@evilking
2018-04-30T16:40:28.000000Z
字数 17581
阅读 3261
NLP
LDA 主题模型
LDA 是两个常用模型的简称:线性判别分析(Linear Discriminant Analysis)和潜在狄利克雷分布主题模型(Latent Dirichlet Allocation),在之前的篇章中我们已经详细讲解了线性判别分析模型,本篇就详细讲解主题模型。
该模型主要是用来给文档划分主题,可得出每篇文档的主题分布,以及每个主题下的词分布。但要理解该模型需要有一些数学功底,比如 Gamma分布、Beta分布、多项式分布、Dirichlet分布等等。
理论部分网友总结的已经很详细了,特别是 《LDA数学八卦》 、 《LDA漫游指南》 这两篇,强烈推荐读一读,本篇理论部分大多都是摘录至这两篇文档,大致总结一些比较重点的部分供初学者快速学习。
数学基础
LDA主题模型主要是用到了 Dirichelt-Multinomial共轭结构,要理解多项式分布,就先要理解伯努利分布、二项分布,而Dirichelt分布又是Beta分布在多维上的扩展,Beta分布又是二项分布的共轭先验分布。这几个分布都与 Gamma函数有关,所以我们下面一个个介绍这些统计中常用的分布函数。
Gamma函数
所谓的 gamma函数其实就是阶乘的函数形式,比如 ,但要问你 ,如果没有 gamma 函数就无法回答了,欧拉经过不懈的努力,最终给出了更一般的函数形式 gamma 函数:
可以直接算出 ,也可以算出 .
详细计算过程参考《LDA漫游指南》2.1 gamma函数一节.
Gamma函数有个重要的性质:
也因为该性质可得:
该性质可用分部积分法展开求解,不难证明,详细可参看《LDA漫游指南》2.1 gamma函数一节.
二项分布(Binomial distribution)
概率论中,二项分布即为重复 次独立的伯努利试验。比如投掷硬币,正面朝上的概率为 ,反面朝上的概率即为 ,投掷一次,即为一次伯努利试验,投掷 次,即为 次伯努利试验,又叫做概率为 的二项分布。
现假设你投掷了 次硬币,有 次正面朝上,但你不确定具体在哪 次,所以是先从 次中任取 次,即 ,那么投掷 次正面朝上的概率为:
其中,
beta分布(beta distribution)
在概率论中,beta分布是指一组定义在区间 的连续概率分布,有两个参数 和 ,且 .
Beta分布的概率密度函数是:
随机变量 服从参数为 的beta分布通常写为:
这个式子中分母的函数称为 B 函数,在LDA算法 Gibbs Sampling 采样公式中也有用到.
该式的证明参考《LDA漫游指南》2.3 beta分布一节,其中证明2 看的更好理解一些。
多项分布(multinomial distribution)
多项分布式二项分布的推广扩展,在 词独立试验中每次只输出 中结果中的一个,且每种结果都有一个确定的概率 。多项分布给出了在多种输出状态的情况下,关于成功次数的各种组合的概率。
举个例子,投掷 次骰子,骰子共有 6 种结果输出,且 1 点出现概率为 ,2 点出现概率 ,,多项分布给出了在 次试验中,骰子 1 点出现 次,2 点出现 次,3 点出现 次,,6 点出现 次。这个结果组合的概率为:
也可以用 gamma 函数表示:
狄利克雷分布(dirichlet distribution)
dirichlet 分布是beta分布在多项情况下的推广,也是多项分布的共轭先验分布。
dirichlet 分布的概率密度函数如下:
其中,
二项分布和多项分布很相似,Beta分布和Dirichlet分布很相似。
另一个重要的公式是:
共轭先验分布(conjugacy prior)
在贝叶斯概率理论中,如果后验分布和先验分布的概率分布函数相同,则先验分布和后验分布被叫做共轭分布,先验分布被叫做似然函数的共轭先验分布。
而什么叫似然函数呢?举个例子,Beta分布式二项分布的共轭先验,先验分布与后验分布当二项分布的 时才成立,但实际应用中这显然是不可能的,所以我们取 为一个有限的常数去近似,所以此时的“二项分布函数”就是“似然函数”。
具体来说,Beta分布是二项分布的共轭先验分布:
这就是 Beta-Binomial 共轭.
