@Mr-13
2020-11-04T00:19:36.000000Z
字数 9713
阅读 1267
工作手机:wechat数据库部署
工作手机
一、关闭SELINUX
SELinux的永久关闭,必须通过修改器配置文件并重启才可以;在线上部署时,我们可以先通过命令临时关闭SELinux,完成其他配置后一起重启完成关闭配置;
1、临时管理SELinux
# 执行 1:[root@mr13 ~]# setenforce 0# 打印:setenforce: SELinux is disabled[root@mr13 ~]#
2、修改SELinux配置文件
# 执行 2:[root@mr13 ~]# sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
说明:
1、SElinux配置文件位置:/etc/selinux/config
2、sed命令:可依照脚本的指令来处理、编辑文本文件。
3、sed -i:直接修改读取的文件内容,而不是输出到终端(在屏幕打印输出)
4、sed -i 's/AAAA/BBBB/g':逐行查找,每行中所有的AAAA全部替换成BBBB
3、重启服务器,检查SElinux状态(可最后再重启检查)
二、关闭FireWall
彻底关闭FireWall不需要修改配置参数;按如下命令即可:
1、停止firewall服务
# 停止firewall服务[root@mr13 ~]# systemctl stop firewalld.service[root@mr13 ~]#
2、禁止firewall开机启动
# 禁止firewall开机启动[root@mr13 ~]# systemctl disable firewalld.service[root@mr13 ~]#
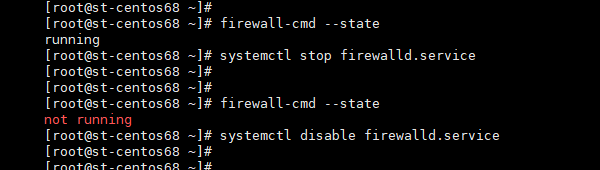
执行上述命令不会有执行结果提示,我们需要确认操作是否有效
# 检查防Firewall运行状态[root@mr13 ~]# firewall-cmd --state# 检查开机启动项服务[root@mr13 ~]# systemctl list-unit-files | grep firewalld
出现如下图提示,说明执行成功;

三、磁盘挂载、目录创建
微信数据库服务器,硬盘推荐配置为:40G(系统盘)+ 2T(数据存储) ;在客户交付服务器之后一定要主要数据库存储的存放位置,千万不要默认全部安装到系统盘里面去了。
如果客户使用阿里云的ECS实例,存储盘默认状态时没有分区、挂载的。需要我们进行磁盘挂载。
如果客户交付的是实体机,一般情况下客户会挂载好硬盘;我们验收时,需要根据实际情况;设置软链。
以下以阿里云为例,编写文档。
1、查看磁盘信息
在磁盘未挂载之前,使用 df -lh 是看不到磁盘信息的,需要使用 fdisk -l 查看磁盘信息
# root用户下操作[root@mr13 ~]# fdisk -l
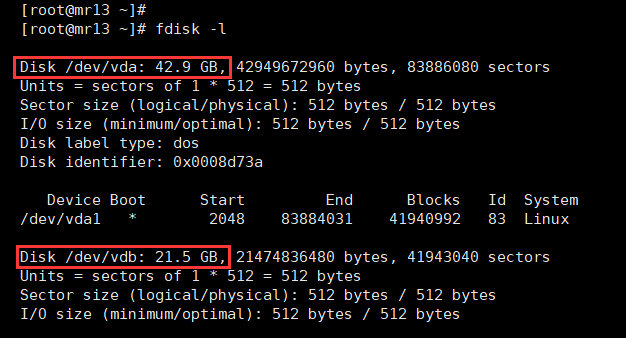
可以看到两块磁盘信息:
系统盘:/dev/vda (42.9G);
数据盘:/dev/vdb (21.5G);我们需要对这块盘操作挂载。
2、磁盘分区(部署过程不需要,仅作了解)
一般我们每台服务器都是专服务专用,基本上不需要对新增磁盘进行分区的动作。这里仅作内容补充。
详情参见:CentOS7磁盘分区挂载
3、格式化磁盘
将未使用的磁盘进行格式化,操作数据盘符前,请自行确认磁盘是否有使用过,如有重要数据请谨慎操作,以免导致数据丢失,带来不必要的麻烦。格式挂过程需要等一会儿。
# root用户下操作# 我这里使用ext4格式,与系统盘保持一致[root@mr13 ~]# mkfs.ext4 /dev/vdb# 执行命令需要稍等一会儿执行完成
.
