队列)
b. 间接通信(信箱通信方式):
我把东西扔到信箱(第三方中间实体),你自己去拿管道通信pipe:
固定大小管道(如Linux的4KB)
同一时刻,管道只能在一个方向传输(半双工通信)
写:只有管道为空的时候,才能写,否则阻塞写进程;且只有写满了才让读
读:只要管道不为空,就可以读
线程
进程&线程对比
| 种类 | 内容 | 有无资源 | 能否独立执行 | 好处目的 | 备注 |
|---|---|---|---|---|---|
| 进程 | PCB、程序段、数据段 | 有自己的资源 | 能独立执行 | 提高CPU利用率 提高吞吐量 |
资源分配的最小单位 |
| 线程 | 线程控制块、唯一标识符 | 没有 | 能独立执行 | 减小并发执行的时空开销(切换),提高并发性能 | 自己没有资源,和其他线程共同继承进程的所有资源 |
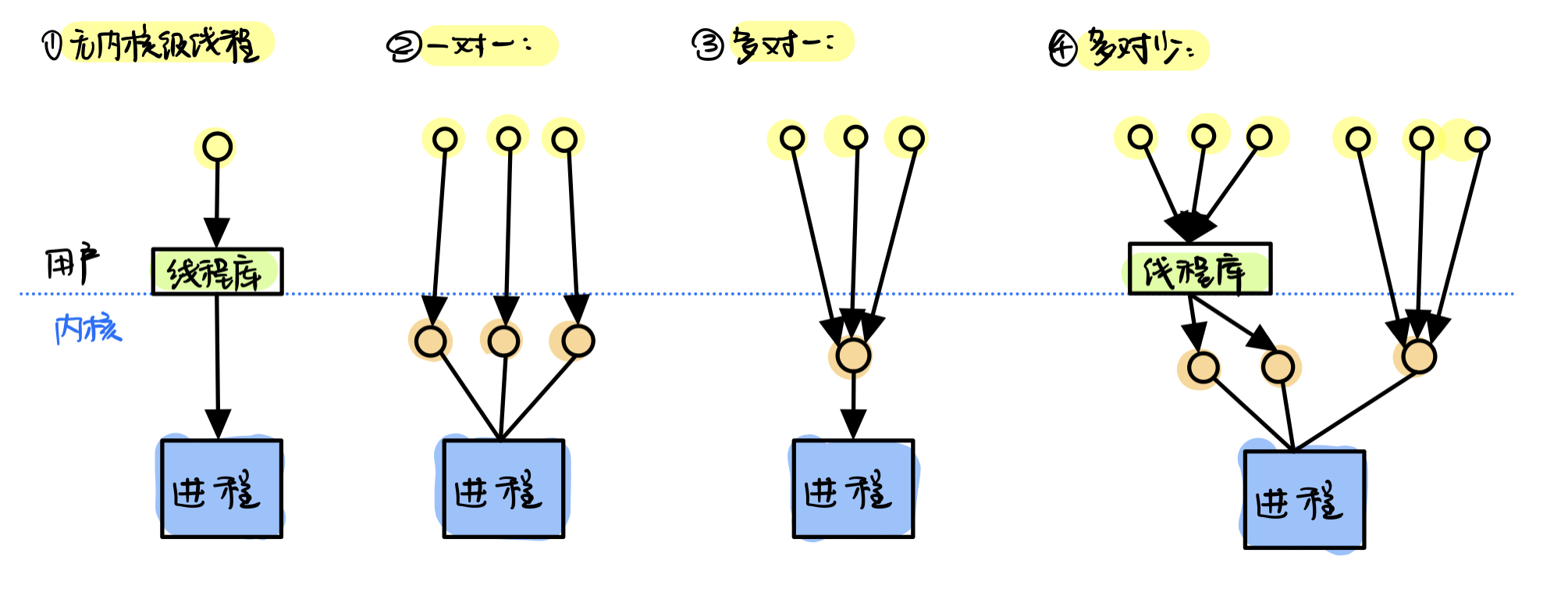
线程的实现方式
- 用户级线程:
所有工作都由应用程序完成,用户调用线程库来实现多线程
但是内核意识不到
可以直接把用户级线程映射到内核里的进程,而不需要对应的内核级线程- 内核级线程:
所有工作都由内核完成,应用程序中没有线程管理的代码
多线程模型
- 一对一:
每个用户级线程都为他建立一个内核级线程
优点:并发能力强,一个阻塞了不影响其他
缺点:创建线程开销大- 多对一:
多个用户级线程共用一个内核级线程,且内核看不到用户级线程,因此以为只有1个内核里的线程
优点:线程管理在用户空间,效率比较高
缺点:一个线程在使用内核服务时被阻塞,其他所有都无法运行- 多对少:
综合以上两个模型,多个用户级线程对应少个内核级线程
处理机CPU调度
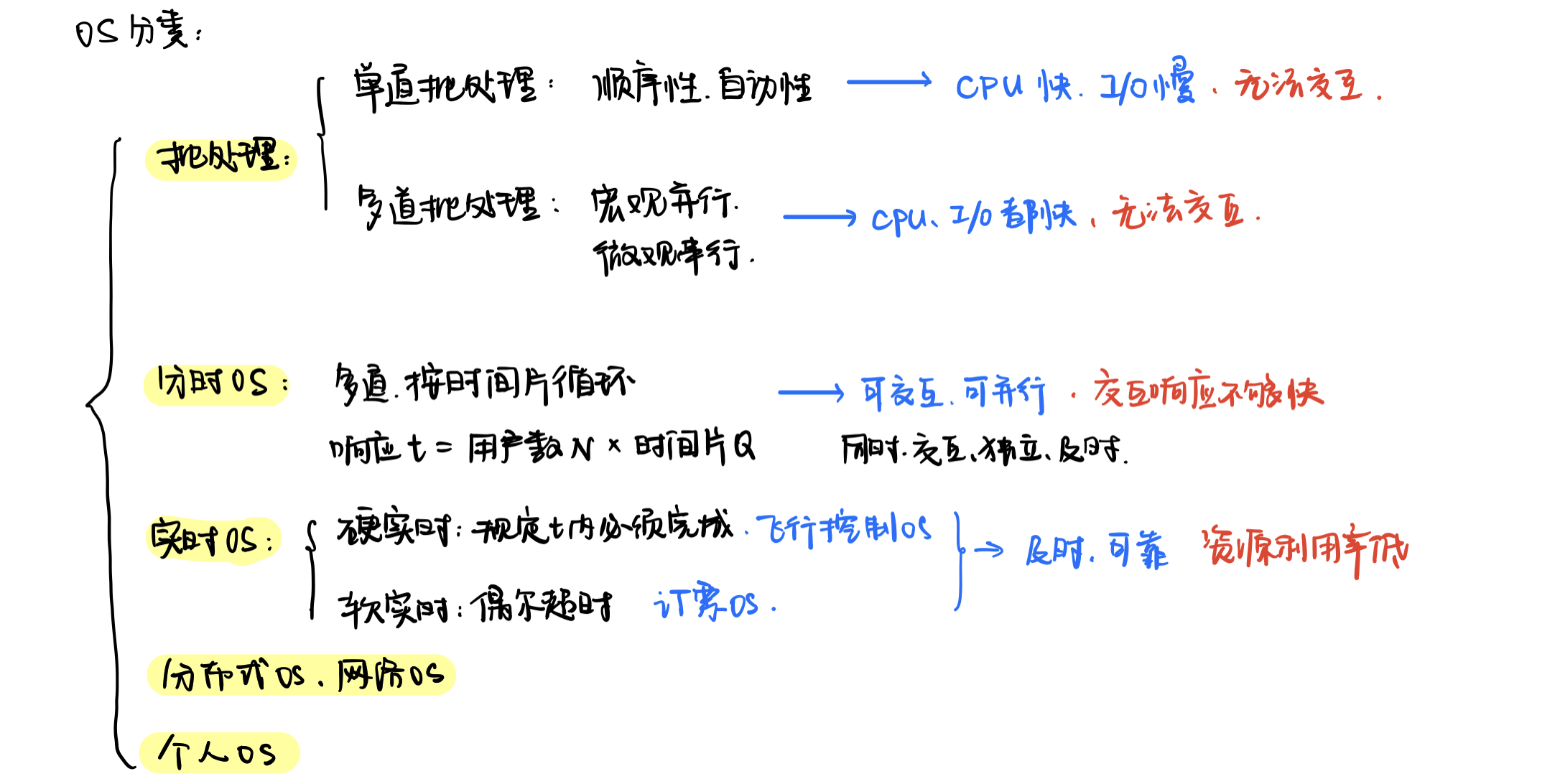
三个级别的调度
- 高级调度/作业调度:
负责调度大的作业,并建立进程,分配资源
每个作业只调入一次,调出一次,频率很低- 中级调度/内存调度:
负责挂起暂时不能运行的进程,将之从内存挂起到外存
当条件充分且内存空了,再把他们重新调入内存- 低级调度/进程调度:
负责将处理机在进程间分配,操作系统中必须有进程调度,且频率很高
调度的时机
不能进程调度的时机:
- 处理中断的时候
- 进程在内核程序的
临界区- 需要完全屏蔽
中断的原子操作过程
如:加锁解锁中断现场保护恢复
进程的调度方式
- 非剥夺式调度/非抢占式调度:
等他主动交出处理机,完事了再把处理机分配给别人
优点:简单,开销小,适用于批处理系统
缺点:不能用于分时和实时系统
参考量
- CPU利用率:
- 系统吞吐量:
单位时间内CPU完成作业的数量- 周转时间:
从作业提交申请到作业完成的时间
a. 周转时间 = 等待时间 + 运行时间
b. 平均周转时间 = 总周转时间 / 作业数
c. 带权周转时间 = 周转时间 / 运行时间- 等待时间:
在就绪队列中待到被分配CPU的时间- 响应时间:
从用户提交请求到首次产生响应的时间
调度算法
1. 先来先服务FCFS
可以用于
作业调度和进程调度,属于不可剥夺算法
优点:长作业有利,CPU繁忙适合
缺点:短作业不利,如果前面来了个长作业就不好;I/O繁忙不适合
2. 短作业优先SJF
选择
估计运行时间最短的,先开始分配CPU
优点:平均等待时间和平均周转时间最少
缺点:不适合长作业,容易发生饥饿;未考虑紧迫程度;用户估计时间误差饥饿:长期得不到调用,和死锁不同
3. 优先级调度
- 剥夺不剥夺:
a. 剥夺式优先级:新任务来了优先级高,必须马上停
b. 非剥夺式优先级:新任务来了先等着,执行完这个了再谈分配- 优先级是否能变:
a. 静态优先级:可能会饥饿
b. 动态优先级:根据等待了多久和运行了多久动态调整,不会饥饿优先级的设计原则:
- 系统进程 > 用户进程
- 交互进程 > 非交互进程
- I/O进程 ? 计算进程:
因为IO慢,计算快,先IO了再计算,IO就可以腾出来给其他进程
4. 高响应比优先
主要用于
作业调度:
响应比:
兼顾了长作业、短作业。
如果运行时间相同,则FCFS
5. 时间片轮转
主要用于
分时系统,用户响应快:
多个用户可以及时干预系统
每个进程先后获得时间片,时间片完了就换人(算是抢占)
时间片的长度影响效率:
- 时间片太长:
变成了FCFS- 时间片太短:
切换开销太大
6. 多级反馈队列(大融合)
- 多个队列
Q1Q2...
且优先级Q1最高,然后其次- 队内用
时间片轮转,如果一转没处理完,则进程剩余部分进入下一个队列
且,优先级越高的队列,时间片越小- 只有等
Q1处理完了才处理Q2,以此类推
进程同步
基本概念
临界资源
临界资源:一次只允许一个进程使用的资源,很多物理设备都是
临界区:用于访问临界资源的代码
比如 打印机
临界区使用分为4个区:
- 进入区:检查是否可以进入
- 临界区
- 退出区
- 剩余区:代码的其他部分
同步与互斥
同步/直接制约关系:工作不能同时进行,且必须要按照一定的次序依次进行
互斥/间接制约关系:工作不能同时进行,但是顺序任意
共享缓冲区一定是互斥访问的
同步机制遵循:
- 空闲让进
- 忙则等待
- 有限等待
- 让权等待:进不去的时候,应该立即释放处理器,防止进程忙等待
软件实现
单标志法
设定
turn,turn等于几,就允许几号变量进入
缺点:必须交叉进入,如果一个人不想进,另一个永远进不了
双标志先检查
设定
flag[i]代表进程i想不想进临界区
初始flag=False
- 先检查对方想不想进?如果对面想,就一直循环等待
- 对面不想进,自己进
- 出来之后把自己的
flag调回FALSE缺点:可能发生俩人同时进去
双标志后检查
设定
flag[i]代表进程i想不想进临界区
- 先设定自己的
flag=True- 再检查对方想不想进?
- 对面不想进,自己进
- 出来之后把自己的
flag调回FALSE缺点:可能俩人互相谦让,谁也进不去
Peterson's Algorithm
设定
turn表示轮到谁了
设定flag[i]表示进程i想不想进临界区
- 自己
flag=True表示自己想进,然后谦让一下把turn设成对方- 如果对方
flag=True且turn也是对方,则谦让一下,自己一直循环等待- 如果不满足循环条件,就进入
临界区- 出来之后把自己的
flag调回FALSE评价:
flag解决互斥访问,turn解决饥饿
满足有限等待,但不满足让权等待
硬件实现方法
又叫低级方法或者元方法
中断屏蔽
又叫
屏蔽中断关中断
- 关中断
- 进入临界区
- 开中断
TestAndSet指令
TestAndSet:读取并返回该变量,完事了把这个变量设为True
lock:bool变量,代表临界区是否正在被访问
实现进程互斥的伪代码:
#要是lock = True,表示别人在用,自己就一直等#要是lock = False,表示没人用,则自己开始用并把他设成True,表示我在用while TestAndSet(lock) == Ture;临界区;lock = False;
Swap指令
swap(A,B):表示交换A和B的值
lock:bool变量,代表临界区是否正在被访问
key:临时bool变量,存放一个临时值,用完了就销毁
本质上和TestAndSet一回事!