而Dirichlet分布是多项式分布的共轭先验分布:
这就是 Dirichlet-Multinomial 共轭.
关于共轭先验分布的证明和解释,在《LDA数学八卦》中讲的很详细,其中举得掷骰子的例子也很经典,强烈推荐读者去看看
Beta/Dirchlet 分布的一个性质
上面都是直接给出的几个分布函数的概率密度函数,因为本篇主要不是介绍理论,具体的理论细节都在《LDA数学八卦》《LDA漫游指南》中讲了。但在 LDA 模型中,用到的一个非常重要的计算是求 Beta/Dirichlet 分布的期望.
如果 ,则
上式右边的积分对应到概率分布 ,对于这个分布,我们有
把上式带入 中,得:
因为
这说明,对于 Beta 分布的随机变量,其均值可用 来估计。
Dirichlet 分布也有类似的结论,如果 ,同样可以证明:
MCMC和Gibbs Sampling
LDA 模型求解主要有两种方法:变分推断EM算法和 Gibbs 采样算法;由于 Gibbs采样算法效率更高,所以一般LDA的实现都是采样的 Gibbs 采样.
关于蒙特卡罗算法和 Gibbs 采样算法,在 http://www.cnblogs.com/pinard/p/6645766.html 这个系列的博文中讲的非常清楚了,读者可以直接看这篇博文进行学习。
不过这篇博文更多的是用通俗的语言去理解 Gibbs采样,应用于 LDA 模型,理论部分可以参考《LDA漫游指南》中 3.3 节讲推导过程。
LDA
到这里关于 LDA 模型涉及到的数学知识就OK了,下面介绍主题模型.
LDA 是从PLSA模型加入贝叶斯框架演变而来,在PLSA模型中假设文档是这样生成的:文档是由多个主题混合而成,而每个主题由对应的词组成。
- 上帝有两种类型的骰子,一类是 doc-topic 骰子,每个 doc-topic 骰子有 K 个面,每个面是一个 topic 的编号;一类是 topic-word 骰子,每个 topic-word 骰子有 V 个面,每个面对应一个词;
- 上帝一共有 K 个 topic-word 骰子,每个骰子有一个编号,编号从 1 到 K;
- 生成每篇文档之前,上帝都先为这篇文章制造一个特定的 doc-topic 骰子,然后重复如下过程生成文档中的词:
- 骰子这个 doc-topic 骰子,得到一个 topic 编号 z
- 选择 K 个 topic-word 骰子中编号为 z 的那个,骰子这个骰子,于是得到一个词.