4、创建挂载点、并进行磁盘挂载
将格式化完的磁盘进行硬盘挂载,硬盘挂载前,先在服务器上创建一个需要挂载的挂载点。
微信数据库服务器数据盘主要是来存储pgsql数据文件。部署时,相应的数据文件都是放在 /data 目录下。/data 目录即为数据盘的挂载点。
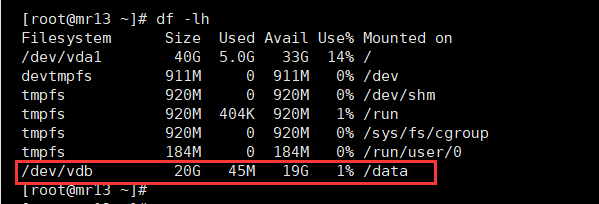
# root用户下操作# 创建挂载点目录:/data[root@mr13 ~]# mkdir /data# 将磁盘vdb挂载到/data目录[root@mr13 ~]# mount /dev/vdb /data/# 如果需要卸载磁盘分区,使用命令umount /...即可;# 磁盘分许卸载后,还可以重新挂载,并且数据还会在的
挂载完成后,使用命令 df -lh 就可以看到磁盘分区信息了。
5、配置开机自动挂载(修改fstab)
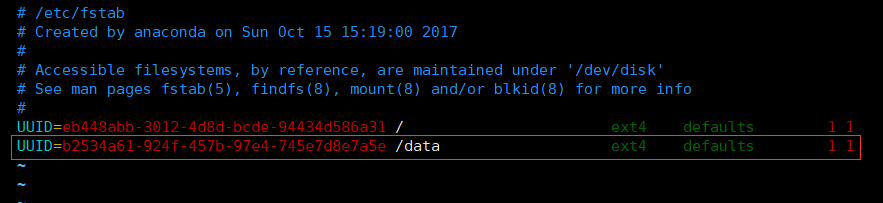
上述动作完成之后,还需要修改fstab的配置信息,让服务器重启时,自动完成磁盘挂载。
# root用户下操作# 查看磁盘UUID[root@mr13 ~]# blkid/dev/vda1: UUID="eb448abb-3012-4d8d-bcde-94434d586a31" TYPE="ext4"/dev/vdb: UUID="b2534a61-924f-457b-97e4-745e7d8e7a5e" TYPE="ext4"# 编辑fstab文件保存[root@mr13 ~]# vim /etc/fstab

至此,完成了对数据盘的挂载。
我们会将pgsql安装到 /data/pgsql 目录下,因为数据盘已经挂载到 /data 目录;这样数据文件也就保存在数据盘上了。
如果客户交付的是实体机,已经做好数据盘的挂载;那么我们就需要创建软链 /data 链接至实际数据盘的目录,同时给软链目录修改授权。
四、安装Pgsql数据库
1、安装相关依赖包
[root@mr13 ~]# yum install -y gcc readline-devel zlib-devel libcurl-devel wget
2、下载PostgreSQL
[root@mr13 ~]# mkdir -p /server/tools[root@mr13 ~]# cd /server/tools[root@mr13 tools]# wget https://ftp.postgresql.org/pub/source/v10.2/postgresql-10.2.tar.gz
pgsql安装包下载速度会很慢,可以提前准备好安装包,从本地上传;
如果没有已经下载好的安装包,可以使用mwget下载(多线程下载);
3、创建安装目录并编译安装
# 创建Pgsql安装目录[root@mr13 ~]# mkdir -p /data/pgsql# 进入安装包下载路径[root@mr13 ~]# cd /server/tools# 解压安装包# z:表示 tar 包是被bai gzip 压缩过的,所以解压du时需要用 gunzip 解压;# x:从 tar 包中把文件提取bai出来# f:指定文件名[root@mr13 tools]# tar zxf postgresql-10.2.tar.gz
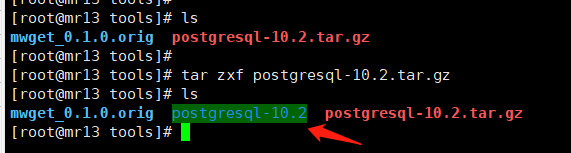
# 进入解压后的路径[root@mr13 tools]# cd postgresql-10.2# 配置(configure)、make(编译)、安装(make install)数据库[root@mr13 postgresql-10.2] ./configure --prefix=/data/pgsql && make && make install# 当执行完成并显示如下说明数据库安装完成PostgreSQL installation complete.