伪代码如下:
key = Truewhile key == True:swap(lock,key)// 表示当lock = True时,即别人在用,自己就会一直循环等待// 当lock = False时,没人在用,就自己用,并且把lock值变成True,表示自己占用临界区;lock = Flase;
信号量
PV操作
P/wait(S):请求一个资源,信号量-1
V/signal(S):释放一个资源,信号量+1
信号量分类
| 信号量种类 | P操作/wait | V操作/signal | 备注 |
|---|---|---|---|
| 整型信号量 | while(s<=0); s=s-1; |
s=s+1 | 不满足让权等待,即如果s<=0则会反复检查而不是让出CPU,即 忙等 |
| 记录型信号量 | s.value --; 若小于0,则 自我阻塞并移到阻塞队列 |
s=s+1;如果s<=0 则唤醒一个阻塞进程 |
满足所有要求 |
信号量的基本应用
信号量实现同步
同步:即并发进程中,必须等这条执行完了,那条才能执行
实现方法:
- 先执行的语句:
结尾加一句V(S)释放信号量,意思是我做完了,你们可以开工了- 后执行的语句:
开头加一句P(S)请求资源,只有S>0时才能做S初始值为0
信号量实现互斥
互斥:我用这个的时候,任何人都不准碰
实现方法:
- 任意互斥的语句:
P(S):请求资源,如果没有可用资源就会被阻塞- 执行要执行的语句
V(S):释放资源,意思是我用完了,其他人可以来了S初始值为1
信号量实现前驱后继
即AOE网的每个节点该怎么实现,每条边设置一个信号量:
- 每个节点:
- P(所有
父节点的信号量);即检查所有的父节点有没有完成?都完成了才能开始- 执行要执行的语句
- V(所有
子节点的信号量):即释放信号给所有子节点,意思是我做完了你们可以开工了
管程
管程:定义了一个数据结构和他的所有操作,类似于
class
每次只准一个进程进入管程!
包括4个部分:
- 管程名字
- 数据结构说明
- 操作函数定义
- 设定共享数据的初始值
条件变量condition:仅用于判断条件,没有值
假设有条件xyz...
x.wait():当x条件不满足时,阻塞该进程,并排到x后面的阻塞队列x.signal():唤醒一个x阻塞队列里的进程
经典同步问题
生产者消费者问题
- 规则:
a. 缓冲区长度为n,且为临界资源,同时只允许一个进程访问
b. 缓冲区不为空,消费者才可以拿
c. 缓冲区不满,生产者才可以生产- 分析:
a. 生产者和消费者需要互斥访问缓冲区(临界资源)
b. 不满才能生产,不空才能消费- 设定信号量:
a.mutex=1,互斥信号量,用于互斥访问
b.empty=n,空位信号量,表示空位资源剩余
c.full=0,资源信号量,表示有多少个消费资源- 实现过程
#生产者进程produce a dataP(empty) //请求一个空位P(mutex) //请求互斥访问add data //将生产的数据放进缓冲区V(mutex) //结束互斥访问V(full) //归还一个消费资源#消费者进程P(full) //请求一个消费资源P(mutex) //请求互斥访问remove data //移出缓冲区数据V(mutex) //结束互斥访问V(empty) //归还一个空位资源consume a data
读者-写者问题
- 规则:
a. 多个读者和多个写者
b. 可以多人同时读
c. 只能有一个人在写
d. 没人读了才能写- 分析:
a.写者之间互斥
b.读者和写者互斥
c.读者和读者可以并发- 设定信号量/变量:
a.writing=1:书写互斥信号量,只能有一个人写
b.mutex=1:访问count时的互斥保护
c.count=0:变量,记录读者数量- 伪代码:
#写者进程P(writing) //申请写入write //写入V(writing) //释放写入信号量#读者进程P(mutex)if(count==0)P(writing) //第一个读者进来,先挂牌“禁止写入”count++V(mutex) //用于对count互斥修改reading...P(mutex)count--if (count==0) //最后一个读者了V(writing) //释放“禁止写入”的牌子V(mutex)
哲学家进餐问题
- 规则:
a. 5人围桌而坐,两人之间有1根筷子,共5根
b. 拿起左右2根才能吃饭,吃完放回- 分析:
a. 筷子是互斥访问
b. 规定只有左右都为空闲,才拿起- 信号量设置:
a.chops[i]=1:为每个筷子设定一个互斥信号量- 伪代码:
#哲学家进程P(mutex)P(left.chop) //互斥申请左边筷子P(right.chop) //互斥申请右边筷子V(mutex)eating //吃饭V(left.chop) //V操作不会被阻塞,因此不需要互斥申请V(right.chop)
