@evilking
2018-05-01T10:08:48.000000Z
字数 16191
阅读 4938
机器学习篇
牛顿法与拟牛顿法
笔者在整理 CRF 算法的时候,对最后一步学习过程没大看懂,于是专门找时间调研了下拟牛顿法。
本篇基本上转载至 : http://blog.csdn.net/itplus/article/details/21896453
因为这是笔者看过的将拟牛顿法讲的最清楚的一篇。
最后笔者再结合 java 代码去分析 LBFSG 算法的实现过程。
考虑如下无约束的极小化问题:
本文不讨论收敛性问题,因此不妨对目标函数 作一个较苛刻的假设,我们假设 为凸函数,且两阶连续可微。令极小问题的解为
梯度下降法
梯度下降法又被称为最速下降法(Steepest descend method),其理论基础是梯度的概念。
梯度与方向导数的关系:梯度的方向与取得最大方向导数值的方向一致,而梯度的模就是函数在该点的方向导数的最大值。
对于一个无约束的优化问题:
梯度下降的更新公式为:
例如:
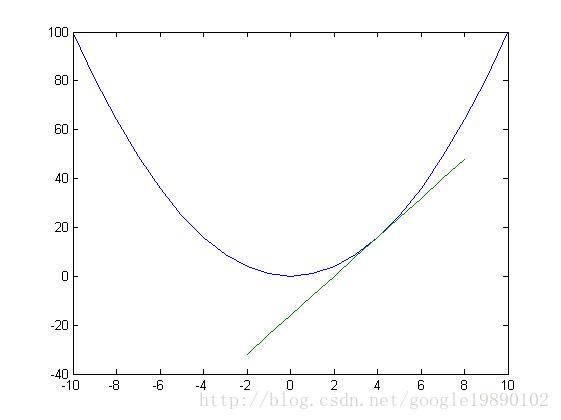
如图,在 处的切线。显然在 处函数取得最小值。沿着梯度的方向是下降速度最快的方向。
具体的过程为:初始时,任取 的值,如取 ,则对应的 。利用梯度下降法 ,去更新 。不断迭代,算法终止的判断标准是:,其中 是一个指定的阈值。
梯度下降的算法流程为:
- 初始化:随机选取取值范围内的任意数
迭代操作:
计算梯度 ;
修改新的变量 ;
判断是否达到终止: 如果 ,则跳出循环;否则继续;输出终止结果
牛顿法
为了由浅入深的讨论,我们考虑 的简单情形(此时目标函数 变为 ).牛顿法的基本思想是:在现有极小点估计值的附近对 做二阶泰勒展开,进而找到极小点的下一个估计值。
设 为当前的极小点估计值,则:
表示 在 附近的二阶泰勒展开式(其中略去了关于 的高阶无穷小项)。
由于求的是最值,由极值必要条件可知, 应满足:
即:
解得:
于是,若给定初始值 ,则可以构造如下的迭代格式:
对于 的情形,二阶泰勒展开式可以做推广,此时:
其中 为 的梯度向量, 为 的海森矩阵(Hessian matrix),其定义分别为:
注意: 和 中的元素均为关于 的函数,以下分别将其简记为 .
特别的,若 的混合偏导数可交换次序,即对 ,成立 ,则海森矩阵 为对称矩阵.
而 则表示将 取为 后得到的实值向量和矩阵,以下分别将其简记为 (这里字母 g 表示 gradient,H 表示 Hessian)
同样地,由于是求极小点,极值必要条件要求它为 的驻点,即:
对泰勒展开使用梯度算子得:
梯度算子: http://www.docin.com/p-79757964.html
泰勒展开式的第二项应用梯度算子得到的是 的高阶无穷小,所以省略.
进一步,若矩阵 非奇异,则可解得:
于是,若给定初始值 ,则同样可以构造出迭代格式:
这就是原始的牛顿迭代法,其迭代格式中的搜索方向 称为牛顿方向.
矩阵非奇异: https://www.zhihu.com/question/35318893
https://baike.baidu.com/item/%E9%9D%9E%E5%A5%87%E5%BC%82%E7%9F%A9%E9%98%B5/4114613?fr=aladdin
下面给出完整的牛顿法的算法描述:
给定初值 和精度阈值 ,并令
计算
若 ,则停止迭代;否则确定搜索方向 .