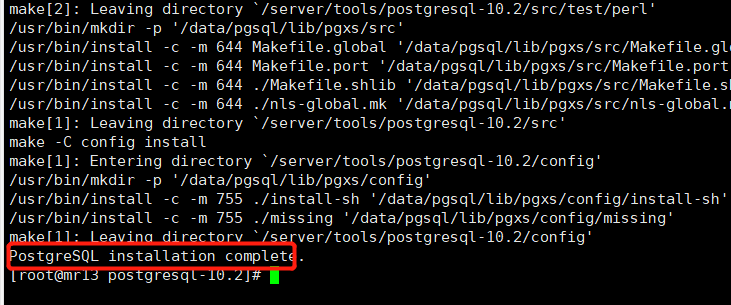
说明:
源码的安装一般由3个步骤组成:配置(configure)、编译(make)、安装(make install),具体的安装方法一般作者都会给出文档,这里主要讨论配置(configure)。Configure是一个可执行脚本,它有很多选项,使用命令./configure –help输出详细的选项列表(这里不多赘述,可以自己试一下)
其中--prefix选项是配置安装的路径,如果不配置该选项,安装后:
可执行文件默认放在:/usr/local/bin;
库文件默认放在:/usr/local/lib;
配置文件默认放在:/usr/local/etc;
其它的资源文件放在:/usr/local/share;非常凌乱。
./configure --prefix=/指定路径;可以把所有资源文件放在指定的路径中,不会杂乱。
用了—prefix选项的另一个好处是卸载软件或移植软件。当某个安装的软件不再需要时,只须简单的删除该安装目录,就可以把软件卸载得干干净净;移植软件只需拷贝整个目录到另外一个机器即可(相同的操作系统)。
当然要卸载程序,也可以在原来的make目录下用一次make uninstall,但前提是make文件指定过uninstall。
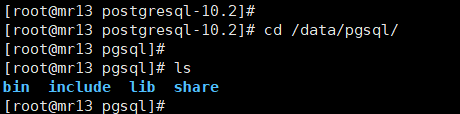
如上图,可以看到,在我们通过 --prefix 参数指定的目录 /data/pgsql 中,软件安装文件都统一放在这里,很方便维护和管理;
4、创建PostgreSQL的管理用户、存储目录,并授权
# 创建一个一般用户[root@mr13 ~]# useradd postgres# 创建数据目录[root@mr13 ~]# mkdir /data/pgsql/{data,log} // 数据库数据文件存放目录[root@mr13 ~]# mkdir -p /data/data/{pg_wal,backup} // 数据库备份、及归档日志存放目录# 更改刚才创建的目录拥有者为:postgres[root@mr13 ~]# chown -R postgres.postgres /data/pgsql[root@mr13 ~]# chown -R postgres.postgres /data/data# 目录授权[root@mr13 ~]# chmod 1777 /tmp
.
