@changedi
2024-02-23T09:35:13.000000Z
字数 3133
阅读 941
RealTime Clustering——实时聚类的一些方法
大数据 机器学习 算法
概述
聚类算法是一系列基于测度理论的无监督分类方法。不同于有监督的分类需要做训练和标注。聚类通过定义一个测度来衡量样本点之间的距离从而构造一套算法过程来将样本空间划分为样本点簇的集合。
典型的聚类算法有顺序聚类算法、K-means和hierarchical聚类等,具体聚类可以参考笔者之前的文章介绍[1]。因为聚类的这种无监督特性,聚类的应用场景主要偏分析、验证,很少有做直接定性结论的分类和预测的。正因为聚类是一种对于大量数据的依据相似度划分子集的分析,所以一般意义上的聚类算法都是针对固定数据集做分析的。很难做到对于流式数据、单个点数据有比较好的算法和效果。
背景
为什么要做流式数据的聚类呢?也和我们遇到的实际场景有分不开的关系——9点电台文本问题发现。在客服应用系统中,作为接受客户心声的VOC(voice of customer)平台,我们接触的大量数据是客户的问题文本(包含电话语音转文本)包含咨询、维权、评价、舆情反馈等等。我们需要识别客户的每个问题,并分析相关的客户体验影响指标,从而可以做出准确合适的服务策略应对,同时将问题准确的描述并传递给前台各个业务以达到提升体验改进业务的目标。这就需要及时发现有价值的重要的问题,尤其是新问题。
面对问题识别的场景,可以把这个场景规约为一个分类问题。通过海量数据的离线标注和训练完成文本分类,模型在线预测。这个方法虽然可能能解决90%的问题(见笔者另一篇离线分类文章),但是留下的问题是是对于新文本问题的发现,分类的方法很难做好。而这种新问题发现,对于大促或者是一些重要的活动下做监控是至关重要的。因此能有一种实时的问题分类并发现新问题的方法就显得非常重要了。介于此,9点电台的算法团队和研发团队基于one pass制定了一套实时聚类算法的方案,并在2017年的双十一成功的应用于天猫国际的实时问题监控大屏上面。
为啥不用kmeans?kmeans需要指定K,这是最大的问题,新问题发现没法做。同时,kmeans的建模是个典型的迭代计算更新centroid的过程,需要O(n^2)的复杂度。kmeans的算法伪码如下:
for k = 1, … , K 令 r(k) 为从D中随机选取的一个点;while 在聚类Ck中有变化发生 do形成聚类:For k = 1, … , K doCk = { x ∈ D | d(rk,x) <= d(rj,x) 对所有j=1, … , K, j != k};End;计算新聚类中心:For k = 1, … , K doRk = Ck 内点的均值向量End;End;