吸烟者问题
- 规则:
a. 三个吸烟者分别拥有A,B,C资源
b. 系统随机往公共桌上提供任意两种资源
c. 缺这两种资源的吸烟者对应拿走,并抽烟
d. 等对应的人抽完了,并发出新的需求,生产者才可以继续供应- 分析:
a. 三个吸烟者同步,但是抽烟动作互斥
b. 抽完烟了才能继续生产- 信号量设置:
a.offer[i]=0:表示第i种资源
b.order=0:表示餐厅订单,即抽完烟了- 伪代码:
#生产者进程random produce item = iV(offer[i])P(order) //收走订单#第i个吸烟者进程P(offer[i]) //请求i资源smokingV(order) //留下新的订单
死锁
死锁定义
根本原因:系统资源的竞争和进程推进顺序非法
四个条件,缺一不可:
- 互斥:该资源必须是互斥访问
- 不可剥夺:该资源的使用是不可剥夺的
- 请求并保持:自己已经占有了资源,不仅不放,还去请求新的资源
- 循环等待:自己请求的资源被其他人占有,其他人请求的又被我占有
死锁的处理策略:
有以下几种:
- 预防:破坏四个必要条件
- 互斥:
共享文件法,但是硬件设备就没办法,如打印机- 不剥夺:设置为可剥夺
- 请求并保持:
预先分配,即需要的所有资源都到空了,才开工- 循环等待:
顺序资源分配,即给资源编号,我最多申请到i号资源,你申请的只能从i之后开始- 避免:
- 银行家算法(系统安全状态)
- 检测和解除:
- 资源分配图:
方为资源,圆为进程
- 若有死锁,必定存在环,且至少2个进程在死锁中
- 死锁定理:当且仅当资源分配图是
不可完全简化的,才是死锁的系统- 解除:
- 剥夺法:
挂起死锁进程,抢占他的资源,但应该防止被挂起太久- 撤销法:
撤销死锁进程,抢占他的资源- 回退法:悔棋,直到可以避免死锁的状态。
自愿释放资源
银行家算法
- 变量设置:
Max:进程所请求的资源个数Allocation:已经分给这个进程的资源个数Available:系统还剩多少资源没分配Need:进程还差多少个资源- 算法流程:
- 先算出
Need=Max-Allocation,即每个进程还差多少个资源?- 然后把
Need跟Available对比:
- 资源还缺的:必须等待
- 资源不缺的:加入
安全序列,并释放他所占有的Allocation- 如果所有进程都在
安全序列中,则系统处于安全状态
内存管理
相关概念
程序编译执行的步骤
- 编译:
- 把用户的源代码编译成多个
目标模块- 在这个过程完成
分段- 链接:
- 把
目标模块和对应的库函数链接起来
- 静态链接:装入前,就链接起来
- 装入时动态链接:一边装入内存,一边链接。但装入后还是完整链接好的程序
- 运行时动态链接:执行该模块时才链接并装入,内存里可能只装了一些模块
- 在这个过程获得
逻辑地址- 装入:
- 把
装入模块装进内存里,获得物理地址:
- 绝对装入:程序和数据放在内存的
绝对位置,仅适用于单道程序环境- 可重定位装入/静态重定位:多道程序,装入前确定位置和空间,并且不能移动和新增了。
地址需要连续!!- 动态运行时装入/动态重定位:装入内存的所有地址都是
相对地址,运行的时候才进行。
需要结合重定位寄存器才能确定绝对地址。可以得到比存储空间大得多的地址空间- 重定位:即
逻辑地址映射到物理地址的过程
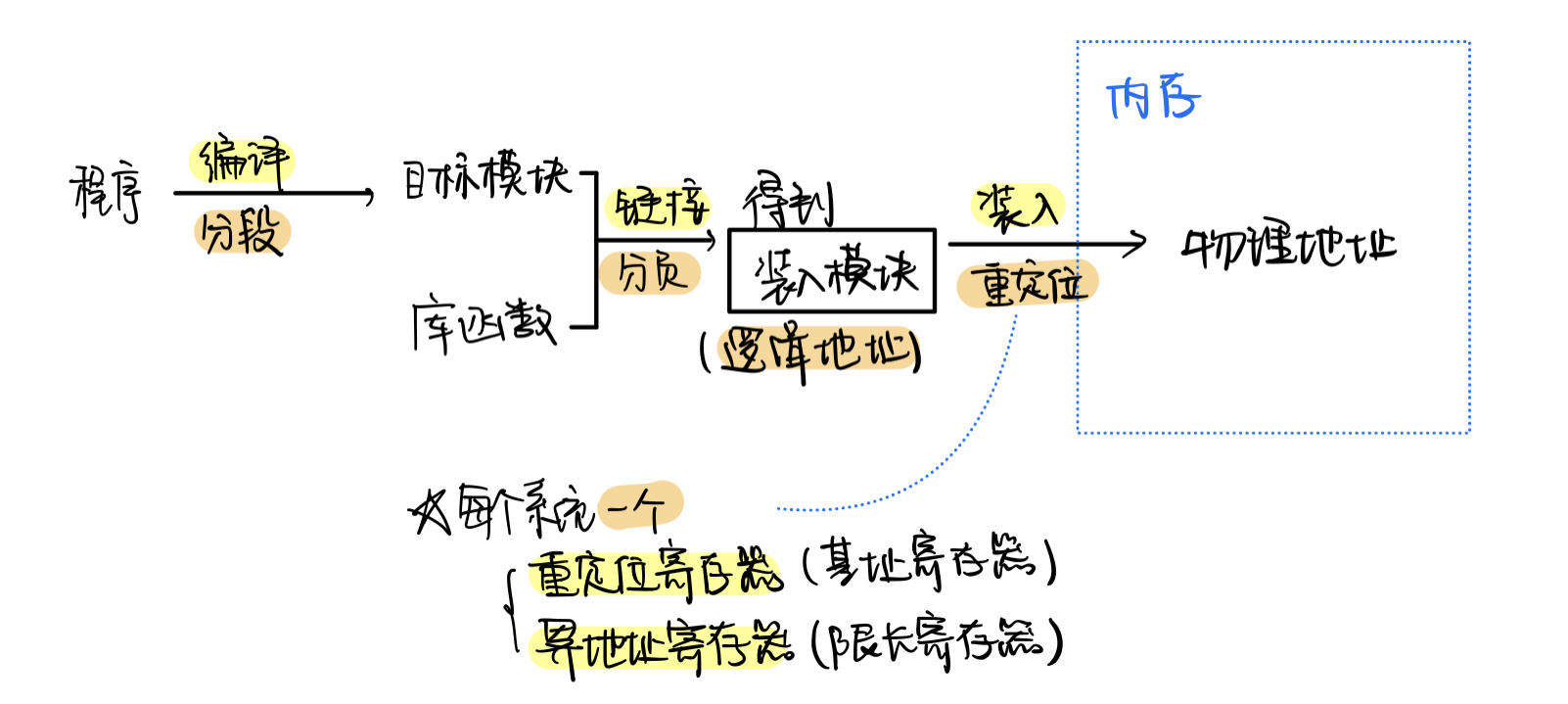
内存保护
有两种方法:
- 设置
上限寄存器和下限寄存器:绝对地址- 设置
重定位寄存器(基址寄存器)和界地址寄存器(限长寄存器):绝对地址 + 相对偏移
覆盖与交换
覆盖
覆盖:把系统分为
固定区和覆盖区,把经常活跃的放在固定区,不需要活跃的放在覆盖区。
把即将要访问的放在覆盖区,其他部分放在外存。
交换
即
挂起和换入,在中级调度中使用
覆盖用于同一个程序和进程中,用的很少;
交换用于不同进程之间
连续分配(分区)
包括:
- 单一连续分配:
- 单道程序,无内存保护
- 效率:
- 内部碎片:有
- 外部碎片:无
- 固定分区分配:
- 多道程序,每个分区只放一道作业
- 效率:最简单的存储分配,但不能实现多进程共享一个主存
- 内部碎片:有
- 外部碎片:无
- 动态分区分配:
- 在装入内存的时候才分配分区
- 分配策略:
- 首次适应:按地址
递增排序,然后在排序序列中找到第一个够用的分区- 最佳适应:按空间大小
递增排序,然后在排序中找到第一个够用的分区- 最坏适应:按空间大小
递减排序,然后在排序中找到第一个够用的分区- 邻近适应:从上个作业的地方往后找,找到第一个够用的分区
- 效率:
- 内部碎片:无
- 外部碎片:有,可以通过
紧凑操作解决整理
非连续分配
注意:地址都是按字节Byte来分配的,1 Byte=8 bit
分页式
将内存分成若干个
页面,类似于固定分区,但每个页面小得多
无外部碎片,有内部碎片/页内碎片
分页对系统可见,但是对用户透明!!
