@evilking
2018-04-30T16:30:31.000000Z
字数 4423
阅读 3696
NLP
SimHash
本篇介绍一个文本去重算法,叫SimHash,包括算法原理及java源码分析;最后再简要介绍一下其他相关去重方法.
SimHash原理
简介
simhash 是 google 用来处理海量文本去重的算法。simhash最牛逼的一点就是将一个文档,最后转换成一个64位的字节,暂且称之为特征字,然后判断重复只需要判断他们的特征字的距离是不是 < n(根据经验这个n一般取值为3),就可以判断两个文档是否相似。
simhash 本质上是一种LSH,它是局部敏感的;所谓局部敏感是指非常相似的文本,即便只差一个字符,MD5 后的序列也可能非常不同,但是simhash之后的序列可能只是某几位不同;这样对于不同的文本来说,可能就几个字不同,使用simhash就能判断文本是否相似,而传统 MD5或者 hashcode就不行了。
算法描述
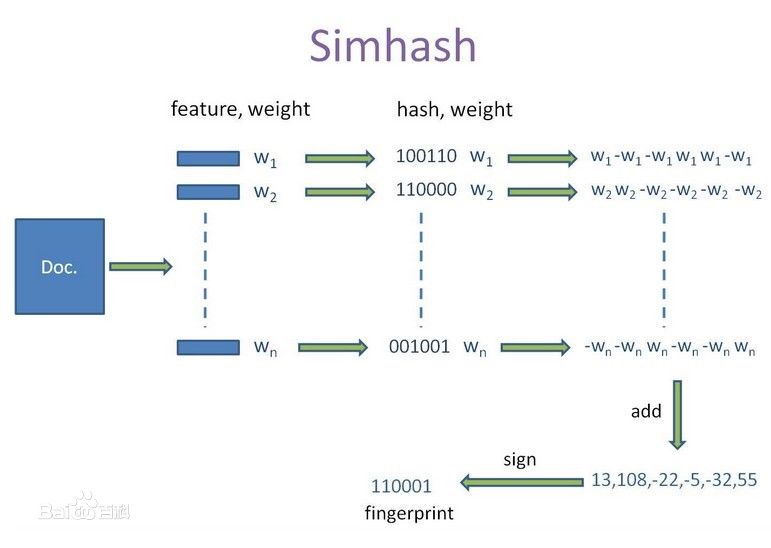
这里直接给出算法过程的 5 步描述 : 分词,hash,加权,合并,转换.
分词
分词是把需要去重的两个文本先通过分词工具分词,然后去掉噪音词,并给每个词加上权重(此数字越大代表这个词对文本越重要,一般可以设置为词频,或者TF-IDF也行).
例如:"美国"51区"雇员称内部有9架飞碟,曾看见灰色外星人",分词之后为 "美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)",括号里的数字表示权重.
hash
此过程是把上一步分词后的每个单词,通过hash算法转换成 hash值,这里指定hashcode的长度,用来控制hash散列的精度.
比如"美国"通过hash算法计算为"100101","51区"通过hash算法计算为"101011";这样我们的字符串就变成了一串串固定长度的数字,提高了相似度的计算性能.
加权
通过上两步的操作结果,需要按照单词的对应位加权,形成加权数字串.
比如 "美国"的hash值为"100101",通过加权计算为"4 -4 -4 4 -4 4";"51区"的hash值为"101011",通过加权计算为"5 -5 5 -5 5 5";
合并
把上步各个单词算出来的序列值按对应位进行累加,合并成一个序列串.
比如"美国"的"4 -4 -4 4 -4 4","51区"的"5 -5 5 -5 5 5",把每一对应位进行累加,"4+5 -4+-5 -4+5 4+-5 -4+5 4+5"计算为"9 -9 1 -1 1 9";
这里作为示例只算了两个单词的,实际情况下要算所有单词的序列串累加
转换
把上步算出来的序列值"9 -9 1 -1 1 9"转换成 0 1 串,形成我们最终的simhash签名;其中每一位大于0 就记为 1,小于 0 记为 0;
比如上述例子中,"9 -9 1 -1 1 9"就转换为了"1 0 1 0 1 1"
文档去重
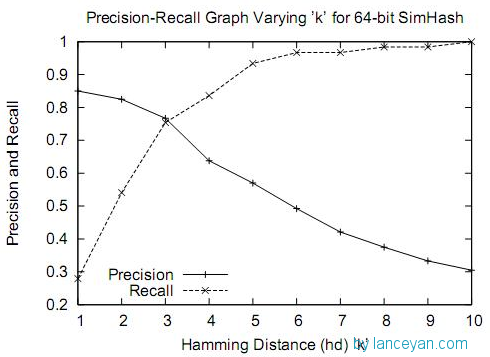
为了计算两篇文档是否相似,先通过上述步骤分别计算出各自的 simhash 签名,然后比较两个 simhash 的汉明距离 ( Hamming Distance ),如果 hamming_distance < k,就认为这两篇文档相似,那这个 k 设置为多少比较合理呢?
