@qinyun
2019-03-08T02:38:35.000000Z
字数 5468
阅读 2155
北大直播
未分类
今天的主题是自然语言与多模态交互的一些前沿技术,下面我会进行一些具体的展示。
深度学习带来AI的新突破
回到很多年前,大概在70年代,深度学习就是神经网络感知机,多年以后,它可以任意分解成任意形状,因为它拥有非常强的分类能力。80年代,整个学术界,包括技术界对神经网络期望是非常高的,但是很快在90年代的时候,大家发现神经网络由于各种原因,如数据不足,训练很困难,很多工作做的不如简单的模型好,大家对它的期望就降下来了,只是在这个低谷时期,还是有科学家坚持把这个领域往前推动。
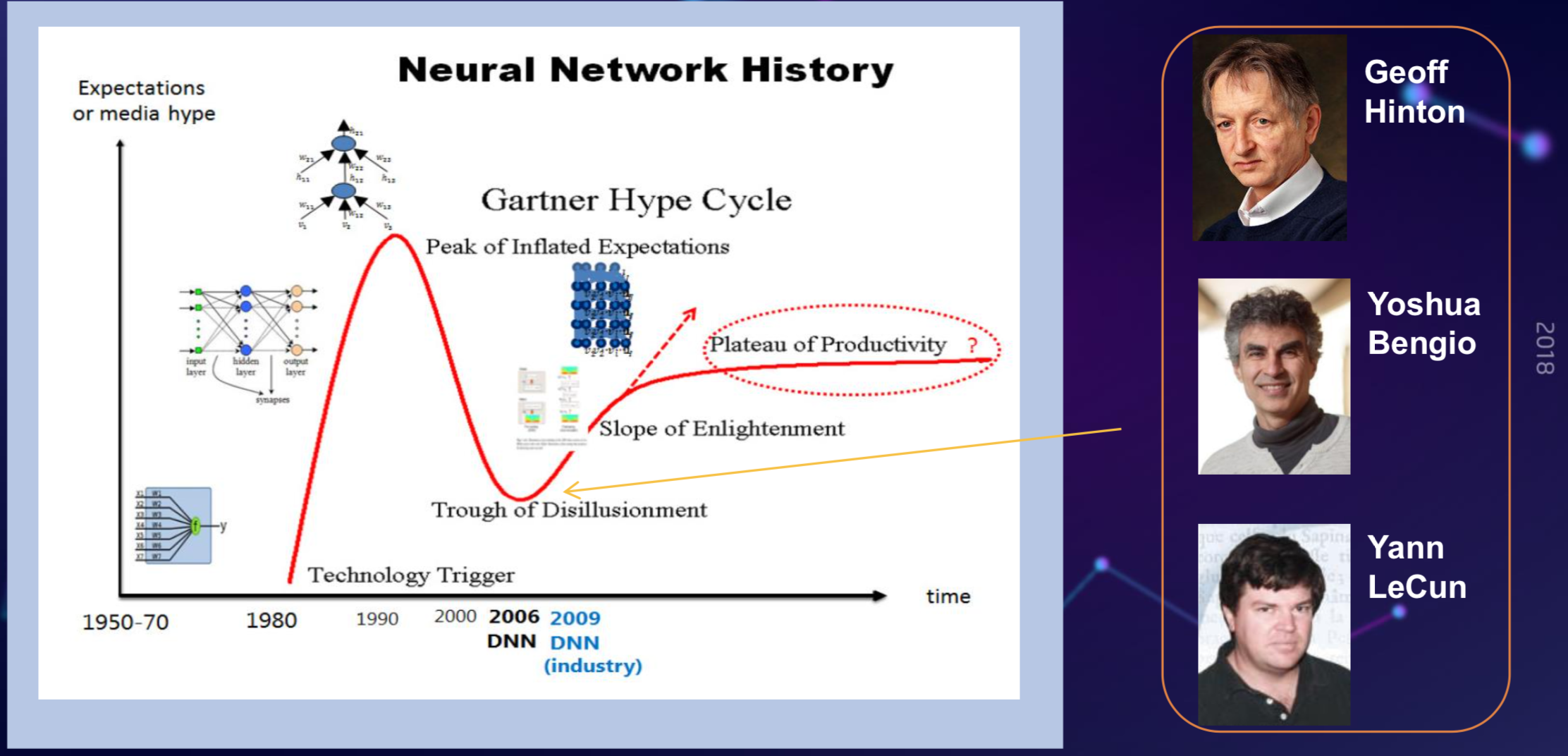
2006年以后,IBM分层训练开始能够使深层的神经网络成为可能,在09年,微软在大规模的语音识别上取得进展,大家重新对深度神经网络产生信心,从那时候开始,大家开始推进对深度神经网络的研究。此后,基于深度学习新的突破,带来了很多AI方面的突破,还有产业上的突破,特别是为产业提供了大量的计算力量,提供了真实的场景。
语音识别
在语音识别上,会看到深度学习一个非常明显的影响力。这个图大概是过去几十年,语音识别核心领域的进展,语音识别是个非常经典的人工智能的问题。
