@sambodhi
2018-09-11T01:22:35.000000Z
字数 4702
阅读 3422
用想象的目标进行视觉强化学习

作者|Vitchyr Pong、Ashvin Nair
译者|sambodhi
编辑|Debra
AI前线导读:大家都知道,AlphaGo Zero完败AlphaGo,这背后就是深度强化学习的功劳。深度强化学习结合了深度学习和强化学习的优势,可以在复杂高维的状态动作空间中进行端到端的感知决策。今天,来自Berkeley的两位大佬给我们介绍了用想象的目标进行视觉强化学习,让我们来看看有什么新颖之处。
我们希望构建这样的智能体(Agent),它能够在非结构化的复杂环境中实现任意目标,例如可以做家务的个人机器人。有一种很有前途的方法就是:深度强化学习。这是一种强大的框架,用于以最大化的奖励函数(reward function)来教会智能体。就典型的强化学习范例来讲,包括训练智能体,以及手动设计奖励函数来解决单一任务。例如,我们可以如此训练机器人学会布置餐桌:通过设计一个奖励函数,这个函数基于每个盘子或器具与其目标位置之间的距离。这种设置要求有人为每个任务设计奖励函数,以及额外的系统,如物体探测器。这样的系统有可能代价昂贵,而且很脆弱。另外,如果我们想有能够做大量家务的机器人,就必须在每个新任务上重复这个强化学习的训练程序。

在设计奖励函数和设置传感器(如门角测量、物体探测器等)时,在模拟中可能很容易,但是在现实世界中很快就会变得不切实际了(见图右)。

我们训练智能体从视觉上来解决各种任务,无需额外的设备。图上一排显示的是目标图像,图下一排是实现这些目标的策略。
在本文中,我们讨论了强化学习算法,它可以用来同时学习多个不同的任务,无需额外的人工监督。智能体必须能够为自己设定目标,与环境进行交互,并评估是否已经实现了改善其行为的目标,所有这些目标都源自原始的观测,如图像等,而无需人工设计物体探测器等额外的组件。我们介绍了这一种系统:它能够设定抽象的目标,并进行自主学习来实现这一目标。然后,我们将展示使用这些自主学习的技能来执行各种用户指定的目标,如推动物体、抓取物体、开门等等,这些都无需额外的学习。最后我们证明这个方法是有效的,可以使Sawyer机器人在现实世界中如此工作。机器人只将图像作为系统的输入进行设定并实现目标,如将物体推送到特定的位置。
目标条件强化学习
我们如何表示现实世界的状况和目标呢?在多任务的设置中,要枚举机器人可能需要注意的所有物体,可能会变得不切实际:因为物体的数量、类型可能有所不同,而检测它们需要专用的视觉管道。相反,我们可以在机器人的传感器上直接操作,将状态表示为机器人摄像头的图像,目标表示为我们所希望的世界图景。要指定一个新任务,用户只需提供目标图景即可。我们注意到,这项工作可以扩展到更为复杂的方式来指定目标,例如通过语言、演示或通过优化目标(如博文《TDM: From Model-Free to Model-Based Deep Reinforcement Learning》所述 http://u6.gg/e6mqD)。

任务:像这副图片那样摆放餐具
强化学习是训练智能体将奖励最大化的形式。对于目标条件强化学习(goal-conditioned reinforcement learning),奖励的一个选择是当前状态和目标状态之间的负距离,因此最大化奖励对应于最小化到目标状态的距离。
我们可以训练单一策略来最大化奖励,通过首先学习目标条件Q函数(goal-conditioned Q function)来达到目标状态。在给定当前状态s和目标g的情况下,目标条件Q函数Q(s,a,g)会告诉我们动作a好到什么程度。例如,Q函数告诉我们,“如果我拿着一个盘子(state s),想把盘子放到桌子上(goal g),我应该将手臂举到什么程度(action,a)?”一旦训练了这个Q函数,那么你就可以通过执行以下优化来提取目标条件的策略。
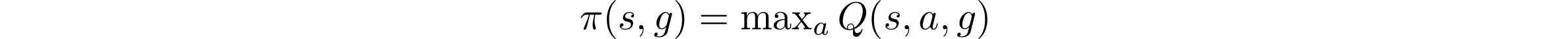
它会有效地说明:“根据此Q函数来选择最佳动作。”通过这一过程,我们就会获得一个最大化奖励总和的策略:达到不同的目标。
Q学习之所以如此受欢迎的原因之一就是,它能够以非策略的方式进行,这意味着我们训练Q函数所需的唯一事项是状态、动作、下一状态、目标和奖励的样本:(s,a,s',g,r)。这种数据可以由任何策略收集,并且可以在多个任务中重复使用。因此,一个简单的目标条件Q学习算法如下图所示是这样的:

收集数据是训练过程的主要瓶颈。如果我们能够以人工方式生成更多的数据,理论上我们就能够在不与世界互动的情况下学会解决各种任务。不幸的是,要学习准确的世界模型很困难,因此我们通常不得不依靠采样来获得state-action-next-state数据:(s,a,s')。但如果我们能有权访问奖励函数r(s,g),那么我们就可以追溯重新标记目标并验算奖励,允许在给定单个(s,a,s')元组的情况下,人为生成更多的数据。因此,我们可以像下图所示那样修改训练过程:

这个目标重采样的好处是,我们可以同时学习如何实现多个目标,而不需要来自环境的更多数据。总的来说,这种简单的修改可以大大加快学习速度。
上面概述的方法做了两个主要假设:
(1) 你可以使用奖励函数;
(2) 你可以使用目标抽样分布p(g)。
以前使用这个目标重标记策略的作品(Kaelbling ' 93(http://u6.gg/e6wN8)、Andrychowicz ' 17(http://u6.gg/e6wNN)、Pong '18(http://u6.gg/e6wPn))对地面实况状态信息(如物体的笛卡尔坐标位置)进行操作,其中就很容易进行手动设计目标分布p(g)和奖励函数。然而,当我们转向基于视觉的任务时,目标就成为了图像,这两个假设就引入了实际问题。首先,我们并不清楚应该使用哪个奖励函数,因为,到目标图像的像素距离可能在语义上没有意义;其次,因为我们的目标是图像,所以我们需要一个目标的图像分布p(g),以便可以从中进行采样目标图像。手动设计目标图像分布是一项非常重要的任务,图像生成仍然是活跃的研究领域之一。我们希望智能体能够自主设定自己的目标,并学习如何实现这些目标。
用想象的目标进行强化学习
我们可以这样减轻与目标-图像条件Q学习(goal-image conditioned Q learning)相关的挑战:通过学习图像的表示,而不是图像本身。关键问题是:我们的表示应该满足哪些属性?为了计算语义上有意义的奖励,我们需要一种能够捕捉图像变化的潜在因素的表示。此外,我们还需要一种能够轻松生成新目标的方法。
我们通过首先训练生成潜变量模型(latent variable model)来实现这些目标,在我们的示例中,就是变分自动编码器(variational autoencoder,VAE。参见:https://arxiv.org/abs/1312.6114)。这种生成模型将高维观察x(如图像)转换为低维潜变量z,反之亦然。该模型的训练,使潜变量捕捉图像变化中的潜在因素,类似于人类用于解释世界和目标的抽象表示。给定当前图像x和目标图像 ,我们将它们分别转换为潜变量z和
,我们将它们分别转换为潜变量z和 。然后,我们使用这些潜变量表示我们的强化学习算法的状态和目标。在这个低维潜空间之上而不是很直接在图像上进行学习Q函数和策略,这样就可以加快学习速度。
。然后,我们使用这些潜变量表示我们的强化学习算法的状态和目标。在这个低维潜空间之上而不是很直接在图像上进行学习Q函数和策略,这样就可以加快学习速度。