在距离为 3 时是一个比较折中的点,在距离为 10 时效果已经很差了,不过我们测试短文本很多看起来相似的距离确实为 10;如果使用距离为 3,短文本大量重复信息不会被过滤,如果使用距离为 10,长文本的错误率也非常高。如何选择,需要根据业务来进行调试。
汉明距离是计算两个等长字符串对应位不同的数量.
比如"101011"与"100101"的汉明距离为 3
java 代码分析
代码准备
这里使用github上的一个开源代码来讲解simhash去重的实现原理 : https://github.com/sing1ee/simhash-java
导入eclipse后,java工程目录如下:
编写测试用例 TestMain类,代码如下:
public static void main(String[] args) {String test1 = "aaaaaaaaaaaaaaaaaaaa";String test2 = "aaaaaaaaaajfljaslfjaslddsjflasdjaaaaaz";//初始化Simhash工具//这里主要是为了初始化其中的分词工具Simhash simHash = new Simhash(new BinaryWordSeg());//计算 64位的simhashlong docHash = simHash.simhash64(test1);long docHash2 = simHash.simhash64(test2);//计算两 simhash的汉明距离int dist = simHash.hammingDistance(docHash, docHash2);System.out.println(dist);}
运行结果如下:
2
源码分析
Simhash构造方法中传入对象,这就是一个分词工具的类,读者可以换成任何其他的分词工具.
public Simhash(IWordSeg wordSeg) {this.wordSeg = wordSeg;}
由于64位的simhash与32位的simhash只是在生成hashcode指纹的时候使用的位数不一样而已,所以这里笔者只以 simhash64来分析:
public long simhash64(String doc) {//指定使用64位的hashcodeint bitLen = 64;int[] bits = new int[bitLen];//分词List<String> tokens = wordSeg.tokens(doc);for (String t : tokens) {//对每个词计算 hashcodelong v = MurmurHash.hash64(t);//这里是为了将整型数按位拆分成 0 1 串//并以词频为权重,按位累加for (int i = bitLen; i >= 1; --i) {if (((v >> (bitLen - i)) & 1) == 1)++bits[i - 1];else--bits[i - 1];}}long hash = 0x0000000000000000;long one = 0x0000000000000001;for (int i = bitLen; i >= 1; --i) {//每位大于0 的就设置为 1if (bits[i - 1] > 1) {hash |= one;}//one = one << 1;}return hash;}
这段源码过程基本与上面讲述的 simhash算法过程一致,读者可以根据自己项目情况做修改.
simhash签名计算完后,如果要计算两篇文档是否相似,就需要计算两simhash字符串的汉明距离;
笔者最开始的实现没有使用位运算,处理性能就不是太好,看了这里用位运算处理的源码,处理性能提升很明显.
