@Mr-13
2021-02-27T03:58:30.000000Z
字数 3131
阅读 123
工作手机:客户电话量分析
数据分析
统计说明
账号范围: 平台所有企业(包含测试账号);
时间跨度: 2019-09-26 ~ 2021-02-21
数据取样: 全量
分钟数处理方式: 平台统计单位为:秒;为数据直观展示,换算单位为:分钟;分钟数向上取整;不足1分钟的按照1分钟计算
数据维度: X轴:电话总数,含呼入/呼出;Y轴:通话总时长,含呼入/呼出
用户活跃度设置
1、设定活跃值计算规则
这是重点:
每天电话达到多少算活跃?通话时长到多少算活跃?
活跃度计算规则又是什么,还是说简单的按照:高活跃、中高活跃、中度活跃、低活跃、0活跃来划分?
2、根基活跃值计算规则计算每个账号“每天”的活跃度情况
a、集中颗粒度(每天)是否需要维度聚合?
b、可以按照每天、每周、每月做集合计算?每季度/年聚合跨度太大,对于日常运营不是很大,而且可以叠加计算
c、不能简单的根据每天的活跃度情况来设置账号的“活跃状态标签”;对于一个账号是否是活跃态的,需要一个短周期的常态/非常态、高频/非高频的使用程度综合计算;
当然还会有一些非自然标签,比如各项功能的使用频率都很低,但是连续登陆;
或者非连续登陆,但是每次登陆会覆盖较多功能点使用
d、基于上一点,可以设定账号活跃状态标签分类:高活用户、重度活跃用户、低活用户、休眠用户;
3、长周期(X轴时间维度)观察活跃值变化
a、单账号结合活跃值,做折线图,展示生命周期内功能使用频率以及年度
b、多账号在某一天做散点图,分析整体用户活跃质量