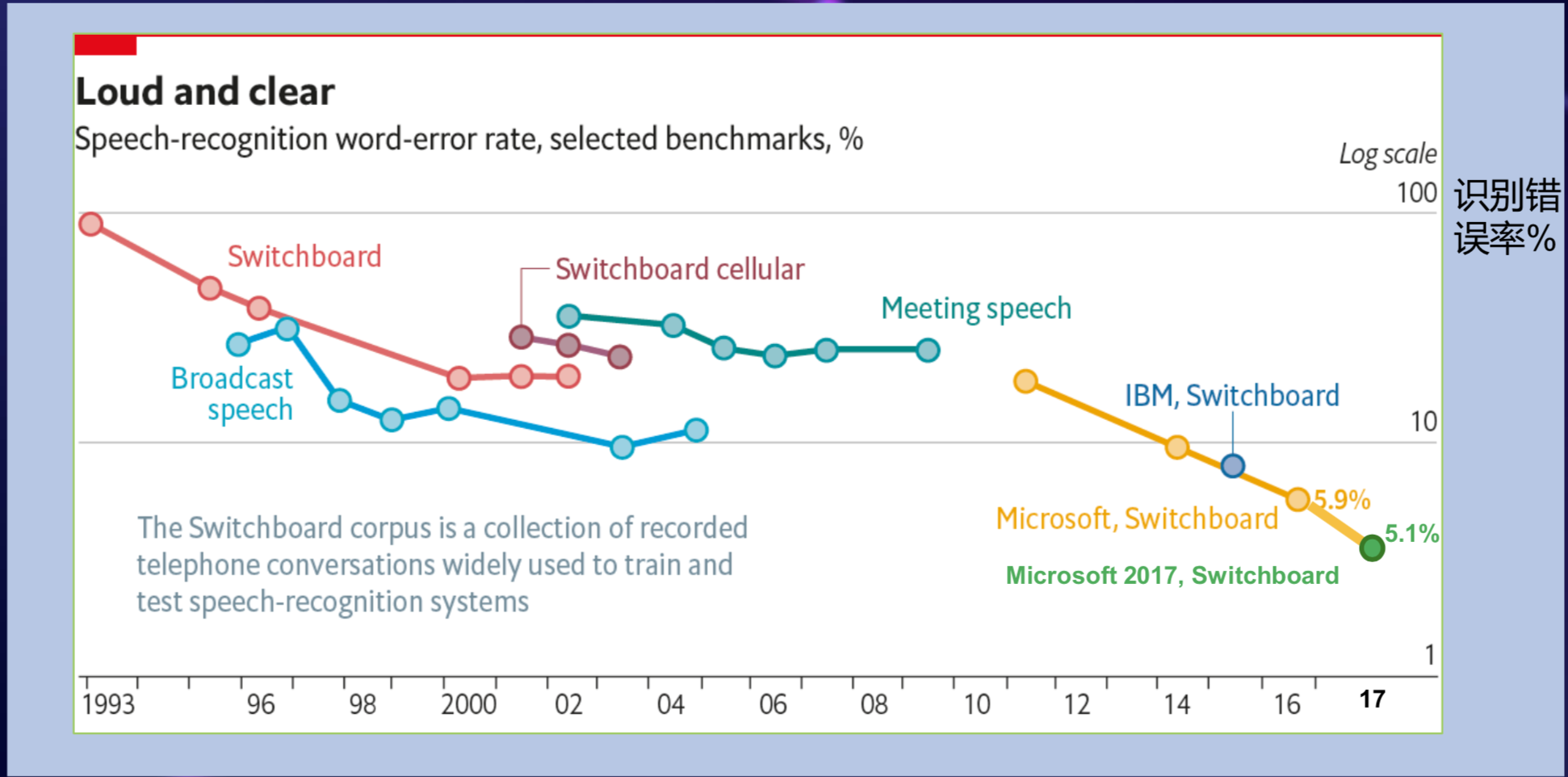
从90年代初到2000年,语音识别的错误率很难在数据集上以倍数下降,从2000年到2010年之间,研究员做了很多工作,比如说做区别性训练,做测试,但是始终没有得到一个特别好的突破,这十年大概可以认为语音识别的技术是停顿的,一直到2010年,微软研究院将学术界的思想和工业界大规模的数据及核心问题结合在一起,开始走出一些小的模型,得到了很多新的突破。
2010年底,深度学习在语音识别核心问题上得到了20%到30%的增长,此后,语音识别错误率迅速往下降,最近降到了5%左右。
在过去几年,我们见证了之前想象不到的一些技术的进步,比如语音翻译,在之前,我们认为语音翻译是基本不可能的语义,因为语义识别错误率很高,翻译错误率也很高,但现在很多大厂都开始有了同传翻译的产品了,这都得益于深度学习的进展。
图像识别
在过去几年,基于深度学习的进步,图像识别也取得极大的成功,比如在2015年,提出了一个数据库,解决了一千类的物体识别问题,但是在那时候,错误率仍然高达25%。
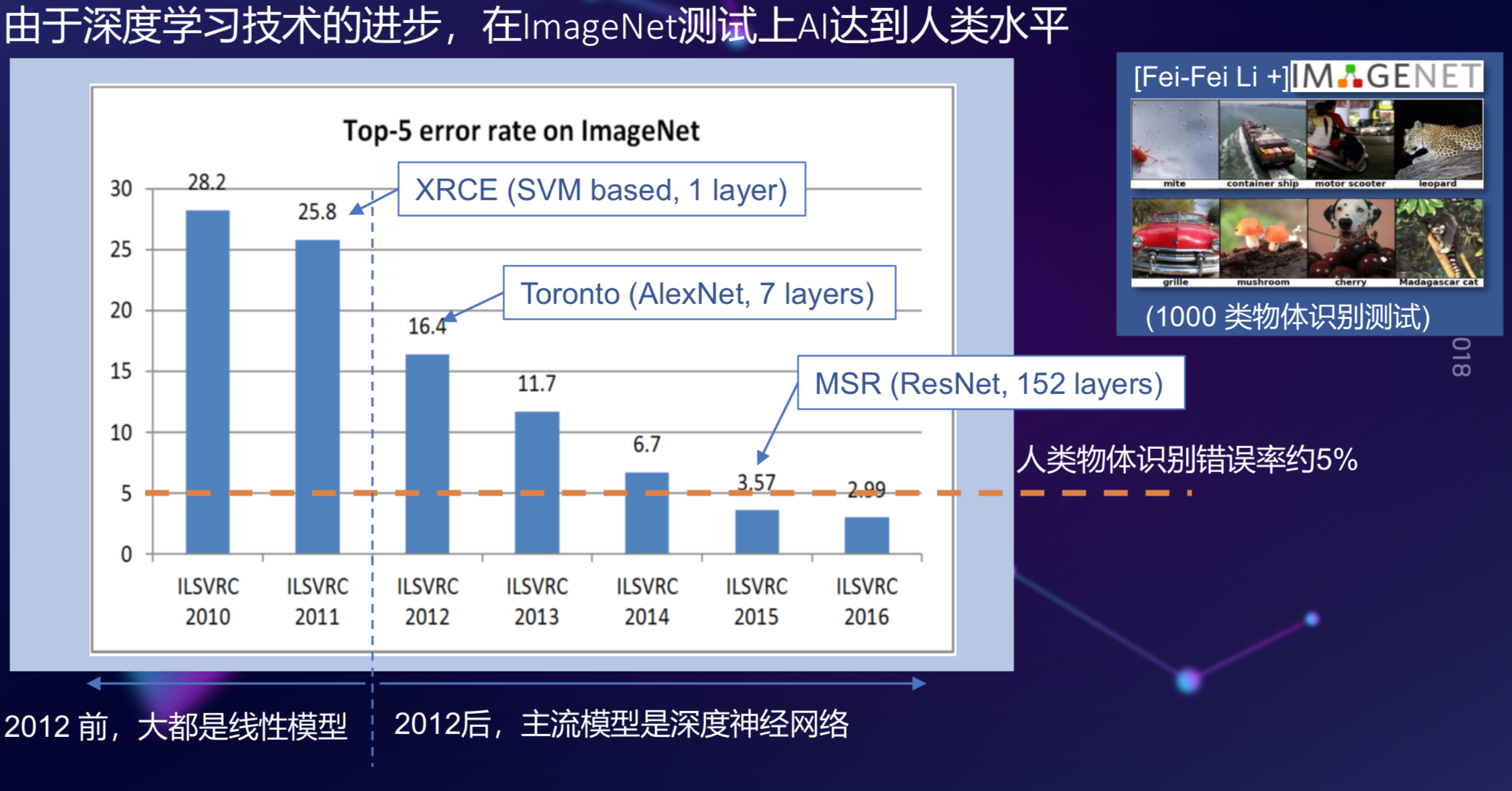
