@evilking
2018-05-01T10:05:06.000000Z
字数 15148
阅读 4479
机器学习篇
HMM (Hidden Markov Model) 隐式马尔科夫模型
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析,例如模式识别。
马尔科夫链
在介绍HMM之前,我们先要了解什么是马尔科夫链。
马尔科夫链是一个随机过程,简单来说就是当前时刻的状态与前p个时刻的状态有关,即
为了简化这个过程以方便应用到模型中,我们有两个假设:
在序列中,当前时刻状态只依赖于前一时刻的状态,也就是P(z(t)|z(t-1), z(t-2), ..., z(1), z(0)) = P(z(t)|z(t-1))。
状态转移的分布不随时间的改变而改变,也就是说任意时刻下的状态产生与时间无关,仅仅与前一状态有关。
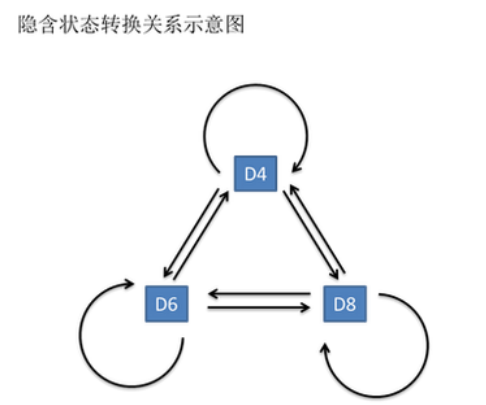
但是实际生活中,这种状态本身是很难观测到的,我们只能根据其他的特征来观测这些状态,同时状态之间的转移矩阵也是很难直接获得的,这就需要隐马尔科夫模型了.
HMM 形象的例子描述
在引入HMM的公式化描述之前,为了更好的理解 HMM模型,我们先用一个掷骰子的例子来形象的描述 HMM模型.
模型描述
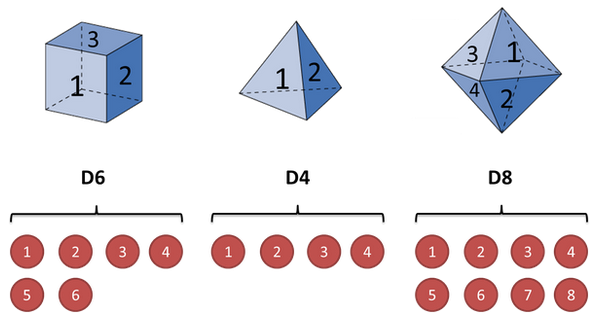
假设我手里有三个不同的骰子。
第一个骰子是我们平常见的骰子(称这个骰子为D6),6个面,每个面(1,2,3,4,5,6)出现的概率是1/6。
第二个骰子是个四面体(称这个骰子为D4),每个面(1,2,3,4)出现的概率是1/4。
第三个骰子有八个面(称这个骰子为D8),每个面(1,2,3,4,5,6,7,8)出现的概率是1/8。
假设我们开始掷骰子,我们先从三个骰子里挑一个,挑到每一个骰子的概率都是1/3。
然后我们掷骰子,得到一个数字,1,2,3,4,5,6,7,8中的一个。
不停的重复上述过程,我们会得到一串数字,每个数字都是1,2,3,4,5,6,7,8中的一个。
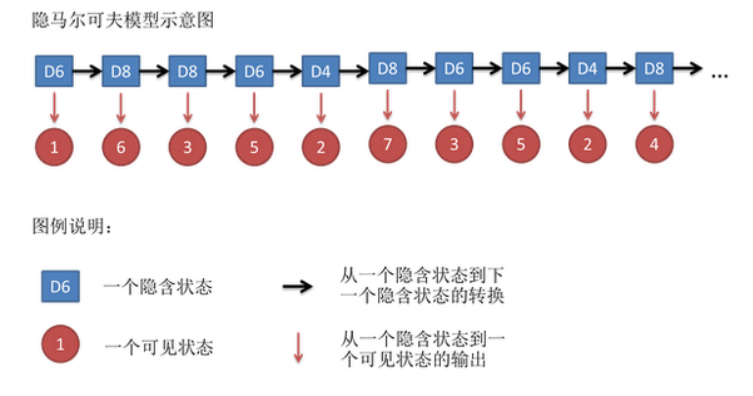
例如我们可能得到这么一串数字(掷骰子10次):1 6 3 5 2 7 3 5 2 4
这串数字叫做可见状态链。但是在隐马尔可夫模型中,我们不仅仅有这么一串可见状态链,还有一串隐含状态链。在这个例子里,这串隐含状态链就是你用的骰子的序列。比如,隐含状态链有可能是:D6 D8 D8 D6 D4 D8 D6 D6 D4 D8
一般来说,HMM中说到的马尔可夫链其实是指隐含状态链,因为隐含状态(骰子)之间存在转换概率(transition probability)。在我们这个例子里,D6的下一个状态是D4,D6,D8的概率都是1/3。D4,D8的下一个状态是D4,D6,D8的转换概率也都一样是1/3。这样设定是为了最开始容易说清楚,但是我们其实是可以随意设定转换概率的。比如,我们可以这样定义,D6后面不能接D4,D6后面是D6的概率是0.9,是D8的概率是0.1。这样就是一个新的HMM。
