@qinyun
2018-05-14T06:42:05.000000Z
字数 4503
阅读 2441
苏宁Nodejs性能优化实战
未分类
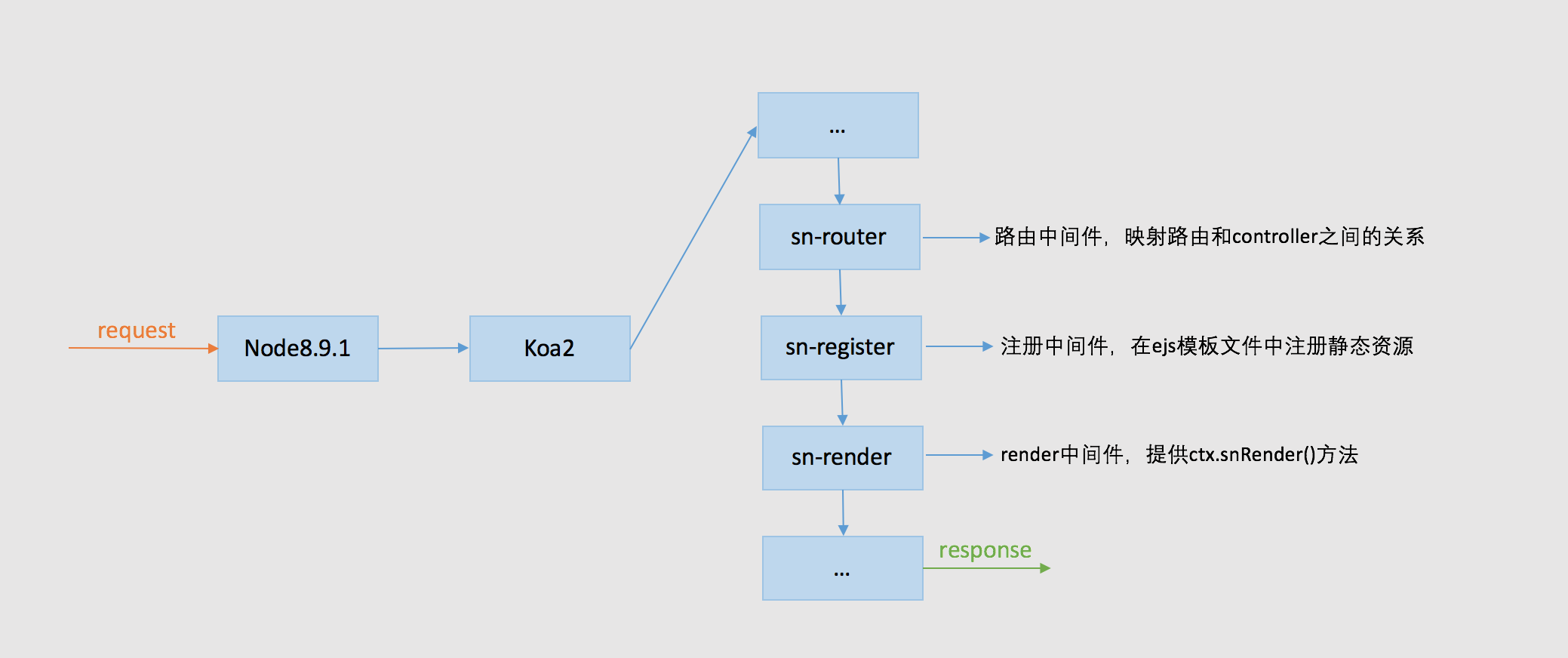
Nodejs项目背景介绍
自2016年以来,苏宁大规模的使用了基于Nodejs渲染的项目,架构使用Nginx+Nodejs+PM2组合,其中Nodejs版本从最初的6.0+升级到如今的8.0+,Nodejs框架从Express过度到Koa2,而Nodejs的性能优化作为其中的核心,性能提升,从0到1,开始摸索。
初步优化—css、js注册与合并
ejs模板相关优化
在苏宁的nodejs项目中,刚开始使用express框架,后来随着node.js 8.0 LTS版本的发布,又开始使用kos框架。无论是express还是koa框架,苏宁在项目开发中都使用ejs模板语言(关于ejs模板语言这里就不多做介绍,有兴趣的同学可以自行搜索)。
合并css和js带来的性能损失
在使用ejs模板过程中,苏宁把公共部分抽出来为layout.ejs文件,页面模板通过ejs include方法在layout.ejs引入,例如:
//layout.ejs<link type="text/css" rel="stylesheet" href="public.css" /><script src="public.js"></script>...include(page1);...//page1.ejs<link type="text/css" rel="stylesheet" href="page1.css" /><script src="page1.js"></script><h1>hello</h1>
这样做解决了公共部分与页面业务逻辑的分离,但是也带来另一个问题--layout模板和page1模板中静态资源标签位置的问题,以下是渲染过后返回给客户端的html页面:
...<link type="text/css" rel="stylesheet" href="public.css" /><script src="public.js"></script></header><body><div class="header"></div><link type="text/css" rel="stylesheet" href="page1.css" /><script src="page1.js"></script><h1>hello</h1></body>...