5、初始化数据库(绑定数据库文件存储目录)
# 切换到postgres用户[root@mr13 ~]# su - postgresLast failed login: Sat Jul 25 02:54:30 CST 2020 from 59.2.114.132 on ssh:nottyThere was 1 failed login attempt since the last successful login.[postgres@mr13 ~]$
说明:
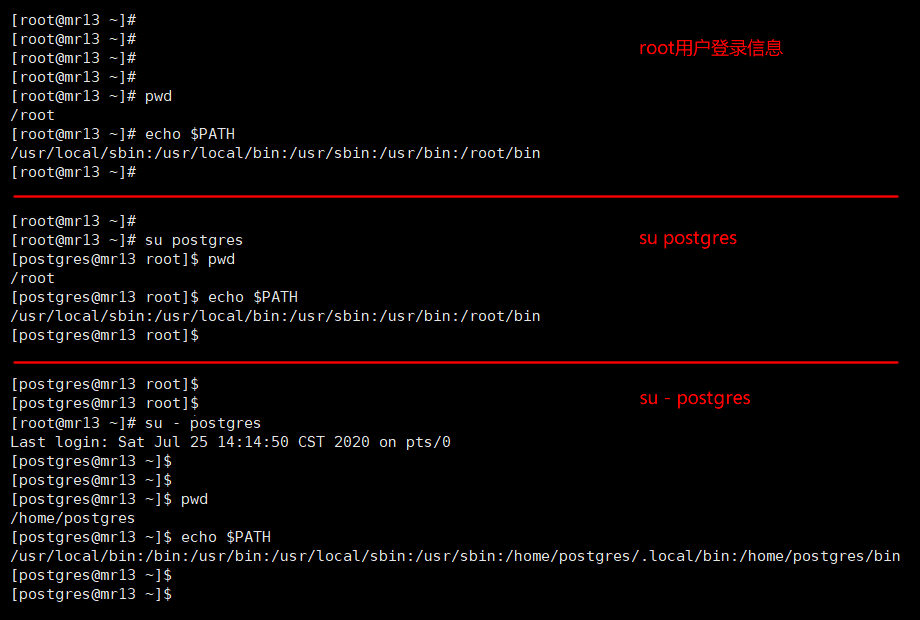
切换用户一定要用
su - postgres;中间一定要加短横线;参考下附图左下说明:
su只是切换了用户身份;但是Shell环境仍然是root用户的Shell;pwd一下也可以发现工作目录并没有发生变化;
su -则是将环境变量和工作目录一起切换成了postgres的身份;这样可以避免因为账户权限、或者环境变量的差异,造成命令执行报错。
.
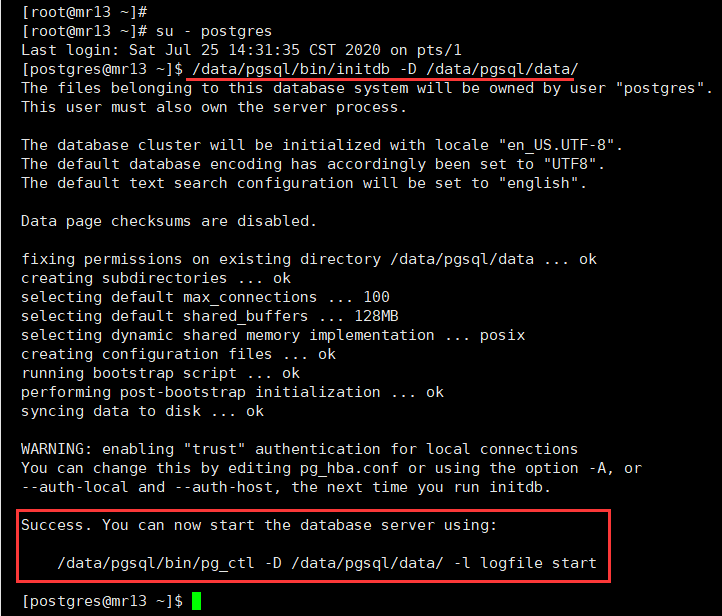
# 在postgres用户下:# 初始化数据库,同时绑定数据库文件存储目录[postgres@mr13 ~]$ /data/pgsql/bin/initdb -D /data/pgsql/data/
输入命令后,会提示初始化的相关执行结果,执行结束,出现“Success......”的相关提示后,初始化完成。
.
