@qinyun
2019-04-19T09:41:58.000000Z
字数 8322
阅读 2521
在此处输入标题
未分类
近日,Mozilla发布了一个实验项目Pyodide,旨在于浏览器内运行一个完整的Python数据科学堆栈。
链接:https://github.com/iodide-project/pyodide/
Pyodide的创意起源于Mozilla的另一个项目Iodide,Iodide是一款基于最先进Web技术的数据科学实验和通信工具。值得注意的是,它是设计用于在浏览器中,而不是在远程内核上执行数据科学计算的。
不幸的是,浏览器中“人人都有的语言”JavaScript,不仅没有成熟的数据科学库,还缺少许多对数值计算有用的功能,例如运算符重载。一方面我们认为业界应该改变这一现状,并推动JavaScript数据科学生态系统向前发展;另一方面我们找到了一条捷径:那就是将流行且成熟的Python科学栈引入浏览器来满足数据科学家的需求。
此外还有更多人认为,Python语言面临的一种生存威胁就是无法在浏览器内运行,当下有如此多的用户交互是在网络或移动设备上发生的,Python要么融入其中,要么就会逐渐落伍。因此,尽管Pyodide首先是要满足Iodide的需求,但它独立工作时也是由自己用武之地的:
https://github.com/iodide-project/pyodide/blob/master/docs/using_pyodide_from_javascript.md
from js import document, iodidecanvas = iodide.output.element('canvas')canvas.setAttribute('width', 450)canvas.setAttribute('height', 300)context = canvas.getContext("2d")context.strokeStyle = "#df4b26"context.lineJoin = "round"context.lineWidth = 5pen = FalselastPoint = (0, 0)def onmousemove(e):global lastPointif pen:newPoint = (e.offsetX, e.offsetY)context.beginPath()context.moveTo(lastPoint[0], lastPoint[1])context.lineTo(newPoint[0], newPoint[1])context.closePath()context.stroke()lastPoint = newPointdef onmousedown(e):global pen, lastPointpen = TruelastPoint = (e.offsetX, e.offsetY)def onmouseup(e):global penpen = Falsecanvas.addEventListener('mousemove', onmousemove)canvas.addEventListener('mousedown', onmousedown)canvas.addEventListener('mouseup', onmouseup)