散点图结合“时间维度”做动态图表,展示产品周期内用户活跃变化;可选定某账号/企业观察趋势
数据分析目的
通过数据自身规律呈现,匹配预定义的用户电话量活跃度阶段,分析平台用户电话功能业务粘度
数据分析思路:(废话区域)
我们相分析某个功能的用户使用粘度,这里面有个前置背景:我们产品功能的定位是:对工作刚需场景的提效工具;所以我们现在分析的场景,是不是每位同事日常办公的必须工作内容?
如果是,我们需要分析的工作内容,是否是可量化的(每天干多少活,能算;不光能算还能分优劣),并且有明确的量化标准?
符合这两个要求的话,我们需要做的就是,对平台数据全量取样,卡评判标准就可以了;对于打电话这个动作来说,在销售工作中是必须动作,并且也有量化标准,那指标是什么、标准又是什么?列举一下:
- 通话量:总量、呼入、呼出(根据工作性质不同、呼出、呼出谁多谁少不一定)
- 通话时长:总时长、呼入时长
- 有效通话:通话时长>= x秒的电话
有效通话个数
大致上是这些,当然还可以根据通话达成结果、是否触达有效联系人等等再细分电话标签,目前平台没有功能支撑,暂时还没发做这些数据分析;“有效通话”也根据不同的企业判定标准有所差异,这个我们可以根据初筛数据样本结果再决定是否需要针对分析。
那一班企业的日常数据量化及格值,基本上就代表了企业数据的平均值,所以我们的期望模型区间也就建立好了。只要看数据呈现结果与期望值区间的偏差情况就可以整体反应用户粘度了。
好了数据指标有了,怎么分析呢?(这里写了一大段常用的图表类型,用作什么需求下的分析展示,又删了.....恩,没错,就是又删了;太特么多了,不想在这里废话)