2012年,因特和他的学生提出用一个7层的深度卷积神经网络做一个任务,一下子把错误率从25%降到16%,当时数据刚刚出来的时候,很多研究员都认为这个数据是不真实的,训练集和测试集在中间过程很可能被污染了,经过仔细检查,发现这个数据就是真实的结果,此后,这个错误率每年降30%左右,一直持续到2015年,这个数据集的错误率降到了3.57%,这是什么概念?让一个学生去做这个测试,一般人眼不会百分之百对,人往往会很多错误,它的错误率在5%左右,你可以认为,在2015年,基于深度学习的图像识别已经超过了人的水平。
自然语言处理
下面我们说到自然语言处理,我个人认为AI突破最难的方向是自然语言理解,语言是人类特有的智能,我们知道,很多高等动物也能把视觉和听觉做得很好,但是语言是人类独有的高级智能。
自然语言处理大概分为两类,一是让AI理解人类,人和人是通过自然语言交流的,我们希望AI系统能够理解我们的意图,解析我们的语义,甚至从文字中看到我们的情绪,能够做些推荐搜索上的工作。
另外一大类是让AI能被人类理解,也就是让计算机生成文本、生成内容,这是比理解内容更加难的问题。在过去几年,新的深度学习模型的进步,越来越多的工作放在这方面,怎么样让AI能够生成人类的自然语言,比如说生成摘要,生成新的内容,生成崭新的话题,甚至生成带有情感的对话,在过去几年发展得非常快。
未来的突破口在哪里?
