@qinyun
2017-11-02T10:04:38.000000Z
字数 4381
阅读 2666
实时语音视频通话SDK如何实现听声辨位
移动开发
前言
通过听声音可以辨别声源的位置,这是我们习以为常的生活认知。从技术的角度来说,听声辨位其实真的一点都不简单。我们人类应该感谢上天的造化,赋予我们一双巧夺天工的耳朵,让我们可以毫不费力地做到听声辨位。在语音视频实时通信的世界里,要实现听声辨位,却是要耗费一番心思的事情。
双耳效应
关于人耳听声辨位的原理,这里不再赘述。有需要了解的同学请自行搜索“双耳效应”问度娘。简单地来说,听声辨位的基础是左右耳朵从同一声源获得的声音信息有细微的差别:
到达左右耳朵的时间不一样
在左右耳朵空间上的相位不一样
音色(频率)不一样
音级(波幅)不一样
人脑和双耳就是根据这两组声音信息的细微区别,判断出声源的位置的。
人类的双耳在自然环境进行听声辨位,已经有过数百万年的实战经验,以至于我们认为这是理所当然的事情。然而,随着科技的发展,我们习以为常的认知遇到了突而其来的挑战。
二十世纪初遇到的第一个有代表性的挑战是留声机。立体声技术较好地为模拟声音解决了立体音效的问题。基础的立体声技术是采用两个麦克风进行拾音,获得两组波形独立的声音信号,然后进行独立的处理,在播放的时候采用两个扬声器独立地播放这两组声音信号。这样,从播放端的角度来说,用户听到的是声音本身的立体音效和用户周遭空间的立体音效的叠加,能够达到听声辨位的效果。
二十一世纪的前二十年,语音视频实时通信遇到了移动互联网,立体声技术也遇到技术限制。这些技术限制其实和应用场景有关系。
听声辨位的应用场景
第一个要提的是游戏场景,如果不是最重要,也是最重要之一。游戏可以分为竞技类的和休闲类的。两类游戏对听声辨位的要求也不尽相同。
竞技类的游戏,包括众多玩家耳熟能详的MMORPG、MOBA和FPS。玩过CS的同学都知道,在虚拟场景中是能听到周遭其它玩家的脚步声的,听声辨位很多时候比视野更加有效地帮助玩家判断其它玩家在哪里,这往往是杀敌制胜和脱险保命的关键手段。现在实时游戏语音技术可以让玩家在CS中和队友一边并肩作战一边对话沟通。