@changedi
2019-06-05T09:52:37.000000Z
字数 3627
阅读 6545
商家服务诊断技术分享——(一)基于多维度分层下钻分析
数据分析
前言
商家数据尤其是服务域的数据,对于商家来说一直是一个空白,商家能看到的数据仅局限于生意参谋的退款、咨询部分数据和某些ISV提供的人员人效分析工具赤兔的数据。而商家服务诊断产品旨在帮助商家做到看数据、分析数据、定位问题、找到方案的完整数据-策略-解法通路,最终通过监控指标的变化来完成业务闭环。
在服务域,新灯塔考核指标是CCO的宗布业务团队在2018年提出的一套综合表达商家体验能力的指标体系,包含了咨询、商品、物流、售后和纠纷5个主题,涵盖旺旺回复率、商品品质退款率、物流到货时长、物流DSR、售后仅退款时长、退货退款时长和纠纷退款率共计7个指标,这些指标通过归一先得到一套满分为5分的分数,再加权平均得到商家综合体验得分(一个0-5分的得分值)。在此之上,综合体验得分再通过全体排名,映射到综合体验星级,也就是大家在手淘店铺页可以看到的综合星级了。有了这个“灯塔”,商家可以通过得分来感知自己店铺的综合体验是否健康,从而去改进对应的服务内容。我们为商家提供了一个数据看板、核心问题定位、解决方案推荐的数据分析产品。