回顾这几年的发展之后,我想再展望一下未来几年NLP可能突破的一些方向。
经过很多年的努力,机器翻译获得了很大的进步,现在我们经常问下一个突破口在什么地方?我认为在以下几个方面:
多模态智能,综合文字、语音、图像、知识图谱等信息来获取智能;
复杂内容的创作,比如人工智能写作长文章;
情感智能,不只识别人的情感,还能像人一样表达情感和风格;
多轮人机对话,理解语境、常识、语言,生成逻辑严谨的有情感的对话 服务于人。
下文中我们将用实例来解释这几点。
多模态智能
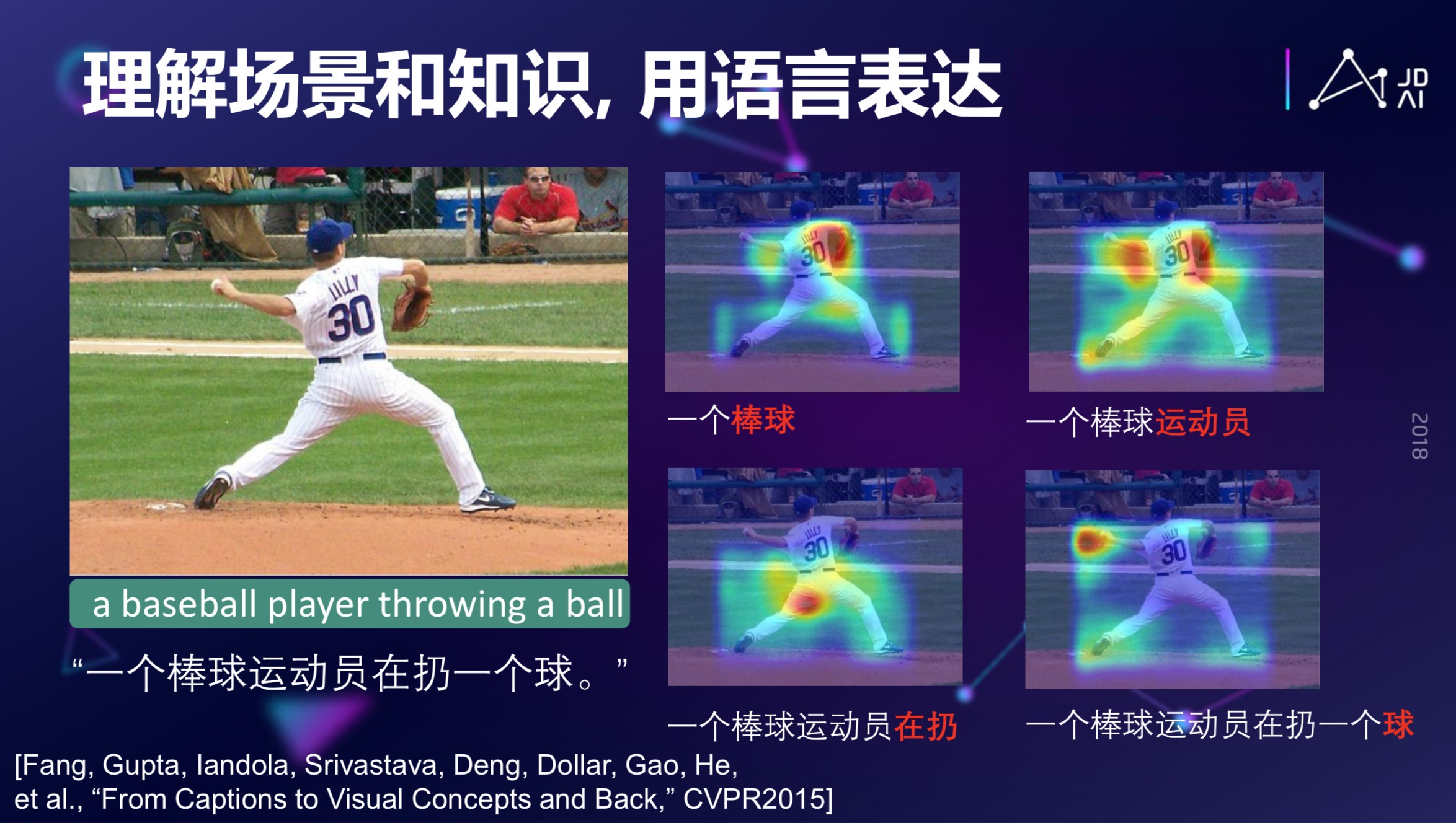
如果我们用深度学习来看上图,会生成这么一句话:一个棒球运动员在扔一个球。为什么会生成这么一句话?比如,当我们发现模型生成这个棒球的时候,它实际上是注意力集中在棒球手套这个地方,这是一个特征,就是证明这是一个棒球运动。当计算机注意到这些动作的时候,它会提出这是个运动员。再往下,当计算机AI模型注意到一个大腿扭曲的姿态的时候,它会提出这是一个人的动作,凭这些,计算机会认为这是一个人扔球的动作,虽然这个球的占的整面积非常小,但是因为这个语言模型有一个强烈地完成这个语义的驱动,使得这个球也能够被识别出来,最后形成一句完整的有意义的话。这就是从图片到文本描述生成的过程。
那么,是否可以反过来?说一句话,能不能生成一个图片?比如你想生成这么一句话:一只红羽毛白肚子的短咀小鸟,如果把这个作为输入,我们能不能生成相应的图片?答案是可以的。