它输出成这样:
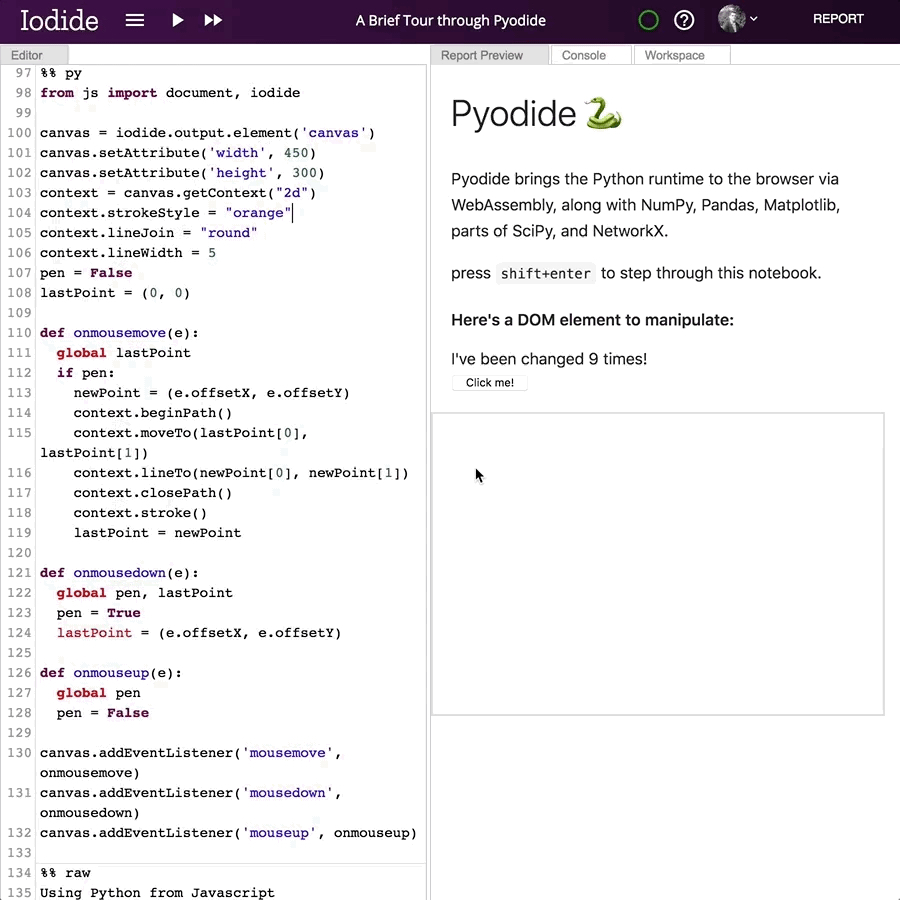
想要了解Pyodide还可以做哪些事情,最好的方法就是去试一试!这里有一个示例笔记(https://alpha.iodide.io/notebooks/300/,50MB)介绍了它的高级功能。下文将深入探讨其工作原理。
现有技术
在Pyodide诞生之前,已经有许多令人印象深刻的项目将Python引入浏览器了。然而,包括NumPy、Pandas、Scipy和Matplotlib在内的这些项目都没有做到实现全功能主流数据科学栈的程度。
像Transcrypt这样的项目会将Python转换为JavaScript。 因为转换步骤是在Python中完成的,所以你需要提前做好所有转换,或者连上一台服务器来完成这项工作。这也无法满足我们的需求,也就是让用户在浏览器中编写Python,并在没有任何外部辅助的情况下运行代码。
像Brython和Skulpt这样的项目是将标准Python解释器重写为JavaScript,因此它们可以直接在浏览器中运行Python代码串。但由于它们是Python的全新实现,并且需要在JavaScript中引导,因此它们与用C编写的Python扩展,例如NumPy和Pandas等并不兼容,也就没有数据科学工具可用。
PyPyJs是Python的实时编译工具PyPy的变体,其使用emscripten即时编译Python到浏览器上。和PyPy一样,它也有能力快速运行Python代码。但它也和PyPy一样在C语言扩展的性能方面存在问题。
上面这些方法都需要我们重写科学计算工具以获得足够的性能。我曾为Matplotlib做过很多工作,所以知道重写代码得花费多少劳力:这条路其他项目已经尝试过且举步维艰,而且它要做的工作肯定不是我们这支拼凑起来的新团队能够处理的。因此,我们需要构建一个尽可能基于Python的标准实现和多数数据科学家正在使用的科学栈的工具。
与Mozilla的几位WebAssembly专家讨论之后,我们意识到开发这个工具的关键在于emscripten和WebAssembly:它们是用来将C语言编写的现有代码移植到浏览器上的技术。随后我们发现了一个使用Python构建的高水平empscripten实现,也就是cpython-emscripten(https://github.com/dgym/cpython-emscripten),最后它成为了Pyodide的基础。