同样的,尽管可见状态之间没有转换概率,但是隐含状态和可见状态之间有一个概率叫做输出概率(emission probability)。就我们的例子来说,六面骰(D6)产生1的输出概率是1/6。产生2,3,4,5,6的概率也都是1/6。我们同样可以对输出概率进行其他定义。比如,我有一个被赌场动过手脚的六面骰子,掷出来是1的概率更大,是1/2,掷出来是2,3,4,5,6的概率是1/10。
其实对于 HMM 来说,如果提前知道所有隐含状态之间的转换概率和所有隐含状态到所有可见状态之间的输出概率,做模拟是相当容易的。
但是应用HMM模型时候呢,往往是缺失了一部分信息的,有时候你知道骰子有几种,每种骰子是什么,但是不知道掷出来的骰子序列;有时候你只是看到了很多次掷骰子的结果,剩下的什么都不知道。如果应用算法去估计这些缺失的信息,就成了一个很重要的问题。
HMM模型解决的三个问题
知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道每次掷出来的都是哪种骰子(隐含状态链)
这个问题呢,在语音识别领域呢,叫做解码问题。这个问题其实有两种解法,会给出两个不同的答案。每个答案都对,只不过这些答案的意义不一样。
第一种解法求最大似然状态路径,说通俗点呢,就是我求一串骰子序列,这串骰子序列产生观测结果的概率最大。
第二种解法呢,就不是求一组骰子序列了,而是求每次掷出的骰子分别是某种骰子的概率。比如说我看到结果后,我可以求得第一次掷骰子是D4的概率是0.5,D6的概率是0.3,D8的概率是0.2
还是知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道掷出这个结果的概率
看似这个问题意义不大,因为你掷出来的结果很多时候都对应了一个比较大的概率。
问这个问题的目的呢,其实是检测观察到的结果和已知的模型是否吻合。
如果很多次结果都对应了比较小的概率,那么就说明我们已知的模型很有可能是错的,有人偷偷把我们的骰子給换了
知道骰子有几种(隐含状态数量),不知道每种骰子是什么(转换概率),观测到很多次掷骰子的结果(可见状态链),我想反推出每种骰子是什么(转换概率)
这个问题很重要,因为这是最常见的情况。很多时候我们只有可见结果,不知道HMM模型里的参数,我们需要从可见结果估计出这些参数,这是建模的一个必要步骤
在实际应用中,比如中文分词,我们更多的是利用第三个问题去建模 ( 当然,如果利用工具的话,你拿到手的时候这部分的参数都是已经训练好了的 ),然后用第一个问题的解码去求隐含状态序列(这也是我们的目标,比如分词、词性标注等).
破解骰子序列
在这个形象的掷骰子的例子中,我们重点讲一下Viterbi algorithm解码过程.