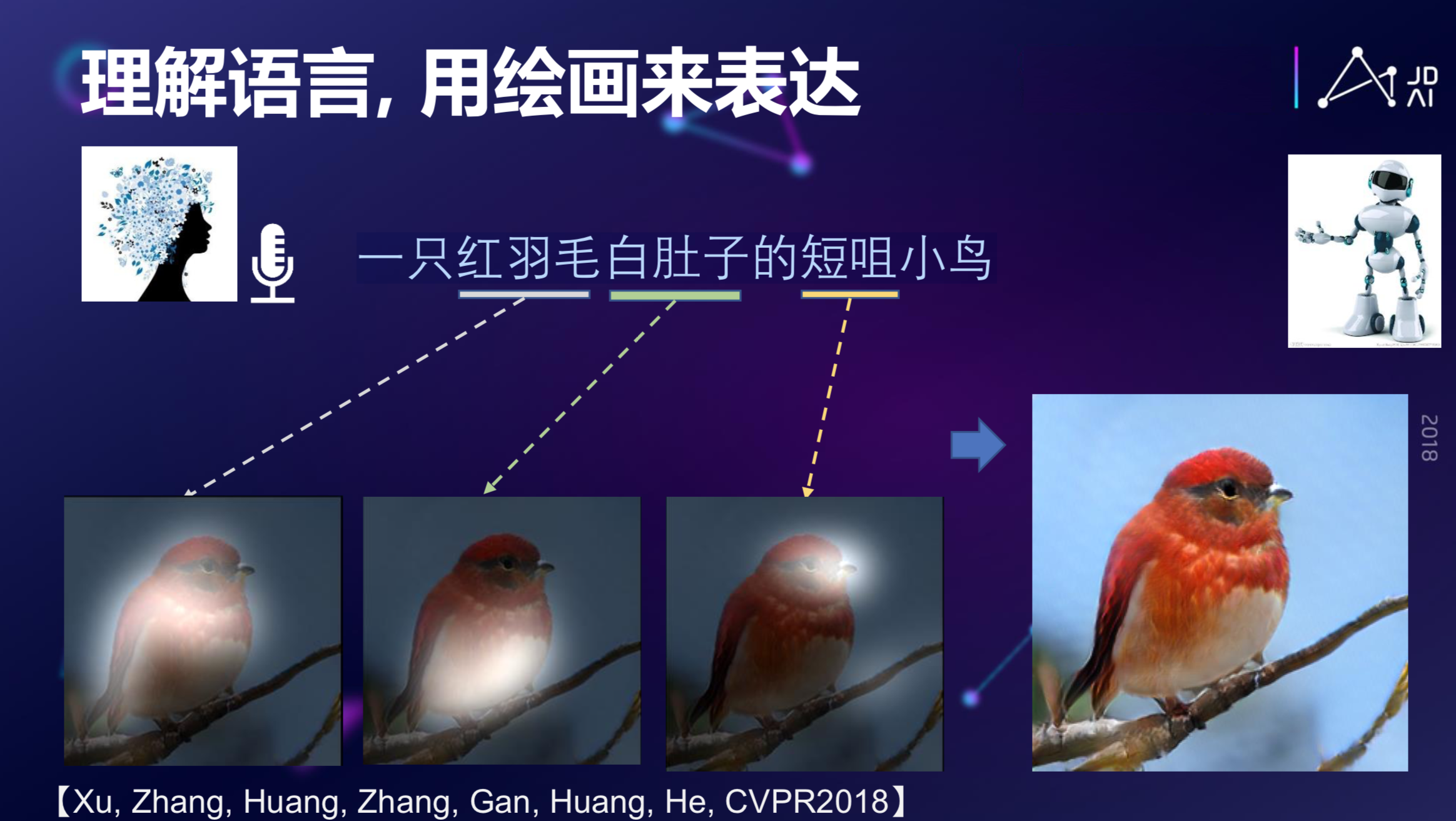
这是完全从无到有的生成,它创造了一个图像,这只鸟也许在这个世界上根本就不存在。这是最近发展很迅速的一个领域,也是跨模态语言和视觉模态的共同推理的模型。当然,它也可以做更多其他的有趣的事情,我们在这里就不一一举例了。

上面是从图片到文字,文字到图片的实例,那么还有一种情况:在图片和文字之间做一些推理和综合问答。

如果你问AI系统,上图中两把蓝色的椅子之间是什么东西?最后它会告诉你,这是一把伞。模型的实现过程是:第一步,有一个question model,先在语言上理解这个问题是什么,同时需要有一个Image Model,对这个图片本身做一些理解,同时还有更重要的multi-level attention model,就是负责在图片的信息和文字信息之间做多层attention的推理,最后得到这个答案,这称为视觉-语言多模态推理问答。
现实中的Boston Dynamics机器人不但能做后空翻、跑步,听懂你的要求,并按照你的要求在房间里走来走去,到指定的地方,这里面就用了一个在视觉信号和语言理解联合的推理功能,得到语言和视觉多模态的导航,这也是多模态智能的应用。
创作长文