注:本文只聚焦于维度分析,对于诊断产品中的解决方案部分、脚本化看板部分将在后续系列文章中介绍。
技术问题
那商家如何定位自己店铺的问题呢?我们简单论述一个通用方法论,就是本文主题所讲述的多维度分层对比下钻分析。场景比如是这样,商家发现自己的物流得分是3分,可以看物流到货时长是否太长,如果是,看下不同的维度表现,如果某个维度值的影响最大,接着下钻,重复分析过程直到覆盖全部目标维度。其实本质上就是杜邦分析法[1]的一种应用。
这种分析方法与多维交叉分析不同,分析目的在于深度找出问题,从某种角度看是一种贪心分析策略解,而多维交叉枚举可以做到全局最佳解。

那么从一个业务分析问题,就可以归约为一个技术问题——如何通过一张多维度的事实表(这是输入),或者更准确的说是一张轻度汇总表(dws),得到一个问题定位链路结果和对应的解决方案(这些是输出)。解决方案目前是完全Rule Based,具体的技术方案分享在目录第四部分会详细介绍。
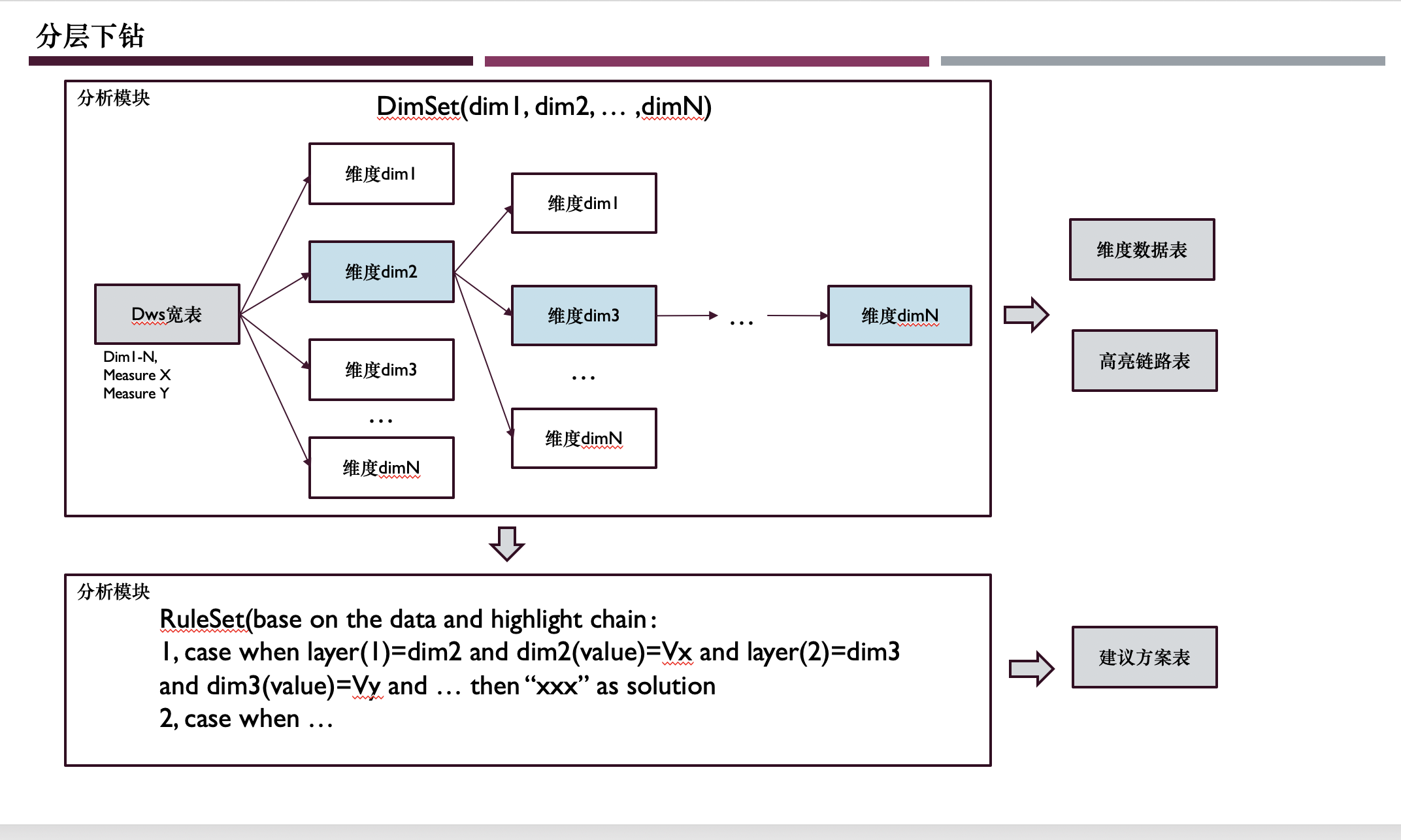
这个问题同时可以有两套配套方案,一是完全人工配置——全部商家看到的是一样的拆解逻辑也就是维度顺序,另一种是自适应搜索——完全通过某个优化目标值搜索得到——每个商家看到的顺序不同。
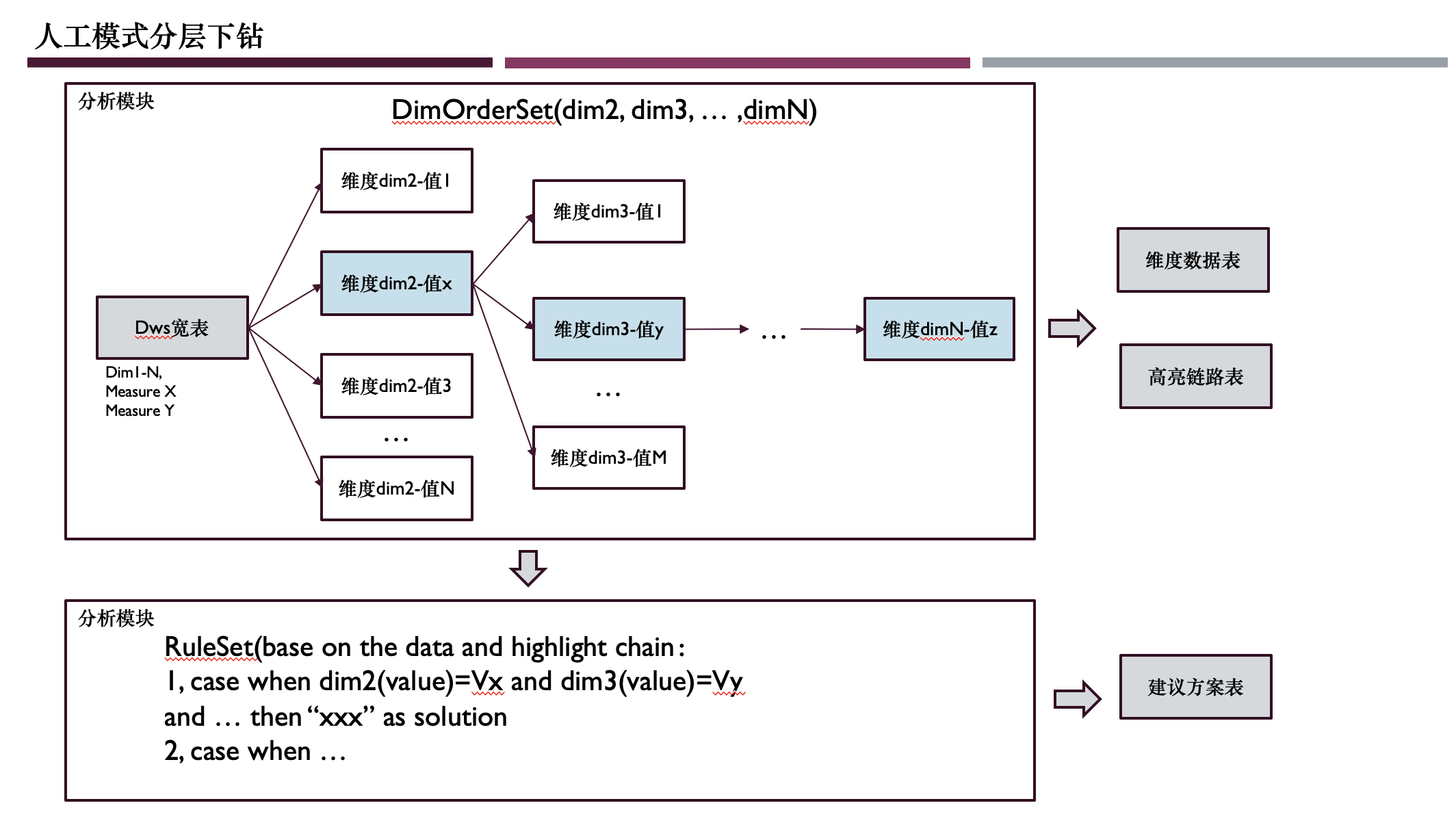