举例来说,我知道我有三个骰子,六面骰,四面骰,八面骰。我也知道我掷了十次的结果(1 6 3 5 2 7 3 5 2 4),我不知道每次用了那种骰子,我想知道最有可能的骰子序列
其实最简单而暴力的方法就是穷举所有可能的骰子序列,然后依照第零个问题的解法把每个序列对应的概率算出来。然后我们从里面把对应最大概率的序列挑出来就行了。如果马尔可夫链不长,当然可行。如果长的话,穷举的数量太大,就很难完成了。
另外一种很有名的算法叫做 Viterbi algorithm.
要理解这个算法,我们先看几个简单的列子。首先,我们只掷一次骰子:
看到结果为 1.对应的最大概率骰子序列就是 D4,因为 D4 产生 1 的概率是 1/4,高于 1/6 和 1/8.
把这个情况拓展,我们掷两次骰子:
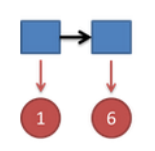
结果为 1,6.这时问题变得复杂起来,我们要计算三个值,分别是第二个骰子是 D6,D4,D8 的最大概率。显然,要取到最大概率,第一个骰子必须为 D4。
这时,第二个骰子取到 D6 的最大概率是:
同样的,我们可以计算第二个骰子是 D4 或 D8 时的最大概率。我们发现,第二个骰子取到 D6 的概率最大。而使这个概率最大时,第一个骰子为 D4。所以最大概率骰子序列就是 D4 D6。
继续拓展,我们掷三次骰子:
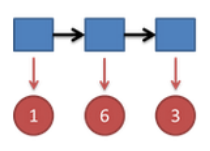
同样,我们计算第三个骰子分别是 D6,D4,D8 的最大概率。我们再次发现,要取到最大概率,第二个骰子必须为 D6。
这时,第三个骰子取到 D4 的最大概率是 :
同上,我们可以计算第三个骰子是 D6 或 D8 时的最大概率。我们发现,第三个骰子取到 D4 的概率最大。而使这个概率最大时,第二个骰子为 D6,第一个骰子为 D4。所以最大概率骰子序列就是 D4 D6 D4。
到这里,大家应该看出点规律了。既然掷骰子一二三次可以算,掷多少次都可以以此类推。我们发现,我们要求最大概率骰子序列时要做这么几件事情。
首先,不管序列多长,要从序列长度为 1 算起,算序列长度为 1 时取到每个骰子的最大概率。
然后,逐渐增加长度,每增加一次长度,重新算一遍在这个长度下最后一个位置取到每个骰子的最大概率。因为上一个长度下的取到每个骰子的最大概率都算过了,重新计算的话其实不难。
当我们算到最后一位时,就知道最后一位是哪个骰子的概率最大了。然后,我们要把对应这个最大概率的序列从后往前推出来。
这也就是动态规划的思想了,Viterbi算法本质上也是一种动态规划
HMM 的几个要素
经过上面形象化的例子描述,读者应该对隐马尔科夫模型有了大致的了解,下面通过引入数学化描述,来正式介绍 HMM.读者在阅读 HMM 数学化描述时,可以对照前面掷骰子的问题来理解.
StatusSet :
状态值集合,常用 来表示系统的隐状态集合,其中 为隐状态数。用 表示系统在时刻 处于隐状态 ,隐状态序列为例如上面的三个不同的骰子,这些状态之间满足马尔科夫性质,是马尔科夫模型中实际所隐含的状态,这些状态通常无法直接观察得到.
ObservedSet :
观察值集合,观测序列记为 ,其中 为观测序列的长度; 为时刻 的观测随机变量,可以是一个数值或向量.例如上面的 1,2,3,4,5,... 等值,在模型中与隐含状态相关联,可通过直接观测得到.