随着模型和数据越来越多,我们不再满足于AI模型只理解人类语言的意图,我们能够希望模型创作语言,比如怎么样创一些很长的文章、诗歌等其他文学作品。此时,我们需要推出一个新的模型,比如我们怎么样做一些顶层设计与规划,但现有的文本生成模型缺乏“规划”,我们应先产生初略的高层主题规划,然后再对主题和子主题展开成文。
人机对话
人机对话本身其实是最难的,我个人认为人机对话是人工智能皇冠上的一颗明珠,也是最难的一颗明珠。
回到当年图灵提出图灵测试时候,它就提到判断一个机器是不是有智能,可以通过人和机器之间的自然语言对话来做判断。人机对话发展到今天,其实已经发展出很多框架来了,从图灵在近60多年前提出这个问题以来,到今天其实已经是主流的方式了。
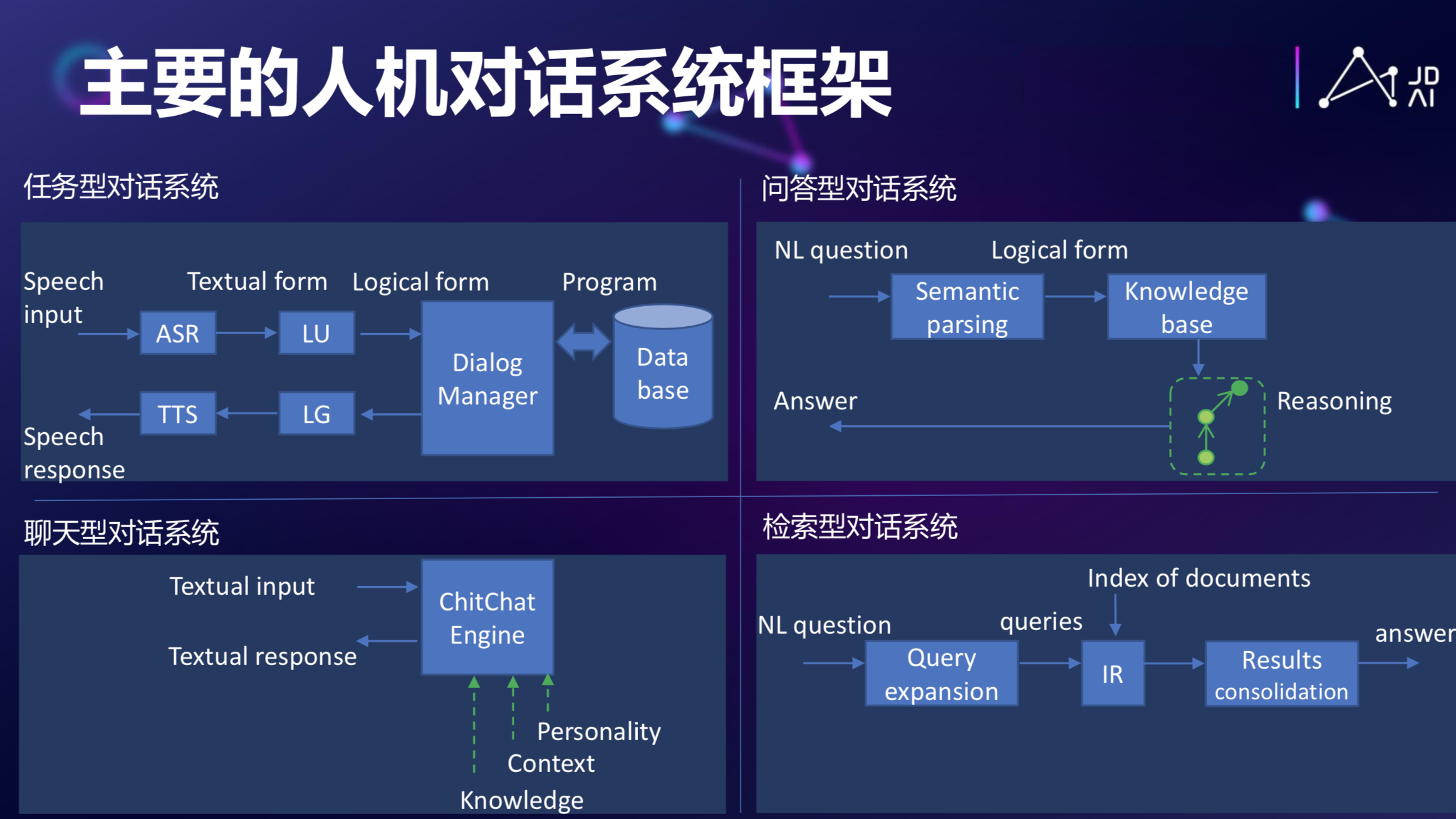
现在已经开始应用的有任务型的对话系统、基于知识图谱的问答式对话、聊天型的机器人,如Eliza、小冰,甚至可以认为百度本身就是一个对话系统,每次一输进去一个Request,它会给你一个document或者title作为它的response。
去年年初的时候,我们回顾了从最早的第一个机器人到小冰的一些进展,当时我们比较乐观,我们认为机器人一方面要满足任务的需求,另一方面希望能够对情感的做一些满足,如果这个趋势走下去,也许随后几年我们会看到越来越多的机器人,不管是虚拟的还是实体的,这些东西会成为我们生活的一部分。
AI产业化的下一个方向是什么?