一级页表
- 基本概念:
页page:进程中的块页框:内存中的块块block:外存中的块页面:一个存储分页,用于分配的单元
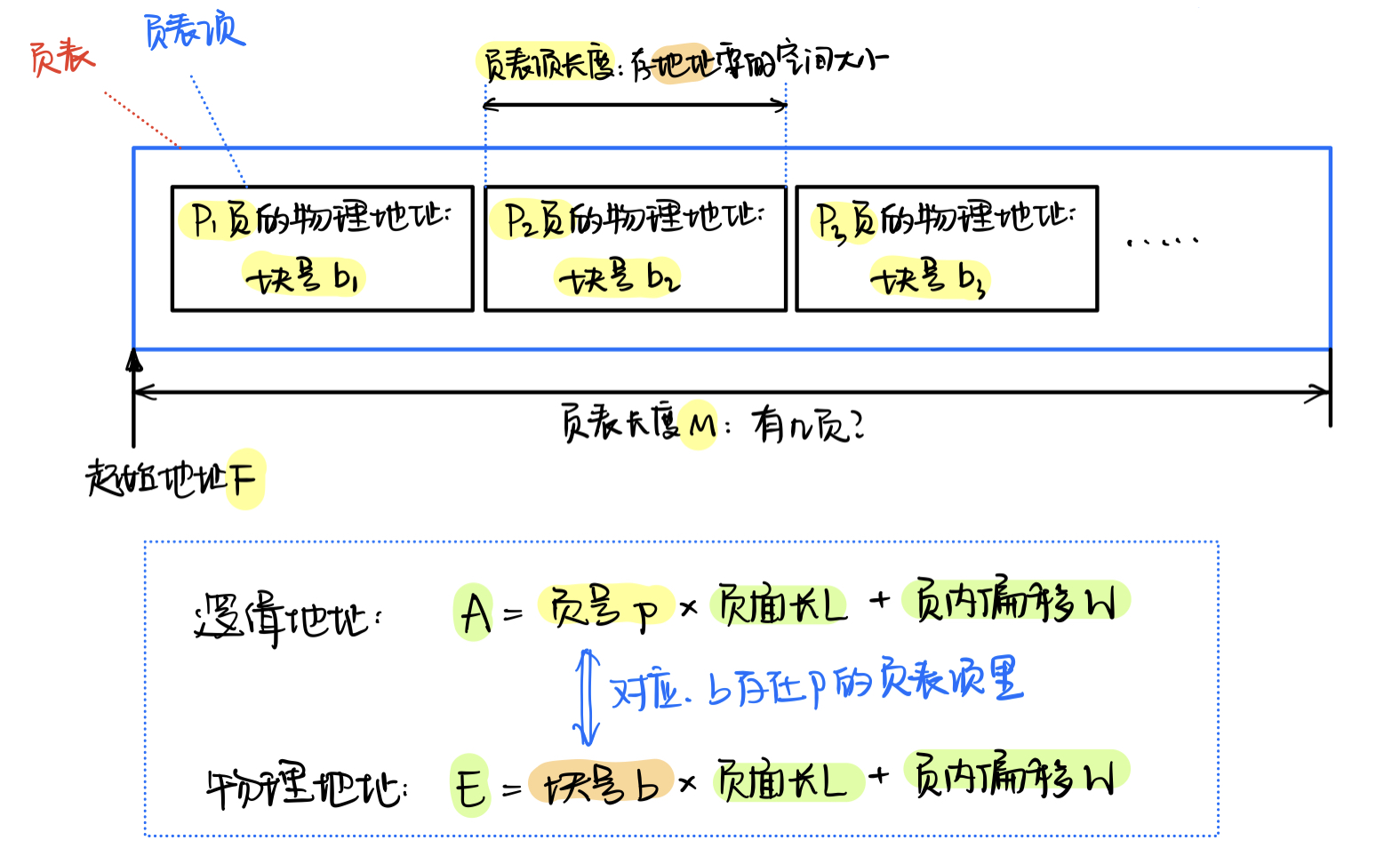
页面大小L:页面里面能装多少东西?例如页面大小为4KB,则对应的是12位地址空间(4*2^10)页号P:页面的相对编号页表:由一个个页表项组成的表,实现从逻辑地址到物理地址的映射
页表项:存储了某一页的页号P(逻辑地址)和他对应的块号b(物理地址)页表项长度:表示每一个页表项要占用多少空间页表长度:表示有多少个页表项页内偏移量W:代表在页内的第几个位置
- 地址变换机构:
- 一般由
硬件实现- 一个系统设置一个
页表寄存器PTR,用于记录:
页表在内存的起始地址F页表长度M- 以上两个信息平时放在
进程控制块PCB中,要执行进程的时候就放在页表寄存器PTR中。
并发执行的时候,都放在PTR中- 地址重映射过程(慢表):
CPU先给出逻辑地址Addr_L- 根据
逻辑地址Addr_L算出其对应的页号P和页内偏移量W- 计算
页表中的页表项地址,也就是:
页表项地址=页表起始地址F+页号P×页表项长度
找到页表项地址之后,访问这个页表项存储的块号b- 根据
块号b×页面大小L+页内偏移量W=物理地址Addr_Ph- 快表/相联存储器TLB:
- 即把以上的地址重映射过程直接简化,不需要计算中间步骤,直接存储
页号P和块号b的对应关系- 如果在
快表中没有,则正常计算(慢表)之后加入快表- 页表的效率:
- 基本分页模式,是一维的
即CPU只需要给出一个逻辑地址,就可以知道物理地址
二级页表
建立
页表的页表,把页表们再次映射到新的页表上
- 二级页表的效率:
- 是一维的
即CPU只需要给出一个逻辑地址,就可以算出物理地址
分段式
将
作业按照编程的自然段,划分成段,在编译的时候就完成该工作,生成段号
段号和段内偏移量由用户显式提供,由编译程序来分配
- 分段:
- 要求:段内连续,段间不一定连续
- 逻辑地址组成:
段号S和段内偏移量W(段内偏移可能越界,一旦越界就报错)- 段表:
- 记录:
段号+段长+本段在主存的起始地址- 段的地址变换机构:
与页的地址变换类似- 段的共享与保护:
- 实现:两个作业指向
共享段的同一个物理副本可重入代码:不可修改的代码,也叫纯代码,不属于临界资源- 可以共享的:
可重入代码和不能修改的数据- 段表的效率:
- 是二维的
即需要CPU同时给出段号S和段内偏移量W,才能确定物理地址
因为每一段长度不一样
段页式
先分段,再把每一段分页
- 逻辑地址:
段号S+页号P+页内偏移量W- 每个进程中,
段表只有一个,但是页表有很多个- 寻址过程
- 先查段,再查页,找到页对应的块,加上偏移量
- 也可以使用
快表- 段页式的效率:
- 是二维的
即需要CPU同时给出段号S和段内的逻辑地址,才能确定物理地址
地址举例
抽象型
假设32位系统
采用二级分页法:(10位页表目录,10位页表索引,12位页内偏移量)
则逻辑地址LA对应的:
- 页表目录号 = [
(unsigned int)LA>>(10+12)] & 0x3FF- 页表索引 = [
(unsigned int)LA>>12] & 0x3FF其中,
0x3FF=11 1111 1111
&0x3FF:后10位做与运算,即取后10位数,相当于%2^10
>>n:表示把该二进制数往右移动n位,并用0占位高位空缺。相当于/2^n
具体型
假设32位系统
采用基本分页法:(20位页号,12位页内偏移量)
- 假设某个逻辑地址
LA为008F H,则需要转换成二进制,即0000 0000 1000 1111 B- 然后页号 =
LA>>12=0 B- 页内偏移量 =
LA&0xFFF=0000 0000 1000 1111&1111 1111 1111=1000 1111 B=008F H- 若第0页的起始地址为
0100 H,则该逻辑地址对应的物理地址就是0100 H+008F H=018F H
虚拟内存管理
传统存储和虚拟存储的对比
- 传统存储特征:
- 一次性:必须一次性装入
- 驻留性:运行期间一直在内存中
- 虚拟存储:
- 多次性:分多次装入
- 对换性:允许运行过程中换进换出
- 虚拟性:逻辑上扩容
局部性原理
局部性原理
- 时间局部性
- 该指令被执行后,不久后很可能再次被执行。因为有很多循环操作
- 空间局部性
- 该指令被执行后,不久后可能附近的存储单元也会被访问,因为一般是顺序存放的指令
虚拟内存的实现
建立在
请求机制,包括:
- 请求分页
- 请求分段
- 请求段页式
需要
中断机制的支持,在发生缺页时,需要中断
新的页表
新的页表包括了:
- 页号
- 物理块号
- 状态位P/合法位:有没有被调入内存?