emscripten和WebAssembly
可以从很多角度来介绍emscripten的内容,但对我们而言最重要的是它的两项用途:
1.将C/C++编译到WebAssembly
2.作为兼容层,在浏览器中模仿原生计算环境
WebAssembly是一种在现代Web浏览器中运行的新语言,是JavaScript的补充。它是一种类似于群集的底层语言,旨在作为C和C++等底层语言的编译目标,提供接近原生环境的性能。值得注意的是,最流行的Python解释器CPython就是用C实现的,所以这里就是emscripten的用武之地了。
Pyodide的工作流程如下:
下载主流Python解释器(CPython,https://github.com/python/cpython)的源代码,以及科学计算包(NumPy等);
进行很小的调整以使其适应新环境;
使用emscripten的编译器将它们编译为WebAssembly。
如果你直接把这个WebAssembly输出加载到浏览器中,那么Python解释器就会和在操作系统中直接运行时有很大区别。例如,Web浏览器没有文件系统(加载和保存文件的位置)。还好emscripten提供了一个用JavaScript编写的虚拟文件系统供Python解释器使用。默认情况下,这些虚拟“文件”会驻留在浏览器选项卡临时占用的内存里,页面关闭时它们就会消失。(emscripten还为文件系统提供了一种在浏览器的本地存储空间中存储内容的方法,但Pyodide不用它。)
通过模拟文件系统和其它标准计算环境中的功能,emscripten可以只用很少的调整就将现有项目迁移到Web浏览器中。(将来我们可能会转而使用WASI作为系统仿真层,但是现在emscripten是更成熟和完善的选择)。
总而言之,要在浏览器中加载Pyodide,你需要下载:
用WebAssembly编译的Python解释器。
emscripten提供的一些JavaScript,用于系统仿真。
一个打包的文件系统,包含Python解释器所需的所有文件,其中最重要的是Python标准库。
这些文件可能会非常大:Python本身为21MB,NumPy为7MB,依此类推。所幸这些包只需要下载一次,之后它们会存储在浏览器的缓存中。
将所有这些东西组合起来后,Python解释器就可以访问其标准库中的文件,启动,然后开始运行用户代码了。
哪些部分正常工作,哪些不行
我们用CPython的单元测试作为Pyodide持续测试的一部分,以便了解Python的哪些功能正常工作,哪些不行。有些东西,比如多线程现在就不能用了,但在新出现的WebAssembly threads的帮助下,我们应该很快就能提供支持了。
由于浏览器的安全沙箱限制,一些功能(如底层网络套接字,https://docs.python.org/3/library/socket.html)不太可能正常工作。另外很抱歉让你失望了,想要在Web浏览器中运行Python minecraft服务器(https://github.com/Yardanico/puremine)可能还有很长的路要走。不过你仍然可以使用浏览器的API通过网络获取内容(后文会具体介绍)。