如果玩家通过游戏语音通话判断出队友的位置和通过游戏系统声音判断出队友的位置不一致,以至于造成判断错误,在分秒必争的虚拟枪战中,这可是致命的误导。要让游戏系统声音反映的虚拟位置和游戏语音通话反映的虚拟位置一致,其实是蛮难的。游戏系统和游戏语音SDK是完全独立和解耦的,游戏系统的声音产生涉及到游戏服务器和客户端的协同,游戏语音SDK的语音是从远端用户传输过来,考虑到两个独立系统和网络传输,两个者之间的步调要保持一致是十分有挑战的任务。

休闲类的游戏包括棋牌等人数较少节奏较慢的游戏,通过游戏语音边玩边聊天是一个刚性的社交需求。请各位闭眼想象,你和其它三个好友在线上打麻将,同时通过语音唠叨家常。如果你能够通过听左、右和前方三个人的声音,分辨出他们就像是坐在你左、右和前方三个位置,音效体验一下子就爆表了。狼人杀游戏更加不在话下,这种完全依托语音会话建立起来的社交游戏,如果能够通过听声音就能辨别出讲话的人的方位,闭着眼睛去感觉,就像是一伙朋友围着圆桌面对面的玩狼人杀游戏呢。
第二个对听声辨位有需求的场景是在线教育的小班课堂。举一个比较具体的例子,在线少儿英语小班课,应该是对线上互动要求最高的一种在线课堂形态,没有之一。小朋友的注意力不容易集中,对课堂趣味性和互动性的要求特别高。如果小朋友能够通过听声感觉到老师就坐在正前方讲台的位置,其它小朋友坐在前后座位各个方位,由远而近多个距离层次都有小朋友,就像是在真实的摆满书桌的教室里面的声音效果一样,这样无疑是大大增强了小朋友的注意力集中程度。
其它的一些应用场景,比如说语音社交、视频社交和互动直播,听声辨位的效果也会让用户感到惊艳。如果你加入houseparty的视频聊天房间,能听到参加趴踢的朋友分布在你前后左右的各个位置,那种沉浸式的听音感觉会让你像是整个人一下子投入到趴踢的人群中去。
这些应用场景即构ZEGO都有丰富的客户案例,即构ZEGO的听声辨位技术能让用户在这些应用场景里获得360度空间感的听声体验。然而,客户越来越苛刻的需求,驱使着即构ZEGO不断的去打磨和升级其听声辨位技术,来给予用户最优的体验。