人工配置和自适应搜索是两套完全不同的方案,在人工指定分析顺序后,技术上理论把一个待分析的维度候选集合DimSet转换为了一个有序的候选集合DimOrderSet,这样就将问题大大简化。从业务诉求和技术选型上,我们先在线上实现了前者,后期在后台实现了后者。
技术方案
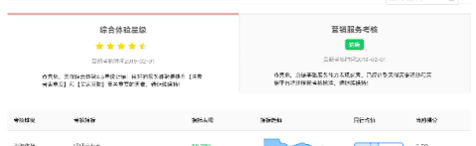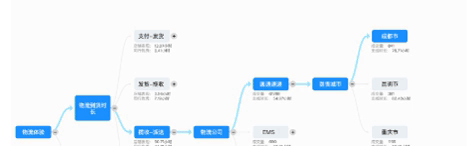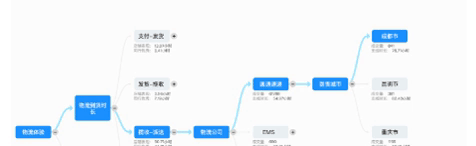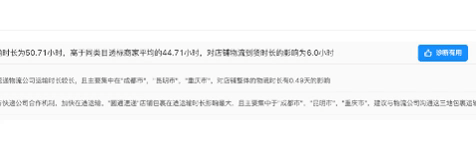
分析一个商家某个主题(比如咨询)下的表现,就是要分析顶层指标——比如旺旺回复率,接着去分层拆解维度——看子账号或者业务量配比或者排班情况,最终找到一个“影响最大”的链路。这看起来像一颗逐层展开的树。先说人工配置方案,因为每棵树对于不同的商家来说只有数据不同,而结构是类似的。因此我们将底层的数据结构设计为一棵多叉树。而从端上看来,我们需要展示分析树、高亮链路和解决方案三类数据。所以从存储结构设计上,对于树的存储,在数据库里就是一个节点表和关系表。而针对“影响最大”的链路,其实存储在另一张计算好的节点链的表中。解决方案存储在解决方案表。