TransProbMatrix :
转移概率矩阵,状态转移的概率分布可表示为 ,其中 ,且满足 ,表示时刻 从状态 状态转移到时刻 状态 的概率.例如上面的取不同骰子的概率,描述了 HMM 模型中各个状态之间的转移概率,
EmitProbMatrix :
发射概率矩阵,假设观测变量的样本空间为 ,在状态 时输出观测变量的概率分布可表示为: ,其中 。例如上面的每个骰子取不同值的概率,令 代表隐含状态数目, 代表可观测状态数目,则 表示在 时刻、隐含状态是 条件下,观察状态为 的概率.
InitStatus :
初始状态分布,一般用 来表示,即 ,其中例如上面我们假设投掷的是第一枚骰子,表示隐含状态在初始时刻 的概率矩阵.
从定义可知,隐马尔科夫模型作了两个基本假设:
齐次马尔科夫假设
即假设隐藏的马尔科夫链在任意时刻 的状态只依赖于其前一时刻的状态,与其他时刻的状态及观测无关,也与时刻 无关.观测独立性假设
即假设任意时刻的观测只依赖于该时刻的马尔科夫链的状态,与其他观测及状态无关.
观测序列的生成过程
上面的例子中我们也大致讲了序列如何生成的,这里我们用数学描述提炼一下:
输入: 隐马尔科夫模型 ,观测序列长度 ;
输出: 观测序列
按照初始状态分布 产生状态
令
按照状态 的观察概率分布 生成
按照状态 的状态转移概率分布 产生状态
令 ;如果 ,转步 3;否则,终止.
HMM 的基本问题
隐马尔科夫模型在实际中运用,必须解决下面三个基本问题 :
给定观察序列 和模型 ,如何有效地计算观测值序列的输出概率 ?
给定观察值序列和输出该观察值序列的隐马尔科夫模型 ,如何有效确定与之对应的最佳状态序列 ?即估计出模型产出观察值序列最有可能经过的路径.
对于初始模型和给定用于训练的观察值序列 ,如何调整模型参数 ,使得输出概率最大 ?
对应到上面掷骰子的例子中所说的三个问题
基本算法
直接计算
给定模型 和观测序列 ,计算观测序列 出现的概率 . 最直接的方法就是按概率公式直接算:通过列举所有可能的长度为 的状态序列 ,求各个状态序列 与观测序列 的联合概率 ,然后对所有可能的状态序列求和,得到 .
状态序列 的概率是
对固定的状态序列 ,观测序列 的概率是
则 同时出现的联合概率为:
然后,对所有可能的状态序列 求和,得到观测序列 的概率 ,即
但是,该式计算量很大,是 阶的,这种算法不可行.
前向-后向算法
解决问题 1 的最常用、最有效的方法就是 Baum 等人提出的前向-后向算法。
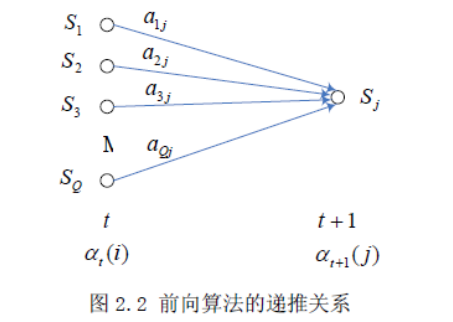
该算法定义 前向概率变量
可由下面递推公式计算得到 :
初始化:
递推:
结束:
其中 是把最后 时刻的所有可能的状态下观察到 的概率求和;因为到最后 时刻时,每一条状态路径都能观察到观测序列 ,且有一个生成概率,即,于是将 时刻所有可能的状态对应的前向概率变量累加,就是将所有可能观察到观测序列的状态序列的概率相加,即
上述前向算法的递推关系如图所示:
与前向算法相似,后向算法是从后向前递推计算输出概率的方法。定义后向概率变量
则 可由下面递推公式计算,后向算法的递推关系图如下所示 :
初始化 :
递推公式 :
结束 :
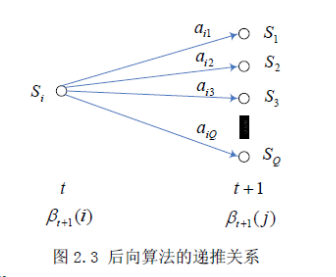
根据前向变量和后向变量的定义,显然下式成立 :
如何来理解该式子?