移动终端的处理能力分秒不停地飞速发展,5G的推出如果不出意外也会在2019年到来,加上VR/AR技术的日渐成熟,沉浸式的语音视频实时互动通信将会成为一种生活方式。当你带着VR头显,环顾360度都看到远端的朋友的视频影像的时候,你是不是也期待他们的声音听起来也像是从他们看起来的那个位置传过来一样?到那时候,听声辨位技术也会成为这种生活方式的必备支柱。
硬件条件的限制
上面对应用场景的展望和抒情有点太超前了,我们稍微回到2017年下半年的现实中来。虽然梦想很美好,但是现实很残酷,现在手机硬件条件还存在诸多限制。
目前,绝大部分的手机采集声音的麦克风只有一个。当然有朋友反对说,iPhone不是有好几个麦克风吗?其实采集语音的麦克风还是只有一个,其它的麦克风是用来做噪声抑制的。一个麦克风采集到的声音就是单声道的,不会产生立体声的效果,也就是不会让你听声音就能辨别出声源的位置。
目前,绝大部分的手机只有一个扬声器,只有少数的手机是支持立体声的。这里要区别分一下,打电话的时候听电话那个喇叭不是扬声器,点了免提键后手机不需要贴到耳朵边的时候发出声音的那个喇叭才是扬声器,播放音乐的时候发声音的喇叭也就是扬声器。既然只有一个扬声器,那么不管声音信号是不是立体声的,播放出来的声音效果都是单声道的。在渲染的时候,应用程序把声音数据放到一个缓冲区,操作系统把声音数据取出来播放,如果只有一个扬声器的话,巧妇难为无米之炊,臣妾也表示办不到,即使是立体声信号也会被降级为单声道播放。当然,耳机线有左右两个喇叭,插入耳机线以后,手机就支持立体声播放了。
单声道虚拟成立体声
如果发送端采用外部采集,采集的设备有两个麦克风,或者本身就是立体声麦克风,那么采集进来的声音信号就是立体声的。立体声信号包含两组独立的波形,由于这两组波形有相关性,可以一起编码传输,在接收端解码以后再独立地渲染,最终获得立体声的效果。
如果发送端采用手机的唯一麦克风,采集进来的声音信号就是单声道的。如果要在接收端获得立体声的效果,就要把单声道的声音信号虚拟成立体声的。不是说巧妇难为无米之炊吗?这里也不完全是“无米”,毕竟还是有一组单声道波形数据的。