智能体将当前的图像(x)和目标图像()编码到潜空间中,并在这个潜空间使用距离作为奖励。
使用图像和目标的潜变量还解决了另一个问题:如何计算奖励。我们没有使用像素级的错误作为奖励,而是使用潜空间中的距离作为奖励来训练智能体实现目标。在这篇完整描述这一方法的研究论文(https://arxiv.org/abs/1807.04742v1)中,证明了这对应于最大化到达目标的概率并提供更有效的学习信号。
这种生成模型也很重要,因为它允许智能体在潜空间中轻松生成目标。特别是我们的生成模型的设计是为了采样潜变量是微不足道的:我们只是从VAE先验采样潜变量。我们使用这种采样机制出于这两种原因:首先,它为智能体设定自己的目标提供了一种机制。智能体只是从生成模型中对潜变量的值进行采样,并试图达到那个潜在目标。第二,这种重采样机制也用于重新标记如上所述的目标。因为我们的生成模型经训练后可以将真实图像编码成先验图像中,因此潜变量先验的样本对应于有意义的潜在目标。

即使没人提供目标,我们的智能体仍然可以生成自己的目标,用于探索和重新标记目标。
(1) 捕捉场景的潜在因素;
(2) 提供有意义的距离来优化;
(3) 提供有效的目标采样机制;允许我们有效地训练一个目标条件下的强化学习智能体,直接在像素上进行操作。这种方法,我们称为“用想象目标进行强化学习”(reinforcement learning with imagined goals,RIG)。
实验
我们进行了一些实验,测试RIG是否具备足够的采样效率,能够在合理的时间内训练真实世界的机器人策略。我们测试了机器人到达用户指定位置并将物体推送到所需位置的能力,如目标物体所示。机器人被训练为只能访问84x84大小的RGB图像,不能访问关节角度或物体位置。机器人首先通过在潜空间中设定自己的目标进行学习。我们可以使用解码器将机器人想象出来的目标进行可视化。在下面的GIF动图中,顶部框架显示了解码后的“想象”目标,而底部框架显示了实际策略的推出。

机器人设定自己的目标(图上)并练习达到目标(图下)。
通过设定自己的目标,机器人就可以在没有人类参与的情况下自主练习到达不同的位置。人类唯一参与的环节是当他想让机器人执行特定任务的时候。这个时候,给机器人一个目标图像,因为机器人已经练习达到这么多目标,我们就可以看到它能够在没有额外训练的情况下达到这个目标:

人类给出目标图像(图上),机器人到达目标图像(图下)。
我们还使用RIG来训练一个策略,以将物体推到目标位置:

左图:Sawyer机器人设置。右上图:人类给出的目标物体;右下图:机器人到达目标图像。
直接从图像训练策略可以很轻松地变更任务,如到达变更为推送物体。我们只需添加一个物体、一个表格,然后调整相机即可。最后,尽管是直接从像素开始工作的,但这些实验并没有花费很长时间。达到的结果大约需要一个小时,而推动结果需要大约4.5小时的真实机器人交互时间。许多真实世界的机器人强化学习结果使用地面真实状态信息,比如物体的位置。但这通常就需要额外的设备了,比如购买和设置额外的传感器或训练物体检测系统。相比之下,我们的方法只需RGB相机,就可以直接从图像开始工作。
未来研究方向
我们已经证明,可以直接从图像中训练一个现实世界的机器人策略,以高效采样的方式完成各种任务。这个项目接下来,还有许多令人兴奋的步骤。然而用目标图像来表示所有的任务是不大可能的,但可以使用其他模式来表示目标,如语言和演示。此外,虽然我们提供了一种机制来对自主探索的目标进行采样,但我们能否以一种更有原则的方式来选择这些目标来进行更好的探索呢?结合内在动机的想法将允许我们的策略积极选择目标,为策略提供信息,从而更快地了解它能够和不能达到的目标。未来的另一个方向是训练我们的生成模型,使其能够感知环境动态。对环境动态的信息进行编码可以使潜空间更适合强化学习,从而加快学习速度。最后,还有各种机器人任务,它们的状态表示难以用传感器捕获,例如,操作可变形的物体,或者处理可变数量的物体的场景。如何让RIG来解决这类任务,是未来的研究方向,这很令人兴奋。
