@changedi
2024-02-23T09:36:19.000000Z
字数 4034
阅读 904
基于统计信息量的半自动问题发现方法
NLP
In the field of mathematics, the art to ask questions is more important than to answer questions.
——Cantor
问题发现
问题发现的场景来源于膏满黄肥的大闸蟹——又到一年一度的吃蟹时节,在全国人民举国吃蟹之际,由蟹买卖带来的大闸蟹商品交易服务问题也逐渐暴露出来。面对每年电商平台上各种对于蟹的维权、投诉、咨询等等问题,不管我们服务部门的人care or not,它们就在那里,推动这些问题改进,带来服务品质提升,优化平台体验,这成为“发现“问题的重要价值,也是9点电台产品的使命。我不知道每年315时央视如何发现这个社会的商品服务体系下各个行业出现的问题,但是,9点电台决定通过运用数据的力量,来发现问题。
统计、统计
数据源
从哪里发现问题,先划个道吧。面对这一年来千奇百怪的维权case,首先要做的第一件事情是圈定数据范围——从千万级别的数据中过滤有用的。我们选择了近一年的水产类目-大闸蟹商品相关的所有维权case作为数据集,从数据集中采取商品标题和维权原因(纯文本内容)字段作为核心分析字段。这是一个很直观的抽取,当然也是9点电台 首席分析师 @湘晨的建议。
数据工具
没有金刚钻,不揽瓷器活。我们除了需要数据,更要有操作数据的工具,否则就是坐在金山上啃馒头。9点开发团队在此有两把武器:搜索和文本统计分析。
搜索引擎可以很方便的从全量case中灵活的找到各种case,快捷的看到相关文本,更快捷的利用“人工”智能发现问题。通过文本搜索,相比于利用Sql通过ODPS查询而言,从效率和灵活度上看,搜索都是绝对的取数神器。具体9点的搜索技术请参考笔者另一篇文章《基于opensearch的搜索引擎实战》。
另一件武器就是文本分析。对于文本分析,我们最常做的就是要确定各种统计量,从中发现数据规律。那么这就引入PAI算法平台的文本分析工具套件,如下图所示
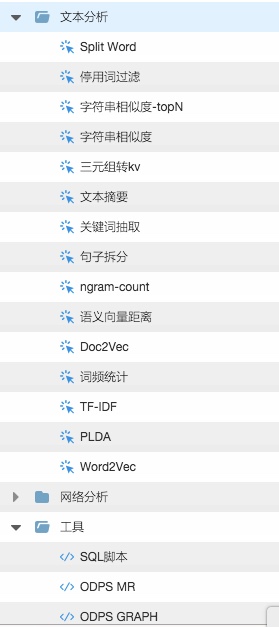
PAI作为算法平台,提供了丰富的文本分析组件,利用这些组件,开发人员可以很快速的统计出各种数据指标以及完成算法实验。
利用这两大武器,我们搭建了大闸蟹直播间的客情top问题发现的产品模块。整个技术设计过程,下面介绍。
过程抽象
问题发现是一个从海量问题文本中自动挖掘主题的典型场景。作为主题挖掘的应用,大家直观的想到了类似文本聚类、LDA等算法。我们也不例外,去尝试了一些算法。算法的实验flow如下:
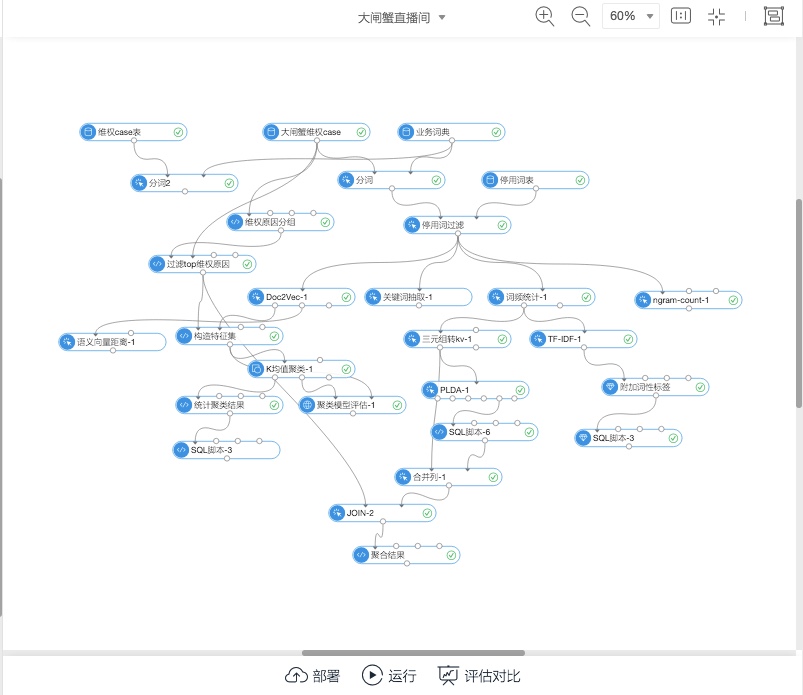
实验一:word2vec + k-means + 评估
