@changedi
2019-01-10T12:53:41.000000Z
字数 1226
阅读 2550
Hive架构
Hive
概念
按照官网翻译,Hive是一个使用SQL管理和使用基于分布式存储的数据集的数据仓库工具软件。注意形容词知道了几个特点:
1. 使用SQL
2. 数据仓库、管理数据集(表)
3. 基于Hadoop
Hive的组件包括HCatalog和WebHCat。
- HCatalog是Hadoop的表和存储管理层,它使具有不同数据处理工具(包括Pig和MapReduce)的用户能够更轻松地在网格上读写数据。
- WebHCat提供了一种服务,可用于运行Hadoop MapReduce(或YARN),Pig,Hive作业。还可以使用HTTP(REST样式)接口执行Hive元数据操作。
架构
照例先说下架构图
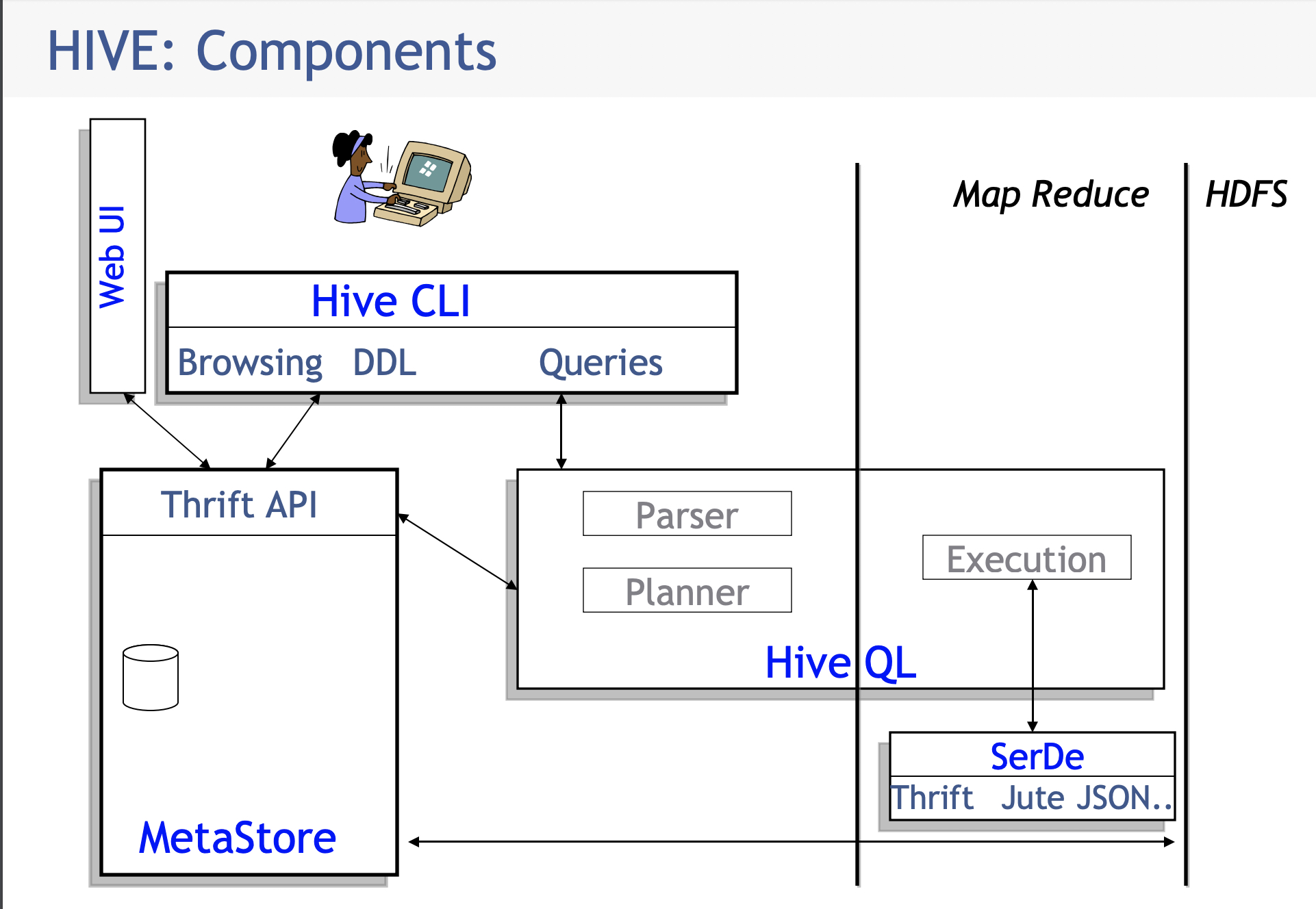