计算新的迭代点
令 ,转至第2步.
当目标函数是二次函数时,由于二次泰勒展开函数与原目标函数不是近似而是完全相同的二次式,海森矩阵退化成一个常数矩阵,从任一初始点出发,利用 的迭代式,只需一步迭代即可达到 的极小点 ,因此牛顿法是一种具有二次收敛性的算法。对于非二次函数,若函数的二次性态较强,或迭代点已进入极小点的领域,则其收敛速度也是很快的,这是牛顿法的主要优点.
但原始牛顿法由于迭代公式中没有步长因子,而是定步长迭代,对于非二次目标函数来说,有时会使函数值上升,即出现 的情况,这表明原始牛顿法不能保证函数值稳定地下降.在严重的情况下甚至可能造成迭代点列 的发散而导致计算失败.
为了消除原始牛顿迭代法的弊病,人们提出“阻尼牛顿法”,阻尼牛顿法每次迭代的方向仍采用 ,但每次迭代需沿此方向作一维搜索(line search),寻求最优的步长因子 ,即:
阻尼牛顿法的算法过程,就是将上步原始牛顿法中的迭代公式增加步长,改成
拟牛顿条件
牛顿法虽然收敛速度快(因为不仅考虑了梯度,而且考虑了梯度的加速方向),但是计算过程中需要计算目标函数的二阶偏导数,计算复杂度较大.而且有时目标函数的海森矩阵无法保持正定,从而使得牛顿法失效.为了克服这两个问题,人们提出了拟牛顿法.
基本思想是:不用二阶偏导数,而是构造出可以近似海森矩阵(或海森矩阵的逆)的正定对称矩阵,在“拟牛顿”的条件下优化目标函数.
拟牛顿条件,或者叫做拟牛顿方程、割线条件.
因为对海森矩阵的近似需要理论指导,该近似矩阵需要满足一定的条件.
一致定义如下:用 表示对海森矩阵 本身的近似,而用 表示对海森矩阵的逆 的近似,即 .
设经过 次迭代后得到 ,此时将目标函数
在上式两边同时作用一个梯度算子 ,可得:
当 时有:
若引入记号:
则可整理得:
或者:
这就是所谓的拟牛顿条件,它对迭代过程中的海森矩阵 作约束,因此,对 做近似的 ,以及对 做近似的 可以将 :
作为指导.
下面一节讨论几种具体的拟牛顿算法,即讨论如何去近似海森矩阵或其逆矩阵.
DFP算法
DFP 算法是以 William C.Davidon、Roger Fletcher、Michael J.D.Powell 三个人的名字的首字母命名的,它由 Davidon 于 1959 年首先提出,后经 Fletcher 和 Powell 加以发展和完善,是最早的拟牛顿法.
该算法的核心是:通过迭代的方法,对 做近似。迭代格式为
其中的 通常取为单位矩阵 . 因此,关键是每一步的矫正矩阵 如何构造.
关于 的构造,是真的有点 tricky,使用的是“待定法”,即首先将 待定成某种形式,然后结合拟牛顿条件来进行推导:
其中, 为待定系数, 为待定向量. 从形式上看,这种待定公式至少保证了矩阵 的对称性(因为 均为对称矩阵).
下面一步的构造就特别精彩:
看到了吧,括号中的 是两个数,既然是数,我们不妨作如下简单赋值:
即:
其中向量 仍有待确定.
其中, 都是 的向量,所以 都是一个数.
那么 如何确定呢?将上面的 带入 ,得:
其中第二个等式用到了 的对称性.
至此,我们就将矫正矩阵 构造出来了:
综上,我们给出 DFP 算法的完整描述:
给定初值 和精度阈值 ,并令
确定搜索方向
利用阻尼牛顿法中的 表达式,得到步长 ,令
若 ,则算法结束.
计算
计算
令 ,转至第 2 步.
BFGS
BFGS 算法是以其发明者 Broyden,Fletcher,Goldfarb 和 Shanno 四人的名字首字母命名的。
与 DFP 算法相比,BFGS 算法性能更佳,目前它已成为求解无约束非线性优化问题最常用的方法之一.