文献[1]指出了常见的主题发现方法——聚类算法,通过划分或者层次聚类进行文本的自动归类,当然这也是做这个场景的经验想法。但是需要说明的是,聚类算法的选择、相似测度的确定等等都需要有大量的实验来调参。我们基于现有的算法工具包实验环境,做了基于PAI的kmeans算法实验。
实验具体情况:
0,数据:根据维权原因计算分布,确定topk=13类原因对应问题,覆盖了数据集88%的数据量,模型可以认可。
1,向量:文档的向量化方法使用word2vec,语言模型skip-gram,产出100维向量,针对字段是refund_desc。
2,算法:选择kmeans(PAI平台目前也只有kmeans)作为聚类算法,相似测度使用余弦相似度,初始聚类目标是k=个主题。
3,评估:利用每个维权case上自带的维权原因字段reason_name(小二打标产生)来确定k个问题主题,另外基于这些标注做结果准确率的评估。
部分结果截图如下:

| 聚类编号 | 原因 | 聚类case数 | 聚类总case数 | 实际case数 | 准确率 | 召回率 |
|---|---|---|---|---|---|---|
| 0 | 商品变质/有异物/水产死亡 | 528 | 1726 | 1410 | 0.30590961761298 | 0.374468085106383 |
| 3 | 未按约定时间发货 | 503 | 672 | 1645 | 0.7485119047619 | 0.305775075987842 |
| 1 | 收到商品与描述不符 | 463 | 1810 | 1756 | 0.25580110497238 | 0.263667425968109 |
| 9 | 商品质量问题 | 222 | 1696 | 1083 | 0.13089622641509 | 0.204986149584488 |
| 6 | 商品成分描述不符 | 215 | 1494 | 659 | 0.14390896921017 | 0.326251896813354 |
| 4 | 未收到货 | 138 | 530 | 553 | 0.26037735849057 | 0.249547920433996 |
| 5 | 产地/批号/规格等描述不符 | 109 | 684 | 469 | 0.1593567251462 | 0.232409381663113 |
| 12 | 卖家发错货 | 12 | 536 | 331 | 0.02238805970149 | 0.0362537764350453 |
| 11 | 包装/商品破损/污渍 | 4 | 51 | 232 | 0.07843137254902 | 0.0172413793103448 |
| 2 | 退运费 | 2 | 11 | 285 | 0.18181818181818 | 0.00701754385964912 |