这里可以看到非常明确的组件关系。数据以文件形式存储在HDFS,执行期间用户通过cli提交DDL 或者query SQL,DDL会与MetaStore交互,其中MetaStore负责存储所有表信息(meta),二querySQL会提交给Hive QL来做执行,这个通用数据库都包含这样的模块。其中包含sql解析,执行计划生成和MR执行,会将sql以MR来执行。
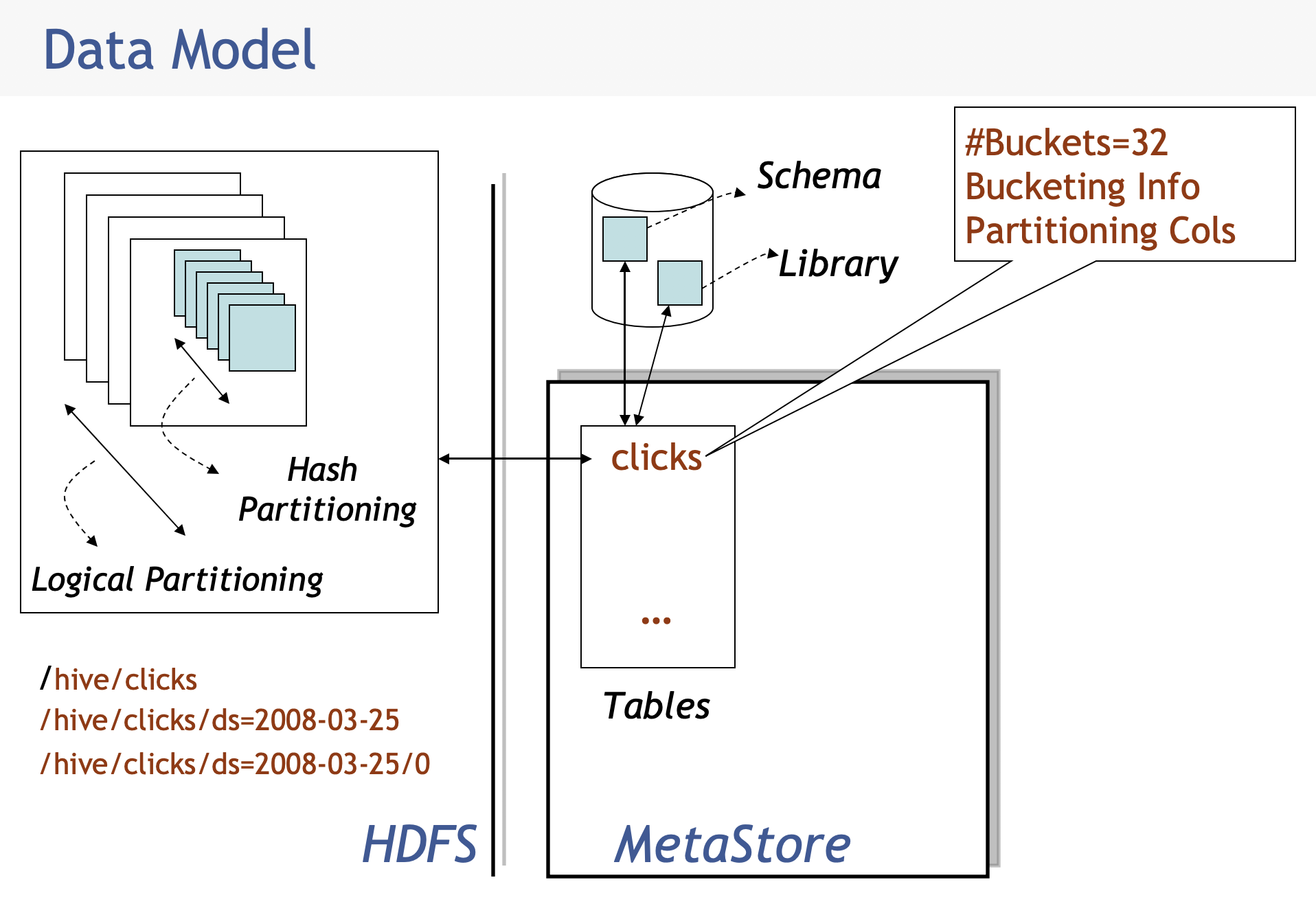
MetaStore
MetaStore负责存储所有的表schema和SerDe库,还有表的HDFS地址等。Hive的表是以HDFS的文件存储的,数据模型如下:
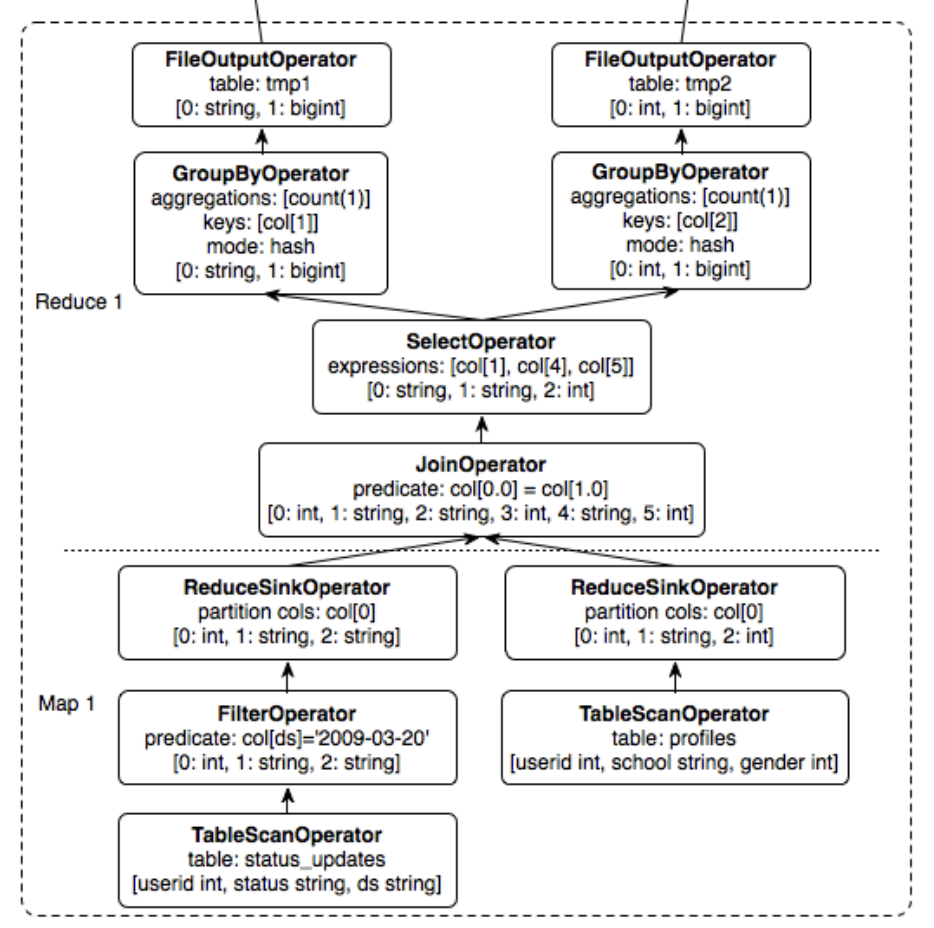
执行
通常的sql引擎执行sql的能力其实没有太多的要说的,hive会将sql解析为一个执行计划来执行MapReduce,比如对于一个sql
select a,count(1) from t where c=1 group by a;
Hive会将其转换为一个执行计划比如下图:
调优
因为本质上是分布式MapReduce模式,因此在写Hive SQL时,我们要了解不同表的数据量和数据分布,在group by聚合以及join操作时避免倾斜。Hive本身LanguageManuel[6]中有对于Join Optimization的介绍,包括了MapJoin的hint以及SMB join优化等。而阿里的ODPS(MaxCompute)服务也在2018年推出了Hash Clustering 和 Range Clustering特性。
总结
这是一篇非常简略的笔记,因为本身hive就很简单,但是具体数仓ETL研发过程中的变化和策略是非常多的。开篇后,希望后续有持续的积累和记录。
图片和内容引用
[4] https://www.slideshare.net/athusoo/hive-apachecon-2008-presentation?from_action=save
[5] https://www.slideshare.net/namit_jain/hive-demo-paper-at-vldb-2009
[6] https://cwiki.apache.org/confluence/display/Hive/LanguageManual
