@sambodhi
2018-06-21T08:41:47.000000Z
字数 4380
阅读 2644
Top 20 Python libraries for data science in 2018
为数据科学在2018年前20名Python库
data sciencemachine learningpython

Python在解决数据科学任务和挑战方面继续处于领先地位。去年,我们发表了一篇博客文章 Top 15 Python Libraries for Data Science in 2017,概述了当时业已证明最有帮助的Python的库。今年,我们扩展了这个名单,增加了新的Python库,并重新审视了去年已经讨论过的Python库,重点关注了这一年来所做的更新。
我们的选择实际上包含了20多个库,因为其中一些库是相互替代的,可以解决相同的问题。因此,我们将它们分组。
核心库和统计数据
1. NumPy (Commits: 17911, Contributors: 641)
官网:http://www.numpy.org/
NumPy是科学应用程序库的主要软件包之一,用于处理大型多维数组和矩阵,它大量的高级数学函数集合和实现方法使得这些对象执行操作成为可能。
2. SciPy (Commits: 19150, Contributors: 608)
官网:https://scipy.org/scipylib/
科学计算的另一个核心库是SciPy。它基于NumPy,因此扩展了它的功能。SciPy主数据结构又是一个多维数组,由Numpy实现。这个软件包包含了帮助解决线性代数、概率论、积分计算和许多其他任务的工具。
此外,SciPy还封装了许多新的BLAS和LAPACK函数。
3. Pandas (Commits: 17144, Contributors: 1165)
官网:https://pandas.pydata.org/
Pandas是一个Python库,提供高级的数据结构和各种各样的分析工具。这个软件包的主要特点是能够将相当复杂的数据操作转换为一个或两个命令。Pandas包含许多用于分组、过滤和组合数据的内置方法,以及时间序列功能。
4. StatsModels (Commits: 10067, Contributors: 153)
官网:http://www.statsmodels.org/devel/
Statsmodels是一个Python模块,它为统计数据分析提供了许多机会,例如统计模型估计、执行统计测试等。在它的帮助下,您可以实现许多机器学习方法并探索不同的绘制可能性。
Python库不断发展,不断丰富新的机遇。因此,今年出现了时间序列的改进和新的计数模型,即GeneralizedPoisson、零捧场模型(zero inflated models)和NegativeBinomialP,以及新的多元方法:因子分析、多元方差分析以及方差分析中的重复测量。
可视化
5. Matplotlib (Commits: 25747, Contributors: 725)
官网:https://matplotlib.org/index.html
Matplotlib是一个用于创建二维图和图形的底层库。藉由它的帮助,您可以构建各种不同的图标,从直方图和散点图到费笛卡尔坐标图。此外,有许多流行的绘图库被设计为与matplotlib结合使用。
6. Seaborn (Commits: 2044, Contributors: 83)
官网:https://seaborn.pydata.org/
Seaborn本质上是一个基于matplotlib库的高级API。它包含更适合处理图表的默认设置。此外,还有丰富的可视化库,包括一些复杂类型,如时间序列、联合分布图(jointplots)和小提琴图(violin diagrams)。
7. Plotly (Commits: 2906, Contributors: 48)
官网:https://plot.ly/python/
Plotly是一个流行的库,它可以让您轻松地构建复杂的图形。该软件包适用于交互式Web应用程序。在它非凡的视觉效果中有轮廓图、三元图和三维图。
8. Bokeh (Commits: 16983, Contributors: 294)
官网:https://bokeh.pydata.org/en/latest/
Bokeh库使用JavaScript小部件在浏览器中创建交互式和可缩放的可视化。该库提供了图形、样式可能性(styling possibilities)、以链接图、添加小部件和定义回调等形式的交互能力以及许多更有用的特性。
9. Pydot (Commits: 169, Contributors: 12)
官网:https://pypi.org/project/pydot/
Pydot是一个用于生成复杂的定向图和无向图的库。它是用纯Python编写的Graphviz接口。在它的帮助下,可以显示图形的结构,这在构建神经网络和基于决策树的算法时是经常需要的。
机器学习
10. Scikit-learn (Commits: 22753, Contributors: 1084)
官网:http://scikit-learn.org/stable/
这个基于NumPy和SciPy的Python模块是处理数据的最佳库之一。它为许多标准的机器学习和数据挖掘任务提供算法,如聚类、回归、分类、降维和模型选择。