它有多快?
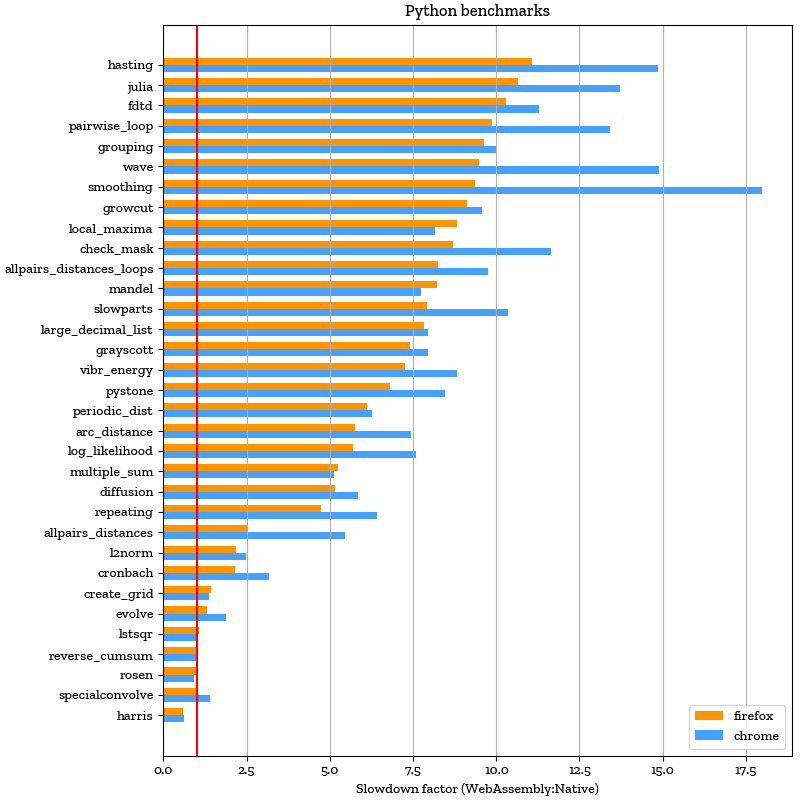
在JavaScript虚拟机中运行Python解释器会损失更多性能,但这种惩罚是很小的——在我们的基准测试中,Firefox上比原生慢1到12倍,Chrome上慢1到16倍。经验表明,这个程度的性能对于交互探索已经很够用了。
要注意的是,在Python中运行大量内部循环的代码往往比使用NumPy执行其内部循环的代码慢很多。以下是在Firefox和Chrome中运行各种Pure Python和Numpy基准测试(https://github.com/iodide-project/pyodide/tree/master/benchmark/benchmarks)的结果,与在相同硬件上原生运行做对比。
Python和JavaScript的交互
如果Pyodide能做的就只是运行Python代码并写入标准输出,那么它就只能当一个很酷的玩具,但难以用于实际工作。Pyodide真正的力量在于它能够以非常高的水平与浏览器API和其他JavaScript库交互。WebAssembly旨在轻松地与浏览器中运行的JavaScript交互。由于我们已经将Python解释器编译为WebAssembly,因此它也与JavaScript这边深度集成在了一起。
Pyodide会隐式转换Python和JavaScript之间的许多内置数据类型。其中一些转换是明显、直截了的,但有趣的部分向来都在于那些少见的情况。
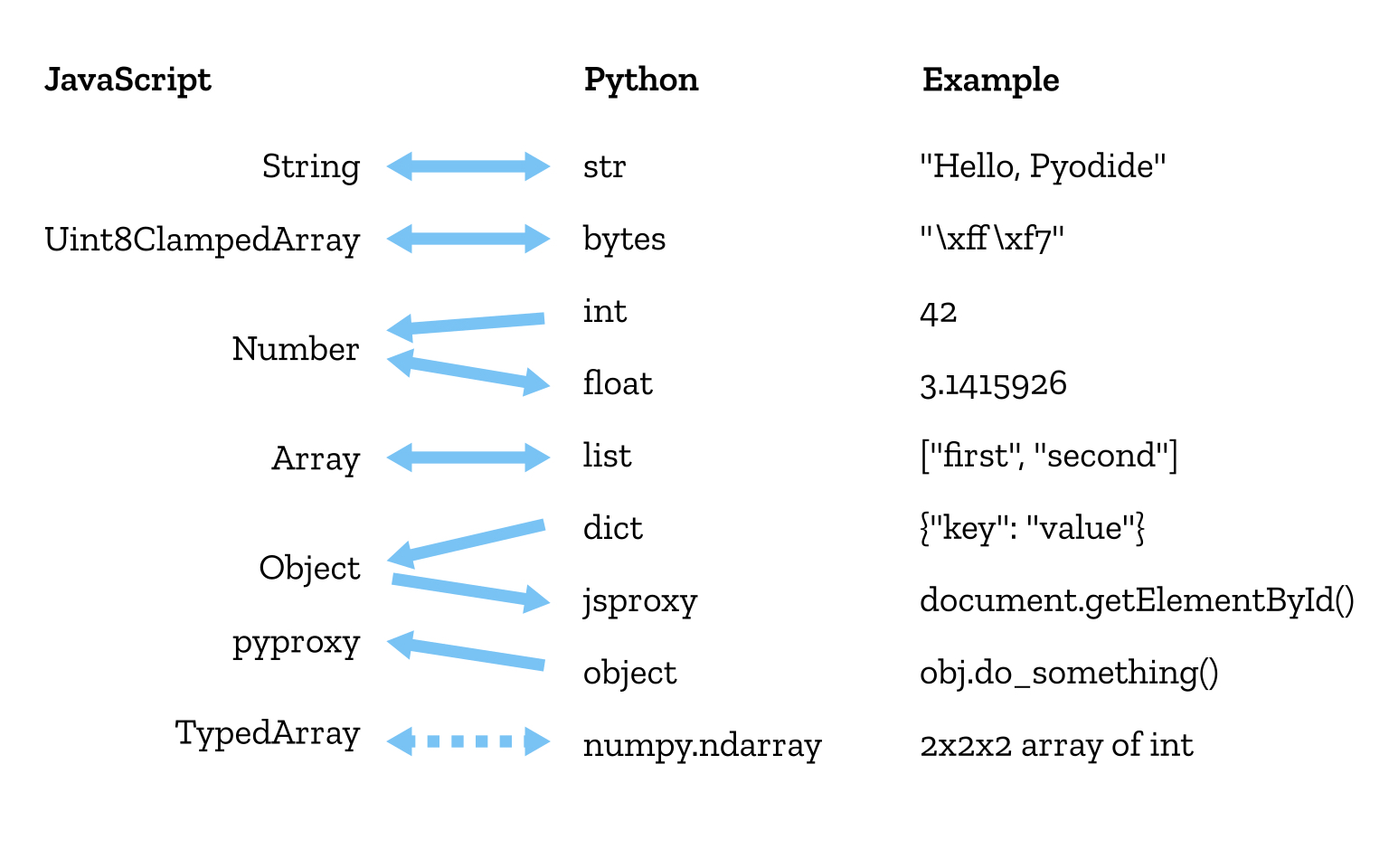
Python将dict和object实例视为两种不同的类型。dict(字典)只是键的映射值。另一方面,object通常具有对这些对象“做某事”的方法。在JavaScript中,这两个概念被混合成一个名为Object的类型。(是的,我在这里简化了很多内容。)
如果没有真正理解开发者使用JavaScript的Object的意图,就没法判断它是该转换为Python的dict还是object。因此,我们必须使用代理,用“鸭子类型”来解决问题。
代理是另一种语言中变量的包装器。代理不是简单地在JavaScript中读取变量并根据Python的构造重写它,就像对基本类型所做的那样,而是维持原始的JavaScript变量并“按需”调用它上面的方法。这意味着任何JavaScript变量,无论它的定制程度多高,都可以从Python完整访问。反过来也是没问题的。
