@Mr-13
2020-08-07T01:37:17.000000Z
字数 32495
阅读 157
limits.conf和sysctl.conf那些事儿
Linux
- limits.conf和sysctl.conf那些事儿
- 一、/etc/security/limits.conf
- 二、/etc/sysctl.conf(内核版本3.10)
- 1、fs.* 设置
- 2、kernel.* 设置
- kernel.cad_pid
- kernel.ctrl-alt-del
- kernel.core_pattern
- kernel.core_pipe_limit
- kernel.core_uses_pid
- kernel.dmesg_restrict
- kernel.kptr_restrict
- kernel.modprobe
- kernel.modules_disabled
- kernel.msgmax
- kernel.msgmnb
- kernel.msgmni
- kernel.numa_balancing
- kernel.panic
- kernel.panic_on_oops
- kernel.panic_on_warn
- perf 性能分析工具
- kernel.pid_max
- kernel.pty.max
- kernel.pty.nr
- kernel.pty.reserve
- kernel.random.boot_id
- kernel.random.entropy_avail
- kernel.random.poolsize
- kernel.random.read_wakeup_threshold
- kernel.random.uuid
- kernel.random.write_wakeup_threshold
- kernel.randomize_va_space
- kernel.sched_child_runs_first
- kernel.sched_latency_ns
- kernel.sched_migration_cost_ns
- kernel.sched_min_granularity_ns
- kernel.sched_nr_migrate
- kernel.sched_rr_timeslice_ms
- kernel.sched_rt_period_us、kernel.sched_rt_runtime_us
- kernel.sched_tunable_scaling
- kernel.sched_wakeup_granularity_ns
- kernel.sem
- kernel.shm_rmid_forced
- kernel.shmall
- kernel.shmmax
- kernel.shmni
- kernel.stack_tracer_enabled
- kernel.sysrq
- kernel.threads-max
- kernel.unknown_nmi_panic
- kernel.watchdog
- kernel.watchdog_thresh
- 3、net.core
- net.core.bpf_jit_enable
- net.core.busy_poll
- net.core.busy_read
- net.core.dev_weight
- net.core.message_burst
- net.core.message_cost
- net.core.netdev_max_backlog
- net.core.netdev_tstamp_prequeue
- net.core.optmem_max
- net.core.rmem_default
- net.core.rmem_max
- net.core.somaxconn
- net.core.wmem_default
- net.core.wmem_max
- 4、net.ipv4
- net.ipv4.conf.all.accept_local
- net.ipv4.conf.all.accept_redirects
- net.ipv4.conf.all.accept_source_route
- net.ipv4.conf.all.arp_announce(定义ARP宣告时候使用的Sender IP)
- net.ipv4.conf.all.arp_ignore
- net.ipv4.conf.all.forwarding
- net.ipv4.conf.all.promote_secondaries
- net.ipv4.conf.all.rp_filter
- net.ipv4.conf.all.secure_redirects
- net.ipv4.conf.all.send_redirects
- net.ipv4.icmp_echo_ignore_all
- net.ipv4.icmp_echo_ignore_broadcasts
- net.ipv4.icmp_ignore_bogus_error_responses
- net.ipv4.icmp_ratelimit
- net.ipv4.ip_forward
- net.ipv4.ip_local_port_range
- net.ipv4.ip_local_reserved_ports
- net.ipv4.ip_no_pmtu_disc
- net.ipv4.ip_nonlocal_bind
- net.ipv4.ipfrag_high_thresh、net.ipv4.ipfrag_low_thresh
- net.ipv4.ipfrag_max_dist
- net.ipv4.route.gc_timeout
- 5、net.ipv4.tcp
- net.ipv4.tcp_abort_on_overflow
- net.ipv4.tcp_adv_win_scale
- net.ipv4.tcp_app_win
- net.ipv4.tcp_challenge_ack_limit
- net.ipv4.tcp_congestion_control
- net.ipv4.tcp_dsack
- net.ipv4.tcp_ecn
- net.ipv4.tcp_fack
- net.ipv4.tcp_fastopen
- net.ipv4.tcp_fin_timeout
- net.ipv4.tcp_keepalive_*
- net.ipv4.tcp_limit_output_bytes
- net.ipv4.tcp_low_latency
- net.ipv4.tcp_max_orphans
- net.ipv4.tcp_max_syn_backlog
- net.ipv4.tcp_max_tw_buckets
- net.ipv4.tcp_mem
- net.ipv4.tcp_moderate_rcvbuf
- net.ipv4.tcp_mtu_probing
- net.ipv4.tcp_no_metrics_save
- net.ipv4.tcp_orphan_retries
- net.ipv4.tcp_reordering
- net.ipv4.tcp_retrans_collapse
- net.ipv4.tcp_retries1
- net.ipv4.tcp_retries2
- net.ipv4.tcp_rfc1337
- net.ipv4.tcp_rmem
- net.ipv4.tcp_sack
- net.ipv4.tcp_slow_start_after_idle
- net.ipv4.tcp_stdurg
- net.ipv4.tcp_syn_retries
- net.ipv4.tcp_synack_retries
- net.ipv4.tcp_syncookies
- net.ipv4.tcp_timestamps
- net.ipv4.tcp_tso_win_divisor
- net.ipv4.tcp_tw_recycle
- net.ipv4.tcp_tw_reuse
- net.ipv4.tcp_window_scaling
- net.ipv4.tcp_wmem
- net.ipv4.tcp_workaround_signed_windows
- net.ipv4.udp_mem
- 6、net.netfilter
- net.netfilter.nf_conntrack_buckets
- net.netfilter.nf_conntrack_count
- net.netfilter.nf_conntrack_generic_timeout
- net.netfilter.nf_conntrack_icmp_timeout
- net.netfilter.nf_conntrack_max
- net.netfilter.nf_conntrack_tcp_be_liberal
- net.netfilter.nf_conntrack_tcp_loose
- net.netfilter.nf_conntrack_max_retrans
- net.netfilter.nf_conntrack_tcp_timeout_close
- net.netfilter.nf_conntrack_tcp_timeout_close_wait
- net.netfilter.nf_conntrack_tcp_timeout_established
- net.netfilter.nf_conntrack_tcp_timeout_fin_wait
- net.netfilter.nf_conntrack_tcp_timeout_last_ack
- net.netfilter.nf_conntrack_tcp_timeout_max_retrans
- net.netfilter.nf_conntrack_tcp_timeout_syn_recv
- net.netfilter.nf_conntrack_tcp_timeout_syn_sent