具体的做法是,首先对声音传播路径进行建模,然后输入原始的波形数据,还有距离d和角度a两个参数,模型会输出两个独立的波形,代表左右声道的声音信号。这两个波形和原始的波形作比较,在相位,音色和音调都有所调整,尽量地逼近原始波形在自然环境中传播到用户的左右耳朵后形成的两个不同的波形。这两个波形有相关性,因此一起编码后的带宽是小于每一个波形带宽的两倍。虚拟立体声信号数据到达接收端以后,结果解码就可以得到两个独立的波形声音信号数据。如果是在手机扬声器播放出来,效果还是单声道的,如果通过耳机播放出来,就能呈现出立体声的效果,用户可以听出声音的空间感,并且依此进行听声辨位。
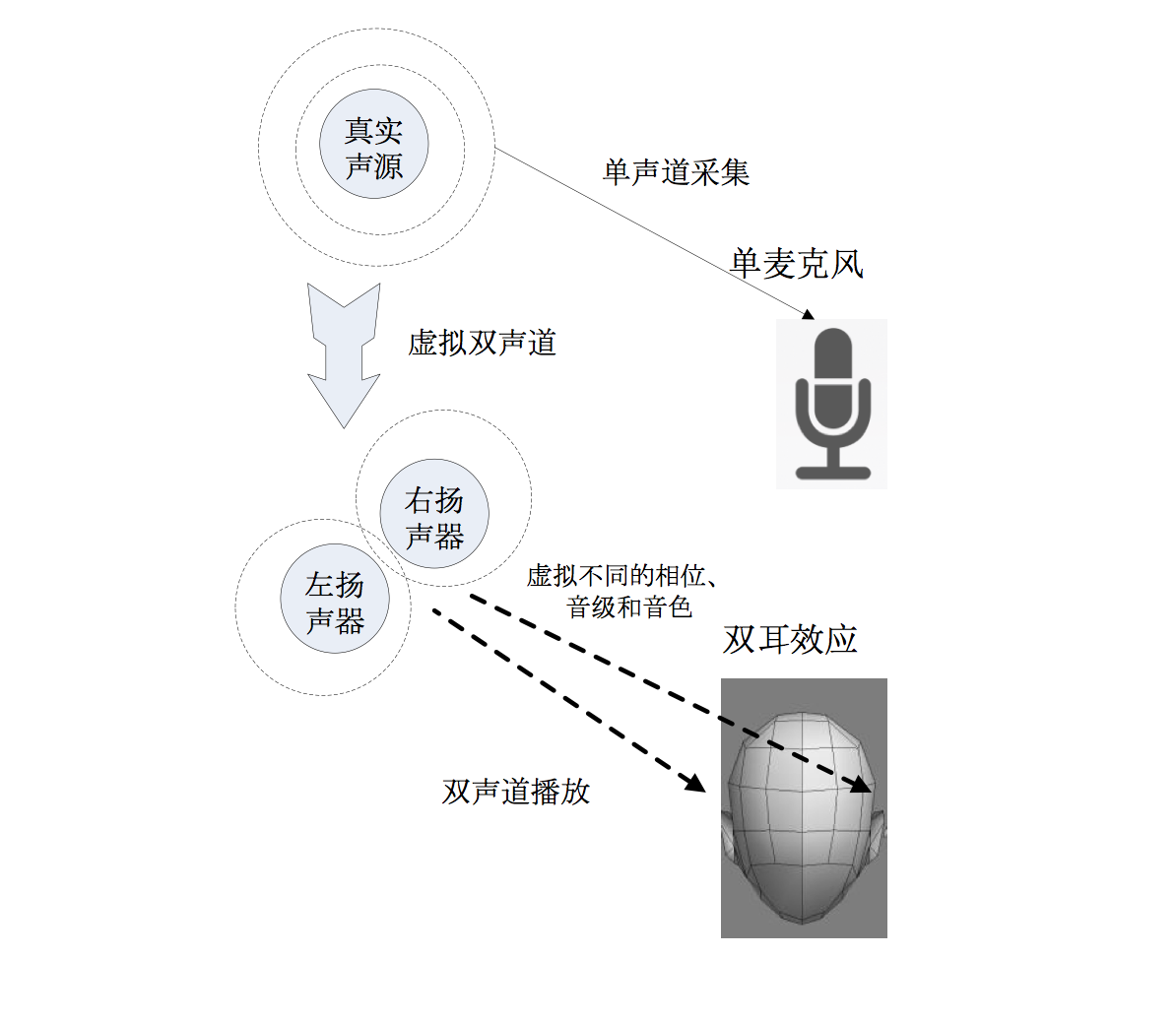
把单声道波形虚拟成两个独立的立体声波形,是在目前移动端硬件限制条件下的一个技术处理手段。虚拟立体声的处理可以在发送端进行,也可以在接收端进行。在哪里进行虚拟化,要看具体的场景需要。如果有混音的需求,也就是要把语音信号和背景音乐混合在一起的话,那么比较适合在发送端来做虚拟立体声;如果没有混音的需求,那么比较适合在接收端做虚拟立体声。背景音乐一般是立体声的,而且是在发送端输入的。如果需要进行混音,而混音必须要在发送端进行,那么背景音乐和语音信号都要是立体声才能对应得混合。因此,虚拟立体声必须要发送端完成,然后虚拟出来的语音立体声才能和背景音的立体声混合,混合好以后再把立体声信号进行编码传输,最后到了接收端解码以后就可以把立体声播放出来。如果不需要进行混音,那么可以把单声道声音信号直接编码发送,接收端收到后进行解码,再把单声道声音信号虚拟成立体声,这样传输的带宽就可以做到最低。
当互动直播遇到立体声
随着硬件的快速更新换代,在不远的将来,手机很可能会支持立体声,拥有双麦克风(考虑到手机的物理尺寸较小,笔者严重怀疑双麦克风的效果)和双扬声器。也许你会觉得这是普大喜奔的好事情,再也不用费脑去搞虚拟立体声了,然而有个现实要让你心碎:即使手机支持立体声,在进行互动直播或者互动语音视频通话的时候,手机依然只能采用单声道采集,因此,还是要继续搞虚拟立体声,这是跑不掉的事情。为什么在互动直播的时候只能采取单声道而不能采取立体声呢?下图展示了使用立体声手机进行回声消除的逻辑,大家看一下此图就理解互动直播不能采取立体声的缘由了。