鸭子类型是一个原则,不是问变量“你是鸭子吗?”而是问它“你像鸭子一样走路吗?”和“你像鸭子一样嘎嘎叫吗?”并从中推断出它可能是一只鸭子, 或者至少像鸭子般行事。这使Pyodide可以延后决定如何转换JavaScript对象:它将对象包装在代理中,并让使用它的Python代码决定如何处理它。当然这招并不总能见效,因为你以为它是鸭子,实际上可能是一只兔子(https://www.illusionsindex.org/i/duck-rabbit)。因此Pyodide还提供了显式处理这些转换的方法:
https://github.com/iodide-project/pyodide/blob/master/docs/api_reference.md#pyodideas_nested_listobj
正是这种紧密的集成让用户可以在Python中处理数据,然后将其发送到JavaScript进行可视化。例如,在我们的Hipster Band Finder演示(https://alpha.iodide.io/notebooks/1623/)中,我们在Python的Pandas中加载和分析数据集,然后将其发送到JavaScript的Plotly进行可视化。
访问Web API和DOM
代理也是访问Web API的关键环节,或者是浏览器提供的使其能够完成工作的一组功能。 例如,Web API的很大一部分位于document对象上。你可以这样从Python中获取它们:
from js import document
这会将JavaScript中的document对象作为代理导入到Python端。你可以从Python开始调用它的方法:
document.getElementById("myElement")
这些都是通过代理来查找document对象可以即时执行的操作。Pyodide不需要包含浏览器所有Web API的完整列表。
当然,直接使用Web API并不会一直像大多数Python风格或者对用户友好的方式那样处理问题。我们希望能看到为Web API创建的对用户友好的Python包装器,就像jQuery之类的库使Web API更容易通过JavaScript使用一样。如果你想做这种工作,请告诉我们:https://gitter.im/iodide-project/iodide
多维数组
数据科学有自己特定的一些重要数据类型,Pyodide也对它们提供了专门支持。其中,多维数组是所有相同类型(通常是数字)值的集合。它们往往很大,并且由于每个元素都是相同的类型,多维数组与可以容纳任意类型元素的Python的list或JavaScript的Array相比,前者具有明显的性能优势。
在Python中,NumPy arrays是多维数组的最流行实现。JavaScript也有TypedArrays,只包含一个数字类型,但它们是单维的,因此需要在其上构建多维索引。
由于实践中这些数组可能会变得非常大,所以我们不希望在各个语言运行时之间复制它们。这不仅需要很长时间,而且在内存中同时存在两个副本会对浏览器有限的可用内存造成负担。
