@evilking
2018-01-10T13:13:23.000000Z
字数 6009
阅读 10883
NLP
基于情感词典的情感分析
情感分析主要是判别文本的情感倾向,即属于正面、负面、中性。利用机器提取人们对某人或事物的态度,从而发现潜在的问题用于改进或预测。
目前主要的情感分析方法是基于情感词典的,以及基于监督或半监督学习的。基于情感词典的方法都好说,本篇接下来会详细讲;基于监督或半监督学习的方法主要是基于神经网络、深度学习的一些方法将文档转换成向量后,利用SVM、贝叶斯分类器等分类器再去分类,从而判断文档的情感倾向。
情感词典
基于情感词典的情感分析主要是利用事先准备好的情感词库,给每个词以相应的情感倾向度的权值,然后从文本中提取出所有的情感词并根据句子特点(反问句,疑问句等)计算最后的情感得分和,根据情感得分判断文本的情感极性。
这种方法的首要任务是如何去构建情感词典,如何判断一个词语是褒义词或贬义词,目前的研究有两种思路:
一种是基于语义计算,一般可根据《知网》情感词计算语义相似度,计算目标词语跟基准词之间的紧密程度,得以判定情感极性;
另一种是基于统计分析,计算目标词语基准词之间的点互信息值,确定两个词之间的紧密程度,从而获取目标词的情感倾向。
基于语义计算
基于语义计算的情感词构建,核心是如何构建基础情感词,然后由目标词与这些基础情感词做语义相似度计算。
这类基础情感词必须要人工标记,我们一般选下列几种前人整理好的情感词典:
《知网(HowNet)》
它是一个以汉语和英语的词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库。
知网发布了“情感分析用词语集(beta版)”,其中中文情感分析用词语集常用的有 4 个文件,分别为“正面情感词语”、“负面情感词语”、“正面评价词语”、“负面评价词语”。台湾大学 NTUSD
NTUSD 的英文全称是 National Taiwan University Sentiment Dictionary,它是由台 湾大学整理并发布的情感词典,分为繁体中文和简体中文两个版本。两个版本都包 括有 2810 个正面情感词语和 8276 负面情感词语。其它情感词典
其它情感词典包括张伟、刘缙等编著的《学生褒贬义词典》、史继林、朱英贵 编著《褒义词词典》以及杨玲、朱英贵编著的《贬义词词典》。
对于微博评论等网络风格比较浓烈的文本情感分析来说,还有一些新生词,比如“稀饭(喜欢)”、“JJWW(唧唧歪歪)”等,就需要人工整理后加入到对应的情感词典表中了。
我们在构建自己的情感词典时,可以综合这几种不同的情感词典,但考虑到受主观判断的影响,可能存在同一情感词在不同情感词典中的情感极性不同,我们可以对情感极性采用如下所示的规则进行投票决定:
其中, 为投票结果; 为情感词在不同情感词典中的极性( 表示正向, 表示负向)。
当情感词同时出现在三部源词典中,有两个词典极性相同,则取两个词典的极性;当情感词只出现在其中两部源词 典中,可能出现结果为 others,此时根据权威性,设定 优先权 来选择极性。 保留原始极性的目的在于对比生成情感词典与源词 典的情感词极性。
构建好上述的基础情感词典后,我们可以对语料库进行中文分词处理,然后扫描每个单词,与情感词典中的词进行 HowNet 语义相似度计算,当相似度达到一定阈值时即可判断该词的情感倾向和权值。
其中 HowNet 语义相似度的计算部分我们在前面的相似度计算一篇中有详细介绍,读者可以参考阅读。
基于统计分析
基于统计分析的情感词典构造也是需要事先准备一套情感极性明显的基础情感词典,然后由目标词与该基础情感词典中的单词计算点间互信息,一般我们使用 SO-PMI算法,然后由点间互信息值来判断该目标词的情感极性和情感倾向度。
基础情感词典的构造与上小节类似,我们下面直接讲 SO-PMI算法。
互信息是非常重要的信息度量,在实际应用中应用最广泛的通常是点间互信息(PMI),主要用于计算词语间的语义相似度,基本思想是统计两个词语在文本同时出现的概率,如果概率越大,其相关性就越紧密,关联度越高。
两个词语 和 的 值计算公式如下:
其中 表示两个词语 与 共同出现的概率, 与 分别表示两个词语单独出现的概率。
若两个词在数据集的某个小范围内共现概率越大,表明其关联度越大;反之,越小。 与 的比值是 与 两个词语的统计独立性度量。通过对其取对数,将其值转换为 3 种状态:
在文本中,两个词语的共线概率以及单个词语出现的概率都可以通过对预料集的统计得到:
其中, 为预料集中文档总数; 表示单词 在多少篇文档中出现; 表示 和 同时在多少篇文档中出现。
上式 公式给出了两个词语的相关性计算,可以得到两个词语的相似度度量,因此可以将 方法引入计算词语的情感倾向(Semantic Orientation, 简称 SO)中,从而达到捕获情感词的目的。
基于点间互信息 算法的基本思想是:首先分别选用一组褒义词跟一组贬义词作为基准词,假设分别用 与 来表示这两组词语; 这些情感词必须是倾向性非常明显的,而且极具代表性的词语;若把一个单词 跟 的点间互信息之和减去 跟 的点间互信息之和会得到一个差值,就可以根据该差值判断词语 的情感倾向。公式如下:
通常情况下,将 0 作为 算法的阈值,由此可得到三种状态:
考虑到网络用语词典可能存在中性词的情况,对上式假如一下条件场, 为阈值:
当满足上面三个条件中的一个,则词汇归入中性词集,即 .