我们可以看到page1的静态资源引用标签都在body内,复杂的页面可能还会有page2、page3、pageN...这样会有大量的静态资源引用标签出现在body内,这显然不符合我们的预期,我们需要控制静态资源标签在页面中的调用位置,为了解决上面的问题,苏宁引入了ejs模板静态资源register机制,其注册步骤如下:
a.使用getResource()方法输出占位符。
b. 使用register()注册方法注册资源,例如:register('a.css', 'b.js')。
c. 将注册的静态资源处理合并后进行字符串replace操作。
使用register方法后ejs模板渲染过后的html页面如下:
...{{{CSS_PLACEHOLDER}}}</header><body><div class="header"></div><h1>hello</h1></body>{{{JS_PLACEHOLDER}}}...
"{{{CSS_PLACEHOLDER}}}","{{{JS_PLACEHOLDER}}}"就是getResource()输出的占位符,在服务器response之前进行字符串replace操作,将占位符替换成register()方法中注册的路径:
...<link type="text/css" rel="stylesheet" href="public.css" /><link type="text/css" rel="stylesheet" href="page1.css" /></header><body><div class="header"></div><h1>hello</h1></body><script src="public.js"></script><script src="page1.js"></script>...
这样就符合了正常的页面静态资源引入位置,同时苏宁在register()方法做路径合并的功能,合并后的地址路径如下:
…<link type="text/css" rel="stylesheet" href="public.css,page1.css " /></header><body><div class="header"></div><h1>hello</h1></body><script src="public.js, page1.js "></script>...
这样浏览器中发起的请求就会少很多,减少页面请求也是性能优化的一个点。
缓存机制