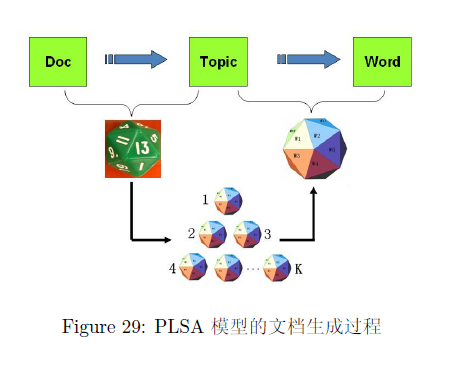
游戏中的 K 个 topic-word 骰子,我们可以记为 ,对于包含 M 篇文档的语料 中的每篇文档 ,都会有一个特定的 doc-topic 骰子 ,所有对应的骰子记为 。为了方便,我们假设每个词 都是一个编号,对应到 topic-word 骰子的面。
于是在PLSA模型中,第 篇文档 中的每个词的生成概率为
所以整篇文档的生成概率为
贝叶斯学派却不这么认为,在这个模型中 doc-topic 骰子 和 topic-word 骰子 对应的概率分布都是模型中的参数,参数都是随机变量,怎么能没有先验分布呢?于是需要对 PLSA 模型加上贝叶斯框架加以改造。
由于 和 都对应到多项式分布,所以先验分布的一个好的选择就是 Dirichlet分布,于是我们就得到了 LDA(Latent Dirichlet Allocation) 模型。
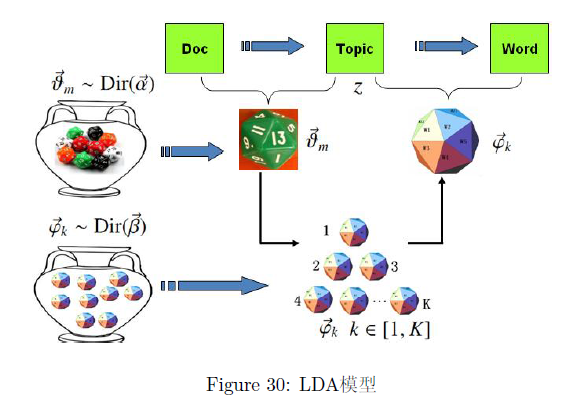
- 上帝有两大坛子的骰子,第一个坛子装的是 doc-topic 骰子,第二个坛子装的是 topic-word 骰子;
- 上帝随机的从第二个坛子中独立的抽取了 K 个 topic-word 骰子,编号为 1 到 K;
- 每次生成一篇新的文档前,上帝先从第一个坛子中随机抽取一个 doc-topic 骰子,然后重复如下过程生成文档中的词:
- 骰子这个 doc-topic 骰子,得到一个 topic 编号 z
- 选择 K 个topic-word 骰子中编号为 z 的那个,投掷这个骰子,于是得到一个词
上式过程涉及到两个物理过程:
表示生成第 篇文档中的所有词对应的 topics。显然 对应于 Dirichlet分布, 对应于 Multinomial 分布,所以整体是一个 Dirichlet-Multinomial 共轭结构;
,在 的限制下,第 个主题-词分布生成第 篇文档的第 个单词。此时 对应于 Dirichlet 分布, 对应与 Multinomial 分布,所以整体也还是一个 Dirichlet-Multinomial 共轭结构;
对于第一个物理过程,我们有
其中 , 表示第 m 篇文档中第 k 个 topic 产生的词的个数。进一步,利用 Dirichlet-Multiomial 共轭结构,我们得到参数 的后验分布恰好是
由于语料中 篇文档的 topics 生成过程相互独立,所以我们得到 个相互独立的 Dirichlet-Multinomial 共轭结构,从而我们可以得到整个语料中 topics 生成概率
类似于第一个物理过程,第二个物理过程我们可以得到:
其中 , 表示第 个 topic 产生的词中 word t 的个数。进一步,利用 Dirichlet-Multiomial 共轭结构,我们得到参数 的后验分布恰好是
而语料中 个 topics 生成words 的过程相互独立,所以我们得到 个相互独立的 Dirichlet-Multinomial 共轭结构,从而我们可以得到整个语料中词生成概率:
于是对于整个语料库的生成概率,我们可以得到:
此处符号表示稍微不够严谨,向量 都是用 表示,主要是通过下标进行区分, 下标为 topic 编号, 下标为文档编号。
这一小节摘录至《LDA数学八卦》,这里面把LDA的两个过程讲的比较清楚
Gibbs采样应用过程
有了联合分布 ,万能的 MCMC 算法就可以发挥作用了!于是我们考虑使用 Gibbs Sampling 算法对这个分布进行采样。由于 是观测数据,只有 是隐含变量,所以我们真正需要采样的是分布 。
语料库 中的第 个词对应的 topic 我们记为 ,其中 是一个二维下标,对应于第 篇文档的第 个词,我们用 表示去除下标为 的词。那么按照 Gibbs Sampling 算法的要求,我们要求得到任意一个坐标轴 对应的条件分布 。
