@sambodhi
2018-04-03T02:05:42.000000Z
字数 2281
阅读 4667
用GAN实现字体风格迁移
作者|Samaneh Azadi
译者|Sambodhi
编辑|Debra

AI前线导读:生成式对抗网络(GAN, Generative Adversarial Networks)是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。GAN最常用的地方就是图像生成,如超分辨率任务,语义分割等等。那么,它可以应用来实现字体风格迁移么?答案是Yes。日前,UC Berkeley学习机器视觉和机器学习的博士生Samaneh Azadi日前撰写了一篇文章:Transfer Your Font Style with GANs。有兴趣的读者可以已阅。值得一提的是,Samaneh Azadi是来自伊朗的女学生。本文中译本得到了作者的授权。
文字是二维设计的重要视觉元素。艺术家耗费大量时间来设计字形,使得这些字形看上去与其他元素的形状和纹理等相匹配。这一过程本身就是劳动密集型的工作,艺术家通常只设计标题或注释所需的字形子集,这样一来,设计一旦完成,文本就很难再次被修改,其他人也无法直接将已有的字体实例用于自己的项目中。
关于字形合成的早期研究主要集中在轮廓的几何建模上,它只限于特定的字形拓扑(如不能应用于装饰性或手写体字形),不能用于图像输入。不过,随着深度神经网络的兴起,研究人员开始研究从图形中进行字形建模的方法。另一方面,综合与部分观察相一致的数据是计算视觉和图形学中的一个有趣问题,例如多视角图像生成、图像完成缺失区域和生成三维形状。字体数据就是一个提供了样式和内容的干净分解的示例。
在许多生成应用中,条件生成式对抗网络(conditional generative adversarial networks,cGAN )最近的进展取得了很大的成果。然而,它们只能在相当专业的领域内才能做到最好,而不能做到一般的或多领域的风格迁移。类似的,如果直接用于生成字形时,cGAN模型就会产生显著的图像伪影。比如,给定如下图所示的五个字母:

训练cGAN学习上图5个字母的字形风格,然后生成相同风格的26个字母,结果并不成功。
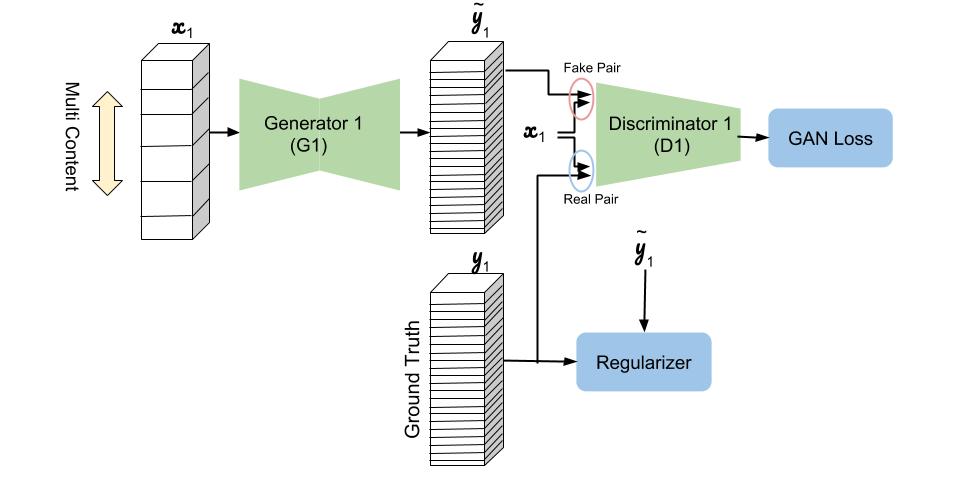
适用于少数字体风格迁移的多内容GAN
我们没有为所有可能的字体装饰训练单一网络,而是设计了多内容GAN(Multi-Content GAN)架构,为每个观察到的字符集重新训练一个定制的网络,只需观察少量的字形即可。这个模型的思路是用通道内的文本(A~Z)和神经网络层中的风格,将给定的字形风格迁移到看不到的内容。
多内容GAN模型由多个cGAN堆叠组成,其中一个cGAN用来预测粗略的字形形状,一个cGAN用来预测字形最终的颜色和纹理。第一个网络称为GlyphNet,预测字形蒙版;第二个网络称为OrnaNet,用来对第一个网络生成的字形进行着色和装饰。每个子网络都遵循cGAN的体系架构,其中部分架构会因实现预测字形或装饰等目的而微调。
网络架构
下图是GlyphNet的示意图,揭示了如何从一组训练数据集中,学习字体的风格。GlyphNet的输入和输出是每个字母分配通道的字形堆栈。在每轮训练迭代中,x1从y1中随机抽取一组字形子集,其余的输入通道清零。
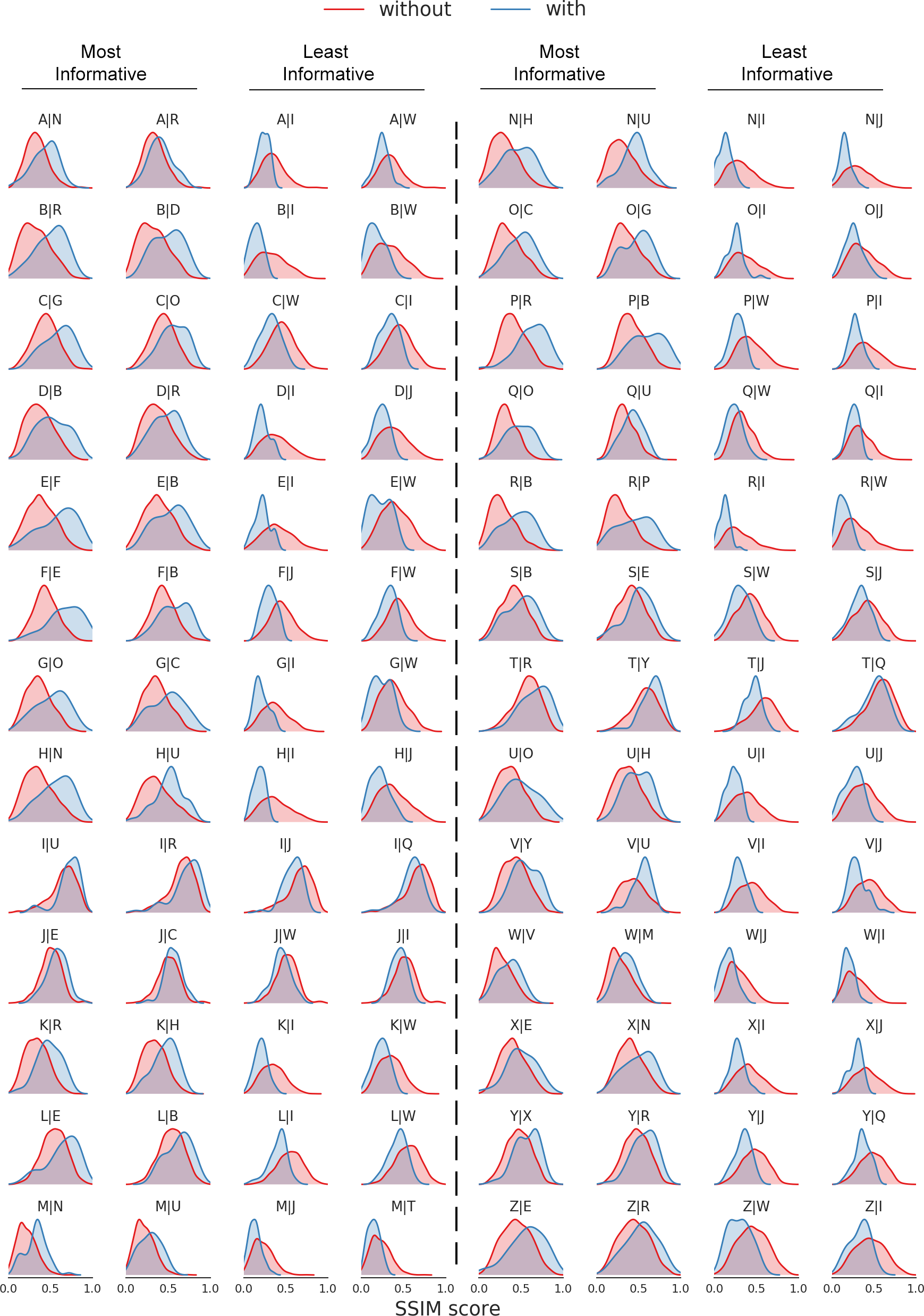
通过这种新颖的字形堆栈设计,神经网络可通过通道信息获得不同字形之间的相互关系,从而实现自动风格迁移。如下图所示,揭示了模型如何从1500个字形样本中学到相关性,并经结构相似性(SSIM)标准进行量化。一次只需观察一个字母,就可找到25个分布。这些图显示了当字母β被观察到时(蓝色)与其他字母而不是β被给出(红色)时生成字母α的分布α|β。图中显示了两个信息最丰富的给定字母的分布和两个最不明显的信息,分别用于生成26个字母。例如,从图中的第五行可知,字母F和B在生成字母E时最有建设性,与其他字母相比较,而I和W是包含信息量最少的字母。另外,O和C是用于构造G以及用于生成P的R和B的最具建设性意义的字母。
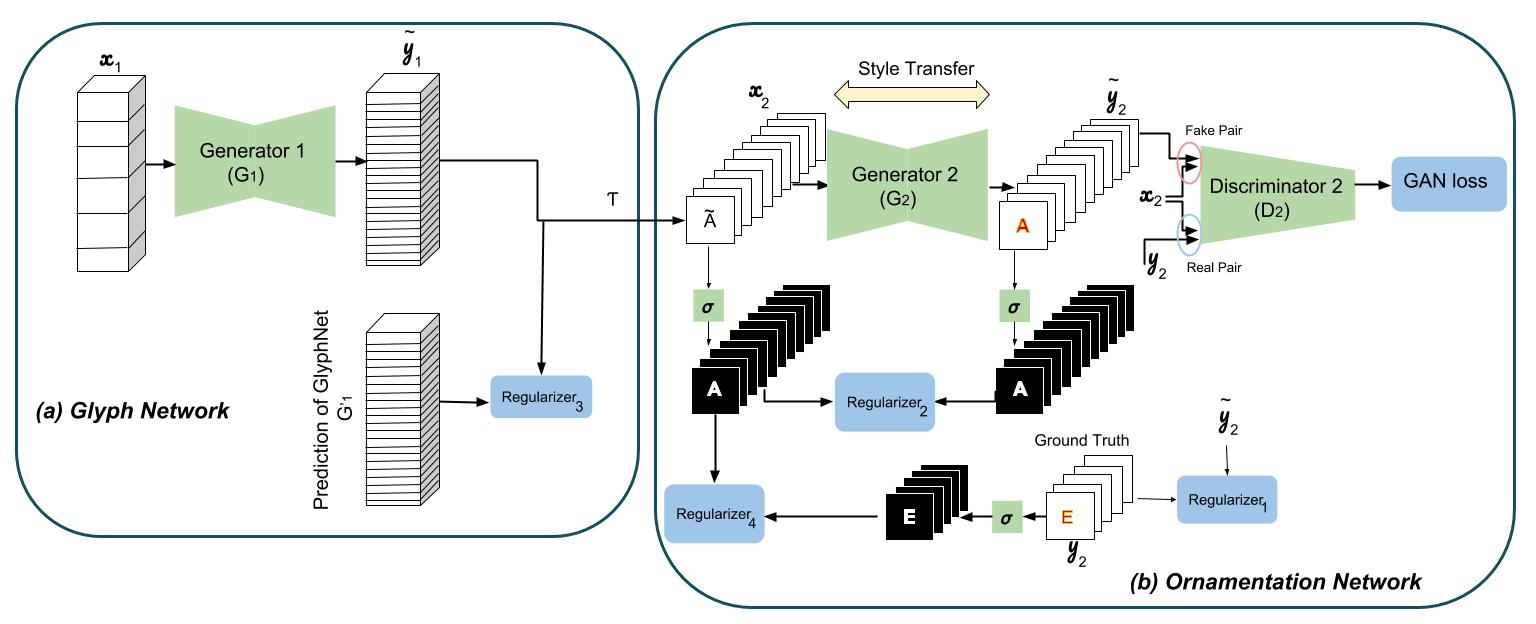