6、编译安装contrib
cintrib是pg的管理工具,主要用于pg的慢查询、统计空间等运维维护;
网上搜到的解释:
源代码目录下有一个contrib目录,是一些第三方组织贡献出来的一些工具代码,这些工具在日常维护中也很有用,建议安装上。
这里注意:
需要在 root 用户下安装;这里在强调一下,不要忘记短横线:su - postgres
# 切换root用户[postgres@mr13 ~]$ su - rootPassword:Last login: Sat Jul 25 19:06:41 CST 2020 from 58.57.86.166 on pts/1[root@mr13 ~]## 进入pgsql解压文件夹的contrib目录[root@mr13 ~]# cd /server/tools/postgresql-10.2/contrib/[root@mr13 contrib]## 编译安装[root@mr13 contrib]# make && make install
命令执行需要等一会,大概十几秒,完成安装过程。
7、添加Pgsql的环境变量
# 在root用户下执行[root@mr13 ~]# echo "export PATH=$PATH:/data/pgsql/:/data/pgsql/bin/" >> /etc/profile# 执行/etc/profile文件[root@mr13 ~]# source /etc/profile# 检查边境变量是否添加成功[root@mr13 ~]# echo $PATH
环境变量添加完成后,使用 echo $PATH 检查一下环境变量添加是否成功。
说明:
1、环境变量
- 什么是环境变量呢,简单的来说就是一种文件搜索策略,在执行相应软件的时候,相关软件会按照给路径去寻找对应的软件,设置环境变量最实用的功能就是,不用拷贝某些dll到系统目录下了,而path就是系统搜索一系列dll的路径。
- 在windows系统下,很多软件安装都需要配置环境变量,比如安装jdk,假如你没有配置环境变量,那么在非软件安装的目录下使用javac命令,系统将会报这不是系统内部命令的错误,出现“Command not found”的提示。如果每次都要到安装目录下才能执行这个软件,那么这个操作就非常的繁琐了。这里就可以使用环境变量来简化这个操作。path的设置也是在linux下定制环境变量的一部分。
通过修改
/etc/profile文件的方式,所添加的环境变量对系统所有用户生效:
2、SOURCE命令
- source命令也称为“点命令”,也就是一个点符号(.),是bash的内部命令。
功能:使Shell读入指定的Shell程序文件并依次执行文件中的所有语句
用法: source filename 或 . filename
source命令通常用于重新执行刚修改的初始化文件,使之立即生效,而不必注销并重新登录。
source命令(从 C Shell 而来)是bash shell的内置命令;点命令(.),就是个点符号(从Bourne Shell而来)是source的另一名称。
source filename 与 sh filename 及./filename执行脚本的区别在那里呢?
- 当shell脚本具有可执行权限时,用sh filename与./filename执行脚本是没有区别得。./filename是因为当前目录没有在PATH中,所有"."是用来表示当前目录的。
- sh filename 重新建立一个子shell,在子shell中执行脚本里面的语句,该子shell继承父shell的环境变量,但子shell新建的、改变的变量不会被带回父shell,除非使用export。
- source filename:这个命令其实只是简单地读取脚本里面的语句依次在当前shell里面执行,没有建立新的子shell。那么脚本里面所有新建、改变变量的语句都会保存在当前shell里面。
.
8、启动数据库服务
需要在postgres用户下操作。
# 切换到postgres用户下进行操作[root@mr13 data]# su - postgres[postgres@mr13 ~]$# 启动数据库服务[postgres@mr13 ~]$ pg_ctl start -D /data/pgsql/data# 重启数据库服务[postgres@mr13 ~]$ pg_ctl restart -D /data/pgsql/data# 停止数据库服务[postgres@mr13 ~]$ pg_ctl stop -D /data/pgsql/data
.