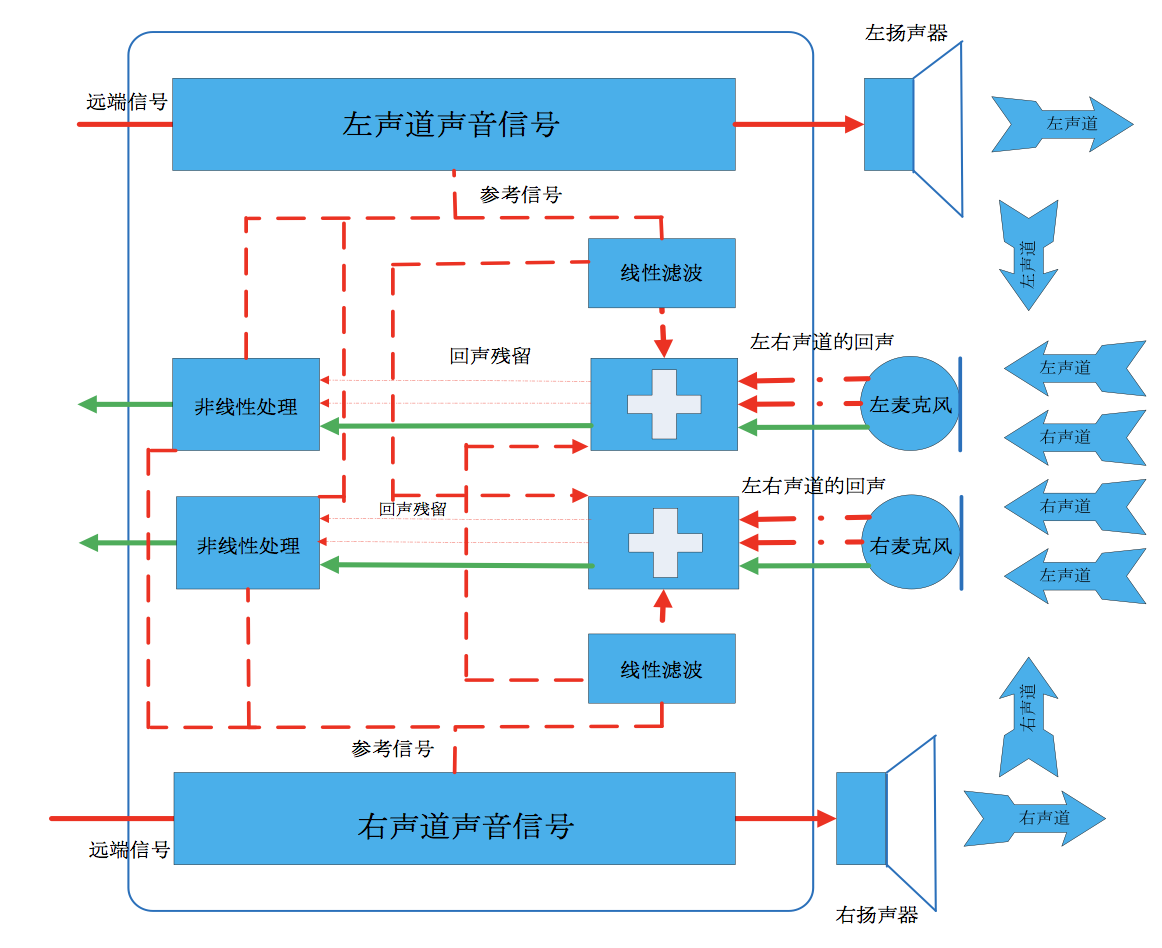
参照上图,我们看一下语音数据的是如何流动的:
远端的左右两个麦克风分别采集左右声道的语音数据;
近端的左右两个扬声器分别播放左右声道的语音数据;
近端左边的扬声器发出的声音经过回声馈路会被近端左右的两个麦克风采集进去;
近端右边的扬声器和#3同理;
近端左边的麦克风采集进来的声音信号包括了左右两个扬声器产生的回声;
近端右边的麦克风和#5同理;
对左边麦克风采集的声音进行回声消除的时候,除了参考远端左声道声音信号消除左边扬声器产生的回声,还要参考远端右声道声音信号消除右边扬声器产生的回声;
对右边的麦克风采集的声音进行回声消除和7同理。
也就是说,对左边麦克风采集进来的声音要消除左右两个扬声器产生的回声,对右边麦克风采集进来的声音进行回声消除也同理,总共要进行四次回声消除,并且要从每一个麦克风采集进来的声音信号里消除两个扬声器造成的回声,计算量一下子变成单声道情形的四倍,复杂度更是远超四倍。同等条件下,立体声回声消除的效果比起单声道回声消除的效果差。目前业界的实践表明,立体声回声消除的效果并不理想。因此,在涉及到互动直播或者互动语音视频实时通话的场景,还是要使用单声道采集和渲染比较能简单而且能保障效果。
结语
听声辨位是人们在自然环境中习以为常的事情,语音视频实时通信的愿景就是要在互联网上完美地还原自然环境的通话场景,这也是即构ZEGO孜孜不倦地追求的使命。随着AR/VR的发展,沉浸式的语音和视频消费方式成为常态,在进行语音视频实时通话的时候,人们也会要求能够做到听声辨位,在游戏语音、语音社交、视频社交、视频会议和在线教育等场景,会有广泛的需求和应用。
作者:冼牛
(微信xianniu1216,邮箱noahxian@zego.im,电话13266561305),即构科技资深语音视频专家,北京邮电大学计算机硕士,香港大学工商管理硕士,多年从事语音视频云服务技术研究,专注互动直播技术、语音视频社交和实时游戏语音。