假设已经观测到的词 ,则由贝叶斯法则,我们容易得到
由于 只涉及到第 篇文档和第 个 topic,去掉第 个词对应的 ,并不改变其他文档的 Dirichlet-Multinomial 共轭结构,只是某些地方的计数会减少。
所以 的后验分布都是 Dirichlet:
我们整理一下,可得到 Gibbs Sampling 公式的推导:
上式看起来复杂,其实是两个独立的过程,每个过程应用 Dirichlet-Multinomail 共轭。
最终得到的 就是对应的两个 Dirichlet 后验分布在贝叶斯框架下的参数估计,我们知道:
于是,我们最终得到了 LDA 模型的 Gibbs Sampling 公式:
LDA 模型的优雅之处在于推导的过程中,用gamma函数换掉了积分,同时分子分母利用阶乘的性质而约去,使得最后的结果非常简洁。
这一小节摘录至《LDA数学八卦》,同时在《LDA漫游指南》3.4节中有非常详细的推导过程
Train and Inference
有了 LDA 模型,我们的目标有两个:
- 估计模型中的参数 和 ;
- 对于新来的一篇文档 ,我们能够计算这篇文档的 topic 分布 .
有了 Gibbs Sampling 公式,基于训练语料,训练的流程如下:
- 随机初始化:对语料中每篇文档中的每个词 ,随机的赋一个 topic 编号 ;
- 重新扫描语料库,对每个词 ,按照 Gibbs Sampling 公式重新采样它的 topic,在语料中进行更新;
- 重复以上语料库的采样过程,直到 Gibbs Sampling 收敛;
- 统计语料库的 topic-word 共现频率矩阵,该矩阵就是 LDA 的模型;
有了训练好的 LDA 模型,当新来一篇文档时,我们可以如下计算 topic 语义分布:
- 随机初始化:对当前文档中的每个词 ,随机的赋一个 topic 编号 ;
- 重新扫描当前文档,按照 Gibbs Sampling 公式,对每个词 ,重新采样它的 topic;
- 重复以上过程直到 Gibbas Sampling 收敛;
- 统计文档中的 topic 分布,该分布就是
记住,inference过程基本与training过程一致,但在inference过程中,Gibbs Sampling 公式中的主题-词分布 部分是稳定不变的,是由训练语料得到的模型提供的.
主题数选取
上述篇章基本就把 LDA模型 大致过了一遍,但有个问题就是主题数 还不好选取, 值取小了,则训练出来的主题之间会有语义上的重叠,若取大了,首先是训练就比较耗时,主题分布会比较稀疏。所以对于一个语料集来说在训练前 设为多少合适呢?
尽管到现在也还没有一个非常好的方法可以有效的选取合适的 值,有人就用测试语料的困惑度(perplexity)来不断的试验,从而得到比较好的 ;同时也有人提出了一些比较复杂的模型自适应调节选取合适的主题数 ,比如 HDP 模型。也有人类比 k-mean 聚类的 值的选取,基于密度的自适应调节来得到合适的主题数,这种模型相对简单些,理解和实现起来都比较容易,所以本篇主要介绍这种。
下面介绍 《一种基于密度的自适应最优LDA模型选择方法》-曹娟 的论文中提到的方法:
定义 1(主题密度):
对给定的主题 和距离 ,以 为中心,半径为 画一个圆,分别计算 与其它主题之间的相似度(余弦相似度),相似度的值落在圆内的主题数目称为 基于 的密度,记为 .定义 2(模型基数):
给定一个主题模型 和正整数 ,模型中密度小于或等于 的主题数目称为该模型的基数,记为 .定义 3(参考样本):
对于主题分布中的一个点 、距离半径 和阈值 ,如果满足 ,则称 代表的词空间向量位主题 的一个参考样本.
参考样本不是实际数据集中的一个文档向量,而是词空间分布上的一个虚拟点.