| 7 | 其他 | 0 | 19 | 335 | 0 | 0 |
| 8 | 假冒品牌 | 0 | 35 | 222 | 0 | 0 |
| 10 | 商品变质 | 0 | 15 | 333 | 0 | 0 |
| 平均 | 0.17595380928292 | 0.155201433474025 |
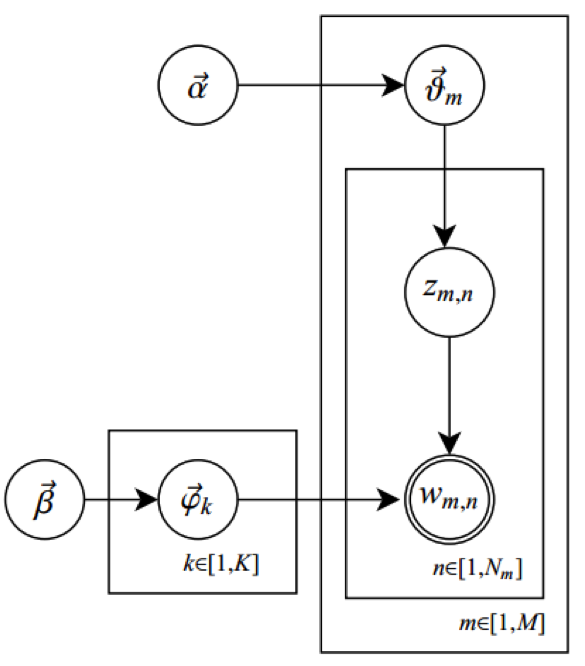
实验二:word-count + PLDA
LDA[2]是大名鼎鼎的主题识别算法,其核心的能力就是在给定一篇文档的前提下,推测其主题分布。其通俗解释为假定语料库中共有m篇文章,一共涉及了K个Topic,每个Topic下的词分布为一个从参数为β的Dirichlet先验分布中采样得到的Multinomial分布(注意词典由term构成,每篇文章由word构成,前者不能重复,后者可以重复)。每篇文章的长度记做Nm,从一个参数为α的Dirichlet先验分布中采样得到一个Multinomial分布作为该文章中每个Topic的概率分布;对于某篇文章中的第n个词,首先从该文章中出现每个Topic的Multinomial分布中采样一个Topic,然后再在这个Topic对应的词的Multinomial分布中采样一个词。不断重复这个随机生成过程,直到m篇文章全部完成上述过程。
对应一个算法流程图如下:
结果如下:
| 原因 | topic编号 | 分析case数 | 分析总case数 | 实际case数 | 准确率 | 召回率 |
|---|---|---|---|---|---|---|
| 未按约定时间发货 | 4 | 246 | 1002 | 1645 | 0.245508982035928 | 0.149544072948328 |
| 收到商品与描述不符 | 0 | 211 | 915 | 1756 | 0.230601092896175 | 0.120159453302961 |
| 商品变质/有异物/水产死亡 | 9 | 176 | 885 | 1410 | 0.198870056497175 | 0.124822695035461 |
| 商品质量问题 | 10 | 141 | 907 | 1083 | 0.155457552370452 | 0.130193905817175 |
| 商品变质 | 12 | 78 | 970 | 333 | 0.0804123711340206 | 0.234234234234234 |
| 商品成分描述不符 | 5 | 69 | 664 | 659 | 0.103915662650602 | 0.104704097116844 |
| 未收到货 | 8 | 46 | 590 | 553 | 0.0779661016949153 | 0.0831826401446655 |