而one pass算法[3],通过0迭代,每次去计算与中心的距离并更新中心来完成流式的计算。算法伪码如下:
While 流入一个点p doFor k = 1, ... , K 遍历已有的K个中心 do比较 d(p,k) < D Thenp 加入 kEnd;If p 没有加入 ThenK = K +1p 成为新聚类K的中心End;
实时聚类
实时聚类需要解决两个问题,一是快速高效计算,另一个是模型的动态更新。要进行高效计算,就不能像普通聚类一样进行迭代。动态更新模型,那又需要cluster模型内部进行比较。[2]里介绍了两种实时聚类算法——RTEFC (实时指数过滤聚类)和RTMAC (实时移动平均聚类),他们都是高效且简单易实现的算法。无论是建立模型还是无模型的模式匹配,这两个方法都有效。
RTMAC
实时移动平均算法是kmeans算法的一种变种,之所以叫做moving average,主要是因为与时序分析中的moving average filter很像。moving average的标准公式如下:
这里计算的是前n个point的均值点,计算方式就是简单的算术平均。
RTMAC在kmeans算法的基础上需要维护一个point的时效属性(区别最老的和最新的)。另外需要设定一个nMax阈值来约束每个cluster的大小上限。因为有移除最老point的逻辑,就体现了moving的概念。这样通过如下的一个步骤就完成了聚类:
对于每个点 p:1. 计算min distance(p, clst_centroid[i]) 寻找最近的cluster2. 将p加入cluster3. 如果 sizeof cluster >= nMax, 那么remove(oldest point)4. update(cluster)计算新的cluster centroid
分析这个流程,如果有K个cluster,nMax=N,且点维度为F的话,这个算法的时间复杂度为O((K+N)F),空间复杂度为O(KN)。
在这个基础上,如果要加入发现新cluster的能力,只需要引入cluster半径即可,同时半径的引入,也会让算法适应数据冷启动。这个算法的复杂度以及对
RTEFC
另一种算法指数过滤器聚类,也是为了减少kmeans算法的迭代而设计的。对比RTMAC就是使用指数过滤器来替代了移动均值。公式如下:
这里是平滑因子,一个自定义参数。