表示 时刻为状态 的前向概率(根据前向概率的定义,已经计算了 时刻状态为 时观测到 的概率), 时刻状态 转移到 时刻的状态 ,在 时刻状态 下观测到 的概率,最后乘以 时刻状态为 的后向概率(因为按后向概率的定义不包含当前状态的观察概率 的计算);分别求所有可能的 状态 的组合,就是 .
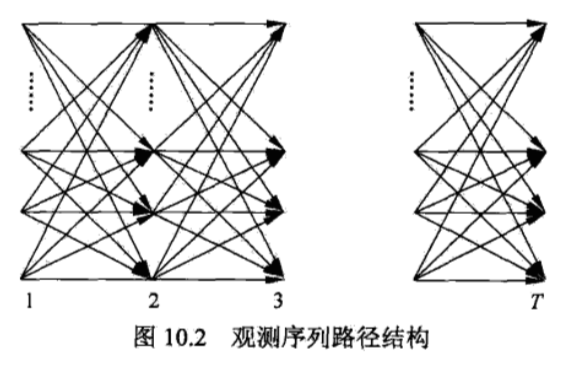
利用该算法减少计算量的原因在于每一次计算直接引用前一个时刻的计算结果,避免重复计算.这样,利用前向概率计算 的计算量是 阶的,而不是直接计算的 阶.
监督学习方法
对于 HMM 参数估计问题,可按训练数据的特点来分是有监督学习还是无监督学习,如果是有监督学习的话,可直接通过对训练样本做一些统计即可得到 HMM 的参数估计;在中文自然语言处理中,许多标注问题就是这么做的.
假设已给训练数据包含 个长度相同的观察序列和对应的状态序列 ,那么我们可以直接利用极大似然估计法来估计隐马尔科夫模型的参数,具体如下:
转移概率 的估计
设样本中时刻 处于状态 ,时刻 时刻由状态 转移到了 ,此种情况出现的频数为 ,那么转移概率 的估计值为即统计由状态 转移到状态 占状态 转移出去的比例.
观测概率 的估计
设样本中状态为 并观测为 的频数是 ,那么状态为 观测为 的概率 的估计是:其中,
Baum-Welch 算法
对于无监督学习的 HMM 参数估计问题,可以使用 Baum-Welch算法.
首先定义两个变量 和 ,给定观察序列 和模型参数 ;
为系统在时刻 系统处在状态 的概率,即
为 时刻状态为 ,到 时刻系统状态转为 的概率,即
根据前向-后向算法中 和 定义有:
则对于观察序列 而言,系统所处于状态 的总次数(期望值)为 ;同样,系统从状态 转移到 的总次数为 .
假设给定训练数据只包含 个长度为 的观测序列 而没有对应的状态序列,目标是学习隐马尔科夫模型 的参数.我们将观测序列数据看作观测数据 ,状态序列数据看作不可观测的隐数据 ,那么隐马尔科夫模型事实上是一个含有隐变量的概率模型
它的参数学习可以用 EM 算法 来实现.
确定完全数据的对数似然函数
所有观测数据写成 ,所有隐数据写成 ,完全数据是 ,完全数据的对数似然函数是EM 算法的 E 步: 求 函数
其中, 是隐马尔科夫模型参数的当前估计值, 是要极大化的隐马尔科夫模型参数.
于是函数 可以写成:式中求和都是对所有训练数据的序列总长度 进行的.这其中的 Q 函数,是直接用的《统计学习方法》中的概念,这本书中的 Q 函数比较难懂,读者可以参考笔者之前写的 EM 算法篇进行理解.
EM 算法的 M 步: 极大化 函数 求模型参数
由于要极大化的参数在 中单独地出现在 3 个项中,所以只需对各项分别极大化.