- net.netfilter.nf_conntrack_tcp_timeout_time_wait
- net.netfilter.nf_conntrack_tcp_timeout_unacknowledged
- net.netfilter.nf_conntrack_udp_timeout
- net.netfilter.nf_conntrack_udp_timeout_stream
- net.nf_conntrack_max
- net.unix.max_dgram_qlen
- 7、vm
- vm.admin_reserve_kbytes
- vm.block_dump
- vm.dirty_background_bytes
- vm.dirty_background_ratio
- vm.dirty_bytes
- vm.dirty_expire_centisecs
- vm.dirty_ratio
- vm.dirty_writeback_centisecs
- vm.drop_caches
- vm.extfrag_threshold
- vm.hugetlb_shm_group
- vm.max_map_count
- vm.memory_failure_early_kill
- vm.memory_failure_recovery
- vm.min_free_kbytes
- vm.min_slab_ratio
- vm.min_unmapped_ratio
- vm.mmap_min_addr
- vm.nr_hugepages
- vm.nr_hugepages_mempolicy
- vm.nr_hugepages_mempolicy
- vm.oom_dump_tasks
- vm.oom_kill_allocating_task
- vm.overcommit_kbytes
- vm.overcommit_memory
- vm.overcommit_ratio
- vm.page-cluster
- vm.panic_on_oom
- vm.stat_interval
- vm.swappiness
- vm.vfs_cache_pressure
- vm.zone_reclaim_mode
一、/etc/security/limits.conf
1、工作原理
limits.conf 文件实际是Linux PAM(插入式认证模块,Pluggable Authentication Modules中pam_limits.so的配置文件),突破系统的默认限制,对系统访问资源有一定保护作用,当用户访问服务器时,服务程序将请求发送到PAM模块,PAM模块根据服务名称在/etc/pam.d目录下选择一个对应的服务文件,然后根据服务文件的内容选择具体的PAM模块进行处理。
limits.conf 和sysctl.conf区别在于:
/etc/security/limits.conf 是针对用户;
/etc/sysctl.conf 是针对整个系统(内核)参数配置。
2、文件格式
username|@groupname type resource limi
1)、username|@groupname
设置需要被限制的用户名,组名前面加@和用户名区别。也可用通配符 * 来做所有用户的限制
2)、type
类型有 soft,hard 和 - ;
soft : 指的是当前系统生效的设置值。
hard : 表明系统中所能设定的最大值,soft的限制不能比hard限制高。
- : 表明同时设置了soft和hard的值。
3)、resource: 表示要限制的资源
core :限制内核文件的大小
core file : 当一个程序崩溃时,在进程当前工作目录的core文件中复制了该进程的存储映像。core文件仅仅是一个内存映象(同时加上调试信息),主要是用来调试的。core文件是个二进制文件,需要用相应的工具来分析程序崩溃时的内存映像,系统默认core文件的大小为0,所以没有被创建。可以用ulimit命令查看和修改core文件的大小。 #ulimit -c 0 #ulimit -c 1000 #ulimit -c unlimited
注意:
如果想让修改永久生效,则需要修改配置文件,如 .bash_profile、/etc/profile或/etc/security/limits.confdate :最大数据大小
fsize :最大文件大小
memlock :最大锁定内存地址空间
nofile :打开文件的最大数目。对于需要做许多套接字连接并使它们处于打开状态的应用程序而言,最好通过使用ulimit -n,或者通过设置nofile参数,为用户把文件描述符的数量设置得比默认值高一些。
rss : 最大持久设置大小
stack :最大栈大小
cpu :以分钟为单位的最多 CPU 时间
noproc :进程的最大数目
as :地址空间限制
maxlogins :此用户允许登录的最大数量
通过 ulimit -a 可以查看限制数量
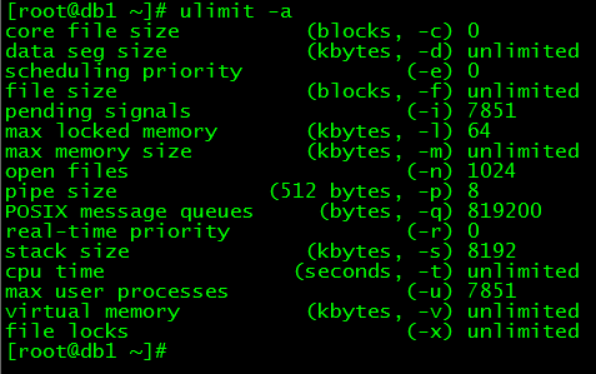
3、Centos5/6下的设置
centos5/6,只需要关注 /etc/security/limits.conf 和 /etc/security/limits.d/ 下配置文件:
open files 设置
- 在/etc/security/limits.conf下,添加以下两行
* soft nofile 65535
* hard nofile 65535- 重启服务器
通过ulimit -a查看,如上面没有生效,添加如下步骤:
- find / -name pam_limits.so
- 在/etc/pam.d/login下结尾处添加:
session required /usr/lib64/security/pam_limits.so
路径为第1步查找时给的结果反馈- 重启服务器
注:
ulimit其实就是对单一程序的限制,进程级别的。
/proc/sys/fs/file-max,该参数指定系统范围内所有进程可以打开的文件句柄的数量限制。
.
file-max 设置
$ vim /etc/sysctl.conf# 添加/修改如下配置节fs.file-max = 2000000# 重新加载配置参数,使配置生效$ sysctl -p# 查看当参数,是否生效$ cat /proc/sys/fs/file-max
.
max user memory 设置
在 /etc/security/limits.d/90-nproc.conf 下,修改以下行(建议值65535)
* soft nproc 1024
.
4、Centos7下设置
centos7下,/etc/security/limits.conf 和 /etc/security/limits.d/ 仅适用于通过PAM认证登录用户的资源限制,但是对systemd的service资源限制不生效。
PAM认证顺序: Service(服务) -> PAM(配置文件) -> pam_*.so ;
PAM认证首先要确定哪一项服务,然后加载相应的PAM的配置文件(位于/etc/pam.d下),最后调用认证文件(位于/lib/security下)进行安全认证。
对于 systemd service 的资源限制,主要依靠 /etc/systemd/system.conf 和 /etc/systemd/user.conf ,同时也会加载两个对应的目录中的所有.conf文件 /etc/systemd/system.conf.d/*.conf 和 /etc/systemd/user.conf.d/*.conf。
system.conf 是系统实例使用的,user.conf 用户实例使用的。一般的service,使用system.conf中的配置即可。
针对单个Service也可以设置,比如nginx.service
LimitNOFILE=65535LimitNPROC=65535
.
open files 设置
- 在/etc/security/limits.conf下,添加以下两行
* soft nofile 65535
* hard nofile 65535- 重启服务器
通过ulimit -a查看,如上面没有生效,添加如下步骤:
- find / -name pam_limits.so
- 在/etc/pam.d/login下结尾处添加:
session required /usr/lib64/security/pam_limits.so
路径为第1步查找时给的结果反馈- 重启服务器
注:
ulimit其实就是对单一进程的限制,进程级别的。/proc/sys/fs/file-max,该参数指定系统范围内所有进程可以打开的文件句柄的数量限制。
.
file-max 设置
vi /etc/sysctl.conf# 修改/添加如下配置节fs.file-max = 2000000# 重新加载配置参数,使配置生效sysctl -p# 查看当前参数,是否生效cat /proc/sys/fs/file-max
.
max user memory 设置
vim /etc/systemd/system.conf# 修改/添加配置节如下DefaultLimitNPROC=100000# 重启服务器reboot# 查看配置是否生效cat /proc/mysql的PID/limits
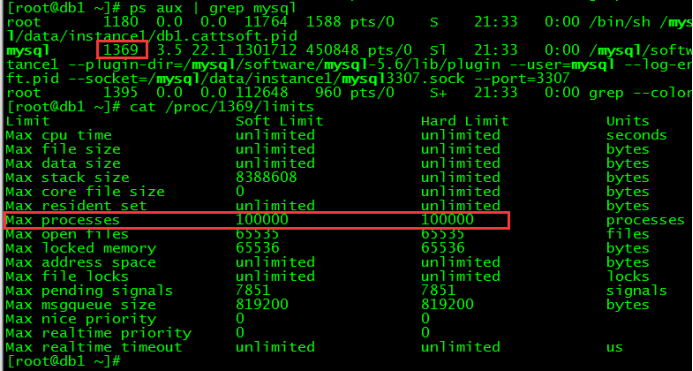
注:
Centos7一次性修改core、max_processes、max_open_file三个参数方法:
$ vi /etc/systemd/system.conf# 编辑/添加配置节如下:DefaultLimitCORE=infinityDefaultLimitNOFILE=100000 #(建议值65535)DefaultLimitNPROC=100000 #(建议值65535)# 重启服务器$ reboot# 查看参数是否生效cat /proc/mysql的PID/limits
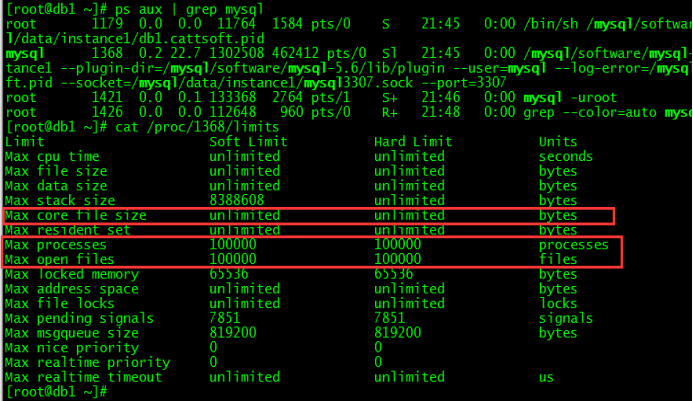
.