BFGS 算法中核心公式的推导过程和 DFP 完全类似,只是 BFGS 是去逼近海森矩阵,而不是像 DFP 去逼近海森矩阵的逆.
即 ,设迭代格式为:
这里的问题同样是如何构造矫正矩阵 ,同样将其待定为:
通过令 ,以及
可算得:
综上,便可得到矫正矩阵 的公式:
最后同样给出完整的 BFGS 算法的描述:
给定初值 和精度阈值 ,并令
确定搜索方向
利用阻尼牛顿法中的 表达式,得到步长 ,令
若 ,则算法结束.
计算
计算
令 ,转至第 2 步.
其中算法的第 2 步,通常是通过求解线性代数方程组 来进行的。然而,更一般的做法是:通过对步 6 中的递推关系应用 Sherman-Morrison公式,直接给出 与 之间的关系式:
这里笔者还没看懂怎么得出来的.
关于 Sherman-Morrison 公式:
设 为非奇异方阵,,若
于是,上述 BFGS 算法的描述可以改写如下. 注意,为了避免出现矩阵求逆符号,统一将 换用成 (这样仅仅是为了看上去舒服).
给定初值 和精度阈值 ,并令
确定搜索方向
利用阻尼牛顿法中的 表达式,得到步长 ,令
若 ,则算法结束.
计算
计算
令 ,转至第 2 步.
对比下 BFGS 和 DFP 算法,唯一不同的仅在于 的迭代公式不同罢了.
LBFGS
在 BFGS 算法中,需要用到一个 的矩阵 ,当 很大时,存储这个矩阵将变得很耗计算机资源.例如考虑 为 10 万 的情形,且用 double 型(8 字节)来存储 ,需要多大的内存呢?我们来计算一下:
74.5 GB,很惊人是吧,这对于一般的服务器是很难承受的。当然,考虑到矩阵 的对称性,内存还可以降一半,但是,在机器学习问题中,像 10 万这样的规模还只能算是中小规模。那么,是否可以通过对 BFGS 算法进行改造,从而减少其迭代过程中所需的内存开销呢?
答案是肯定的,L-BFGS(Limited-memory BFGS 或 Limited-storage BFGS) 算法就是这样一种算法.它对 BFGS 算法进行了近似,其基本思想是:不再存储完整的矩阵 ,而是存储计算过程中的向量序列 ,需要矩阵 时,利用向量序列 的计算来代替.而且,向量序列 也不是所有的都存,而是固定存最新的 个(参数 可由用户根据自己机器的内存自行指定).每次计算 时,只利用最新的 个 . 显然,这样做就将存储由原来的 降到了 .
接下来,讨论 L-BFGS 算法的具体实现过程.我们的出发点是修改如下迭代式:
如果给定初始矩阵 (通常为正定的对角矩阵,如 ),则依次可得:
一般地,我们有:
由上式可见,计算 需用到 ,因此,若从 开始连续地存储 组的话,只能存储到 ,亦即,只能依次计算 直到 . 那么, 该如何计算呢?
自然地,如果一定要丢掉一些向量,那么肯定优先考虑那些最早生成的向量. 具体来说,计算 时,我们保存 ,丢掉了 ;计算 时,我们保存 ,丢掉了
但是舍弃掉一些向量后,就只能 近似计算 了,当 时,可以构造近似计算公式:
这被称为 special BFGS matrices. 若引入 ,则还可以推出:
看到这里,读者千万不要被上面冗长复杂的形式所吓到。事实上,由 BFGS 算法流程易知, 的作用仅用来计算 获取搜索方向,因此,若能利用上述表达式设计出一种计算 的快速算法,则大功告成:
算法:( 的快速算法)
Step 1 初始化:
Step 2 后向循环:
Step 3 前向循环:
最后算出的 即为 的值.