(1). 第一项可以写成:注意到 满足约束条件 ,利用拉格朗日乘子法,写出拉格朗日函数:对其求偏导数并令结果为零:(2). 第 2 项可以写成:
注意到约束条件 ,应用拉格朗日乘子法得:求其对 的偏导,并令其等于零:对 求和:(3). 第 3 项与第 2 项的计算类似:
同样用拉格朗日乘子法,约束条件是 .注意,只有在 时 对 的偏导数才不为 0,以 表示,求得
则上面的概率公式整理一下,并用 表示为:
于是整理 Baum-Welech 完整算法描述如下:
输入:观测数据
输出:隐马尔科夫模型参数.
初始化
对 ,选取 ,得到模型递推,对
右端各值按观测 和模型 计算.
终止,得到模型参数
Viterbi算法
Viterbi算法是解决问题 2 的常用方法,又称解码。
定义变量 ,则具体步骤如下 :
初始化 :
递推 :
终止 :
逆推得到最佳状态序列 :
式中, 为保存最佳状态序列的函数,即将使 最大的状态 i 存放在 中.
R中使用 HMM
笔者在实际项目中使用的是 java 版本的结巴分词,它是词典+HMM模型的分词工具,源码中对 HMM的Viterbi算法演示的很清楚,不过这里为了与整体风格相统一,我们使用 R语言的相关HMM包来演示;
后面我们单独用一个篇幅去讲解结巴分词,因为结巴分词工具总体上来说算是一个效果不错,而且原理简单的工具.
install.packages("HMM")library(HMM)
安装 HMM包,以及导入 HMM包.
#后向算法求观察值出现的概率hmm = initHMM(c("A","B"),c("L","R"),transProbs = matrix(c(0.8,0.2,0.2,0.8),2),emissionProbs = matrix(c(0.6,0.4,0.4,0.6),2))print(hmm)# 序列观察值observations = c("L","L","R","R")logBackwardProbabilities = backward(hmm,observations)print(exp(logBackwardProbabilities))
# 通过前向算法求观察值出现的概率hmm = initHMM(c("A","B"), c("L","R"), transProbs=matrix(c(.8,.2,.2,.8),2),emissionProbs=matrix(c(.6,.4,.4,.6),2))print(hmm)# Sequence of observationsobservations = c("L","L","R","R")# Calculate forward probablitieslogForwardProbabilities = forward(hmm,observations)print(exp(logForwardProbabilities))
# 通过Baum-Welch算法训练 hmm参数hmm = initHMM(c("A","B"),c("L","R"))transProbs = matrix(c(0.9,0.1,0.1,0.9),2)emissionProbs = matrix(c(0.5,0.51,0.5,0.49),2)print(hmm)a = sample(c(rep("L",100),rep("R",300)))b = sample(c(rep("L",300),rep("R",100)))observation = c(a,b)# Baum-Welchbw = baumWelch(hmm,observation,10)print(bw$hmm)
# 观察序列最可能出现的概率hmm = initHMM(c("A","B"), c("L","R"), transProbs=matrix(c(.8,.2,.2,.8),2),emissionProbs=matrix(c(.6,.4,.4,.6),2))print(hmm)# Sequence of observationsobservations = c("L","L","R","R")# Calculate posterior probablities of the statesposterior = posterior(hmm,observations)print(posterior)
# Viterbi算法解码,求最可能的隐状态序列# Initialise HMMhmm = initHMM(c("A","B"), c("L","R"), transProbs=matrix(c(.6,.4,.4,.6),2),emissionProbs=matrix(c(.6,.4,.4,.6),2))print(hmm)# Sequence of observationsobservations = c("L","L","R","R")# Calculate Viterbi pathviterbi = viterbi(hmm,observations)print(viterbi)
# 训练hmm参数# Initial HMMhmm = initHMM(c("A","B"),c("L","R"),transProbs=matrix(c(.9,.1,.1,.9),2),emissionProbs=matrix(c(.5,.51,.5,.49),2))print(hmm)# Sequence of observationa = sample(c(rep("L",100),rep("R",300)))b = sample(c(rep("L",300),rep("R",100)))observation = c(a,b)# Viterbi-trainingvt = viterbiTraining(hmm,observation,10)print(vt$hmm)
参考
- 《统计学习方法》——李航 的 Baum-Welch 模型的参数估计