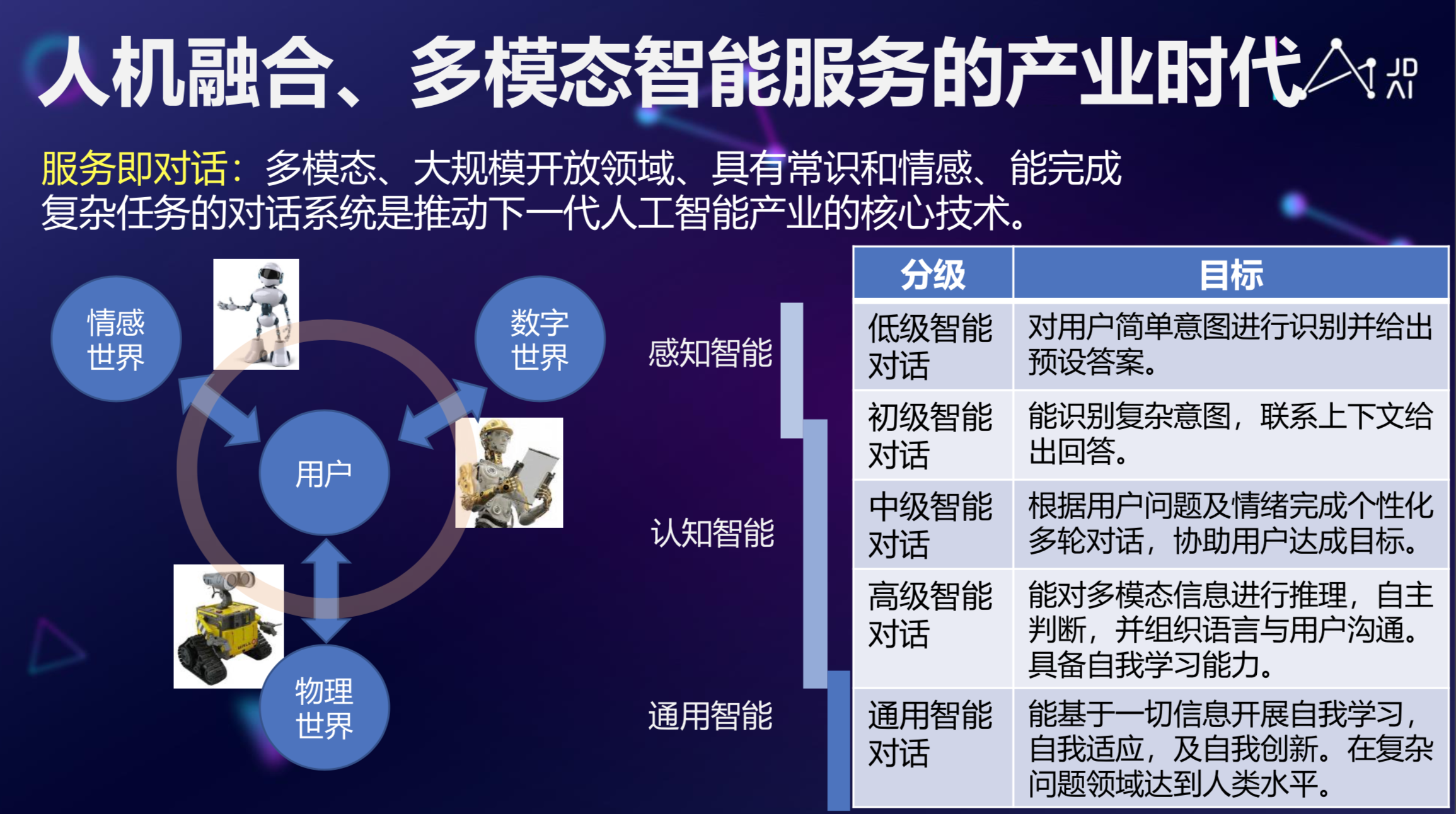
从AI角度来说,传统人力密集型产业,有广阔自动化、智能化空间,但随着这个AI技术、IOT技术的创新,各种各样的市场迅速成长,如2B的市场、2C的市场,多模态、具有常识和情感、能完成复杂任务的智能人机交互技术在整个智能服务产业还是有很大的市场和机会的。
总的来说,随着AI技术的发展,特别是人机对话、文本生成、情感智能技术的提升,我们开始逐渐进入到人机融合、多模态智能的产业时代,通过对话多模态大规模对话的技术,我们能够对数字世界,比如银行帐号、各种各样的数字资产进行管理,甚至还能通过情感多模态和物理世界进行情感交流,希望随着人工智能尤其是NLP和其他多模态智能的发展,我们可以真正做到人机融合。
问答时间
1、GPT2.0通过这种大规模的网络,机器学习十几亿的参数,然后还有使用,看到,NLP都有比较大的提升,根据这一块,能够专家看出来,比如说在这个方向呢,有很大的,我们叫做。
A:我个人对暴力美学不反感,能解决问题就是进步,算法很重要,算法是整个工作的核心,但是光有算法还不够,还需很多锻炼、学习,AI是跟产业界是紧密结合的,有大量的数据,有训练的算力,虽然听起来很冒险,但绝对是好事情,它把整个门槛降低了。
另一方面,我想强调的算法还是很重要,虽然我们看到这个暴力求解,大量的数据,大量的计算,算法还是很重要,因为算法是灵魂,举个例子,为什么深度学习能起来?深度学习需要足够的的这个容量,使的算法能够起来,随着这个数据的成长,随着这个算力的成长,算法模型才能充分利用算力和数据带来的好处。如果是传统的这个线型模型,你就是给它再多的数据,GPU,线性模型也没办法take the benifit,所以我认为算法是灵魂,但算力和这个数据是长大的物质基础。
2、我们看到这个模型越大,数据越多,这个效果越好,我们现在有一个模型,如果我们50亿,500亿时候,会不会能实现这个,如果能实现,在哪些方面?