java 版本 L-BFGS 实现源码分析
L-BFGS 源码下载地址:https://github.com/vinhkhuc/lbfgs4j
我们从 test 目录下的com.github.lbfgs4j.LbfgsTest 测试类的 rosenbrock() 方法开始分析。
//创建函数Function f = new Function() {public int getDimension() {}public double valueAt(double[] x) {}public double[] gradientAt(double[] x) {}};boolean verbose = true;// 创建 Lbfgs 优化器LbfgsMinimizer minimizer = new LbfgsMinimizer(verbose);//得到最小值点的坐标double[] x = minimizer.minimize(f);//最小值点的函数值double min = f.valueAt(x);
源码这里使用的是 rosenbrock函数:
类 LbfgsMinimizer 的构造方法主要是设置了 L-BFGS 优化算法的基本参数,暂时先不看。
下面主要分析 LbfgsMinimizer 类的 minimizer.minimize(f) 方法.
public double[] minimize(Function f, double[] x0) {//函数的维度,这里考虑的 (x,y) 两维int dim = f.getDimension();double[] x = x0 != null? x0 : new double[dim];MutableDouble fx = new MutableDouble();// 评估器是为了获取参数函数的函数值和梯度Evaluate eval = new Evaluate(f);Progress progress = verbose? new Progress() : null;// Start the L-BFGS optimization; this will invoke// the callback functions evaluate() and progress() when necessary.Lbfgs.lbfgs(dim, x, fx, eval, progress, null, param);return x;}
接下来重点看 L-BFGS 优化过程了。
public static ReturnValue lbfgs(int n,double[] x,MutableDouble ptr_fx,LBFGS_Evaluate proc_evaluate,LBFGS_Progress proc_progress,Object instance,LBFGS_Param _param){...//构建 LBFGS 优化参数LBFGS_Param param = _param != null? _param : _defparam;int m = param.m;......//线性搜寻器LineSearchProc linesearch = new LineSearchMorethuente();....../* Store the current position and gradient vectors. */veccpy(xp, x, n);veccpy(gp, g, n);/* 寻找最优步. */if (param.orthantwise_c == 0.) {//通过线性搜寻计算梯度 gls = linesearch.eval(n, x, fx, g, d, step, xp, gp, w, cd, param);}............for(;;){//最后一次迭代保存数据的对象it = lm[end];/*** Update vectors s and y:* s_{k+1} = x_{k+1} - x_{k} = \step * d_{k}.* y_{k+1} = g_{k+1} - g_{k}.*/vecdiff(it.s, x, xp, n);vecdiff(it.y, g, gp, n);/*** Compute scalars ys and yy:* ys = y^t \cdot s = 1 / \rho.* yy = y^t \cdot y.* Notice that yy is used for scaling the hessian matrix H_0 (Cholesky factor).*/ys = vecdot(it.y, it.s, n);yy = vecdot(it.y, it.y, n);it.ys = ys;/*** Recursive formula to compute dir = -(H \cdot g).* 正如上面理论部分讲到的过程,这里是初始化步*/bound = (m <= k) ? m : k;++k;end = (end + 1) % m; //这里的 delta 应该与上面理论部分的过程有点出入/* Compute the steepest direction. */if (param.orthantwise_c == 0.) {/* 计算负梯度. */vecncpy(d, g, n);} ......//这是后向循环处代码j = end;for (i = 0;i < bound;++i) {j = (j + m - 1) % m; /* if (--j == -1) j = m-1; */it = lm[j];/* \alpha_{j} = \rho_{j} s^{t}_{j} \cdot q_{k+1}. */it.alpha = vecdot(it.s, d, n);it.alpha /= it.ys;/* q_{i} = q_{i+1} - \alpha_{i} y_{i}. */vecadd(d, it.y, -it.alpha, n);} //这里跟上面理论中的公式一样//这里到 前向循环的初始化步得到 r_0,不过笔者没看明白这里为什么要缩放 ys/yyvecscale(d, ys / yy, n);//前向循环for (i = 0;i < bound;++i) {it = lm[j];/* \beta_{j} = \rho_{j} y^t_{j} \cdot r_{i}. */beta = vecdot(it.y, d, n);beta /= it.ys;/* r_{i+1} = r_{i} + (\alpha_{j} - \beta_{j}) s_{j}. */vecadd(d, it.s, it.alpha - beta, n);j = (j + 1) % m; /* if (++j == m) j = 0; */}......}}
上面列出了核心步以及其注释,代码中省略了很多变量的初始化,以及变量取值范围的检查。
核心 L-BFGS 迭代过程就是如上面 for(;;){} 循环中的代码所示,不过核心的步骤跟上面理论算法过程一致.