二、/etc/sysctl.conf(内核版本3.10)
/proc/sys 目录下存放着大多数内核参数,并且可以在系统运行时进行更改,不过重新启动机器就会失效。
/etc/sysctl.conf 是一个允许改变正在运行中的Linux系统接口,它包含一些TCP/IP堆栈和虚拟内存系统的高级选项,修改内核参数永久生效。
也就是说/proc/sys下内核文件与配置文件sysctl.conf中变量存在着对应关系。
常见参数及设置:
1、fs.* 设置
.
fs.aio-max-nr 设置
表示同时拥有的异步IO请求数量。Oracle建议将该参数设置为1048576或更高。
默认值:65536
fs.aio-nr
表示当前IO请求数量。该参数为只读参数。
fs.epoll.max_user_watches
一个用户能够往epoll 内核事件表注册的事件总量,它是指该用户打开的所有epoll实例总共能监听的事件数目,而不是单个epoll实例能监听的事件数目。这个内核参数限制了epoll使用的内核内存总量。
默认值:411648
fs.file-max
表示系统级文件描述符数限制最大值,是对整个系统的限制,并不是针对用户的。
粗暴一点理解,file-max 限制内容可以打开的最大文件数量。
当前测试环境默认为198266。建议计算的公式:
grep -r MemTotal /proc/meminfo | awk '{printf("%d",$2/10)}'
文件描述符:
内核(kernel)利用文件描述符(file descriptor)来访问文件。文件描述符是非负整数。打开现存文件或新建文件时,内核会返回一个文件描述符。读写文件也需要使用文件描述符来指定待读写的文件。
fs.file-nr
文件与file-max相关,它有三个值:已分配文件句柄的数目,已使用文件句柄的数目,文件句柄的最大数目,该文件是只读的,仅用于显示信息。
fs.inode-state
此文件保存了三个值,前两个分别表示已分配inode数和空闲inode数。第三个是已超出系统最大inode值的数量,此时系统需清除排查inode列表
inotify-tools相关内核参数
fs.inotify.max_queued_events:
表示调用inotify_init时分配给inotify instance中可排队的event的数目的最大值,超出这个值的事件被丢弃,但会触发IN_Q_OVERFLOW事件。fs.inotify.max_user_instances:表示每一个real user ID可创建的inotify instatnces的数量上限。
fs.inotify.max_user_watches:表示每个inotify instatnces可监控的最大目录数量。如果监控的文件数目巨大,需要根据情况,适当增加此值的大小。
租借锁相关内核参数
fs.lease-break-time = 45:表示租借锁时间为45s
fs.leases-enable = 1:表示启用租借锁,默认状态启用。
fs.nr_open
表示单个进程可分配的最大文件数,注意ulimit的nofile hard limit(/etc/security/limits.conf中配置)不能超过该值,否则会造成无法登录。
默认值为:1048576
fs.protected_hardlinks
用于限制普通用户建立硬链接:
0:不限制用户建立硬链接
1:限制,如果文件不属于用户,或者用户对此用户没有读写权限,则不能建立硬链接
默认值为:1
fs.protected_symlinks
用于限制普通用户建立软链接
0:不限制用户建立软链接
1:限制,允许用户建立软连接的情况是软连接所在目录是全局可读写目录或者软连接的uid与跟从者的uid匹配,又或者目录所有者与软连接所有者匹配
默认值:1
fs.suid_dumpable
表示如果一个程序设定了setuid,那么普通用户在默认情况下不生成core文件,只有当该参数为1时,才会产生。
默认值为0
.
2、kernel.* 设置
.
kernel.cad_pid
表示接收Ctrl+Alt+Del操作的INT信号的进程的PID
默认值为1
PID=1的进程:
centos7之前是 init ,centos7开始是 systemd ;叫根进程,或者超级进程; 是内核完成之后启动的第一个进程,然后init根据/etc/inittab的内容再去启动其它进程
kernel.ctrl-alt-del
该值表示控制系统在接收到 ctrl+alt+delete 按键组合时如何反应:
1:不捕获ctrl-alt-del,将系统类似于直接关闭电源
0:捕获ctrl-alt-del,并将此信号传至cad_pid保存的PID号进程进行处理
默认值为0
kernel.core_pattern
设置core文件保存位置或文件名,只有文件名时,则保存在应用程序运行的目录下
默认值为core
kernel.core_pipe_limit
定义了可以有多少个并发的崩溃程序可以通过管道模式传递给指定的core信息收集程序。如果超过了指定数,则后续的程序将不会处理,只在内核日志中做记录。0是个特殊的值,当设置为0时,不限制并行捕捉崩溃的进程,但不会等待用户程序搜集完毕方才回收/proc/pid目录(就是说,崩溃程序的相关信息可能随时被回收,搜集的信息可能不全)。
默认值为:0
kernel.core_uses_pid
Core文件的文件名是否添加应用程序pid做为扩展:
0:表示不添加;
1:表示添加;
默认值为1
kernel.dmesg_restrict
限制哪些用户可以查看syslog日志:
0:表示不限制;
1:表示只有特权用户可以查看。
默认值为0
kernel.kptr_restrict
是否启用kptr_restrice,此功能为安全性功能,用于屏蔽内核指针。
0:该特性被完全禁止;
1:那些使用“%pk”打印出来的内核指针被隐藏(会以一长串0替换掉),除非用户有CAP_SYSLOG权限,并且没有改变他们的UID/GID(防止在撤销权限之前打开的文件泄露指针信息);
2:所有内核指使用“%pk”打印的都被隐藏。
默认值为0,建议设置为1
kernel.modprobe
该文件给出了当系统支持module时完成modprobe功能的程序的名字(包括路径)
默认值为:/sbin/modprobe
kernel.modules_disabled
表示是否禁止内核运行时可加载模块:
0:表示不禁止
1:表示禁止
默认值为0
kernel.msgmax
消息队列中单个消息的最大字节数。
默认值为:8192
kernel.msgmnb
单个消息队列中允许的最大字节长度(限制单个消息队列中所有消息包含的字节数之和)
默认值为:16384
kernel.msgmni
系统中同时运行的消息队列的个数
默认值为:3965
kernel.numa_balancing
表示是否禁止NUMA自动平衡策略,0表示禁止,1表示不禁止。
默认为:0
补充:numa相关知识
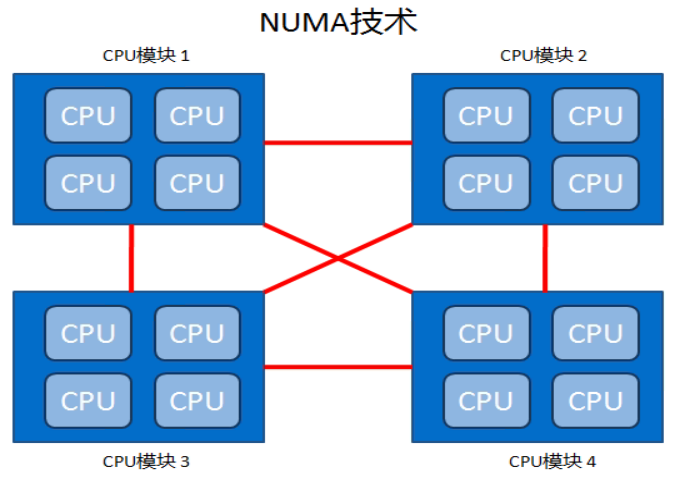
numactl需要安装相应软件包numactl.x86_64
$ dmesg | grep -i numa # 若有返回值表示CPU支持NUMA,例如下图:

numastat查看具体numa信息
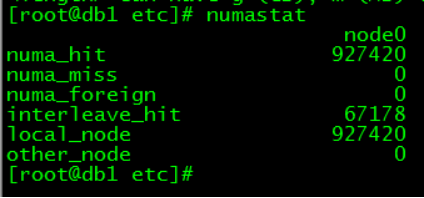
numa_hit :是打算在该节点上分配内存,最后从这个节点分配的次数;
num_miss :是打算在该节点分配内存,最后却从其他节点分配的次数;
num_foregin :是打算在其他节点分配内存,最后却从这个节点分配的次数;
interleave_hit :是采用interleave策略最后从该节点分配的次数;
local_node :该节点上的进程在该节点上分配的次数
other_node :是其他节点进程在该节点上分配的次数
numactl --hardare # 查看不同节点的内存总大小,可用大小及node distance
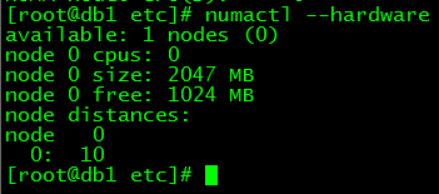
建议:
数据库服务器关闭该功能,centos7,vi /etc/grub2.cfg
找到rhgb quiet,在他们后面加上“numa=off”,重启即可。
kernel.panic
系统发生panic时内核重新引导之前的等待时间,0表示禁止重新引导,>0表示引导前等待几秒。
默认值为:0
kernel.panic_on_oops
当系统发生oops或BUG时,所采取的措施,0表示继续运行,1表示让klog记录oops的输出,然后panic,若kernel.panic不为0,则等待后重新引导内核
默认值为:1
kernel.panic_on_warn
0: 表示只警告,不发生panic;
1: 表示发生panic
默认值为:0
perf 性能分析工具
- kernel.perf_cpu_time_max_percent:perf
分析工具最大能够占用CPU性能的百分比:
0: 表示不限制;
1~100: 表示百分比
默认值为:25
- kernel.perf_event_max_sample_rate:
设置perf_event最大取样速率
默认值:10000
- kernel.perf_event_mlock_kb:
设置非特权用户允许常驻内存的内存大小。
默认值为516(KB)
- kernel.perf_event_paranoid:
用于限制访问性能计数器的权限。
0:表示仅允许访问用户空间的性能计数器;
1:表示内核与用户空间的性能计数器都可以访问
2:表示仅允许访问特殊的CPU数据
-1:表示不限制
默认值为:1
kernel.pid_max
表示当前操作系统PID的最大值
64位操作系统最大值为4194303
默认值:131072
kernel.pty.max
所分配的PTY的最大值(PTY为虚拟终端,用于远程连接)
默认为:4096
kernel.pty.nr
当前配置的PTY个数。该参数为可变参数。
kernel.pty.reserve
保留的PTY个数,主要分配给系统使用。
默认值为:1024
kernel.random.boot_id
此文件是个只读文件,包含了一个随机字符串,在系统启动的时候会自动生成这个uuid。
kernel.random.entropy_avail
此文件是个只读文件,给出了一个有效的熵(4096位)
kernel.random.poolsize
熵池大小,一般是4096位,可以改成任何大小。
kernel.random.read_wakeup_threshold
该文件保存熵的长度,该长度用于唤醒因读取/dev/random设备而待机的进程(random设备的读缓冲区长度)