在《中文文本情感词典构建方法》中,上面的 是通过搜索引擎查 两个单词在多少个页面中共同出现来算。
考虑到中文用词的灵活性,遣词造句的差异性很大,严格按 算法来统计,会带来数据稀疏问题。所以我们可以考虑把基准情感词的同义词加入 计算,这样基准词 在所有语料数据集中的概率 就扩展为基准词 及其同义词在语料数据集中的概率 ; 也因此成为 与 及其同义词共现的概率。
通过扩展后的 算法能够有效避免数据稀疏问题。
情感倾向分析
首先对文本进行分词,然后通过查事先准备好的情感词典表,以提取所有的情感词,并读取情感词对应的情感极性和权值。
这种是比较明显的,但句子存在情感转移或情感极性反转等情况,比如“我不喜欢你”,“喜欢”是褒义词,但前面加个“不”否定一下,则整个句子就成了负面。
否定词分析
否定词是副词的一种,它是表示否定意义的词语,在文本中具有独特的语法意 义和影响。根据中文成句习惯,单重否定往往会改变情感极性,而双重否定表示肯定。
所以我们可以对句子范围内检测情感词前面出现否定词的个数,如果为奇数就将情感词的极性反转,具体表现在情感词权值乘以 ;如果为偶数就可保持情感词的权值不变,或者适当提高,因为双重否定表示肯定,比直接肯定的语气更重。
常见的否定词有:不、没、无、非、莫、弗、毋、勿、未、否、别、無 、休 不曾、未必、没有、不要、难以、未曾。
程度副词分析
程度副词也是副词的一种,副词一般用于修饰或限制动词与形容词,表示范围、 程度等。 “程度”是指某个量处于相应层次序列中的某个层级上,是量的层级表现。
比如句子“这个小姐姐非常好看”,其中 “好看” 是褒义词,“非常”在前面修饰,加强了这种褒义程度。由此可知,程度副词的加入使用户在的情感倾向 强弱程度上发生了变化,仍需做相应处理。
又如“太好看”和“特别好看”,“太”和“特别”这两个程度词表现的程度是不一样的,所以有人提出把程度副词划分为四个等级,即极量、高量、中量和低量,分别对应不同的权重。
同否定词的处理方式一样,句子中检测情感词前面是否存在程度副词,如果存在,则将情感词的权值乘以程度副词的权重。
其中需要事先准备好程度副词表,一般从《知网》的“中文程度级别词语”整理。
感叹句分析
感叹句是以抒发感情为主的句子,它所抒发的感情有赞美、愉悦、愤慨、叹息、 惊讶、哀伤等,句末通常都用感叹号来标识。通常感叹句是依附于它所在情感句的情 感极性,可以是对正面情感或者负面情感的程度加深。
我们可以将感叹句中的情感词的权值加倍,或者乘以某一权重来加深这种情感;感叹句通过感叹号(“!”)来识别。
反问句分析
反问句的目的往往是加强语气,把原本的思想表达更加强烈、鲜明。它通常比陈述句 表达更为有力,感情色彩也更加明显。
比如“难道我对你不够好么?”,“好”是褒义,“不够好”就变成了贬义,而反问“难道 ... ?”又将句子转换成了褒义,而且语气更强烈。
反问句的存在可以通过反问标志来判断,可从语料中挑选出大量反问句并对反问标记词进行抽取,获得部分反问句标记词。类似感叹号, 反问句在句尾有疑问号“?”的出现,这给反问句的判断 提供了帮助。