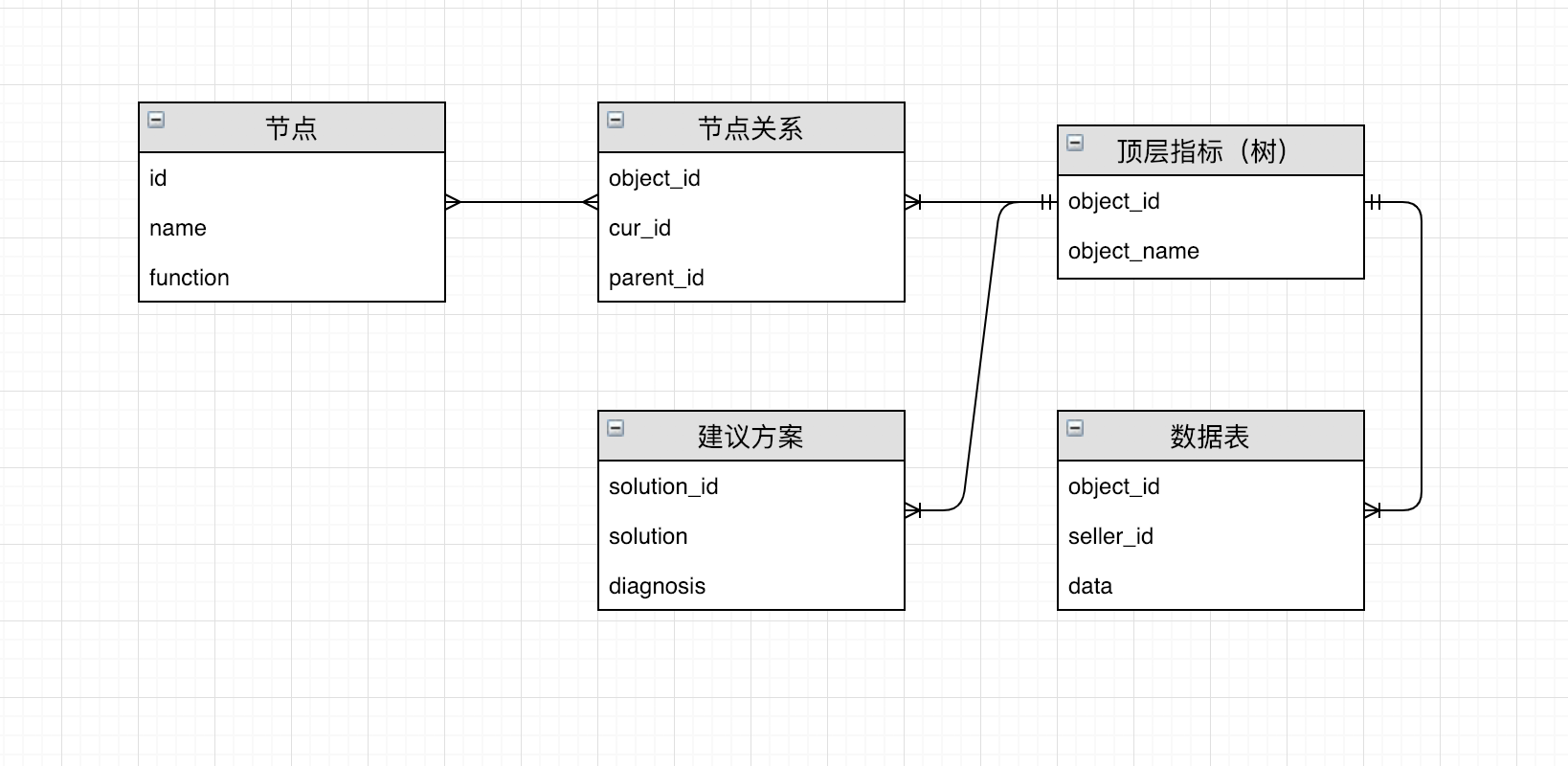
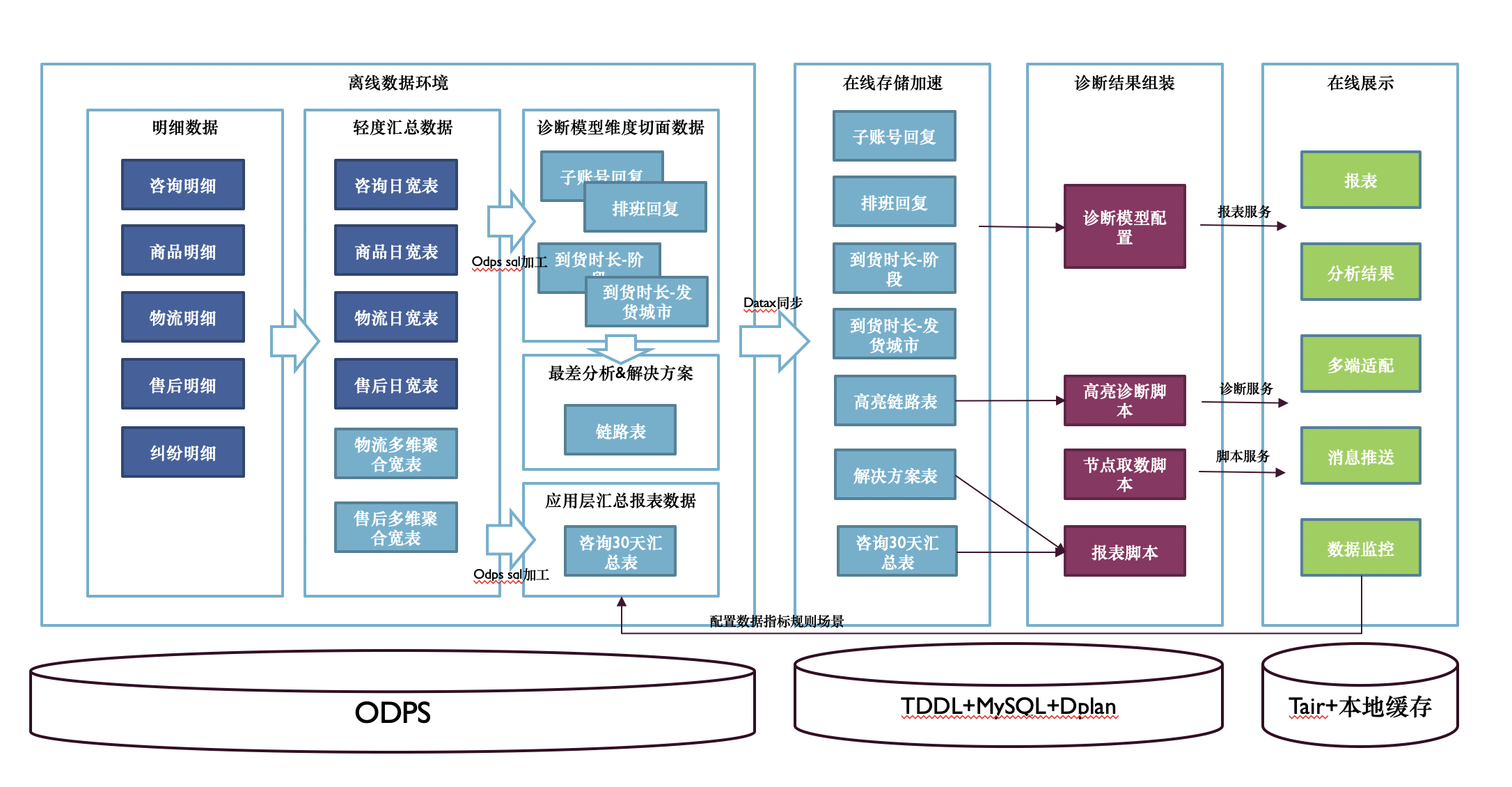
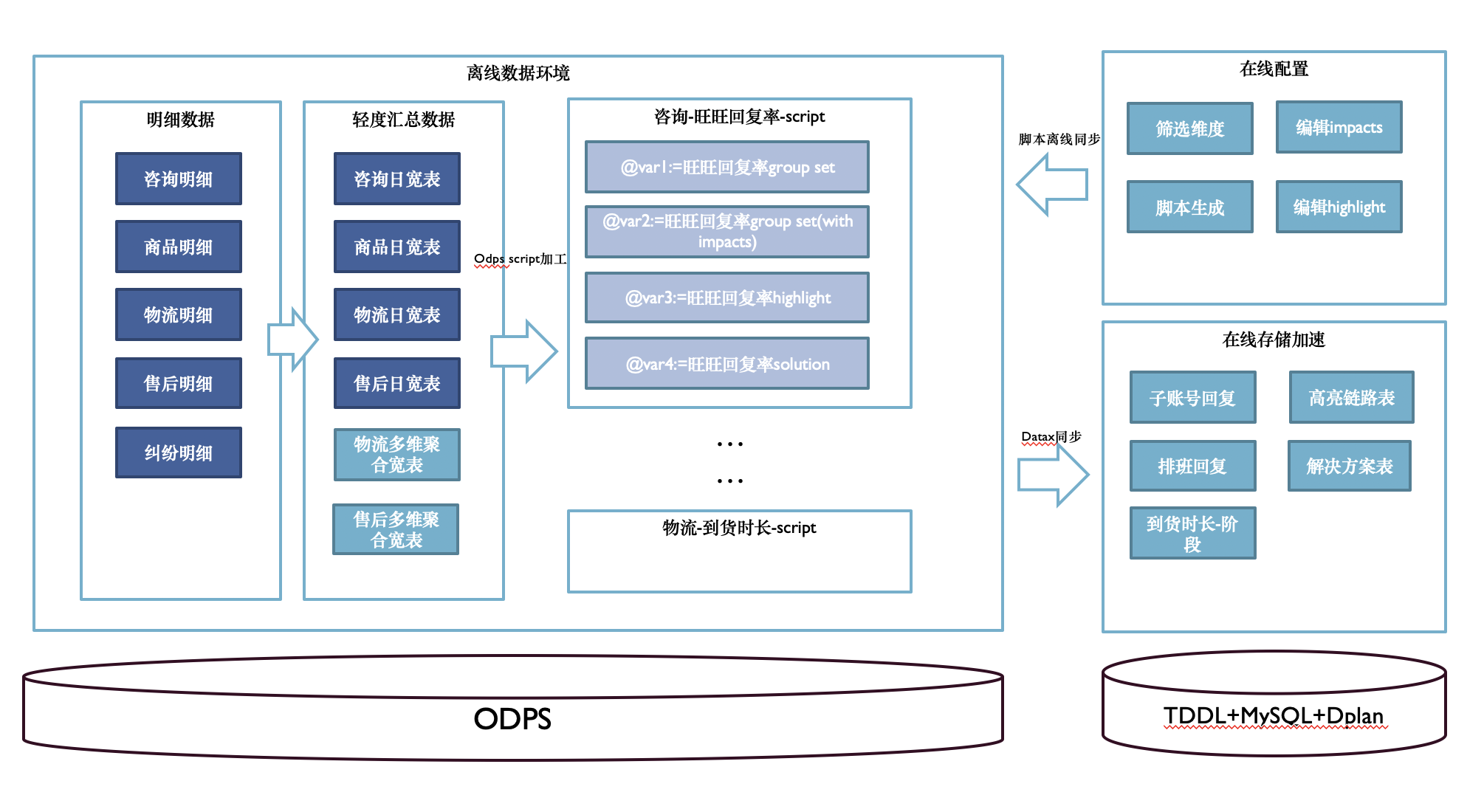
问题的核心是数据,而人工配置树的易切入点在于结构与数据分离,即结构是确定的,而数据是依据商家和日期不同的。所以就可以很好的通过将结构配置留在Java服务端配置开发,而数据在ODPS环境靠构建数据表来解决。所以有如下的一个数据链路图:
在我们的多维度分析中包含两个基础假设,一个基础假设是维度可分层且维度值在对顶层指标拆解贡献中是具备可加性的,说白了就是可以划分。另一个是要有一个维度评价标准定义,在这里我们定义为影响程度(表达了当前分析维度值在对顶层指标的影响),公式如下:
这就要求我们在宽表dws层建设时,把原始指标和响应的占比数据(或者比率)数据作为度量值都带上。
数据加工
做这样的多维度分析,我们直观的想法是构建一个数据立方体,在早期阶段,我们为每个维度切片构建一张中间表,在该过程中包含了对这个维度的聚合和相关指标计算。这个过程是个典型的聚合查询过程,这里就不赘述了。这个方案带来的最大问题就是没办法大规模生产——太依赖人肉开发,并且产出了大量的中间结果表。