kernel.random.uuid
此文件是个只读文件,包含了一个随机字符串,在random设备每次被读的时候生成。
kernel.random.write_wakeup_threshold
该文件保存熵的长度,该长度用于唤醒因写入/dev/random设备而待机的进程(random设备的写缓冲区长度)
kernel.randomize_va_space
用于设置进程虚拟地址空间的随机化。
0:表示关闭进程虚拟地址空间随机化
1:表示随机化进程虚拟地址空间中的mmap映射区的初始地址,栈空间的初始地址以及VDSO页的地址
2:表示在1的基础上加上堆区的随机化
默认值为:2
kernel.sched_child_runs_first
设置保证子进程初始化完成后在父进程之前先被调度。
0:表示先调度父进程
1:表示先调度子进程
默认值为:0
kernel.sched_latency_ns
表示正在运行进程的所能运行的时间的最大值,即使只有一个处于running状态的进程,运行到这个时间也要重新调度一次(以纳秒为单位,在运行时会自动变化)
同时这个值也是所有可运行进程都运行一次所需的时间;
每个CPU的running进程数 = sched_latency_ns / sched_min_granularity_ns
kernel.sched_migration_cost_ns
该变量用来判断一个进程是否还是hot,如果进程的运行时间(now - p->se.exec_start)小于它,那么内核认为它的code还在cache里,所以该进程还是hot,那么在迁移的时候就不会考虑它。
默认值为:500000
kernel.sched_min_granularity_ns
表示一个进程在CPU上运行的最小时间,在此时间内,内核是不会主动挑选其他进程进行调度(以纳秒为单位,在运行时会自动变化)
默认值为:10000000
kernel.sched_nr_migrate
在多CPU情况下进行负载均衡时,一次最多移动多少个进程到另一个CPU上。
默认值为:32
kernel.sched_rr_timeslice_ms
用来指示round robin调度进程的间隔,这个间隔默认是100ms。
默认值为:100ms
kernel.sched_rt_period_us、kernel.sched_rt_runtime_us
sched_rt_period 与 sched_rt_runtime_us一起决定了实时进程在以sched_rt_period为周期的时间内,实时进程最多能够运行的总的时间不能超过sched_rt_runtime_us。
默认值:
kernel.sched_rt_period_us = 1000000
kernel.sched_rt_runtime_us = 950000
kernel.sched_tunable_scaling
当内核试图调整sched_min_granularity_ns,sched_latency_ns和sched_wakeup_granularity_ns这三个值的时候所使用的更新方法。
0:不调整
1:按照cpu个数以2为底的对数值进行调整
2:按照cpu的个数进行线性比例的调整
默认值为:1
kernel.sched_wakeup_granularity_ns
该变量表示进程被唤醒后至少应该运行的时间的基数,它只是用来判断某个进程是否应该抢占当前进程,并不代表它能够执行的最小时间(sysctl_sched_min_granularity),如果这个数值越小,那么发生抢占的概率也就越高。
默认值为:15000000
kernel.sem
该变量的四个值分别表示 SEMMSL、SEMMNS、SEMOPM、SEMMNI
SEMMSL:
每个信号集的最大信号数量,数据库最大PROCESS实例参数的设置值再加上10,oracle建议将SEMMSL的值设置为不少于100。SEMMNS:
用于控制整个Linux系统中信号(而不是信号集)的最大数。Oracle建议将SEMMNS设置为:系统中每个数据库的PROCESSES实例参数设置值的总和,加上最大PROCESSED值的两倍,最后根据系统中Oracle数据库的数量,每个加10。
使用以下计算方式来确定在Linux系统中可以分配的信号最大数量。它将是以下两者中较小的一个值:
SEMMNS 或 SEMMSL*SEMMNISEMOPM:
内核参数用于控制每个 semop 系统调用可以执行的信号操作的数量。semop 系统调用(函数)提供了利用一个 semop 系统调用完成多项信号操作的功能。一个信号集能够拥有每个信号集中最大数量的SEMMSL 信号,因此建议设置 SEMOPM 等于SEMMSL 。
Oracle 建议将 SEMOPM 的值设置为不少于 100 。SEMMNI:
内核参数用于控制整个 Linux 系统中信号集的最大数量。
Oracle 建议将 SEMMNI 的值设置为不少于100。
默认参数:kernel.sem = 250 32000 32 128
Oracle参考值:kernel.sem = 5010 641280 5010 128
kernel.shm_rmid_forced
表示是否强制将共享内存和一个进程联系在一起,这样的话可以通过杀死进程来释放共享内存。
默认值为:0;建议设置为:1
kernel.shmall
系统上可以使用的共享内存的总量(以字节为单位)
默认为:18446744073692774399,可以根据内存大小设置,如64*1024*1024*1024 / 4K = 16777216
kernel.shmmax
系统所允许的最大共享内存段的大小(以字节为单位)
默认为:18446744073692774399,可以根据内存大小设置,如64*1024*1024*1024 = 68719476736
kernel.shmni
整个系统共享内存段的最大数量
默认值:4096
shmmax(bytes) = shmmni(page size, default 4k) * shmall (page的个数)
kernel.stack_tracer_enabled
表示是否开启栈底溢出检测,0表示不启用,1表示启用。
默认值为:0
kernel.sysrq
该文件指定的值为非零,则激活键盘上的sysrq按键。这个按键用于给内核传递信息,用于紧急情况下重启系统。当遇到死机或者没有响应的时候,甚至连 tty 都进不去,可以尝试用 SysRq 重启计算机。
默认值为:16。为了安全起见,建议修改为0
kernel.threads-max
表示指定内核所能使用的线程最大数目,基本可以理解为每个进程所允许打开的线程最大数量。
默认值为:15703
kernel.unknown_nmi_panic
该参数的值影响的行为(非屏蔽中断处理)。当这个值为非0,未知的NMI受阻,PANIC出现。这时,内核调试信息显示控制台,则可以减轻系统中的程序挂起。
默认值为:0
kernel.watchdog
表示是否禁止softlockup模式和nmi_watchdog(softlockup用于唤醒watchdog)。0表示禁止;1表示开启。
默认值为:0
kernel.watchdog_thresh
watchdog异常等待时间,表示watchdog设备被意外关闭而不是正常,从而造成cpu soft lockup而等待的时间。
默认值为:10(s)
.
3、net.core
.
net.core.bpf_jit_enable
基于时间规则的编译器,用于基于PCAP并使用伯克利包过滤器的用户工具,可以大幅提升复杂规则的处理性能。
0:禁止
1:开启
2:开启并请求编译器将跟踪数据时间写入内核日志
默认值为:0。基于NoSQL内存数据库时,建议启用该参数。
net.core.busy_poll
要在特定socket中启用繁忙轮询,将sysctl.net.core.busy_poll设置为除0以外的值,这一参数控制的是socket轮询和选择位于等待设备队列中数据包的微秒数。红帽推荐值为50。
默认值为:0
net.core.busy_read
要全局启用繁忙轮询,须将 sysctl.net.core.busy_read 设置为除了 0 以外的值。这一参数控制了socket 读取位于等待设备队列中数据包的微秒数,且设置了 SO_BUSY_POLL 选项的默认值。红帽推荐在 socket 数量少时将值设置为 50 , socket 数量多时将值设置为 100。对于 socket 数量极大时(超过几百),请使用 epoll。
默认值为:0
net.core.dev_weight
设备重量是指设备一次可以接收的数据包数量(单个预定处理器访问)。设备重量由 dev_weight 参数控制。
默认值为:64
net.core.message_burst
写新的警告消息所需的时间(以 1/10 秒为单位);在这个时间内所接收到的其它警告消息会被丢弃。这用于防止某些企图用消息“淹没”您系统的人所使用的拒绝服务(Denial of Service)攻击。
默认值为:10
net.core.message_cost
该文件表示写每个警告消息相关的成本值。该值越大,越有可能忽略警告消息。当用来防止DOS攻击时设置为0。
默认值为:5
net.core.netdev_max_backlog
每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
默认值为:1000
net.core.netdev_tstamp_prequeue
0:关闭,接收的数据包的时间戳在RPS程序处理之后进行标记,这样有可能时间戳会不够准确
1:打开,时间戳会尽可能早的标记。
默认值为:1
net.core.optmem_max
表示每个套接字所允许的最大缓冲区的大小。
默认值为20480,4G内存服务器推荐优化值为81920
net.core.rmem_default
设置接收TCP socket的缺省缓存大小(字节)。
根据硬件自动生成值为212992
net.core.rmem_max
设置接收socket的最大缓存大小(字节)
根据硬件自动生成值为212992
net.core.somaxconn
定义了系统中每一个端口最大的监听队列的长度,这是个全局的参数。
web应用中listen函数的backlog默认会给我们内核参数的net.core.somaxconn限制到128,而nginx定义的NGX_LISTEN_BACKLOG默认为511,所以有必要调整这个值。
默认值为:128
net.core.wmem_default
设置发送TCP socket的缺省缓存大小(字节)。
根据硬件自动生成值为212992
net.core.wmem_max
设置发送socket的最大缓存大小(字节)
根据硬件自动生成值为212992
.