主题 之间的相似度为:
越小,主题之间越独立;
所有主题之间的平均相似度来度量该主题结构的稳定性:
当主题结构的平均相似度最小时,对应的模型最优.
在以上定义的基础上,基于密度的最优模型选择算法可描述为以下过程:
- 根据任意给定的初始 值,以随机抽样方式对 Dirichlet 分布的完全统计矩阵进行初始化,得到一个初始模型 ;
- 将初始模型的主题分布矩阵 作为一个初始聚类结果,计算所有主题之间的相似度矩阵和平均相似度 ,基于 得到所有主题的密度 ,最后,设 ,计算该模型 的基数 ;
根据上步的参考 值重新估计 LDA 模型参数, 的更新函数为:
其中 表示 的变化方向,当 的变化方向为负时(与前一次相反),;当 的变化方向为正时(与前一次相同),;当 时,将主题从小到大按密度排序,将前 个主题视为参考样本,对下一次 LDA 模型参考估计的 Dirichlet 完全统计矩阵进行初始化;反之采用从集合中抽样的方式对完全矩阵进行初始化;
反复执行第 2 步、第 3 步,直到平均相似度 和参数 同时收敛。
由于平均相似度最小时主题结构最优,则每次迭代使得 减小的方向为正方向.
该论文中的第 2 步感觉是有问题的,首先为什么是以主题的平均相似度为半径计算所有主题的密度 density(z,r) ,按照定义这个密度应该是 " - 领域"内的主题数量。
另外为什么要设置 来计算模型 M 的基数 ;
这两点论文中写的不清不楚。但大致这种思路我们可以借鉴,经过实际项目中实践去调整出合适的方法。
java 源码分析
github 源码地址:https://github.com/NLPchina/ansj_fast_lda
导入该 maven 工程,程序入口为默认包名下的 FileLDATest.java 程序,首先看看主方法:
public static void main(String[] args) throws IOException {LDA lda = new LDA(10);for (File dir : files) {for (File file : dir.listFiles()) {//往 LDA 模型训练器中添加语料lda.addDoc(file, "gb2312");}}// 训练模型并保存lda.trainAndSave("result/cluster", "utf-8");}
其中添加文本语料核心代码如下:
public void addDoc(String name ,Reader reader) {// 分词words = analysis.getWords(reader);// 将分词结果设置到 LDA模型中,做统计ldaAModel.addDoc(name,words);}
下面看看再 ldaModel 中做了哪些统计:
public void addDoc(String name, List<String> words) {//生成一个文档数据结构,并设置主题数Doc doc = new Doc(name,topicNum);Integer id = null;int topicId = 0;//统计文档总数dCount++;for (String string : words) {//将单词映射到索引上id = vectorMap.get(string);if (id == null) {id = vCount;vectorMap.put(string, vCount);//统计单词总数vCount++;}// 对每个单词随机初始化一个主题编号topicId = (int) (Math.random() * topicNum);// 文档增加向量doc.addVector(new Vector(id, topicId));}docs.add(doc);}
我们看到,当一篇文档添加到主题模型中时,会更新单词总数和文档总数,并将单词映射到整数索引上。
回到最开始的主方法,接着我们看训练部分:
public void trainAndSave(String modelPath, String charset) throws IOException {//利用初始化好的每个单词的主题来填充主题-词矩阵fullTopicVector();// 迭代收敛for (int i = 0; i < iteration; i++) {for (Doc doc : docs) {//对每个单词(单词 id,主题 id)for (Vector vector : doc.vectors) {//采样每个单词的主题sampleTopic(doc, vector);}}}//保存训练好的模型saveModel("result", modelPath, charset);}
一步一步来,fullTopicVector()中也做了一些主题有关的统计:
private void fullTopicVector() {//为主题-词矩阵分配内存topics = new Topic[topicNum];for (int i = 0; i < topics.length; i++) {topics[i] = new Topic(vCount);}for (Doc doc : docs) {// 对每篇文档的每个单词for (Vector vector : doc.vectors) {//统计每个主题中的每个单词出现的次数topics[vector.topicId].addVector(vector);}}}
每个 Topic 数据结构中 vCount 表示该主题中所有的单词统计次数,vectorIdArray[id] 表示该主题中单词 id 为 id 的单词出现的次数.