9、安装pg_pathman插件
需要在postgres用户下操作。
# 切换到postgres用户下进行操作[root@mr13 data]# su - postgres[postgres@mr13 ~]$# 下载pg_pathman[postgres@mr13 ~]$ git clone https://github.com/postgrespro/pg_pathman# 下载过程提示,可能下载比较慢,耐心等一下# 下载完成后,进入pg_pathman目录[postgres@mr13 ~]$ lspg_pathman[postgres@mr13 ~]$ cd pg_pathman# 编译安装pg_pathman[postgres@mr13 pg_pathman]$[postgres@mr13 pg_pathman]$ make USE_PGXS=1 && make USE_PGXS=1 install
安装完成后,需要修改 postgres 配置文件:postgresql.conf,添加 pg_pathman 配置
# 继续在postgres用户下进行操作[postgres@mr13 ~]$[postgres@mr13 ~]$ cd /data/pgsql/data/[postgres@mr13 data]$ vim postgresql.conf# 使用Vim打开配置文件# 可以通过 / + 字符,搜索定位到相关配置节,如下图:/shared_preload_libraries
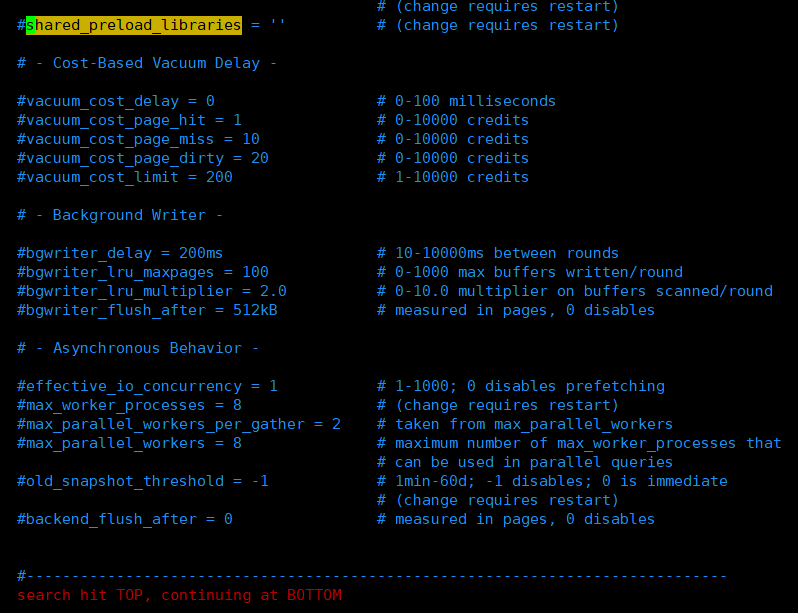
将该配置节修改为:
# pg_stat_statements : 就是上面编译安装的 contribshared_preload_libraries ='pg_stat_statements,pg_pathman'
如下图:
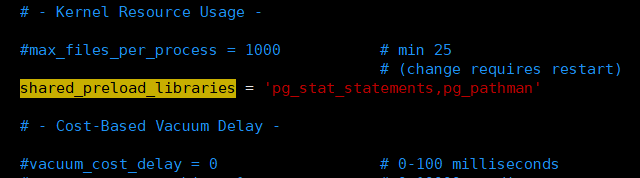
重新启动数据库、启动pg_pathman、pg_stat_statements插件:
# 继续在postgres用户下进行操作[postgres@mr13 ~]$# 重启pgsql服务[postgres@mr13 ~]$ pg_ctl restart -D /data/pgsql/data/# 启动pg_pathman插件,需要在数据库命令下执行[postgres@mr13 ~]$ psqlpsql (10.2)Type "help" for help.# 执行启动插件命令postgres=# create extension pg_pathman;postgres=# create extension pg_stat_statements;# 查看pg_pathman插件状态postgres=# \dx;# 使用命令 \q 退出psql
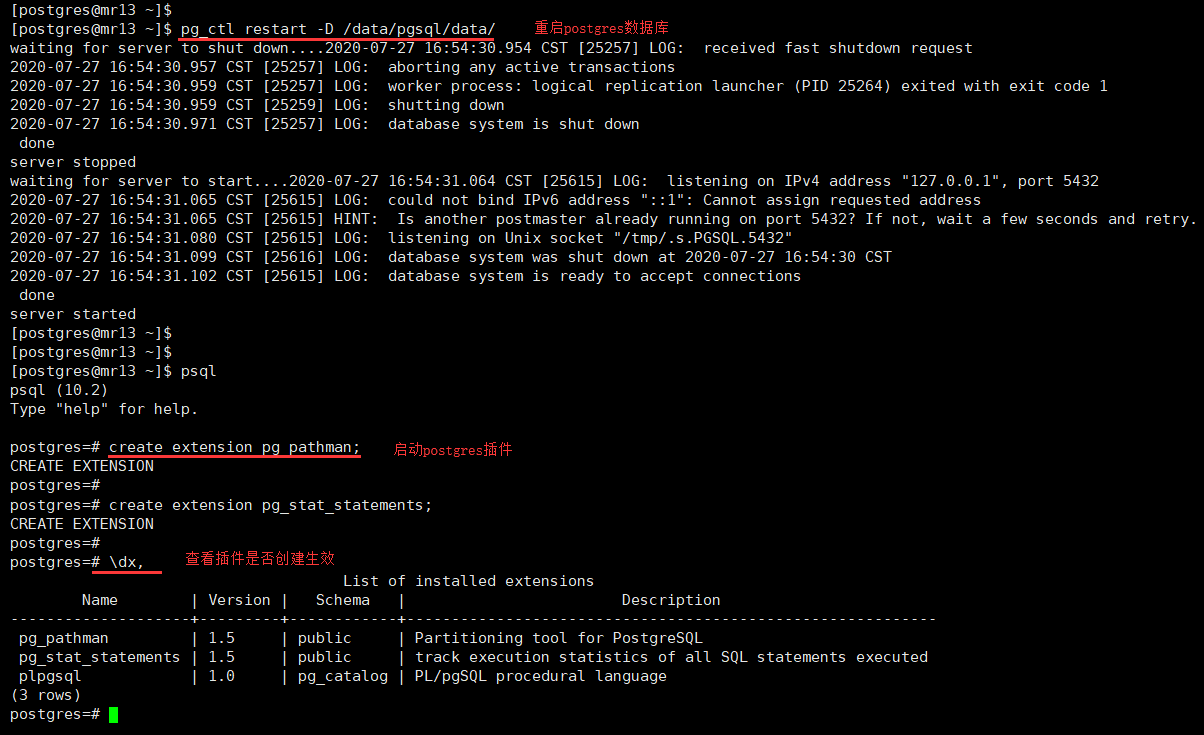