我们需要呈现的是当前平台所有用户的整体使用粘度,这里需要先查一下数据样本数量,再决定数据分析方式和呈现(15W份);直接一点,以大规模散点(二维,正好匹配电话量、通话时长)看一下每天/没用户的电话数据情况,根据数据聚集密度的直观呈现、对比我们的期望模型区域就可以达到我们的目的。
废话中的废话:
当然可以结合生命周期,做动态散点迁移图,直观的看到用户在使用工作手机后,利用率、激活量等等其他的分析,但都是后话了,先完成整体数据的基础分析。废话完结
一、用户整体通话量/通话时长数据分析:
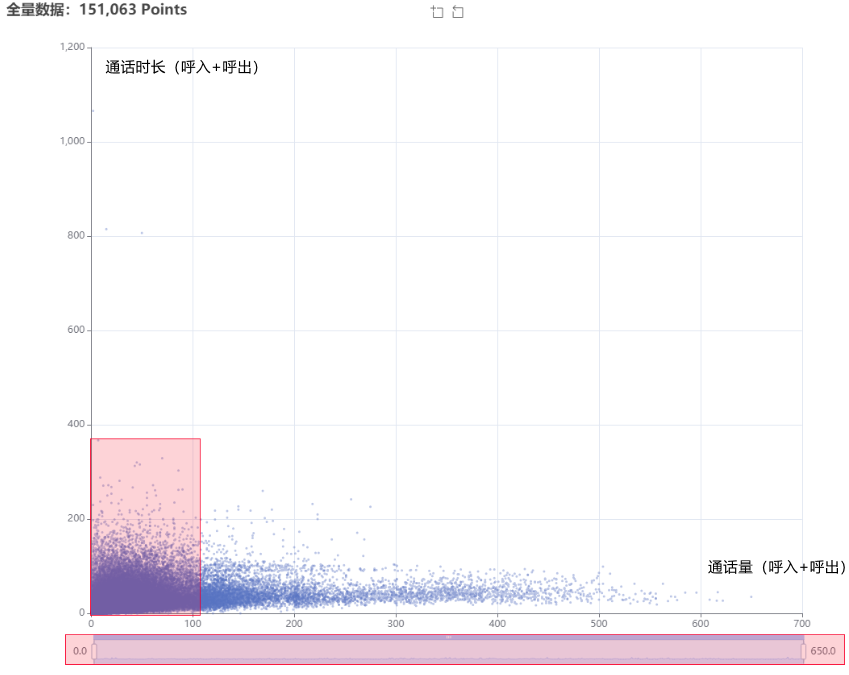
说明:上图红框区域为Echart脏矩形算法自动标注;呈现散点集中分布区域
1、图表简析:(仅通过观察图表分析,不计算数据)
- 散点高密度区域介于(0,0)、(200,200)之间;
X轴:<200的散点密集度较高无法直观反馈离散度,需要取样二次分析;
y轴:<200的散点密集区域较为明显,在二次取样时预计可得出较为直观的离散度呈现;
- 存在大偏差数据样本,需要去除离散度较高的干扰项:
x:分割区间:0~100,100~200,200~300,300~500,>500(该区域先呈现,参考价值不大)
y: 分割区间:0~200,>200(该区域先呈现,参考脚趾不大)
最终二次取样分析区域:(如下图)
a、 [(0~100),(101~200),(201~300),(301~500),(>500)],(0~200)
b、 y>200 的散点暂时只统计数量,不做二次取样分析