因此我们在这个方向上的探索在ODPS升级后得到了一些启发:利用grouping set这样的roll up能力[2],结合odps script mode 的能力[3],先固化脚本再结构化脚本。从而减少维护的脚本数量,未来可以做到全配置自动化生产。CUBE的语法支持(hive很早就有)使构建数据立方体成为可能,同时固定模式的分析方法(多维度分层下钻)也使配置系统化成为可能。在早期产品探索阶段,放弃高大上的ad hoc模式而采用传统lambda架构下的数据加工生产,按需按配来计算加工数据,虽然“土”了点,但是从投入产出比来看应该是最划算的。
配置后台
我们为人工配置树方案提供了一套配置后台,目的在于可以支持业务方灵活的修改诊断逻辑。在后台我们结合antd g6的前端画图能力将诊断主题的树通过拖拽形成一套节点和边的关系数据,并先持久化到文件,然后持久化到数据库。借着通过抽象几类节点将节点的取数逻辑进行管理,并通过TQL完成取数逻辑脚本编写。这样就形成了一个节点实体、节点关系、节点脚本的实体抽象,将这些组合在一起就构建了一个可配置可编辑的后台。在配置后台,我们可以随意测试和模拟前端诊断树的展示和取数逻辑是否正确。
具体脚本的模式将在第二篇文章中介绍。
搜索方案
我在这里简述一下搜索的方案。因为需要完全依据商家数据的实际情况展示不同的诊断树,因此需要先定义一个搜索算法,然后对每个商家应用这个算法产出数据并存储对应的结构展示。