pg_pathman升级:
部署过程中,我们不需要执行升级;在后续使用中,如果需要升级,可使用一下命令:
alter extension pg_pathman update to "x.y";
如果报错的话,就执行 alter extension pg_pathman update;
set pg_pathman.enable = t;
.
10、设置定时任务备份数据库、开启归档日志
1、开启归档日志
编辑pgsql数据库配置文件 /data/pgsql/data/postgresql.conf
# 设置配置节如下:wal_level = archive // 设置信息级别archive_mode = on // 是否进行归档操作,默认值为否(off)archive_command = 'test ! -f /data/data/pg_wal/%f && cp %p /data/data/pg_wal/%f' // 归档命令archive_timeout = 1200 // 表示归档周期,在超过该参数设定的时间(秒)时强制切换WAL段,默认值为0# 设置完成后重启pgsql服务[postgres@mr13 ~]$ pg_ctl restart -D /data/pgsql/data/
.
2、使用系统定时任务(crontab)进行数据库备份
crontab如果不会使用,参见:crontab用法与实例;
创建数据库备脚本目录并添加数据库备份脚本:
$ mkdir /data/pgsql/scripts$ touch /data/pgsql/scripts/bak.sh$ chmod +x /data/pgsql/scripts/bak.sh // 给脚本添加可执行权限$ chown -R postgres.postgres /data/data // 更改目录拥有者为postgres# 编辑脚本内容如下:#!/bin/bashdate=$(date +%Y-%m-%d-%H)/data/pgsql/bin/pg_basebackup -U postgres -Ft -R -h 127.0.0.1 -D /data/data/backup/data$date# 保存并退出编辑
继续对 postgres 用户添加定时任务:
$ crontab -u postgres -e# 编辑内容如下01 1 * * 6 /bin/sh /data/pgsql/scripts/bak.sh# 保存并退出编辑# 查看定时任务设置是否成功$ crontab -u postgres -l# 如下图,显示刚才设置的定时任务说明设置成功

上图是给合作伙伴私有化设置的数据库备份任务截图,设置作业执行时间是每周三的凌晨 01:01。
.