4、net.ipv4
.
net.ipv4.conf.all.accept_local
设置是否允许接收从本机IP地址上发送给本机的数据包
0:表示不允许
1:表示允许
默认值为:0。
net.ipv4.conf.all.accept_redirects
收发接收ICMP重定向消息。对于主机来说默认为True,对于用作路由器时默认值为False。
0:表示禁止
1:表示允许
默认值为:1。建议修改为0。
net.ipv4.conf.all.accept_source_route
表示是否接收源路由数据包
0:表示禁止
1:表示允许
默认值为:0
net.ipv4.conf.all.arp_announce(定义ARP宣告时候使用的Sender IP)
Define different restriction levels for announcing the local source IP address from IP packets in ARP requests sent on interface:
0:表示在任意网络接口的任何本地地址。
1:尽量避免不在该网络接口子网段的本地地址。当发起ARP请求的源IP地址是被设置应该经由路由达到此网络接口的时候很有用。此时会检查来访IP是否为所有接口上的子网段内ip之一。如果改来访IP不属于各个网络接口上的子网段内,那么将采用级别2的方式来进行处理。
2:对查询目标使用最适当的本地地址。在此模式下将忽略这个IP数据包的源地址并尝试选择与能与该地址通信的本地地址。首要是选择所有的网络接口的子网中外出访问子网中包含该目标IP地址的本地地址。如果没有合适的地址被发现,将选择当前的发送网络接口或其他的有可能接受到该ARP回应的网络接口来进行发送。
默认值为:0。建议设置为2。(nginx keepalive配置时)
net.ipv4.conf.all.arp_ignore
定义对目标地址为本地IP的ARP询问不同的应答模式
0:回应任何网络接口上对任何本地IP地址的arp查询请求
1:只回答目标IP地址是来访网络接口本地地址的ARP查询请求(不限定ARP请求源IP地址,ARP目的IP必须为本接口IP,才回应ARP请求)
2:只回答目标IP地址是来访网络接口本地地址的ARP查询请求,且来访IP必须在该网络接口的子网段内(限定ARP请求源IP地址必须在该接口的子网内,ARP目的IP必须为本接口IP,才回应ARP请求)
3:不回应该网络界面的arp请求,而只对设置唯一和连接地址做出回应
8:不回应所有(包含本地地址)的arp查询
默认值为:0,建议设置为1(nginx keepalive配置时)
net.ipv4.conf.all.forwarding
表示是否启用端口转发功能
0:表示禁止
1:表示允许
默认值为:0。如果需要做NAT等要求,则需要打开该功能。
net.ipv4.conf.all.promote_secondaries
0:当接口的主IP地址被移除时,删除所有次IP地址
1:当接口的主IP地址被移除时,将次IP地址提升为主IP地址
默认值为:1。
net.ipv4.conf.all.rp_filter
0:不通过反向路径回溯进行源地址验证。
1:通过反向路径回溯进行源地址验证(在RFC1812中定义)。对于单穴主机和stub网络路由器推荐使用该选项。
默认值为:1。
net.ipv4.conf.all.secure_redirects
仅仅接收发给默认网关列表中网关的ICMP重定向消息
0:表示禁止
1:表示允许
默认值为:1。
net.ipv4.conf.all.send_redirects
允许发送重定向路由
0:表示禁止
1:表示允许
默认值为1。建议修改为0。
注:
net.ipv4.conf.{all|default|ethX|lo}下选项都是一样的。
net.ipv4.icmp_echo_ignore_all
忽略所有接收到的icmp echo请求的包(会导致机器无法ping通)
0:表示不忽略
1:表示忽略
默认值为:0。
net.ipv4.icmp_echo_ignore_broadcasts
忽略所有接收到的icmp echo请求的广播
0:不忽略
1:忽略
默认值为:1。
net.ipv4.icmp_ignore_bogus_error_responses
错误消息防护,会警告你关于网络中的ICMP异常
0:记录到系统日志中
1:忽略
默认值为:1。
net.ipv4.icmp_ratelimit
限制发向特定目标的匹配icmp_ratemask的ICMP数据报的最大速率。配合icmp_ratemask使用。
0:没有任何限制
>0:表示指定时间内中允许发送的个数。(以jiffies为单位,一般为10ms)
默认值为:1000。
net.ipv4.ip_forward
是否打开ipv4的IP转发。
0:禁止
1:打开
默认为0,表示不启用端口转发。
注:
建议在开启该功能,同时还要针对net.ipv4.conf.{all|default|ethX}.forwarding几个选项一起设置。
net.ipv4.ip_local_port_range
本地发起连接时使用的端口范围,tcp初始化时会修改此值
默认为:32768 60999。建议至少为1000 65535
net.ipv4.ip_local_reserved_ports
表示设置预留的端口,这些端口不是会随机分配出去。
默认为空
例: net.ipv4.ip_local_reserved_ports = 1986, 11211-11220
net.ipv4.ip_no_pmtu_disc
表示在全局范围内关闭路径MTU探测功能
0:表示开启
1:表示关闭
默认值为:0。
net.ipv4.ip_nonlocal_bind
如果您想让应用程式能够捆绑到一个不属于该系统的IP地址﹐就需要设定这里。(当机器使用非固定/动态的网络连接的时候,或者离线调试程序的时候,当线路断掉之后,该服务仍可启动而且捆绑到特定的位址之上。)keepalive可能需要用到该参数。
0:表示禁止
1:表示允许
默认值为:0。
net.ipv4.ipfrag_high_thresh、net.ipv4.ipfrag_low_thresh
表示用于重组IP分段的内存分配最高值和最低值。
net.ipv4.ipfrag_max_dist
相同的源地址ip碎片数据报的最大数量,这个变量表示在ip碎片被添加到队列前要作额外的检查.如果超过定义的数量的ip碎片从一个相同源地址到达,那么假定这个队列的ip碎片有丢失,已经存在的ip碎片队列会被丢弃,如果为0关闭检查。
默认值为:64。
net.ipv4.route.gc_timeout
设置一个路由表项的过期时长(秒)。
默认值为:300秒。建议修改100。
.
5、net.ipv4.tcp
.
net.ipv4.tcp_abort_on_overflow
当 tcp 建立连接的 3 次握手完成后,将连接置入 ESTABLISHED 状态并交付给应用程序的 backlog 队列时,会检查 backlog 队列是否已满。若已满,通常行为是将连接还原至 SYN_ACK 状态,以造成 3 路握手最后的 ACK 包意外丢失假象 —— 这样在客户端等待超时后可重发 ACK —— 以再次尝试进入 ESTABLISHED 状态 —— 作为一种修复/重试机制。
如果启用tcp_abort_on_overflow则在检查到 backlog 队列已满时,直接发 RST 包给客户端终止此连接 —— 此时客户端程序会收到 104 Connection reset by peer 错误。
0:表示不启用
1:表示启用
默认值为:0。
net.ipv4.tcp_adv_win_scale
linux使用net.ipv4.tcp_adv_win_scale(对应文件 /proc/sys/net/ipv4/tcp_adv_win_scale· )指出应用缓存的比例。
if tcp_adv_win_scale > 0:
应用缓存 = buffer / (2^tcp_adv_win_scale);
tcp_adv_win_scale默认值为2;
表示缓存的四分之一用于应用缓存,可用接收窗口占四分之三。
if tcp_adv_win_scale <= 0:
应用缓存 = buffer - buffer/2^(-tcp_adv_win_scale);
即接收窗口=buffer/2^(-tcp_adv_win_scale),
如果tcp_adv_win_scale=-2,接收窗口占接收缓存的四分之一。
如何算接收窗口呢?