A:这是另外一个有趣的问题,刚才,是在那个,随着这个任务越来越复杂,这个任务本身是一个符合爆炸式的任务,比如说只做义图识别的话,如果识别的话,你定义10个义图,和一百个意图,就是一百个,如果你开始生成整个文章的时候,它的组合很多,你不可能所有的组合,换句话说,只有作为黑盒子,一个黑盒子把除非把所有组合都看到,这个爆炸会超过计算机算力和数据的成长,我们一定要提出更加有效的算法,特别是这个conversational算法,就是这种组合性的算法,必须有充分的解释性,必须有充分的模块化,才使的真正解决爆炸式的这个问题,所以说这两个来说,也许是50亿的模型,但是光50亿模型还不够的,同时算法能够,更加就是底下的解决爆炸的问题,才能够解决更高层次智能这个问题。
M:算法之外,模型相对往前走,随着网络的加深会,整个运算能够更大,是说,整个的效果更好,所以感觉是一个后续把算法和算力交替的往前走?这个问题。那另外我们再探讨一下,刚才讲到,我在语义识别,在这个图像识别上,基本上都已经达到了这种,现在我们看的话,就是让,其实一定程度上,我觉得,这样自然语言的对话,或者文本的生成,真正的这个语义理解,这个摘要,这些东西,还有很多的,不上的,这里面能不能,隐含的问题和思考,相对图像来讲,这个一些问题,自然语言的复杂度应该非常高的,这个复杂很难解释。
这个比如说我们刚才说这个图像问题,说你人类,这个是有定义的,这个是不是计算,这个一千亿的分类,在非常,比如说这个很噪音的地方,和光线很暗的地方,人会比计算机做得更好,但是另一方面,我想说的是从感知智能到认知智能,语音和图像识别,本身是一种感知智能,这个感知智能它是一个比较,就是你确实需要很多运算,但是确实它是一种比较基础的一种智能,到认知的时候,你需要做推理,做常识和服辅助,需要对语义理解,这时候,它往往是更大的一种组合性的一个支持,这方面确实也,我个人的话会比较难一些,其实你肯定认为,这是为什么,这个人才特有语言能力,很多动物没有这个语言能力。
3、在AI商业落地这块,您认为在AI的哪些技术是可以落地?
A:上文说的那些技术在很多场景都是可以落地的,比如说推荐,数据挖掘,我们可以用来理解用户的偏好,给他推荐更合适的商品,这是很成熟的一个落地的技术,再比如说情感客服,我们大概要服务这个用户的需求,同时还能安抚情感,让满意度得到一个提高。还有智能音响,现在很多大厂yao为什么亏钱做这个事情,因为智能音响只是一个入口,重要的是它背后的引入,逐渐的更加个性化,然后的话,我们通过沟通的方式在,让它事情,是说,一种云端的后端服务,叫做虚拟助手,或者叫做虚拟助理,如果说,就是大家是拿下虚拟助理这个业务,就是这个业务是难以想象的,我们说,京东阿里,衣服都到我这来,想买啥直接就买了。
4、另外呢,比方说,因为咱们AI是个,工程学校,学生,还有,AI在,有什么,然后如果想有所发展的话,
A:第一,这里领域发展的话,最好是欢迎报考AI算法,我个人认为语言学还是很重要的,但是语言学和计算语言学是有区别的,我是希望语言学得到英文,更敏感和Insite,能够帮助我们设计更好的模型,我们刚才说到了,语言是一个组合爆炸的一个问题,所以你不能靠,对于结构的理解,和对于语言结构的,才能使的你能够处理这些情况,所以从语言学来说,如果你对这个语言有更多的了解和敏感的话,那么可以帮助你设计更好的符合这个语言特性的这么一个结构化的模型,这个方面来说是有帮助的,但是这样的话,必须,确实是需要,在学一个计算机,学一个人工智能职位。
M:问题综合,学这个深度学习的知识,专业对于这个,相对其他学科优势,感觉现在,学的比较多,而且,或者,Topic相对少一点。