因此,就算只观察到少数几个字母的任何想要的字体,经过预训练的GlyphNet会根据这些字母的风格生成全部26个A~Z的字形。但是,我们应该如何实现风格迁移呢?第二网络OrnaNet采用这些生成的字形,Multi-Content GAN对这些数据经过重复的转换,如下图中,用T表示灰度信道重复的步骤,之后OrnaNet再用cGAN生成满足预期的颜色和装饰。OrnaNet的输入和输出是批量的RGB图像,而不是堆栈,其中每个字母的RGB通道,作为图像被反复填充进GlyphNet生成的相应灰度字形中。OrnaNet中也被填进多个正则项(regularizer),用于弥补生成字母的掩码与相应字形的偏差。
结果
下面是我们演示使用单个词中给出的字体样式的示例句子。
Given: 

![]()
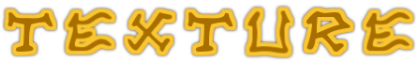
![]()
Given: 

![]()

![]()
Given: 

![]()

![]()
Given: 

![]()

![]()
另外,这里是OrnaNet预测的逐步过程:
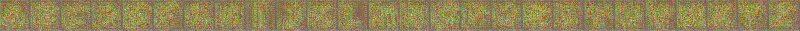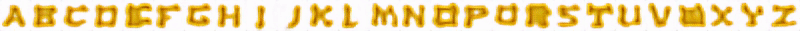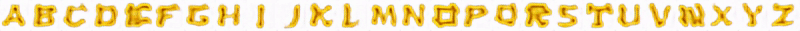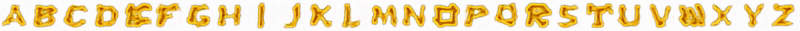
参考文献
[1] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. "Image-to-Image Translation with Conditional Adversarial Networks." CVPR 2017.
[2] Samaneh Azadi, Matthew Fisher, Vladimir Kim, Zhaowen Wang, Eli Shechtman, and Trevor Darrell. "Multi-Content GAN for Few-Shot Font Style Transfer." CVPR 2018.