BDP(bandwidth-delay product,带宽时延积) = bandwith(bits/sec) * delay(sec),代表网络传输能力,为了充分利用网络,最大接收窗口应该等于BDP;delay = RTT/2。
以我们的机房为例,同机房的带宽为30Gbit/s,两台机器ping可获得RTT大概为0.1ms,那
BDP=(30Gb/1000) * 0.1 / 2 = 1.5Mb
buffer = 1.5Mb * 4 / 3 = 2Mb
默认值为:1
net.ipv4.tcp_app_win
保留max(window/2^tcp_app_win, mss)数量的窗口用于应用缓冲。当为0时表示不需要缓冲。
默认值为:31
net.ipv4.tcp_challenge_ack_limit
内核3.6至4.7之间的操作系统,建议调整该值可以使得攻击者不能合理地达到主机。比如999999999
默认值为1000
net.ipv4.tcp_congestion_control
表示TCP拥塞控制算法
reno:是最基本的拥塞控制算法,也是TCP协议的实验原型。
bic:适用于rtt较高但丢包极为罕见的情况,比如北美和欧洲之间的线路,这是2.6.8到2.6.18之间的Linux内核的默认算法。
cubic:是修改版的bic,适用环境比bic广泛一点,它是2.6.19之后的linux内核的默认算法。
hybla:适用于高延时、高丢包率的网络,比如卫星链路;同样适用于中美之间的链路。
默认值为:cubic
hybla的使用方法:
/sbin/modprobe tcp_hyblavi /etc/sysctl.confnet.ipv4.tcp_congestion_control = hybla
net.ipv4.tcp_dsack
表示是否允许TCP发送“两个完全相同”的SACK。
0:禁止
1:启用
默认值为:1。
net.ipv4.tcp_ecn
表示显式拥塞通告。
1:表示套接字支持ECN协议
2:表示发送在接收到ECE报文后,设置该标志,并将拥塞状态机设置为TCP_CA_CWR状态
4:接收端处于该状态,将在所有ACK报文中添加ECE,直到接收到CWR报文
8:是否接收到过ECT报文
默认值为2。建议一般情况下不修改。
net.ipv4.tcp_fack
表示是否打开FACK拥塞避免和快速重传功能。
0:禁止
1:打开
默认值为:1。
net.ipv4.tcp_fastopen
三次握手会造成一个RTT的延迟,因此TFO(tcp fast open)的目标就是去除这个延迟,在三次握手期间也能交换数据。
0:表示关闭该功能
1:表示开启客户端TFO功能
2:表示开启服务器端TFO功能
3:表示同时开启客户端和服务器端TFO功能
默认为:0。建议高流量高并发服务器设置为3。
net.ipv4.tcp_fin_timeout
本端断开的socket连接,TCP保持在FIN-WAIT-2状态的时间。
默认值:60。建议修改为30或更低。
net.ipv4.tcp_keepalive_*
net.ipv4.tcp_keepalive_intvl = 75
net.ipv4.tcp_keepalive_probes = 9
net.ipv4.tcp_keepalive_time = 7200
以上三个参数合起来含义:
如果某个TCP连接在idle 2个小时后,内核才发起probe。
如果probe 9次(每次75秒)不成功,内核才彻底放弃,认为该连接已失效。
建议修改值:
net.ipv4.tcp_keepalive_intvl = 15
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_limit_output_bytes
每个套接字TCP队列的大小限制
默认值为:262144。
net.ipv4.tcp_low_latency
允许 TCP/IP 栈适应在高吞吐量情况下低延时的情况;这个选项一般情形是的禁用。(但在构建Beowulf 集群的时候,打开它很有帮助)
0:关闭
1:开启
默认值为:0。
net.ipv4.tcp_max_orphans
系统所能处理不属于任何进程的TCP sockets最大数量。假如超过这个数量,那么不属于任何进程的连接会被立即reset,并同时显示警告信息。
之所以要设定这个限制,纯粹为了抵御那些简单的 DoS 攻击,千万不要依赖这个或是人为的降低这个限制。因为增加过大会导致吃掉过多内存。
默认值:8192。
net.ipv4.tcp_max_syn_backlog
对于那些依然还未获得客户端确认的连接请求,需要保存在队列中最大数目。加大该值,可以容纳更多的等待连接的网络连接数。
默认值:128。推荐修改该,如8192、16384、262144。
同时该参数设置时,应不能比net.core.somaxconn数值大
net.ipv4.tcp_max_tw_buckets
系统在同时所处理的最大timewait sockets 数目。如果超过这个数字,TIME_WAIT将立刻被清除并打印警告信息。
默认值为8192。该参数可以适当调大,同时该不应该比net.ipv4.ip_local_port_range端口范围数值大很多。
net.ipv4.tcp_mem
tcp_mem(3个INTEGER变量):low, pressure, high,其单位是页,1页等于4096字节
low:当TCP使用低于该值的内存页面数时,TCP不会考虑释放内存。
pressure:当TCP使用了超过该值的内存页面数量时,TCP试图稳定其内存使用,进入pressure模式,当内存消耗低于low值时则退出pressure状态。
high:允许所有tcp sockets用于排队缓冲数据报的页面量,当内存占用超过此值,系统拒绝分配socket,后台日志输出“TCP: too many of orphaned sockets”。
一般情况下这些值是在系统启动时根据系统内存数量计算得到的。
默认值:46002 61339 92004(该值根据内存大小自动计算的),该数值建议与net.ipv4.tcp_rmem和net.ipv4.tcp_wmem同时考虑使用,并在实际环境按需修改。
net.ipv4.tcp_moderate_rcvbuf
接收数据时是否调整接收缓存
0:不调整
1:调整
默认值为:1
net.ipv4.tcp_mtu_probing
控制TCP分组层路径MTU发现。
0:表示不启用
1:表示默认不启用,当有一ICMP黑洞检测时启用
2:总是启用
默认值为:0。建议设置为1。
net.ipv4.tcp_no_metrics_save
默认情况下tcp会在连接关闭时也就是LAST_ACK状态保存各种连接信息到路由缓存中,新建立的连接可以使用这些条件来初始化。通常这会增加总体的系统性能,但是有些时候也会引起性能下降。如果开启该选项,TCP 在关闭的时候不缓存这些指标。
0:关闭
1:开启
默认值为:0。按需要考虑设置为1。
net.ipv4.tcp_orphan_retries
针对孤立的socket(也就是已经从进程上下文中删除了,可是还有一些清理工作没有完成).在丢弃TCP连接之前重试的最大的次数,重负载web服务器建议调小,net.ipv4.tcp_orphan_retries = 0并不是想像中的不重试。
默认值为:0。建议值1~3之间。
net.ipv4.tcp_reordering
TCP流中重排序的数据报最大数量 。
默认值为:3。
net.ipv4.tcp_retrans_collapse
对于某些有bug的打印机提供针对其bug的兼容性。
0:不启用
1:启用
默认值为:1。
net.ipv4.tcp_retries1
表示放弃回应一个TCP连接请求前进行重传的次数。
默认值为:3。建议不修改。
net.ipv4.tcp_retries2
表示放弃在已经建立通讯状态下的一个TCP数据包前进行重传的次数。
默认值为:15。建议修改该值为5~8。
net.ipv4.tcp_rfc1337
表示是否启动对于在RFC1337中描述的"tcp 的time-wait暗杀危机"问题的修复。启用后,内核将丢弃那些发往time-wait状态TCP套接字的RST 包。
0:关闭
1:开启
默认值为:0。该值暂不建议修改。
net.ipv4.tcp_rmem
此文件中保存有三个值,分别是
Min:
为TCP socket预留用于接收缓冲的内存最小值。每个tcp socket都可以在建立后使用它。即使在内存出现紧张情况下tcp socket都至少会有这么多数量的内存用于接收缓冲Default:
为TCP socket预留用于接收缓冲的内存数量,默认情况下该值会影响其它协议使用的net.core.rmem_default 值,一般要低于net.core.rmem_default的值。该值决定了在net.ipv4.tcp_adv_win_scale、net.ipv4.tcp_app_win和tcp_app_win=0默认值情况下,TCP窗口大小为65535。Max:
用于TCP socket接收缓冲的内存最大值。该值不会影响net.core.rmem_max,静态"选择参数SO_SNDBUF则不受该值影响。
根据硬件自动生成值为:4096 87380 6291456。按需修改。
net.ipv4.tcp_sack
表示是否启用有选择的应答(Selective Acknowledgment),这可以通过有选择地应答乱序接收到的报文来提高性能(这样可以让发送者只发送丢失的报文段);
默认值为:1。也可以考虑关闭。
net.ipv4.tcp_slow_start_after_idle
如果设置满足RFC2861定义的行为,在从新开始计算拥塞窗口前延迟一些时间,这延迟的时间长度由当前rto决定。
0:关闭
1:开启
默认值为:1。
net.ipv4.tcp_stdurg
使用 TCP urg pointer 字段中的主机请求解释功能。大部份的主机都使用老旧的BSD解释,因此如果您在 Linux 打开它,或会导致不能和它们正确沟通。
0:关闭
1:打开
默认值为:0。
net.ipv4.tcp_syn_retries
表示本机向外发起TCP SYN连接超时重传的次数,不应该高于255;该值仅仅针对外出的连接,对于进来的连接由tcp_retries1控制。
默认值为:6。建议设置为1。
net.ipv4.tcp_synack_retries
对于远端的连接请求SYN,内核会发送SYN + ACK数据报,以确认收到上一个 SYN连接请求包。这是所谓的三次握手。该参数决定内核在放弃连接之前所送出的 SYN+ACK 数目。
默认值为:5。建议设置为1。
net.ipv4.tcp_syncookies
表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击。
0:关闭
1:打开
默认为:1。
net.ipv4.tcp_timestamps
如果服务器前端需要部署LVS等负载均衡,建议关闭该值。
0:不启用
1:启用
默认值为:1。建议设置为0。
net.ipv4.tcp_tso_win_divisor
控制根据拥塞窗口的百分比,是否来发送相应的延迟tso frame。
0:关闭
>0:值越大表示tso frame延迟发送可能越小.