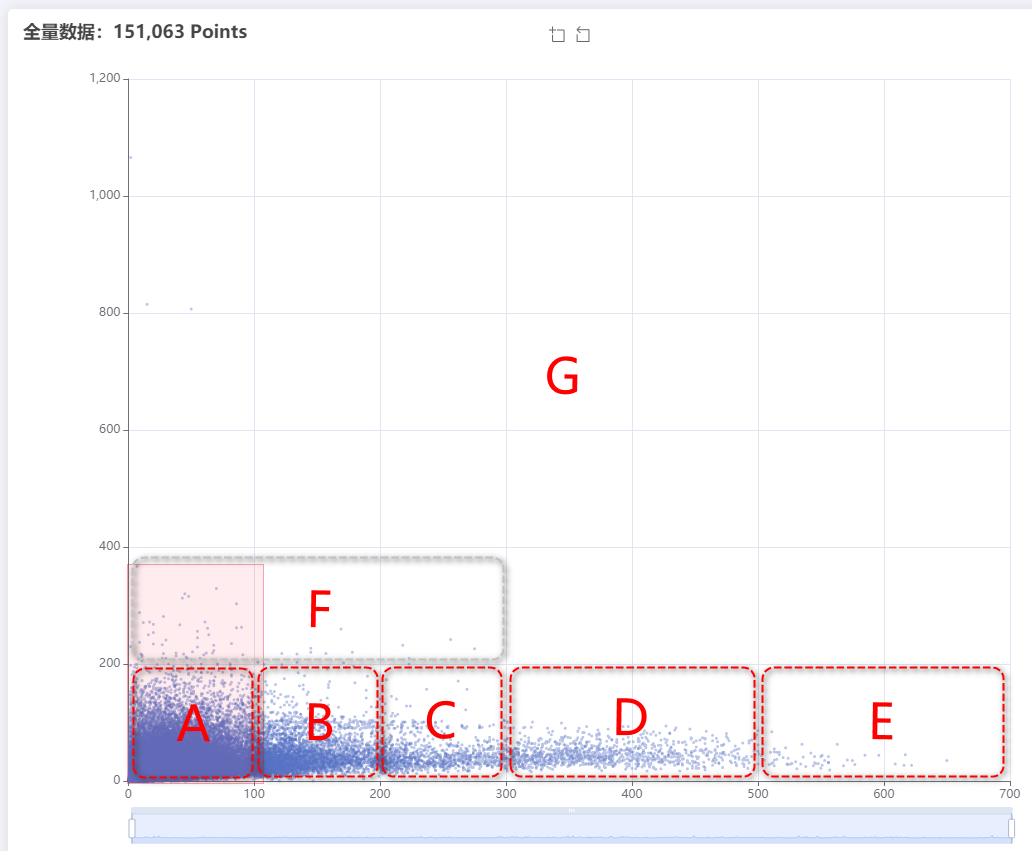
2、取样区域散点数量统计
通过计算数据,先准确描述各区数据占比
样本总数:151,063
A区数量:143,287(94.85%)
B区数量:5,363(3.55%)
C区数量:1,187(0.79%)
D区数量:1,100(0.73%)
E区数量:58(0.04%)
F区数量:65(0.04%)
G区数量:3(≈0.00%)
以上可以看到,B~G区的数据量、以及占比都非常少(整理重点:不能说占比少就不要了,要看数据量本身的大小;具体事具体分析),所以这几个区的数据我们暂时不做二次取样分析。
对A~D区域的数据做二次分析,如下图:
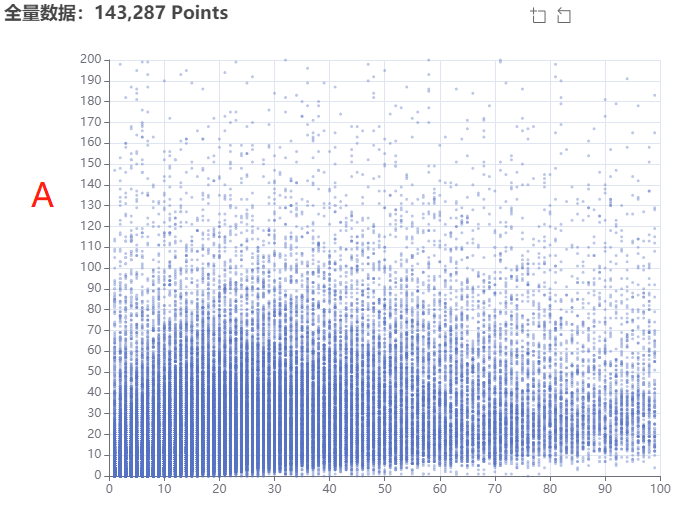
上图的散点密度非常大,我们很难直观的得出明确的“聚合区域”结论,那么下一步,我们以10为步长分割一下A区的坐标系,使用热力图来展示一下数据处理结果:
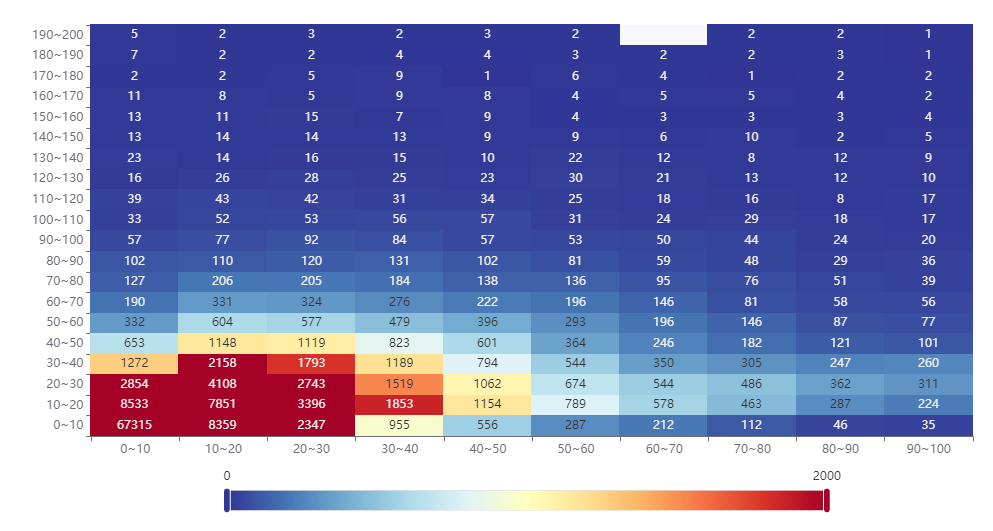
tips:热力图数据通过mysql存储过程完成聚合处理
结果确实是有点不理想,因为数据处理已经过程化,数据处理已经比较方便了;那么对A~C区的数据整体做一下热力图处理,如下图:(存储过程处理耗时:110s)
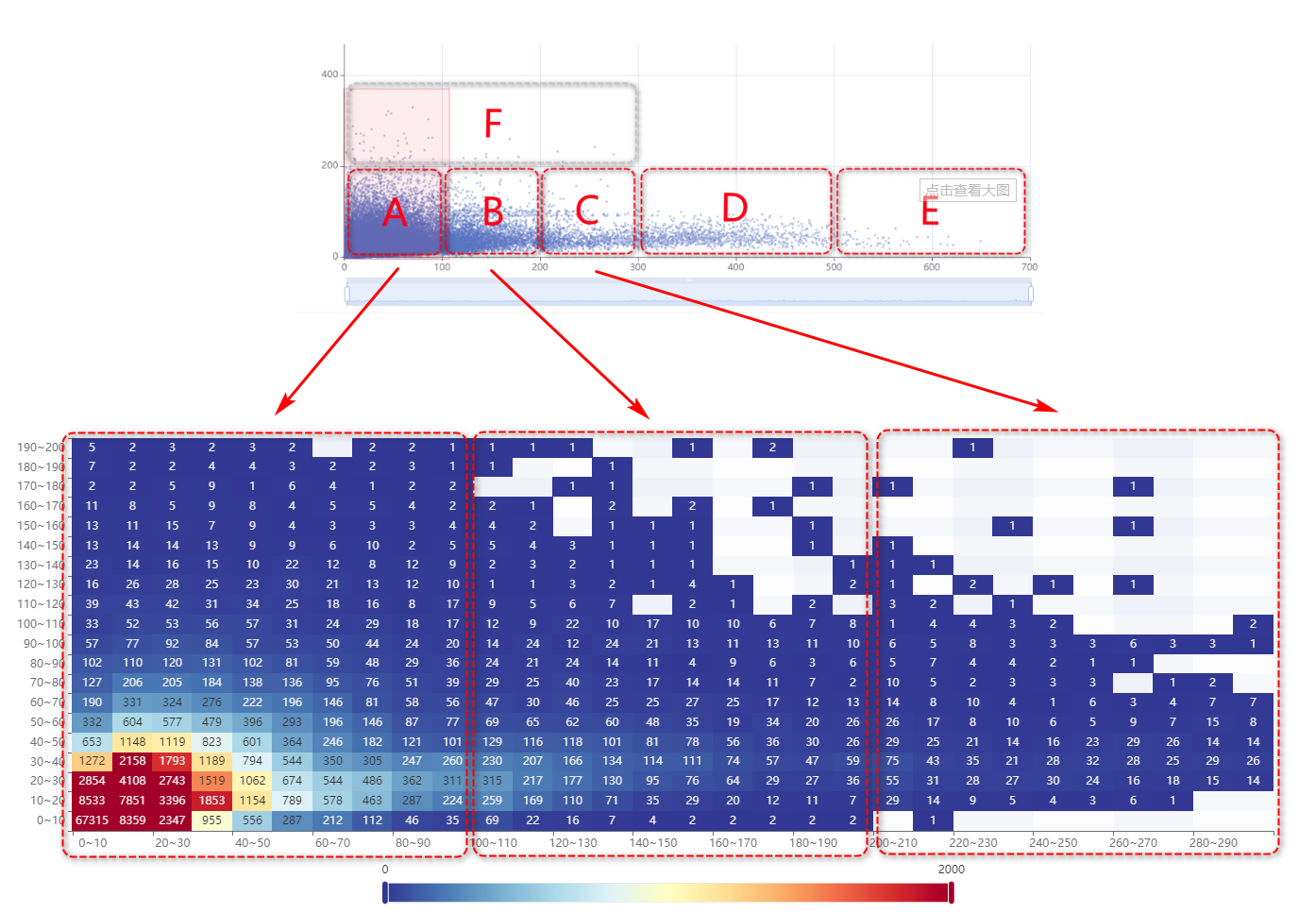