还好我们无需复制即可共享此数据。多维数组通常使用少量元数据来实现,这些元数据描述了值的类型、数组的形状和内存布局。数据本身通过指向内存中另一个位置的指针从该元数据中引用。这部分内存位于一个称为“WebAssembly堆”的特殊区域,优点在于它既能用JavaScript也能用Python访问。我们可以简单地在语言之间来回复制元数据(元数据非常小),然后用指针指向引用WebAssembly堆的数据。
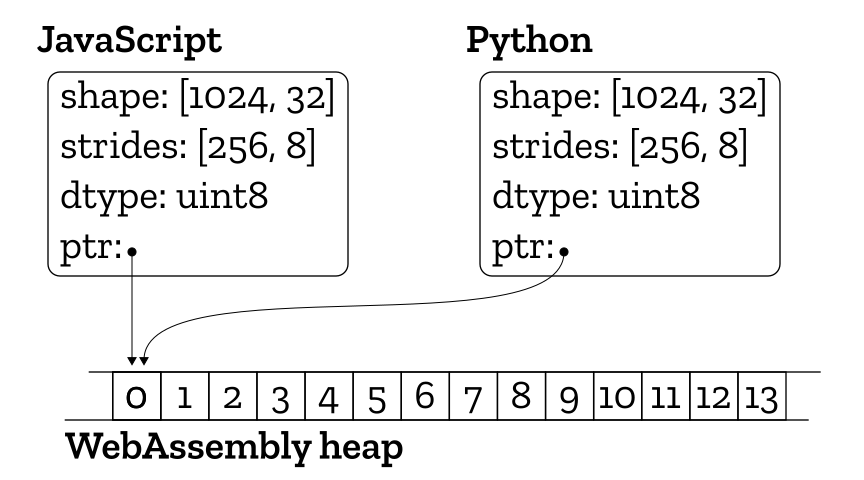
目前,这个想法是针对一维数组实现的,对于更高维数组而言,这是一个次优的解决方法。我们需要对JavaScript侧进行改进,以便用一个有用的对象来处理它。现在JavaScript多维数组还没有很好的选择。Apache Arrow和xnd的ndarray(https://xnd.io/)等有前景的项目正在研究这方面的问题,旨在使不同语言运行时之间的内存结构化数据的传递更加便利。我们正在研究如何利用这些项目,以进一步增强这种数据转换操作。
实时交互式可视化
如Jupyter所做的那样,在浏览器中而不是在远程内核中进行数据科学计算的优点之一是,交互式可视化不必通过网络通信以重新处理和显示其数据。这大大降低了延迟——也就是从用户移动鼠标到更新绘图显示到屏幕所需的响应时间。
完成这项工作需要上述所有技术部分协同工作。先来看看这个交互式示例(https://alpha.iodide.io/notebooks/1658/),它使用matplotlib展示了对数正态分布的原理。首先,使用Numpy在Python中生成随机数据;接下来Matplotlib获取该数据,并使用其内置的软件渲染器绘制它;它使用Pyodide对零拷贝数组共享的支持将像素发送回JavaScript端,最终将它们渲染到HTML画布中。然后浏览器将这些像素显示屏幕上。用于交互的鼠标和键盘事件由从Web浏览器调用的回调处理,发送回Python。
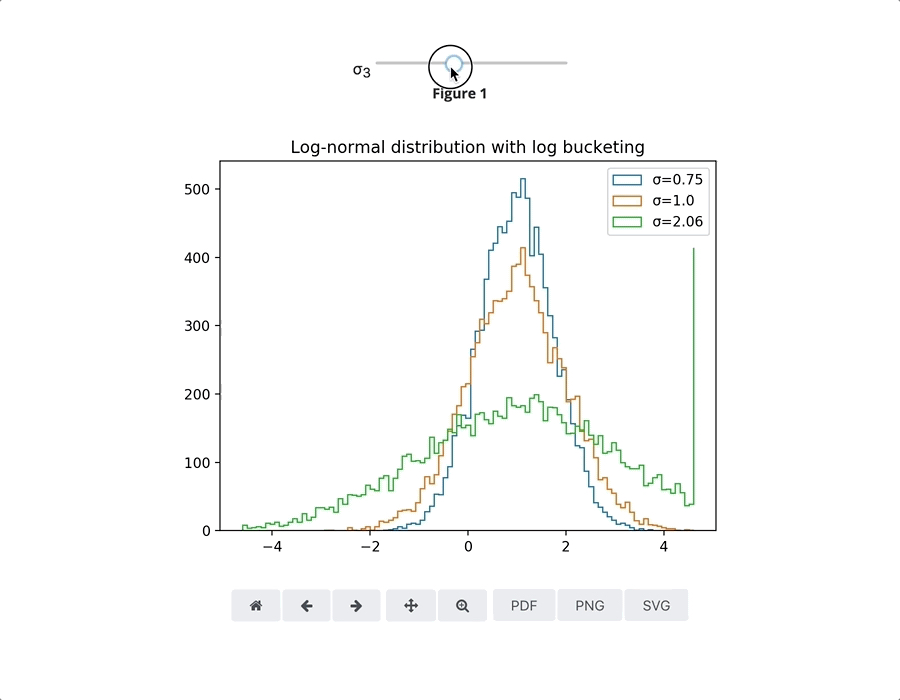
打包
Python科学栈不是一个整体——它实际上是一组松散的附属包,它们协同工作以打造生产环境。其中最受欢迎的是NumPy(用于数值数组和基本计算)、Scipy(用于更复杂的通用计算,如线性代数),Matplotlib(用于可视化)和Pandas(用于表格数据或“数据帧”)。可以在此处查看Pyodide为浏览器构建的完整包列表,该列表还在不断更新:
https://github.com/iodide-project/pyodide/tree/master/packages
其中一些包很容易引入Pyodide。通常来说,任何使用纯Python编写而没有编译语言扩展的东西都非常简单。难度高一些的类别中,像Matplotlib这样的项目需要使用特殊代码在HTML画布中显示绘图。有些包属于极端困难的类型,其中Scipy就一直是一项巨大的挑战。