使用register机制后我们又发现了一个问题,当客户端每一个request请求发起,nodejs服务在响应之前都会进行字符串查找替换, 如果页面够复杂,最终渲染生成的字符串足够大,每一次进行字符串查找替换的过程中也造成了一定的性能损耗。正常在实际的使用中我们多次访问一个路由地址,其页面引用的静态资源并不会发生变化。利用这个特性苏宁引入了静态资源缓存机制。
当一个新的页面请求进来之后,在执行register方法之前,会根据页面请求地址的pathname进行缓存查找,如果命中缓存,则getResource()直接返回缓存内容,相应的regsiter方法也不会去执行。否则执行register()流程。引入缓存机制后,非第一次访问代码逻辑中少了注册、替换流程,相应的页面响应时间也缩短了,经过多次测试,页面响应时间大概缩短4-8ms。
进阶优化—大量路由的优化匹配
在开发苏宁易购香港站过程当中,由于整站页面较多、参数开发人员众多及基于项目安全性的考虑,项目开发中配置了多达173条静态路由以及11条动态路由,所以路由匹配效率明显下降。究其原因,得从express源码入手,express框架在处理路由配置的方法是,将每一条配置信息转换成一条正则表达式,在请求进入的时候,逐条进行匹配,直到匹配成功为止。