搜索算法是一个非常简单的迭代算法,迭代找出最优的维度即可。伪代码如下:
输入:候选维度集合DimSet(dim1,dim2,...,dimN), 度量M输出:有序顺序DimOrderSetStart:0,按照sellerId聚合,计算店铺层面度量值M(s)和对应数量值Cnt(s)1,遍历DimSet:1)按照对应dim聚合计算度量M,数量Cnt和impacts=[M-M(s)]*[Cnt/Cnt(s)],查询数据库(一个形如select dim,m,cnt,impacts from dws_table where seller_id=xxx group by dim的语句)并按照impacts排序,得到当前维度最大值dim(i,x)和当前维度impacts(i,y)2)比较当前维度impacts(i,y)和最大维度impacts(max,y),记录最大impacts(max,y)=impacts(i,y)>impacts(max,y)?impacts(i,y):impacts(max,y),记录最大维度dim(max,x)2,把dim添加到DimOrderSet,并从DimSet移除最大dim,重复步骤1直到DimSet为空End
唯一复杂的是在这个过程中,每次取数时去哪里取数是个费脑筋的问题。目前我们基于HiStore实现了一套后台demo,单线程单指标单次计算耗时近30s。对于淘系近千万商家的量,以及一个会水平不断扩展的指标数量(目前是10个),那么计算耗时将非常高(即便开几百个线程也要耗数百台虚机)。一个替代方案是构建数据立方体然后存储到HBase加快查询速度来缩小单次耗时,但是过度的存储浪费也不是最合理的。因此目前还在ad hoc查询、Hbase、search as OLAP等几类方案中评估测试,暂时不会全面上线,后续有结论会再补充一篇文章来介绍。
未来
诊断型产品天生需要结合全栈开发的能力来建设,因此需要在数据模型、算法模型和后台开发甚至前端开发方面持续投入。商家服务诊断产品目前还只是初窥门径,未来的路还很长,如何做好数据分析,如何赋能商家,如何结合方案形成闭环,都将是我们要发力的方向。希望可以和大家共建共享。
同时,多维分析也是一种通用的能力建设,我们也希望将模型和配置过程系统化沉淀为平台,将分析和配置能力为通用业务指标分析提供工具。
参考文献
[1]. 杜邦分析法
[2]. ODPS GROUPING SET
[3]. ODPS SCRIPT MODE
文章目录
(一)基于多维度分层下钻分析
(二)基于脚本化设计的数据看板配置
(三)趋势数据分析诊断
(四)解决方案管理模型