- 访问字段A:该页被访问的次数,供
置换算法参考- 修改位M:是否被修改过?
- 外存地址:一般是物理块号
缺页中断机制
- 在指令执行期间产生和处理
中断,属于内部中断- 一条指令执行中,可能产生多次中断
页面置换算法
决定了什么页面要调出
- 最佳置换(OPT, Optimal):
- 换出
最长时间都没被访问的页面- 理论上的算法,实际没法实现,用于评价别的算法
- 先进先出(FIFO):
- 在满了的情况下,最先分配的页会被置换出去
- Belady异常:页框空位越多,反而
缺页次数也变多的异常
- 只有FIFO算法才会有Belady异常
- 最近最久未使用(LRU):
- 在最久未被使用的集合中,找到最近的那个页面替换掉
- 举例:若有4个空位,则读到第
i个指令发生缺页时,被置换的页面是:
在访问序列中从i往前数,直到第一次出现4+1种页面时,这个页面就是要被置换的页面- 算法性能好,但是需要
寄存器和栈的支持,是堆栈类算法- 时钟(CLOCK)/最近未用(NRU, Not Recently Used):
- 变量设置:
- 使用位:表示在这一轮扫描中,这个页面被用过没有
- 算法描述:
- 在调入页面时,
使用位设置为1- 当发生缺页时,开始循环扫描缓冲区:
- 如果
使用位是0,则停下来,他就该换出去了- 如果
使用位是1,则把它置0,然后往后扫描- 性能最接近于
LRU
页面分配策略
- 固定分配+局部置换
- 每个进程物理块固定,要换只能在自己的块里面换出去
- 可变分配+全局置换
- 每个进程物理块看情况分,多余的谁要就给谁
- 可变分配+局部置换
- 每个进程物理块看情况分,只能在自己的块里换出去:
- 缺页太多的话就多补点
- 缺页较少就少分点
调入页面的时机
- 预调页策略
- 运行前,一次性把我觉得可能要访问的都调入
- 一般用于首次调入,由程序猿决定
- 请求调页
- 运行时,进程缺页了,请求了,才给他调页
抖动
指刚被换出去,又要换进来的情况
所有算法都无法避免抖动!
工作集
工作窗口:最近相邻的n次访问区间
工作集:工作窗口内不同的页面的集合(重复的算一个)
文件管理
文件的概念
文件包括:
- 存储空间
- 分类和索引信息
- 访问权限
文件的基本操作
- 读写:
读和写采用同一个指针- 文件的打开:
open:
- 只把文件的
FCB文件控制块调入内存,文件本身不调入- 返回
索引打开计数器代表有多少进程打开了该文件,当=0时代表没人用,就调回外存(如果被修改过,就把修改写回外存),然后释放FCB和他占用的内存
文件的逻辑结构/存储结构
无结构文件/流式文件
按顺序记录,只能通过
穷举搜索来访问
有结构文件/记录式文件
- 顺序文件:
- 按一个记录一个记录顺序排列,每个记录一般是定长的
- 串结构:与关键字无关,按时间先后顺序排列
- 顺序结构:按关键字排列
- 索引文件:
- 每个文件一个索引
索引号+记录长度+文件指针- 非定长记录:
- 只能顺序访问索引文件
- 索引顺序文件:
- 每组文件一个索引
- 组内无序
- 组间有序
- 直接文件/散列文件/Hash file:
- 无顺序的特性
文件目录
文件目录:
FCB的有序集合,一个FCB就是一个文件目录项
文件控制块+索引结点
- 文件控制块
FCB(全套文件信息):
- 存放文件各种信息,实现
按名存取- 包括了:
- 基本信息:文件名,物理位置,逻辑结构,物理结构等
- 存取控制信息:文件存取权限
- 使用信息:建立时间,修改时间
- 索引结点(文件名以外的全套文件信息)
- 目录只存
文件名,其他信息存在索引结点中目录项指向索引结点- 索引结点就是文件的直接经纪人
- 存放在
磁盘(外存)的索引结点叫做磁盘索引结点
- 当文件被打开时,
磁盘索引结点要被复制到内存的索引结点中
目录结构
- 单级目录结构:
- 目录中:
FCB1,FCB2...FCBn- 每个
FCB直接连一个文件- 不允许重名
- 两级目录结构
- 分为
主文件目录和用户文件目录主文件目录存各个用户- 分支下来各个
用户文件目录存文件- 为了解决重名,可以重名
- 多级目录结构/树形目录
- 绝对路径:从根目录出发的路径
- 相对路径:从
当前目录出发的路径- 无环图目录结构
- 为了实现共享
文件共享
静态共享:硬链接、软链接,即只能有一个进程对文件操作
动态共享:两个进程可以同时对文件操作
硬链接,基于索引结点(更快)
进程A和进程B直接连接到文件的索引结点(经纪人)- 索引结点中加入
链接计数器
- 当新增链接时,计数器+1
- 当有进程提出删除时,不直接删除,计数器-1
- 当
count=0时,这时候才删除
软连接,基于符号链
文件F主人还是进程A,只有他直接指向索引链接
进程A相当于粉丝头头进程B想共享文件,需要建立一个Link文件,里面存着文件的路径名
但是他不直接链接索引结点- 要删除时:
- 只有文件的主人可以删除
- 当文件主人删除了,其他人再去访问时,
符号链失效,就删除符号链- 这样就不会出现
空指针
文件保护
- 访问控制:
- 建立
访问控制表,规定了每个用户允许的访问类型- 用户类型:
- 拥有者
- 组
- 其他
- 口令:
- 创建者生成一个
口令放在FCB口令放在内存,不够安全- 更加灵活
- 密码:
- 密码需要
编码和译码- 更加安全
文件系统的实现
文件系统层次结构
- 用户调用接口:文件操作功能函数,新建、删除等
- 文件目录系统:在这里找文件目录,例如
D:/documents/...- 存取控制验证模块:看有没有权限访问
- 逻辑文件系统与文件信息缓冲区:得到逻辑块号
- 物理文件系统:把逻辑地址转换成物理地址
- 该层:
- 辅助分配模块:管理辅存空间
- 设备管理程序模块:分配设备,实现输入输出等
目录的实现
即查找目录在哪里
- 线性列表
- 新增文件:
- 搜索有没有重名?