对于动态路由——路由中含有模糊匹配,则必须使用正则表达式来进行匹配,无法优化。而对于静态路由,就是固定的字符串的路由表达式,则可以通过键值对映射进行匹配,复杂度从O(n) 变成了O(1) 大大缩短匹配时间,且不会随着路由增加而耗时加长。在实际代码中,由于架构采用了集中路由配置,所以很方便的从配置文件里面就筛选出了静态路由,然后存放在一个Object中(HashMap)。然后形成一个中间件形式,相当于把多条路由中间件变成了一条路由中间件。
缺陷:和原来的逻辑相比,优化后的方案缺少了路由匹配的顺序,所以在开发的时候需要额外注意,不过总体来说影响甚微,因为静态路由优先匹配,也是应该优先响应的。
高阶优化—TPS的提升
在苏宁易购大聚惠系统的前后端分离中,初次提交压力测试结果非常差。怀疑有什么配置没有配好,当时的数据是这样的(16台4C4G)
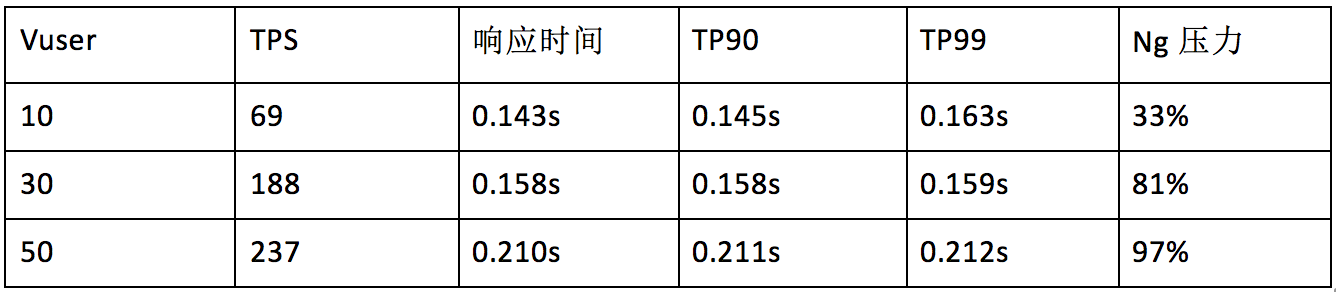
TPS低的不能忍,而且当时已经配备了Node.js 8.9.1这个版本,理论上绝不可能那么差,在观察代码,也没有发现特别消耗性能的地方。最后我们找到了原因,在ejs模版配置的时候没有开启模版缓存导致。如果不开启模版缓存那么每次请求渲染的时候,都会从磁盘中读取本地模版文件进行操作,这个磁盘读取的动作消耗了很多CPU。平时使用不会察觉,只有当压力测试的时候才会体现出来。设置好了参数后,我们得到了10倍的性能提升。