默认值为:3。
net.ipv4.tcp_tw_recycle
打开快速 TIME-WAIT sockets 回收。对客户端和服务器同时起作用。
0:关闭
1:开启
默认值为:0。建议不要轻易打开此选项。
net.ipv4.tcp_tw_reuse
表示是否允许重新应用处于TIME-WAIT状态的socket用于新的TCP连接。只对客户端启用作用。
0:关闭
1:开启
默认值为:0。建议设置为1。
net.ipv4.tcp_window_scaling
表示设置tcp/ip会话的滑动窗口大小是否可变。
0:不可变
1:可变
默认值为:1。
net.ipv4.tcp_wmem
此文件中保存有三个值,分别是
Min:
为TCP socket预留用于发送缓冲的内存最小值。每个tcp socket都可以在建立后使用它。Default:
为TCP socket预留用于发送缓冲的内存数量,默认情况下该值会影响其它协议使用的net.core.wmem_default 值,一般要低于net.core.wmem_default的值。Max:
用于TCP socket发送缓冲的内存最大值。该值不会影响net.core.wmem_max,"静态"选择参数SO_SNDBUF则不受该值影响。根据硬件自动生成值为:4096 16384 4194304。按需修改。
net.ipv4.tcp_workaround_signed_windows
0:假定远程连接端正常发送了窗口收缩选项,即使对端没有发送
1:假定远程连接端有错误,没有发送相关的窗口缩放选项
默认值为:0。
net.ipv4.udp_mem
该文件保存了三个值,分别是
* low:
当UDP使用了低于该值的内存页面数时,UDP不会考虑释放内存。
presure:当UDP使用了超过该值的内存页面数量时,UDP试图稳定其内存使用,进入pressure模式,当内存消耗低于low值时则退出pressure状态。
high:
允许所有UDP sockets用于排队缓冲数据报的页面量。
根据硬件自动生成值为:47109 62813 94218
.
6、net.netfilter
.
net.netfilter.nf_conntrack_buckets
只读,描述当前系统的ip_conntrack的hash table大小。
net.netfilter.nf_conntrack_count
只读,内存中ip_conntrack结构的数量
net.netfilter.nf_conntrack_generic_timeout
通用或未知协议的conntrack被设置的超时时间(每次看到包都会用这值重新更新定时器),一旦时间到conntrack将被回收.(秒)
默认值为:600。
net.netfilter.nf_conntrack_icmp_timeout
icmp协议的conntrack被设置的超时时间,一旦到时conntrack将被回收.(秒)
默认值为:30。
net.netfilter.nf_conntrack_max
内存中最多ip_conntrack结构的数量。
默认值为:65536。 64G的64位操作系统,哈希最佳范围是 262144 ~ 1048576。
net.netfilter.nf_conntrack_tcp_be_liberal
当开启只有不在tcp窗口内的rst包被标志为无效,当关闭(默认)所有不在tcp窗口中的包都被标志为无效。
be_liberal不为1时,tcp_packet要求数据包必须in_window。
默认值为:0。建议设置为1。
net.netfilter.nf_conntrack_tcp_loose
当想追踪一条已经连接的tcp会话, 在系统可以假设sync和window追逐已经开始后要求每个方向必须通过的包的数量. 如果为0,从不追踪一条已经连接的tcp会话。
loose参数不为1的情况下,tcp_new要求新到来的第一个包必然要有SYN标志,否则不予创建conntrack,数据包将成为游离数据包,NAT等都将失去作用,即便是中间的数据包。
默认值为:1。
net.netfilter.nf_conntrack_max_retrans
没有从目的端接收到一个ack而进行包重传的次数,一旦达到这限制nf_conntrack_tcp_timeout_max_retrans将作为ip_conntrack的超时限制。
默认值为:3。
net.netfilter.nf_conntrack_tcp_timeout_close
TCP处于close状态超时时间(秒)
默认值为10。
net.netfilter.nf_conntrack_tcp_timeout_close_wait
TCP处于close wait状态超时时间(秒)
默认值为60。有时需要考虑修改此值。
net.netfilter.nf_conntrack_tcp_timeout_established
TCP处于established状态超时时间(秒)
默认值为:432000。根据业务特性修改此值,比如7200,3600,180等。
net.netfilter.nf_conntrack_tcp_timeout_fin_wait
TCP处于fin wait状态超时时间(秒)
默认值为:120。
net.netfilter.nf_conntrack_tcp_timeout_last_ack
TCP处于last ack状态超时时间(秒)
默认值为:30。
net.netfilter.nf_conntrack_tcp_timeout_max_retrans
TCP处于max retrans状态超时时间(秒)
默认值为:300。
net.netfilter.nf_conntrack_tcp_timeout_syn_recv
TCP处于syn recv状态超时时间(秒)
默认值为:60。
net.netfilter.nf_conntrack_tcp_timeout_syn_sent
TCP处于syn sent状态超时时间(秒)
默认值为:120。
net.netfilter.nf_conntrack_tcp_timeout_time_wait
TCP处于time wait状态超时时间(秒)
默认值为:120。
net.netfilter.nf_conntrack_tcp_timeout_unacknowledged
TCP处于unacknowledged状态超时时间(秒)
默认值为:300。
net.netfilter.nf_conntrack_udp_timeout
udp协议的conntrack被设置的超时时间(每次看到包都会用这值重新更新定时器),一旦到时conntrack将被回收.(秒)
默认值为:30。
net.netfilter.nf_conntrack_udp_timeout_stream
当看到一些特殊的udp传输时(传输在双向)设置的ip_conntrack超时时间(每次看到包都会用这值重新更新定时器).(秒)
默认值为:180。
net.nf_conntrack_max
内存中最多ip_conntrack结构的数量,功能与net.netfilter.nf_conntrack_max一样,修改时两处都得改。(也有说是改一处,两处都修改了)
默认值为:65536。 64G的64位操作系统,哈希最佳范围是 262144 ~ 1048576。
net.unix.max_dgram_qlen
允许域套接字中数据包的最大个数,在初始化unix域套接字时的默认值。在调用listen函数时第二个参数会复盖这个值。
默认值为:512。
7、vm
.