11、修改postgres网路访问设置
默认,PostgreSQL只监听本地连接,不允许远程通过TCP/IP链接,运行远程连接需要在Server端修改两个配置文件;postgresql.conf 和 pg_hba.conf 文件。
一般来说,我们对数据库服务器是不配置公网网络的;设置允许远程TCP/IP仅是为了让内网其他服务器进行访问。
- postgresql.conf: 中修改监听配置,修改为
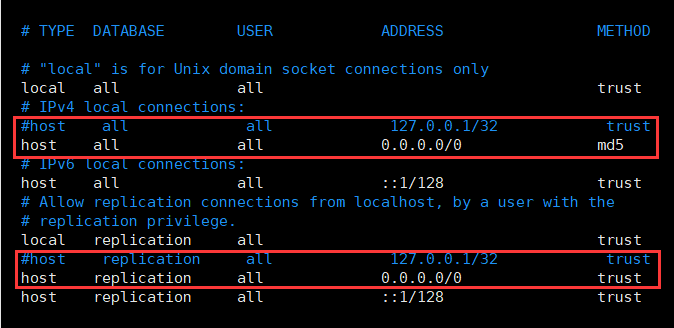
listen_addresses = '*'- pg_hba.conf:修改权限配置,
host all all 0.0.0.0/0 md5,在配置文件最后添加即可;- 修改完成后,需要重启数据库才能生效。
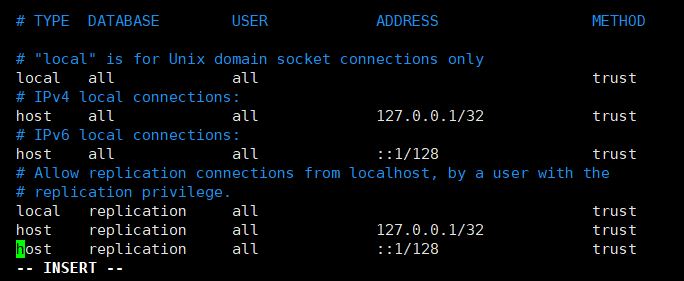
上图修改为如下:
这两个配置文件的位置;可以在数据库中使用postgres用户通过以下sql进行查询:
show config_file;:显示 postgresql.conf文件的具体位置show hba_file;:显示 pg_hba.conf文件的具体位置
完成配置文件编辑后,需要重启pgsql服务,使所发生的配置生效。
# 重启pgsql数据库服务[postgres@mr13 ~]$ pg_ctl restart -D /data/pgsql/data
.
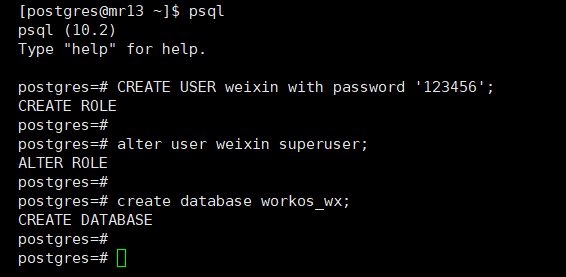
12、创建超级管理员和数据库
# 在postgres用户下进行[postgres@mr13 data]$ cd ~[postgres@mr13 ~]$ psqlpsql (10.2)Type "help" for help.# 创建用户并设置密码postgres=# CREATE USER weixin with password '123456';# 设置为超级管理员postgres=# alter user weixin superuser;# 创建数据库postgres=# create database workos_wx;
13、导入业务数据表到数据库
创建目录 /data/pgsql_data ,并授权给用户 postgres,过程不赘述(导入完成后,该目录直接删除即可);上传业务数据库的sql文件到当前目录下。
使用postgres用户,在 /data/pgsql/bin 目录下执行导入
注意:
这里注意,./psql -d database 一定不要写成 ./psql -s database ;要不然就会有敲不完的回车.....
# 导入sql文件时,先导入序列,再创建表[postgres@mr13 bin]$ pwd/data/pgsql/bin# 导入序列[postgres@mr13 bin]$ ./psql -d workos_wx -a -f /data/pgsql_data/序列.sql# 创建表[postgres@mr13 bin]$ ./psql -d workos_wx -a -f /data/pgsql_data/表.sql