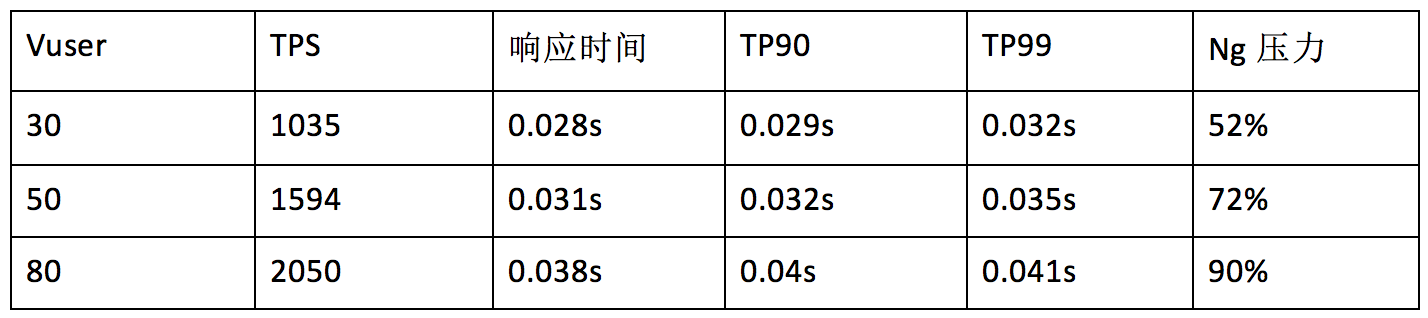
但我们的优化并没有止步于此,我们定的目标是3000TPS,也就是还需要再提高50%的渲染性能。这时候我们就必须找到影响nodejs性能的点。Nodejs的特点是单线程异步编程,意味着异步操作对性能的影响不大,而同步操作则会严重影响性能。
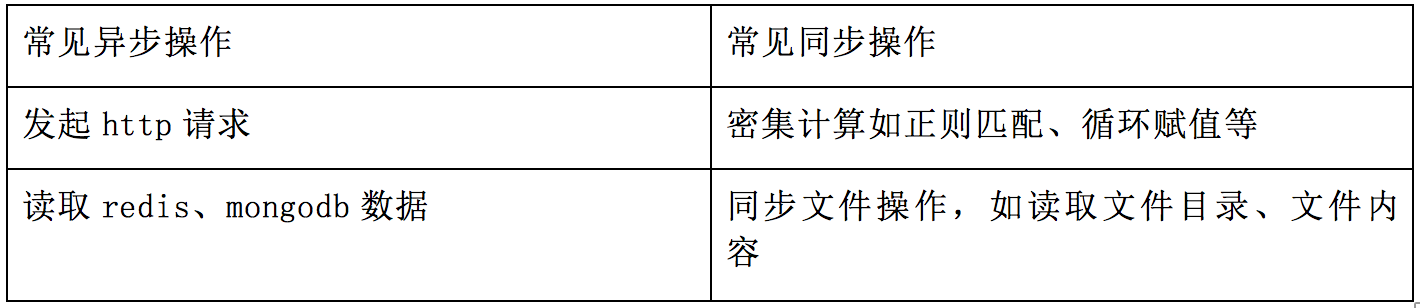
所以第一步,是先检查代码中同步操作的逻辑,是否有消耗CPU的代码。经过检查,排除了代码部分的嫌疑。只好借助chrome提供的devtools来进行分析,启动node参数—inspect,打开chrome的devtools插件就可以通过CPU profile进行分析了。排除掉不可避免的CPU消耗,问题浮出水面,原来还有一部分的CPU消耗来自于ejs模版引擎的内部。

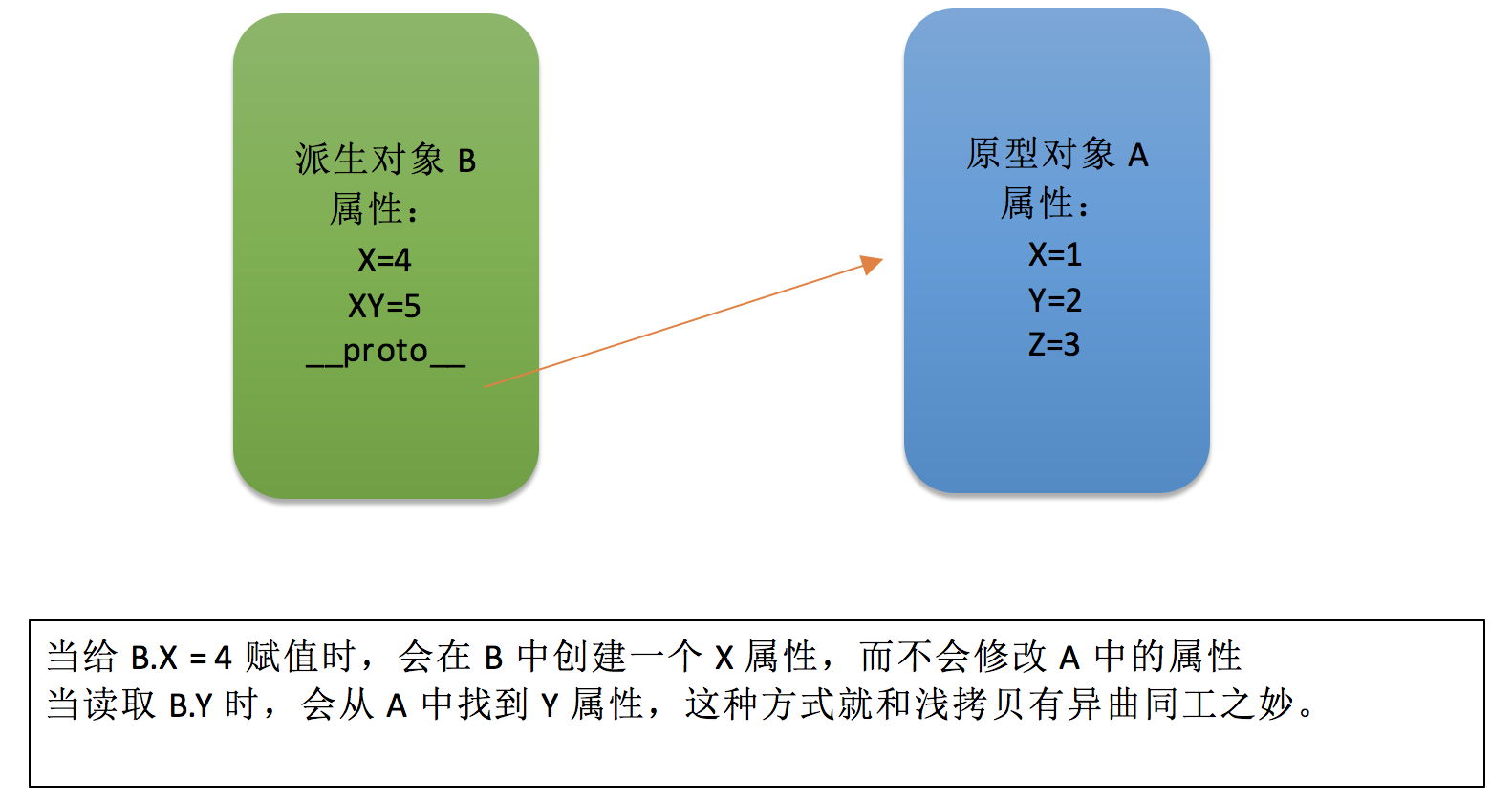
从图中可以看出来有两部分消耗,一部分是来自ejs模版引擎内部的浅拷贝,一部分是来自查找文件是否存在的系统命令。由于大聚会系统的ejs里面大量使用include,导致了这部分消耗凸显了出来。