| 产地/批号/规格等描述不符 | 6 | 31 | 546 | 469 | 0.0567765567765568 | 0.0660980810234542 |
| 其他 | 2 | 29 | 512 | 335 | 0.056640625 | 0.0865671641791045 |
| 退运费 | 3 | 27 | 652 | 285 | 0.0414110429447853 | 0.0947368421052632 |
| 卖家发错货 | 7 | 25 | 544 | 331 | 0.0459558823529412 | 0.0755287009063444 |
| 假冒品牌 | 11 | 18 | 668 | 222 | 0.0269461077844311 | 0.0810810810810811 |
| 包装/商品破损/污渍 | 1 | 13 | 424 | 232 | 0.0306603773584906 | 0.0560344827586207 |
| 平均 | 0.103932493192036 | 0.108222111588734 |
实验三:word-count + statistical phrase-merge
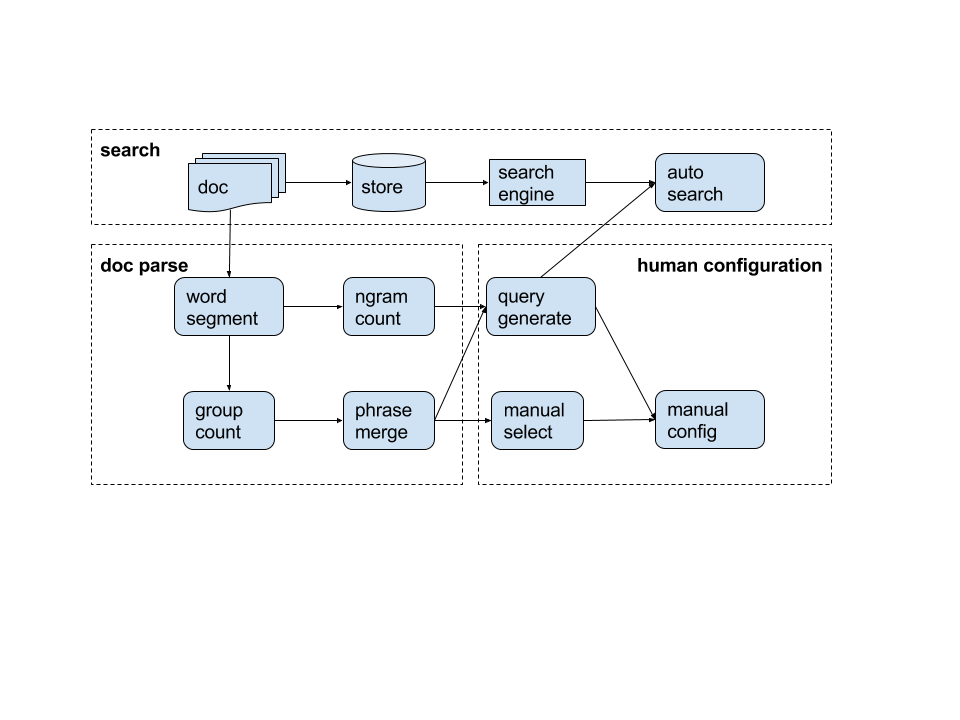
单词和短语的统计,可以很直观的知道这些文档中大家都在说什么。利用词频的热词统计以及基于互信息和左右熵的短语合成,二者结合后就可以构造出基本的模式,通过模式匹配结合搜索引擎的计算能力,这就是目前9点的问题发现方案。在线demo已经完成,体验demo如下:
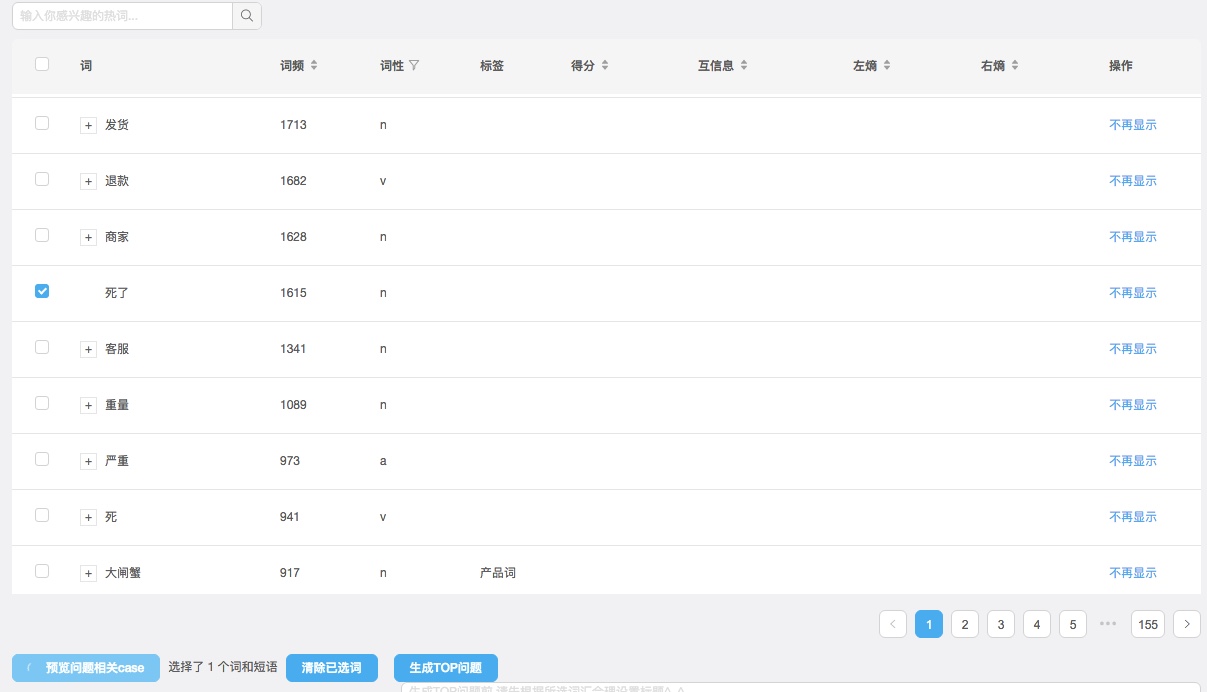
附上地址:9点直播间问题管理
总结:
对比划分聚类和LDA,基于文本统计分析的方法有这么几个优势:1,可以发现新的短语和问题。由于划分聚类和LDA需要先验知识(k值的确定),因此对于问题的分析需要通过已有的标注(比如维权原因)来确定问题可能的种类数,再进行计算。而短语发现是基于统计量的监控,会自动发现新词和短语。2,配合近实时数据源,可以很好的契合直播间这类需求。LDA和聚类的方法换个角度也可以通过一些trick完成自动发现,但是需要面临着更大的计算量来选择k值,因此面临着计算灾难和实时性的问题。而对于完全无监督无先验的文本统计量方法,则可以自动浮现主题,配合监控和人工结合的方法做到半自动的问题发现。
未来进化
我们做的实验并不想说明方法的优劣(另外本身在不同的算法上需要及可能优化的点非常多),我也相信技术的殊途同归,方法上的差异一定是可以做到趋同的效果。但是如何结合业务场景,如何拆分工程步骤,如何降低成本,如何适应业务的不同阶段,这是技术在选型和实现上需要思考的重点。
目前问题发现的方案仍然有很多待优化点。比如自动生成问题描述、自动生成query模式、语义理解和分析的知识图谱等等。也欢迎感兴趣的同学一起来讨论并参与到我们的实验中来。