具体算法如下:假设新计算的点为p,聚类中心集合为P,d(p,p[i])为p和P中的中心点的距离。
对于每个点 p:1. 计算p到P中每个点p[i]的距离d[i],找到最近的d[close]=min(d[i])对应的p[close]2. 如果 d[i]小于聚类半径,并且dim(P)<nCaseMax,那么p作为一个新的聚类中心加入集合P3. 否则更新p[close],更新方法为指数过滤器公式:p[close]=a*p[close] + (1-a)*p
其中dim(P)是P集合的中心个数,而nCaseMax是最大聚类常数。这个过程就是一个中心点的指数平滑过程[4]。下图比较清楚的表述了聚类中心移动的过程:
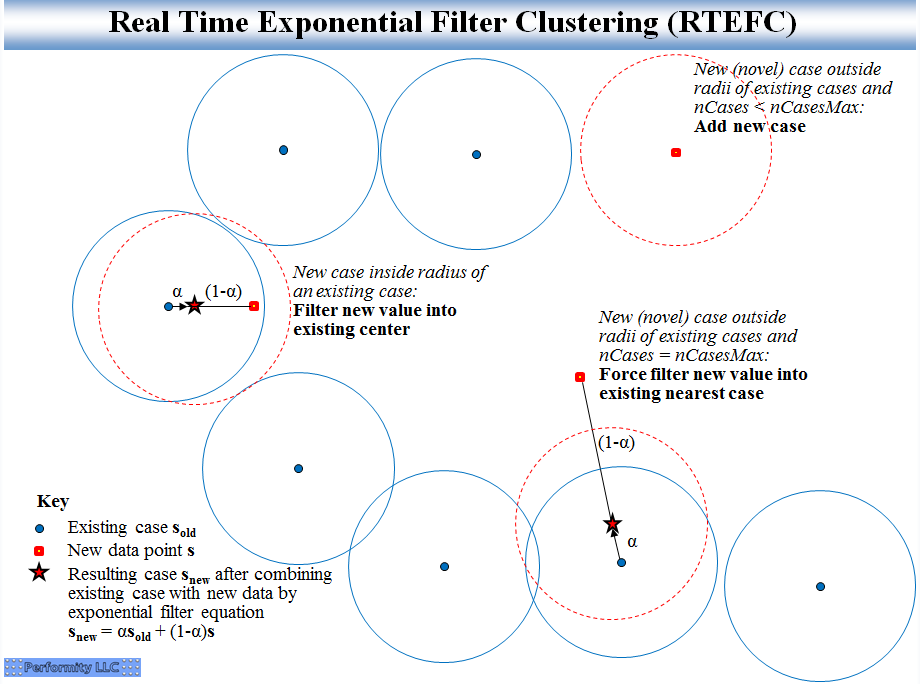
图片来源(picture source):见文献[2] (reference[2])
使用filter算法的优势
我们对比kmeans算法,上述两个filter算法,不仅能平滑噪声数据,更重要的是它们是有存储限制的,也就是说窗口的长度约定了cluster的大小,从而会丢弃老数据,而kmeans是一个全量数据的算法,不会“遗忘”老数据。对于持续运行的实时数据,filter算法可以保证每个点对cluster centroid的影响是同样的,不会因为先到后到而衰减。另外一个优势就是上面提到的,可以发现新的cluster。
设计实现
我们的完整流程是这样的,包含了搜索索引和问题发现两部分。
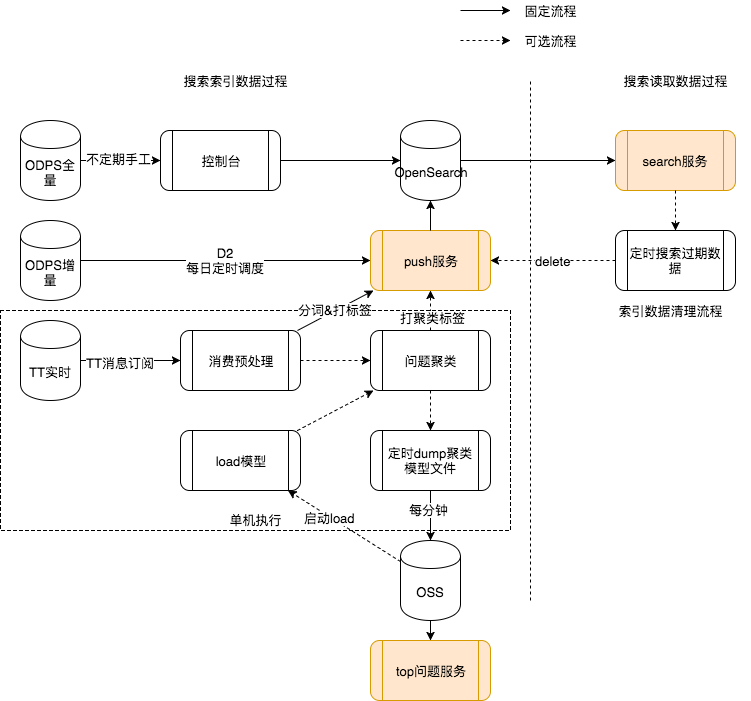
而聚类算法的流程如下:
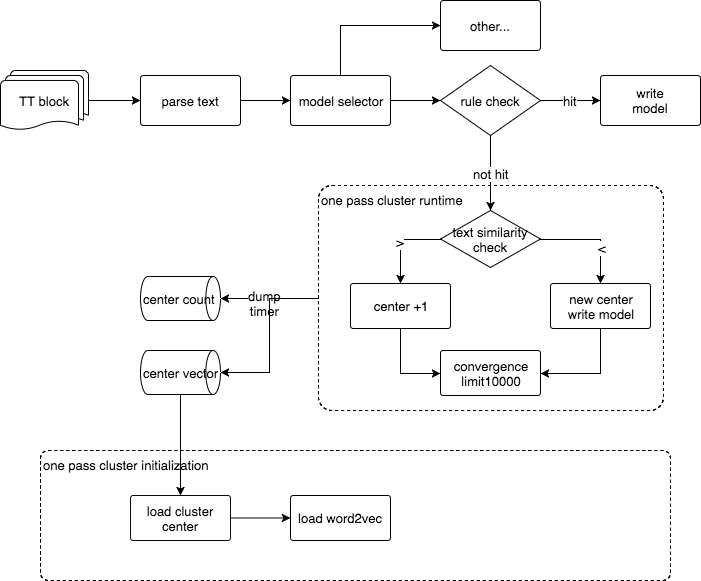
具体一些实现的细节还包括:
1. 距离测度基于欧式距离
2. 特征选择word2vec离线全语料训练的模型
3. 每个cluster默认采用10000个point作为cluster的容量,目前没有涉及oldest remove的逻辑,是一个直接reject新point的实现
4. 算法前置一个规则判断,做一层filter
5. 距离阈值等同于半径概念,支持发现新cluster
6. 定时dump模型,初始化冷启动加载
总结
实时聚类的方法虽然看似简单,但是作为分类场景的补充个人觉得是机器学习应用场景中很重要的一环。参考文献[2]中还提供了几种微聚类、微批处理和递归密度估计等方法。具体细节可以详细阅读相关文献。
写在最后,欢迎各界技术大牛来指导工作和技术交流,也欢迎对客户服务领域感兴趣的小伙伴加入我们客户体验RDC的团队,这里有各种复杂的业务场景和平台挑战。