上图呈现的,每日量化散点呈现已经非常明显了;一般电话销售型的公司,每位同事每天大概可以外呼150~200通(保守值);即便每通电话都算短时通话(20秒以内),接通率按照30%计算,那么每日的通话时长也不低于20分钟;少量通话单通时长较长,单日通话按照>=30分钟是较为合理的。
Tips:
仅以电销型公司模型分析,不同行业的数据模型差异较大;
在用户覆盖行业、及用户基础规模化之后,需要根据用户行业、销售模式定向分析;结合人工的售后服务,增加用户标签;建立不同行业的数据模型。
如下图,是我们希望的理想模型数据区域,可以直观的看到,散点聚集密集区域偏差还是非常大的;用户的日常电话业务对工作手机的粘度还是相对比较低的。
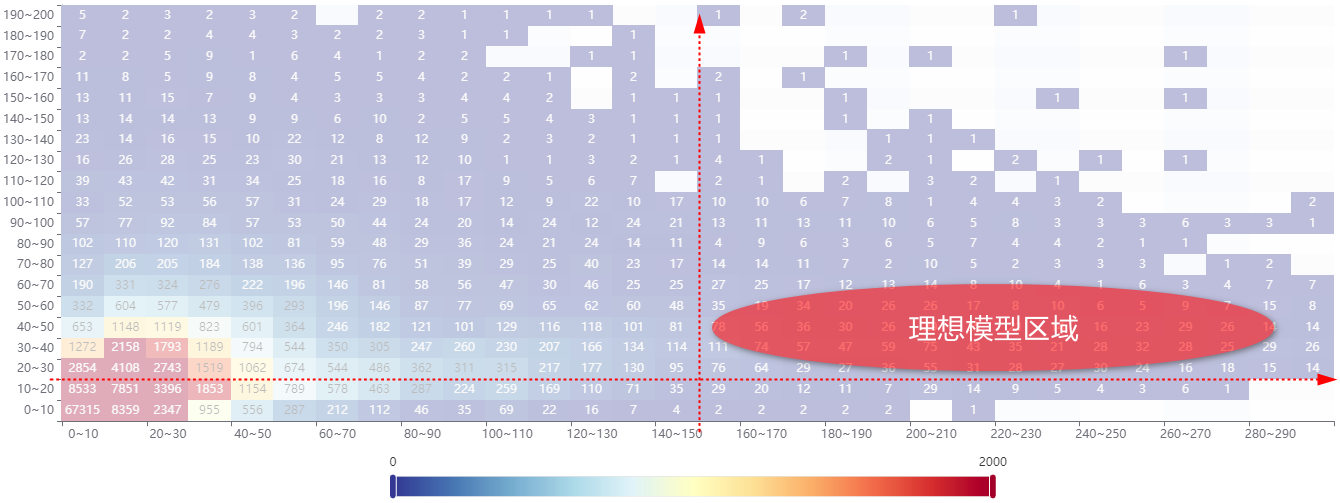
Tips:
当前的数据分析还存在少量数据偏差,并没有对节假日、周末的业务数据分离单独分析;
但从当前比较“粗犷”的数据本机来看,现有数据分离法定节假日及周末后,二次分析的价值不大;
因为我们的理想模型区域主要在B区后半部分及C区;这两部分的样本呈现量非常的少,已经足够说明问题。
二、微信数据分析
微信数据因为从来都没有相关的数据量化指标概念,也并没有可以参考的量化标准;那就直接用数据说话吧,先看一下数据表现再说。
做之前,小分析一下;微信只要在手机端登陆了,那么所有的微信数据都为呗抓取,不存部分迁移的问题,所以很难体现出来“粘度”。如果真的是对产品不感冒,不愿意用,结果会很直接:不用,退出微信,不登陆。
1、什么样的数据是有效的数据样本?
指标:好友数量、群数量、微信号注册时间、每个微信号当天登录状态维持时间(>6小时)、有没有双开微信(简单罗列,二次分析的时候根据指标细分)