vm.admin_reserve_kbytes
给有cap_sys_admin权限的用户保留的内存数量(默认值是 min(free_page * 0.03, 8MB))。这些内存是为了给管理员登录和杀死进程恢复系统提供足够的内存。
默认值:8192
vm.block_dump
如果设置的是非零值,则会启用块I/O调试。
默认值为:0。
vm.dirty_background_bytes
当脏页所占的内存数量超过dirty_background_bytes时,内核的flusher线程开始回写脏页。
注意:
dirty_background_bytes参数和dirty_background_ratio参数是相对的,只能指定其中一个。当其中一个参数文件被写入时,会立即开始计算脏页限制,并且会将另一个参数的值清零。
默认值为:0。
vm.dirty_background_ratio
当脏页所占的百分比(相对于所有可用内存,即空闲内存页+可回收内存页)达到dirty_background_ratio时,内核的flusher线程开始回写脏页数据。所有可用内存不等于总的系统内存。
默认值为:10。可以适当调小为5。
vm.dirty_bytes
当脏页所占的内存数量达到dirty_bytes时,执行磁盘写操作的进程自己开始回写脏数据。
注意: dirty_bytes参数和 dirty_ratio参数是相对的,只能指定其中一个。当其中一个参数文件被写入时,会立即开始计算脏页限制,并且会将另一个参数的值清零。
默认为:0。
vm.dirty_expire_centisecs
脏数据的过期时间,超过该时间后内核的flusher线程被唤醒时会将脏数据回写到磁盘上,单位是百分之一秒。
默认值为:3000。
vm.dirty_ratio
当脏页所占的百分比(相对于所有可用内存,即空闲内存页+可回收内存页)达到dirty_ratio时,执行磁盘写操作的进程会自己开始回写脏数据。所有可用内存不等于总的系统内存。
默认值为:30。可以适当调小为20。
vm.dirty_writeback_centisecs
设置flusher内核线程唤醒的间隔,此线程用于将脏页回写到磁盘,单位是百分之一秒。如果设置为0,则禁止周期性地唤醒回写线程。
默认值为:500。
vm.drop_caches
写入数值可以使内核释放page_cache,dentries和inodes缓存所占内存:
1:只释放page_cache
2:只释放dentries和inodes缓存
3:释放page_cache、dentries和inodes缓存
这个操作不是破坏性操作,脏的对象(比如脏页)不会被释放,因此要首先运行sync命令,然后再先设置该参数。
默认值为:0。一般该参数只适用于手工释放内存使用。
vm.extfrag_threshold
如果出现内存不够用的情况, Linux会为当前系统的内存碎片情况打一个分, 如果超过了extfrag_threshold这个值, kswapd就会触发memory compaction。
这个值设置接近1000, 说明系统在内存碎片的处理倾向于把旧的页换出, 以符合申请的需要; 而设置接近0, 表示系统在内存碎片的处理倾向于做memory compaction。
默认值为:500。
vm.hugetlb_shm_group
指定组ID,拥有该gid的用户可以使用大页创建SysV共享内存段。
尤其需要给比如类似DBA用户权限时使用。
默认值为:0。
vm.max_map_count
定义了一个进程能拥有的最多的内存区域。在调用malloc,直接调用mmap和mprotect和加载共享库时会产生内存映射区域。虽然大多数程序需要的内存映射区域不超过1000个,但是特定的程序,特别是malloc调试器,可能需要很多,例如每次分配都会产生一到两个内存映射区域。
默认值为:65535。建议修改值131072。
vm.memory_failure_early_kill
控制发生某个内核无法处理的内存错误发生的时候,如何去杀掉这个进程。当这些错误页有swap镜像的时候,内核会很好的处理这个错误,不会影响任何应用程序,但是如果没有的话,内核会把进程杀掉,避免内存错误的扩大
0:只对这部分页进行unmap,然后把第一个试图进入这个页的进程杀掉
1:在发现内存错误的时候,就会把所有拥有此内存页的进程都杀掉
默认值为:0。
vm.memory_failure_recovery
启用内存错误恢复(如果平台支持的话)
0:当发生内存错误时panic
1:尝试恢复
默认值为:1。
vm.min_free_kbytes
每个内存区保留的内存大小(以KB计算)
默认值为:45056。
vm.min_slab_ratio
只在numa架构上使用,如果一个内存域中可以回收的slab页面所占的百分比(应该是相对于当前内存域的所有页面)超过min_slab_ratio,在回收区的slabs会被回收。这样可以确保即使在很少执行全局回收的NUMA系统中,slab的增长也是可控的。
默认值为:5。
vm.min_unmapped_ratio
该参数只在NUMA内核中有效,它是一个相对于每个内存域所有页面的百分比。只有在当前内存域中处于zone_reclaim_mode允许回收状态的内存页所占的百分比超过min_unmapped_ratio时,内存域才会执行回收操作。
如果zone_reclaim_mode的值是4,这个百分比(应该是百分比对应的页面数量)和所有基于文件的未映射页数比较,包括swapcache页和tmpfs文件。否则,只考虑基于普通文件的未映射页,不包括tmpfs文件。
默认值为:1。
vm.mmap_min_addr
指定用户进程通过mmap可使用的最小虚拟内存地址,以避免其在低地址空间产生映射导致安全问题;如果非0,则不允许mmap到NULL页,而此功能可在出现NULL指针时调试Kernel;mmap用于将文件映射至内存;
该设置意味着禁止用户进程访问low 4k地址空间
默认值为:4096。
vm.nr_hugepages
大页的最小数目,需要连续的物理内存;oracle使用大页可以降低TLB的开销,节约内存和CPU资源,但要同时设置memlock且保证其大于大页;其与11gAMM不兼容
默认值为:0。
vm.nr_hugepages_mempolicy
与nr_hugepages类似,但只用于numa架构,配合numactl调整每个node的大页数量。
默认值为:0。
vm.nr_hugepages_mempolicy
保留于紧急使用的大页数,系统可分配最大大页数= nr_hugepages + nr_overcommit_hugepages
默认值为:0。
vm.oom_dump_tasks
如果启用,在内核执行OOM-killing时会打印系统内进程的信息(不包括内核线程),信息包括pid、uid、tgid、vm size、rss、nr_ptes,swapents,oom_score_adj和进程名称。这些信息可以帮助找出为什么OOM killer被执行,找到导致OOM的进程,以及了解为什么进程会被选中。
0:不打印系统内进程信息
1:打印系统内进程信息
默认值为:1。
vm.oom_kill_allocating_task
决定在oom的时候,oom killer杀哪些进程
0:它只杀掉导致oom的那个进程,避免了进程队列的扫描,但是释放的内存大小有限
非0:它会扫描进程队列,然后将可能导致内存溢出的进程杀掉,也就是占用内存最大的进程
默认值为:0。
vm.overcommit_kbytes
内存可过量分配的数量(单位为KB)
默认值为0
vm.overcommit_memory
是否允许内存的过量分配,允许进程分配比它实际使用的更多的内存。
0:当用户申请内存的时候,内核会去检查是否有这么大的内存空间,当超过地址空间会被拒绝
1:内核始终认为,有足够大的内存空间,直到它用完了位置
2:内核会使用一个决不过量使用内存的算法,即系统整个内存地址空间不能超过swap+50%的RAM值,50%参数设定是在overcommit_ratio中设定。
Memory allocation limit = swapspace + physmem * (overcommit_ratio / 100)
默认值为:0。
vm.overcommit_ratio
当overcommit_memory=2的时候,它一般是代表的是系统中总的内存的百分比。
默认值为:50。
vm.page-cluster
参数控制一次写入或读出swap分区的页面数量。它是一个对数值,如果设置为0,表示1页;如果设置为1,表示2页;如果设置为2,则表示4页。
内核一次读取page的数量等于2的page-cluster值的次方即2^page-cluster。当设的值超过2的5次方即2^5,它不会被swap所检测到。因为swap的数据page最大为2的5次方即32-page。
默认值为:3,即8页。
vm.panic_on_oom
控制内核在OOM时是否panic。
如果设置为0,内核会杀死内存占用过多的进程。通常杀死内存占用最多的进程,系统就会恢复。
如果设置为1,在发生OOM时,内核会panic。然而,如果一个进程通过内存策略或进程绑定限制了可以使用的节点,并且这些节点的内存已经耗尽,oom-killer可能会杀死一个进程来释放内存。在这种情况下,内核不会panic,因为其他节点的内存可能还有空闲,这意味着整个系统的内存状况还没有处于崩溃状态。
如果设置为2,在发生OOM时总是会强制panic,即使在上面讨论的情况下也一样。即使在memory cgroup限制下发生的OOM,整个系统也会panic。
默认值是:0。将该参数设置为1或2,通常用于集群的故障切换。选择何种方式,取决于你的故障切换策略。
vm.stat_interval
VM信息更新频率(以秒为单位)
默认值为:1。
vm.swappiness
该参数控制是否使用swap分区,以及使用的比例。设置的值越大,内核会越倾向于使用swap。如果设置为0,内核只有在看空闲的和基于文件的内存页数量小于内存域的高水位线(应该指的是watermark[high])时才开始swap。
默认值为:30。建议保持30
vm.vfs_cache_pressure
控制内核回收用于dentry和inode cache内存的倾向。
内核会根据pagecache和swapcache的回收情况,让dentry和inode cache的内存占用量保持在一个相对公平的百分比上。
减小vfs_cache_pressure会让内核更倾向于保留dentry和inode cache。当vfs_cache_pressure等于0,在内存紧张时,内核也不会回收dentry和inode cache,这容易导致OOM(out of memory)。
如果vfs_cache_pressure的值超过100,内核会更倾向于回收dentry和inode cache。
默认值为:100。
vm.zone_reclaim_mode
参数只有在启用CONFIG_NUMA选项时才有效,zone_reclaim_mode用来控制在内存域OOM时,如何来回收内存。
0:禁止内存域回收,从其他zone分配内存
1:启用内存域回收
2:通过回写脏页回收内存
4:通过swap回收内存
默认值是:0。