海量数据优化方案
随着业务的增长,每天都有大量的数据产生,如果一天100w,10天就是1000w了,插入一条数据就要去比较1000w次,显然这个计算量是巨大的。
针对海量数据的去重优化,我们可以将 64 位指纹,切分成 4 份 16 位的数据块,根据抽屉原理在汉明距离为 3 的情况下,如果两个文档相似,那么它必有一块的数据时相等的,如图:
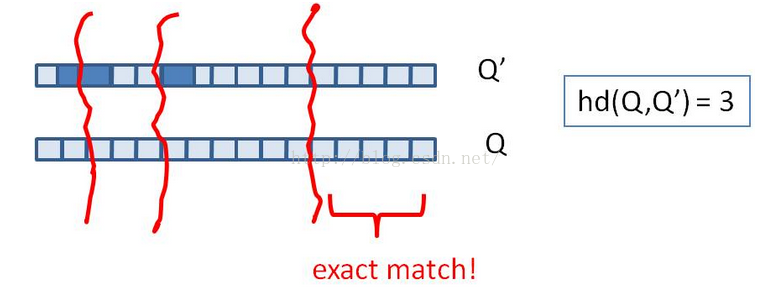
然后将 4 份数据通过 k-v 数据库或倒排索引存储起来,k 为 16 位截断指纹,v 为 k 相等时剩余的 48 位指纹集合,查询的时候,精确匹配这个指纹的 4 个 16位截断,如图所示 :
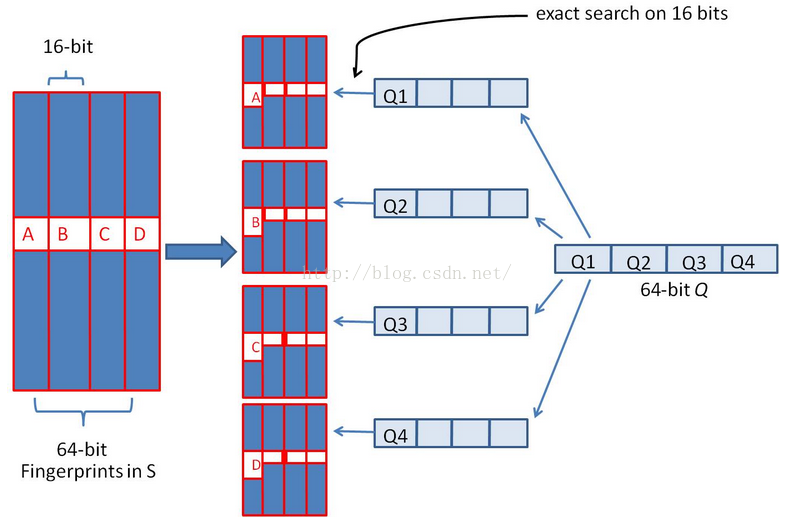
如此,假设样本库有 条数据(约171亿数据),假设数据均匀分布,则每个 16 位(16 个 0 1 数字随机组成的组合为 个 )倒排返回的最大数量为 个候选结果,4 个 16 位截断索引,总的结果为 : ,约为 100多万,通过这样的降维处理,原来需要比较 171亿次,现在只需要比较 100万次即可,大大提升了计算效率.
这种是使用了倒排索引的方式进行了优化
笔者在想是否可以使用图数据库索引的方式来加快速度,simhash分隔的每一小块就是图数据库中的一个实体
相关的去重方案
百度的去重
百度的去重算法最简单,就是直接找出此文章的最长的n句话,做一遍hash签名。n一般取3。 工程实现巨简单,据说准确率和召回率都能到达80%以上。
Shingle算法
简单描述一下:先对两个文本进行分词,两个分词集合的交集除以两个集合的并集,得到Jaccard系数,通过判断Jaccard系数是否大于某个数,来判断两个集合是否重复。

Shingle算法也可作为句子相似度的计算方法
若想了解更多Shingle算法细节,请自行搜索.
Rabin指纹去重
假设 包含了 个二进制符号串,并且 ,那么构造一个 阶的多项式 为:
具体可参考《Rabin指纹去重算法在搜索引擎中的应用》这篇论文.
R 中使用 simhash
# 创建 worker启动器,计算simhash,取前两个关键词> simhasher = worker("simhash",topn = 2)> simhasher <= "你妈妈叫你回家吃饭啊"$simhash[1] "5255740375710833686"$keyword6.55531 6.44422"妈妈" "吃饭"> simhasher <= "你妈妈喊你回家吃饭,回家喽"$simhash[1] "9184284471008831268"$keyword12.3845 6.55531"回家" "妈妈"># 计算hamming distance> distance("你妈妈喊你回家吃饭","你妈妈叫你回家吃饭啊",simhasher)$distance[1] 0$lhs6.55531 6.44422"妈妈" "吃饭"$rhs6.55531 6.44422"妈妈" "吃饭">
例子中两句话相差两个字,但是hamming distance计算出来的值为 0,说明两句话极为相似,事实上也确实如此.
[4]: http://img.blog.csdn.net/20151013190318299?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQv/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center