// Compute p(z_i = k|z_-i, w) 抽样protected void sampleTopic(Doc doc, Vector vector) {// 单词的主题 idint oldTopic = vector.topicId;// w_-idoc.removeVector(vector);// z_-itopics[oldTopic].removeVector(vector);double[] p = new double[topicNum];for (int k = 0; k < topicNum; k++) {// topics[k].vectorIdArray[vector.id] 表示 第 k 个主题所对应的单词中,单词 id 为 vector.id 的单词出现的次数// doc.topicArray[k] 表示文档 doc 中第 k 个主题所包含的单词数// 根据 Gibbs Sampling 公式更新p(z_i = k|z_-i, w)p[k] = (topics[k].vectorIdArray[vector.id] + beta) / (topics[k].vCount + vCount * beta) * (doc.topicArray[k] + alpha)/ (doc.topicArray.length - 1 + topicNum * alpha);}// 轮盘赌最后累计使得p[k]是前面所有topic可能性的和// 在《LDA漫游指南》中 4.1 节详细讲了这步逻辑for (int k = 1; k < topicNum; k++) {p[k] += p[k - 1];}double u = Math.random() * p[topicNum - 1];int newTopic;for (newTopic = 0; newTopic < topicNum; newTopic++) {//一个随机数 小于某一累积和if (u < p[newTopic]) {break;}}//更新单词的主题vector.topicId = newTopic;//更新统计量topics[newTopic].addVector(vector);doc.updateVecotr(vector);}
基本就是按照上述理论中提到的
公式进行采样.
整个 LDA 模型训练部分就完了,可以看到实现起来很简单。
最后保存模型时,我们保存的是文档-主题分布 和 主题-词分布 ,所以对上述训练结果需要做一些计算:
private void saveModel(String iters, String modelPath, String charset) throws IOException {//初始化double[][] phi = new double[topicNum][vCount];double[][] theta = new double[dCount][topicNum];//更新 phi,theta 两个分布updateEstimatedParameters(phi, theta);//保存模型到文件中saveModel(iters, phi, theta, modelPath, charset);}
根据 和 的 Dirichlet 后验概率分布来估计:
protected void updateEstimatedParameters(double[][] phi, double[][] theta) {Topic topic = null;for (int k = 0; k < topicNum; k++) {topic = topics[k];for (int v = 0; v < vCount; v++) {// 主题 / 单词 模型phi[k][v] = (topic.vectorIdArray[v] + beta) / (topic.vCount + vCount * beta);}}Doc doc = null;for (int d = 0; d < dCount; d++) {doc = docs.get(d);for (int k = 0; k < topicNum; k++) {// 文档 / 主题 模型theta[d][k] = (doc.topicArray[k] + alpha) / (doc.vectors.size() + topicNum * alpha);}}}
测试过程与训练过程类似,只是主题-词分布稳定不变,其他过程都一样,这里就不多说了。
小结
LDA 主题模型涉及到的数学知识比较多,也比较难理解,笔者也是看了挺多资料才懂,不过该模型的实现很简单,并且在 《LDA漫游指南》中也将了基于分布式平台的模型训练方法,在实际项目中也很有帮助。
虽然理解起来比较困难,但多看几遍还是比较清楚的。其中关于主题数的自适应选取,笔者实现一版后再继续更新本文档。
参考
- http://www.360doc.com/content/16/0428/10/478627_554452907.shtml
- http://www.cnblogs.com/pinard/p/6805861.html
- 《LDA 数学八卦》
- 《LDA漫游指南》
- 《一种基于密度的自适应最优LDA模型选择方法》