- 没有重名,那就添加一个
目录项- 采用链表:增删方便,但是实现比较费时
- 所以一般不用链表
- 哈希表
- 直接散列存储
- 需要避免冲突的设备
- 非常快,但是对于哈希表的长度是固定的
在
磁盘(外存)上反复搜索,需要不断I/O,开销很大。
因此一般先把目录复制到内存,降低磁盘操作次数
文件的实现
文件分配空间的方式
- 连续分配
- 连续n块分给同一个文件
- 可以顺序和直接访问,访问速度最快
- 反复增删会产生
外部碎片- 适用于长度固定的文件!!
- 链接分配
- 长度可以随时变化,但是不能随机访问
- 隐式链接:下一块的链接都存在自己那里
- 显式链接:单独把所有链接提出来,放在
文件分配表FAT- 索引分配
- 把索引表存在一块里面
- 当索引表太长,一块放不下时:
- 链接:把索引表串起来
- 多层索引
- 混合索引:
- 直接地址
- 单级索引
- 多级索引
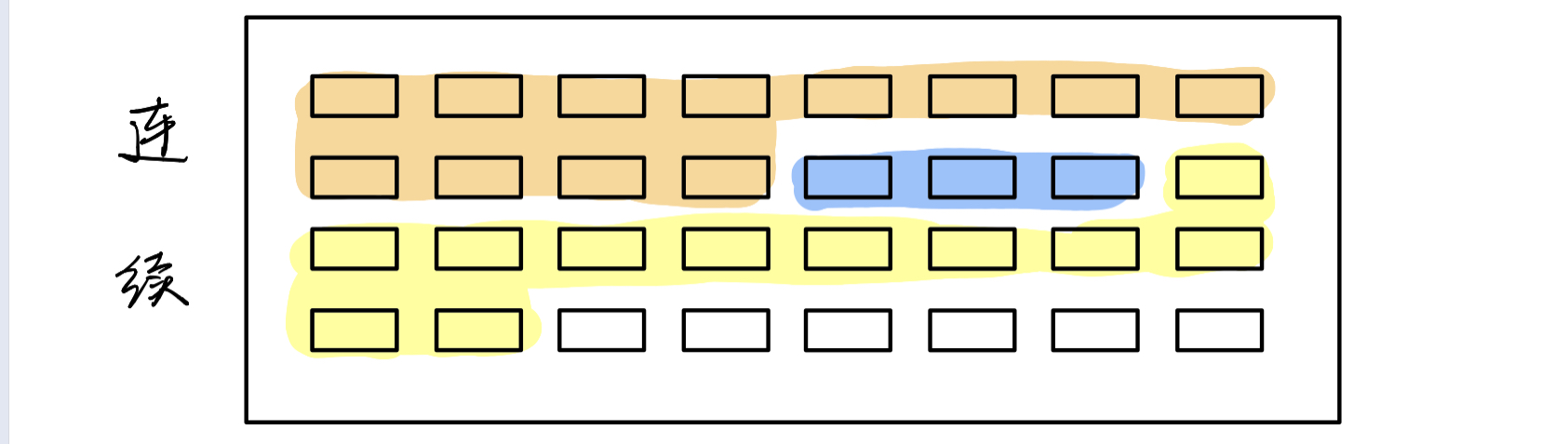
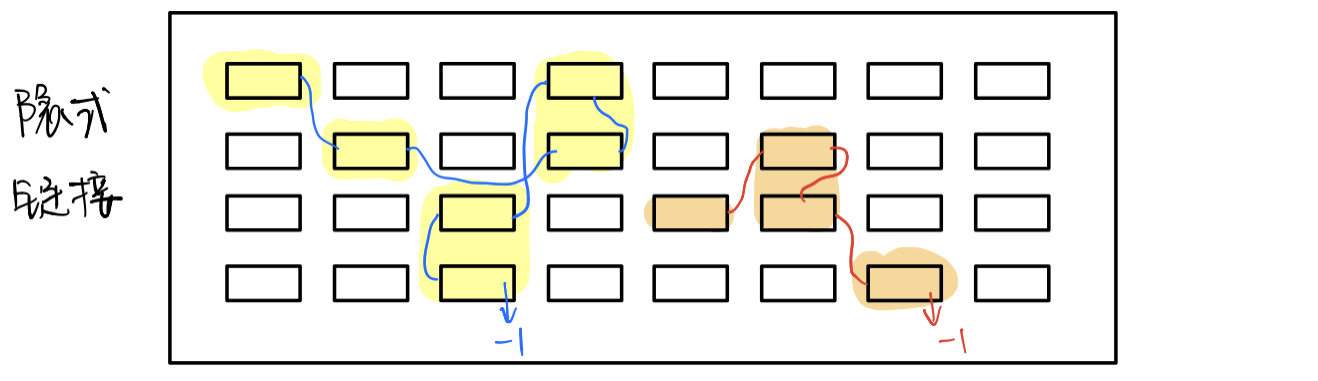
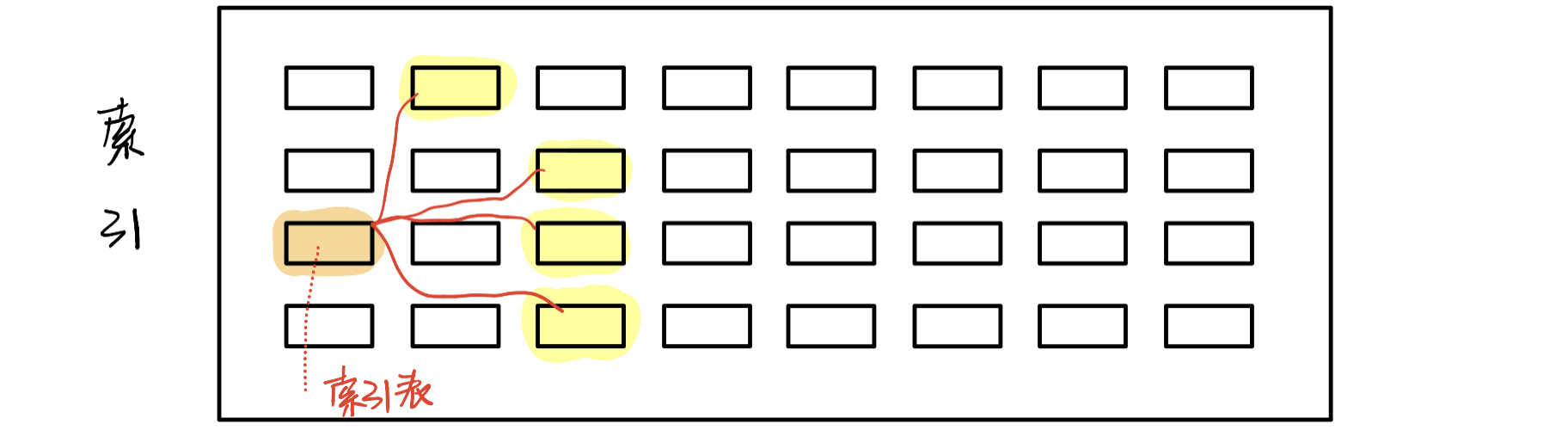
文件存储空间管理:外存空闲空间
- 空闲表法:连续的
- 为所有
空闲区建立一个空闲表,记录了:
空闲区起始块号空闲区长度- 空闲链表法:非连续
- 把所有
空闲块拉成一条链- 位示图法:
- 每一
位代表一块是否空闲,即一个字节B有8位b- 成组链接法:
- 适用于大型系统
- 实现方法:
- 领头的叫
超级块
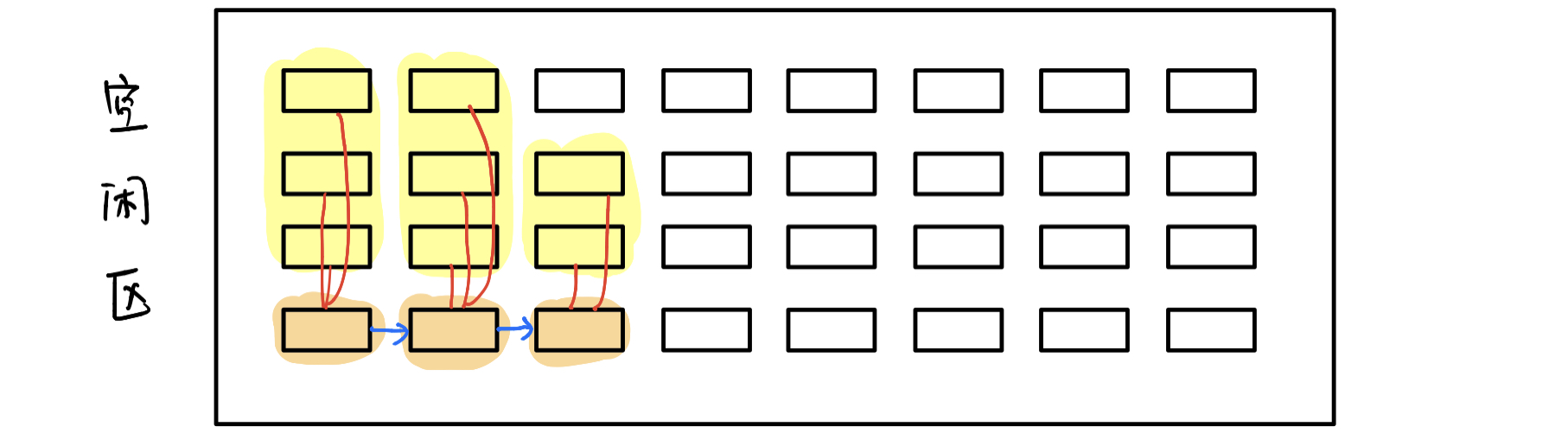
访问磁盘次数专题
- 访问直接地址:2次
- 从外存调取索引,算一次
- 根据索引找到文件,算一次
- 访问二级索引:3次
- 从外存调取一级索引,1次
- 从外存调取二级索引,1次
- 根据索引找到文件,1次
- 修改文件:2次
- 找到并打开文件,算1次
- 修改完了要写回外存,算1次
磁盘管理
磁盘结构
- n个柱面
- 盘面:每个柱面有多个盘面
- 磁道:每个盘面有一圈圈磁道
- 扇区=盘块:每个磁道有n个扇区
磁盘调度算法
- FCFS,先来先服务
- 直接按照申请序列访问,接近随机调度
- 效率很低
- SSTF,最短寻找时间有限
- 谁近先服务谁
- 可能会饥饿:
- 如果在一头附近一直有访问,另一头的就可能饥饿
- SCAN,扫描/电梯算法
- 单向走,走到磁盘尽头,然后掉头
- 局部性较差,对刚访问过的区域不公平
- C-SCAN,循环扫描
- 单向走,走到磁盘尽头,然后啥也不管直接移到开头,始终同向
- 适合处理最里和最外的磁道
- LOOK,改进的SCAN:
- SCAN,但是不走到磁盘尽头,走到最远访问的就回来了
磁盘命名