同感叹句的处理一样,先根据“?”来判断句子是否为疑问句,然后对疑问句检测反问标志词,判断是否为反问句。如果为反问句,就将句中情感词的权值直接乘以 ,以表示情感反转并加强。
常用的反问标记词有:为什么、凭什么、难道、何必、怎能、怎么能、怎么会 怎会、哪能、能不、能没、不都、不也、不就、谁叫 谁让、就算、这算、还算、就不、还不、莫非 等等。
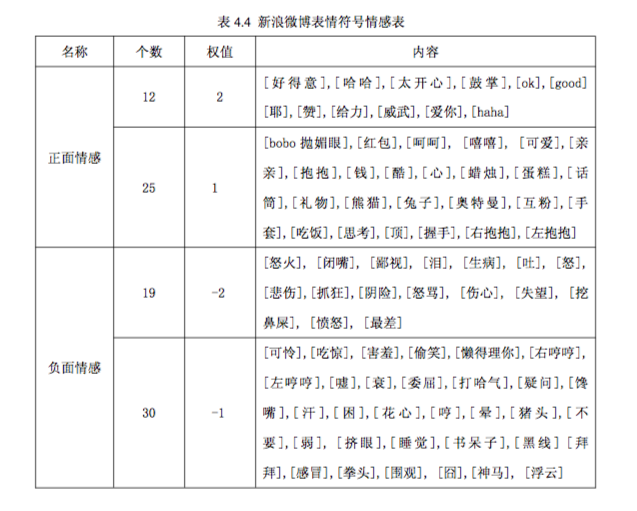
表情符号分析
对于网络文本,比如微博或者论坛等,平台都提供了丰富多彩的表情符号供用户选择。由于有些表情符号暗含了感情色彩,人们常用合适的表情来直接表达某种心情。
比如“今天掉了100块钱[\大哭]”,其中整个句子汉字部分都是称述事实,不含情感色彩,但最后的表情符号“[\大哭]”就含有悲伤的情感。
同基准情感词的处理一样,我们事先 人工挑选 暗含情感色彩的表情符号构成正负面表情符号表,并根据表达的情感程度不同而为不同的表情符号设置不同的权重;对句子进行分析时,之间提取句子中的情感表情符号及其对应的权重即可。
如下是论文《基于情感词典的中文微博情感倾向分析》中给出的表情符号示例:
情感倾向度加权计算
情感倾向度是为了计算文本表达正面情感的程度或者负面情感的程度,一般我们把每条句子的情感值进行累加,得到整个文本的情感值;而句子的情感值根据上面的分析逻辑来算。
根据标点符号将文本分割成 个句子: ,提取每个句子中的情感词 ,如果出现程度副词 修饰情感词 或者该句子是包含情感词的感叹句时,该情感词的情感倾向权重计算为:
式中, 表示程度副词,或者感叹号“!”的权值, 是句子中情感词 的权值。
当出现否定词 修饰情感词 时,为了实现其情感极性取反,则情感词的情感倾向权值公式为:
式中, 表示否定词的权值, 是句子中情感词 的权值。
假设句子 中包含 个情感词,即为 ,故该条句子的情感倾向度为:
故含有 条句子的文本 最终的情感倾向度为:
根据上式得到的最终情感倾向值 ,将会出现下列三种情况:
故根据最终的情感倾向值 所处的不同情况,判断该文本是属于正面、负面、或者中性的。
小结
笔者查阅过多种资料,基本上基于情感词典的情感分析方法都如上面所述,大同小异,所以其他的不做过多讲解
这种方法依赖于情感词典的完善程度,需要大量的情感词典做多模式匹配,所以高效的匹配算法对工程实现来说是有价值的,可参考笔者之前写的《双数组字典树》一篇。
参考
- 《基于情感词典的中文微博情感倾向分析研究》
- 《中文文本情感词典构建方法》
- 《sentiment analysis and opinion mining》
- 《面向文本情感分析的中文情感词典构建方法》
- https://www.cnblogs.com/arkenstone/p/6064196.html
- https://www.jianshu.com/p/0ce646c16032