Roman Yurchak致力于将Scipy中的大量旧Fortran代码编译为WebAssembly。Kirill Smelkov改进了emscripten,使共享对象可以被其他共享对象复用,从而缩小了Scipy的体积。(这些外部贡献者的工作得到了Nexedi,http://www.nexedi.com/的支持)。如果你正在努力将包移植到Pyodide上,请在Github上与我们联系,你的问题我们之前很可能也遇到过:
https://github.com/iodide-project/pyodide/
由于我们无法预测用户最终需要哪些包来完成任务,因此用户可以根据需要将它们单独下载到浏览器中。例如在导入NumPy时:
import numpy as np
Pyodide会获取NumPy库(及其所有依赖项)并同时将它们加载到浏览器中。同样,这些文件只需要下载一次,之后会存储在浏览器的缓存中。
现在向Pyodide添加新包是一个半手动过程,其中需要向Pyodide中添加文件。长远来看,我们更倾向于采用分布式方法解决这个问题,这样任何人都可以无需处理单个项目就为生态系统贡献包。这方面最好的例子是conda-forge。如果能将它们的工具进一步扩展,支持WebAssembly作为平台目标就好了,这样就省去了很多重复劳动。
此外,Pyodide很快将支持(https://github.com/iodide-project/pyodide/pull/147)直接从PyPI(Python的主社区包存储库,https://pypi.org/)加载包,只要它以纯Python编写并以轮格式(https://pythonwheels.com/)分发。这样以来,Pyodide现在就可以访问大约59,000个包。
超越Python
Pyodide较早期的成功已经激励了其他语言,包括Julia、R、OCaml、Lua等社区的开发者,设法让他们的语言运行时在浏览器中正常工作,并与Iodide等网络优先工具集成。我们定义了一组级别,以鼓励人们创建与JavaScript运行时联系更紧密的集成:
第1级:只是字符串输出,可以用作基本控制台REPL(read-eval-print-loop)。
第2级:将基本数据类型(数字、字符串、数组和对象)与JavaScript互相转换。
第3级:在访客语言和JavaScript之间共享类实例(带方法的对象)。这样就能允许Web API访问了。
第4级:在访客语言和JavaScript之间共享数据科学相关类型(n维数组和数据帧)。
如果你尚未尝试过Pyodide,现在就试试吧:https://alpha.iodide.io/notebooks/300/
原文链接
https://hacks.mozilla.org/2019/04/pyodide-bringing-the-scientific-python-stack-to-the-browser/