打开ejs引擎源码查看,发现虽然缓存了模版,但每次include函数依然会去执行fs.exsitSync函数。找到罪魁祸首以后,修改起来其实很简单,在执行改函数的判断条件里面加上先判断缓存中是否存在。修改后这部分消耗减少了不少。浅拷贝的问题,通过js的原型链解决,将传入的数据对象作为原型对象,通过Object.create函数构造一个派生对象,实现原来浅拷贝达到的目的(模版内部修改对象属性不会影响原始对象,防止污染原始对象传入到其他模版中去)。派生对象修改属性,并不会修改原型中对象的属性,只会在派生对象中新建一个同名的属性,所以不会污染原始对象。新增属性也只会在派生对象中。这一步优化减少了很多赋值操作。
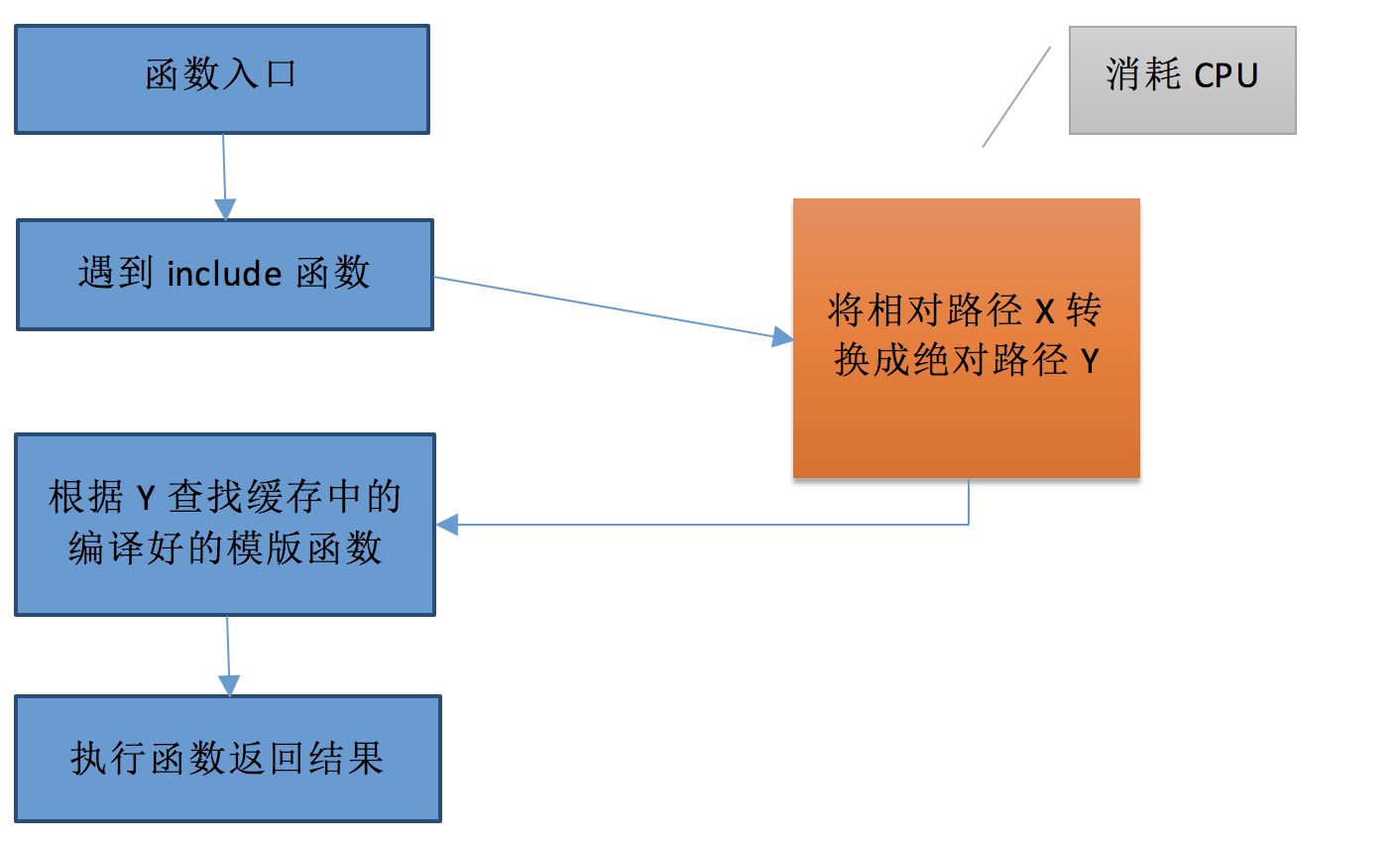
经过以上的优化,再进行CPU profile分析,发现在ejs引擎内部依然有一个函数在消耗CPU,那就是getIncludePath。这个函数的目的是在执行include 的时候讲传入的相对路径转成绝对路径,目的是防止嵌套的include中传入相同的相对路径字符串,却是代表不同的模版文件。但是在转换成绝对路径这一步里面会调用文件系统函数造成CPU消耗。解决的思路很快就出来了,就是需要讲相对路径映射成绝对路径,然后缓存起来,这样就不必每次去计算绝对路径了。当然这个缓存不能是全局的,必须每一个include创建一个缓存,这样才能避免相同的相对路径有歧义的问题。