一般为了减小延迟,错位命名
I/O管理
I/O设备分类
按照传输速率分类
- 低速设备:键盘、鼠标
- 中速设备:打印机
- 高速设备:磁带机、磁盘
按照信息交换的单位分类
- 块设备:磁盘等
- 有结构设备
- 传输速率高
- 可寻址,可以随机读写
- 字符设备:打印机
- 无结构设备
- 不可寻址,不可随机访问
I/O控制方式
- 程序直接控制:
- 循环检查有没有I/O任务
- 每个字读入、输出,都得CPU来
- 中断驱动方式:
- 平时不用管
- 有I/O的时候,才把CPU叫来
- 每个字还是得经过CPU
- DMA方式:
- DMA(直接存储器)作为经纪人
- 平时没事CPU不管
- 每块开始时把CPU叫过来管一下
- 每块传完了把CPU叫过来签收一下
- 通道控制方式:
- 通道:特殊的处理机,是硬件
- 他没有自己的内存
- 与CPU共享内存
- 传完一组数据块了才叫一下CPU
I/O子系统的层次结构
- 用户层I/O软件
- 设备独立性软件
逻辑设备名映射到物理设备名- 设备驱动程序
- 一类设备只要一个驱动
- 中端处理程序
- I/O的时候,需要中断
- 硬件设备
- 机械部分
- 电子部分:设备控制器,I/O逻辑
I/O调度
磁盘高速缓存Disk Cache
- 逻辑上:属于磁盘
- 物理上:属于内存
- 当高速Device要访问低速Device时:
- 把低速的数据复制到
Cache- 如果
Cache里面有,那就在这访问- 如果
Cache里面没有,那就直接访问低速设备
缓冲区Buffer
基本特点:
- 空了,才准写
- 满了,才准读
常见的各种缓冲机制:
- 单缓冲
- 1个
工作区+1个缓冲区,一般来说大小相等- 初始状态:
- 工作区:空
- 缓冲区:满
- 完成一次循环时间:
- 即
- 双缓冲
- 1个
工作区+2个缓冲区- 初始状态:
- 工作区:空
- 缓冲区1&2:一空一满
- 完成一次循环时间:
- 循环缓冲
- 一串一串的缓冲区
in指针:指向第一个可以冲入的缓冲区out指针:指向第一个可以冲出的缓冲区- 缓冲池
- 队列有3个:
- 空缓冲队列
- 输入队列:装满输入数据
- 输出队列:装满输出数据
- 缓冲区有4种:
- 收容输入、收容输出:正在进出的
- 提取输入、提取输出:已经装满了输入/输出数据的
SPOOLing假脱机技术
- 目的:
- 把
独占设备改造成共享设备,即虚拟设备- 牺牲空间,换时间
- 输入井、输出井
- 装好了,可以直接拿来用的输入、输出数据
- I/O缓冲区
- 正在装的
- 装完了送到
井- I/O进程
- 实现虚拟设备的进程
常见知识点
进程管理
并行与并发
并行:同一
时刻,两个都在运行
并发:同一时间间隔,大家交替来
文件管理
I/O设备:在UNIX中被系统视为特殊文件