原始逻辑:
优化的逻辑:
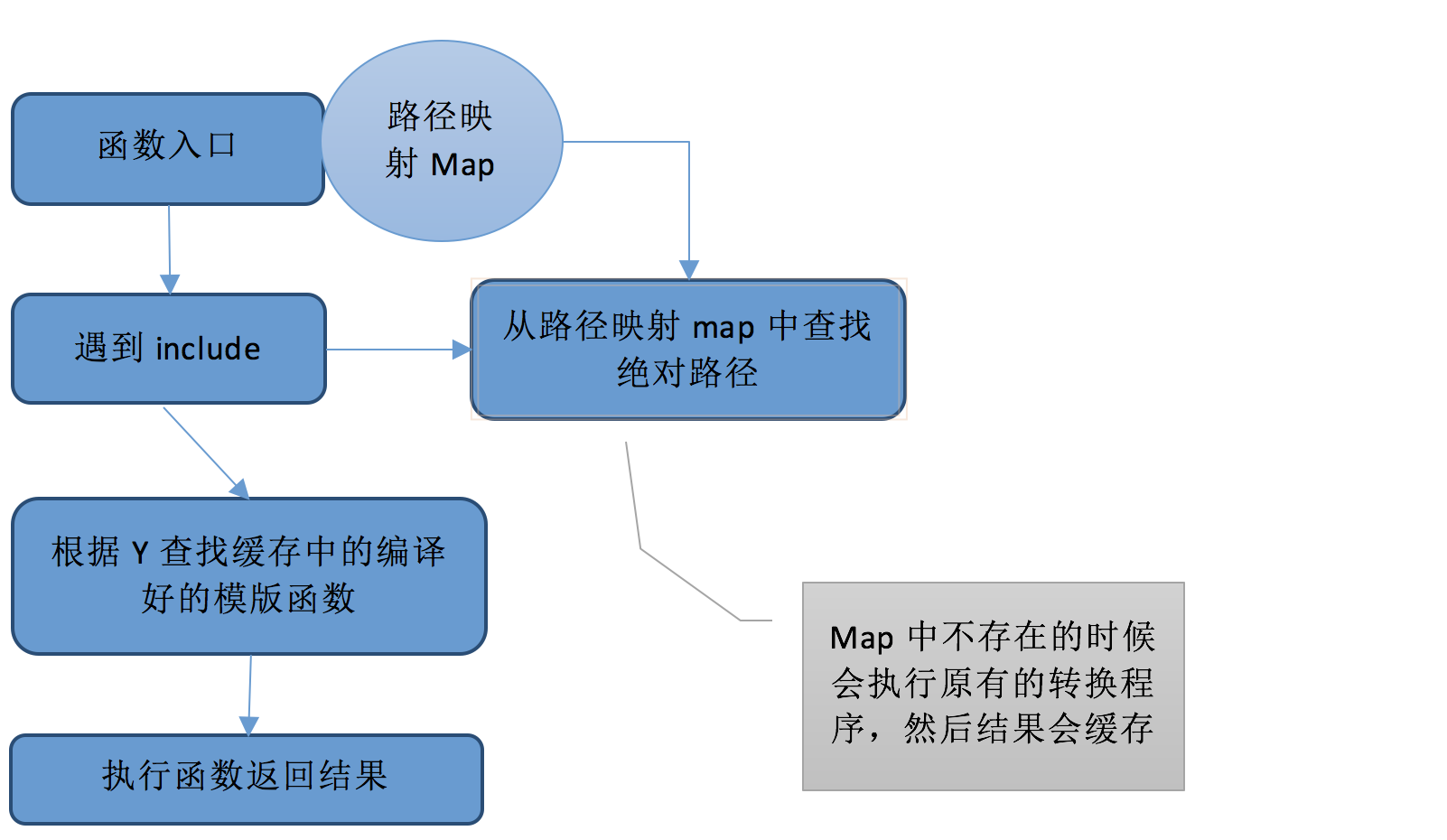
说明:路径映射Map是一个定义在模版函数所在作用域上的,只有该模版函数内部能访问到,每次执行模版函数的时候都会拥有一个独立的Map。
经过上述优化后,本地进行压测有50%的性能提升,故提交测试组对大聚会进行线上压测。
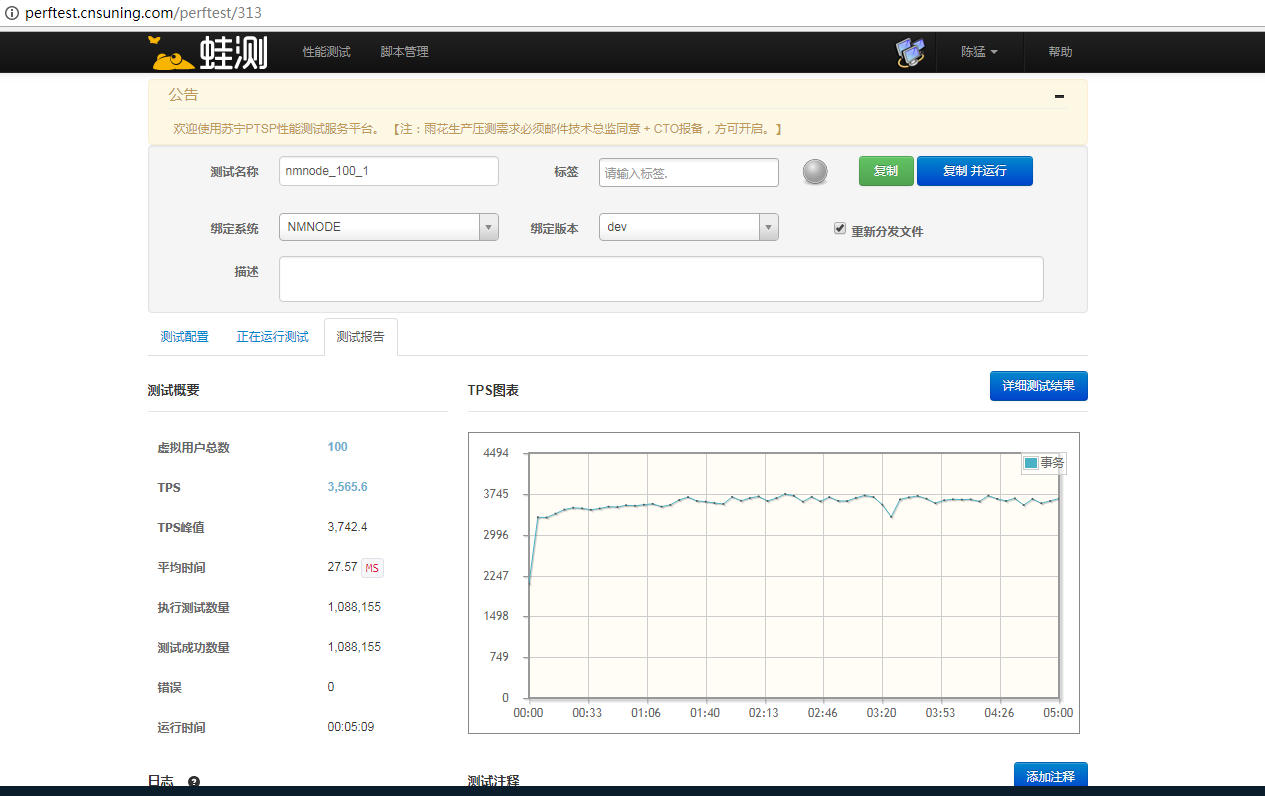
压测结果非常好,从2000tps到了3500多,提升了75%之多。单台机器大约220tps左右,而原java系统单台大概150tps左右。
总结
Nodejs系统的性能优势主要体现在异步IO上面,所以性能瓶颈基本都是出在同步操作上面,那么优化也是主要尽量减少同步操作,适当使用一些js的技巧,另外npm包的开源特点也给优化工作带来了便利。
作者介绍
李浩,苏宁易购高级前端技术经理,主要负责苏宁前后端分离nodejs项目开发。具有多年的web前端从业经历,曾任途牛金服前端负责人。热爱前端,对新技术有学习热情,在nodejs前后端分离、koa等框架方面有独特的见解和丰富的项目实践。