Improve your skills with Data Science School
利用数据科学学院提高您的技能
11. XGBoost / LightGBM / CatBoost (Commits: 3277 / 1083 / 1509, Contributors: 280 / 79 / 61)
梯度增强算法是最流行的机器学习算法之一,它是建立一个不断改进的基本模型,即决策树。因此,为了快速、方便地实现这个方法而设计了专门库。就是说,我们认为XGBoost、LightGBM和CatBoost值得特别关注。它们都是解决常见问题的竞争者,并且使用方式几乎相同。这些库提供了高度优化的、可扩展的、快速的梯度增强实现,这使得它们在数据科学家和Kaggle竞争对手中非常流行,因为在这些算法的帮助下赢得了许多比赛。
12. Eli5 (Commits: 922, Contributors: 6)
官网:https://eli5.readthedocs.io/en/latest/
通常情况下,机器学习模型预测的结果并不完全清楚,这正是Eli5帮助应对的挑战。它是一个用于可视化和调试机器学习模型并逐步跟踪算法工作的软件包,为scikit-learn、XGBoost、LightGBM、lightning和sklearn-crfsuite库提供支持,并为每个库执行不同的任务。
深度学习
13. TensorFlow (Commits: 33339, Contributors: 1469)
官网:https://www.tensorflow.org/
TensorFlow是一个流行的深度学习和机器学习框架,由Google Brain开发。它提供了使用具有多个数据集的人工神经网络的能力。在最流行的TensorFlow应用中有目标识别、语音识别等。在常规的TensorFlow上也有不同的leyer-helper,如tflearn、tf-slim、skflow等。
14. PyTorch (Commits: 11306, Contributors: 635)
PyTorch是一个大型框架,它允许您使用GPU加速执行张量计算,创建动态计算图并自动计算梯度。在此之上,PyTorch为解决与神经网络相关的应用程序提供了丰富的API。该库基于Torch,是用C实现的开源深度学习库,在Lua中有一个包装器。
15. Keras (Commits: 4539, Contributors: 671)
Keras是一个用于处理神经网络的高级库,运行在TensorFlow、Theano之上,现在由于新版本的发布,还可以使用CNTK和MxNet作为后端。它简化了许多特定的任务,并且大大减少了单调代码的数量。然而,它可能不适合一些复杂的事情。
分布式深度学习
16. Dist-keras / elephas / spark-deep-learning (Commits: 1125 / 170 / 67, Contributors: 5 / 13 / 11)
随着越来越多的用例需要花费大量的精力和时间,深度学习问题变得越来越重要。然而,使用像Apache Spark这样的分布式计算系统,处理如此多的数据要容易得多,这再次扩展了深入学习的可能性。因此,dist-keras、elephas和spark-deep-learning都在迅速流行和发展,而且很难挑出一个库,因为它们都是为解决共同的任务而设计的。这些包允许您在Apache Spark的帮助下直接训练基于Keras库的神经网络。Spark-deep-learning还提供了使用Python神经网络创建管道的工具。
自然语言处理
17. NLTK (Commits: 13041, Contributors: 236)
NLTK是一组库,一个用于自然语言处理的完整平台。在NLTK的帮助下,您可以以各种方式处理和分析文本,对文本进行标记和标记,提取信息等。NLTK也用于原型和建立研究系统。
18. SpaCy (Commits: 8623, Contributors: 215)
SpaCy是一个具有优秀示例、API文档和演示应用程序的自然语言处理库。库是用Cython语言编写的,Cython是Python的C扩展。它支持近30种语言,提供了简单的深度学习集成,保证了健壮性和高准确率。SpaCy的另一个重要特性是专为整个文档处理设计的体系结构,无须将文档分解成短语。
19. Gensim (Commits: 3603, Contributors: 273)
Gensim是一个用于健壮语义分析、主题建模和向量空间建模的Python库,构建在Numpy和Scipy之上。它提供了流行的NLP算法的实现,如word2vec。尽管gensim有自己的models.wrappers.fasttext实现,但fasttext库也可以用户高效学习词语表示。
数据采集
20. Scrapy (Commits: 6625, Contributors: 281)
Scrapy是一个库,用来创建网络爬虫,扫描网页和收集结构化数据。此外,Scrapy可以从API中提取数据。由于该库的可扩展性和可移植性,使得它非常方便。
结论
本文上述所列就是我们在2018年为数据科学领域中丰富的Python库集合。与上一年相比,一些新的现代库越来越受欢迎,而那些已经成为经典的数据科学任务的库也在不断改进。
下表显示了GitHub活动的详细统计数据:
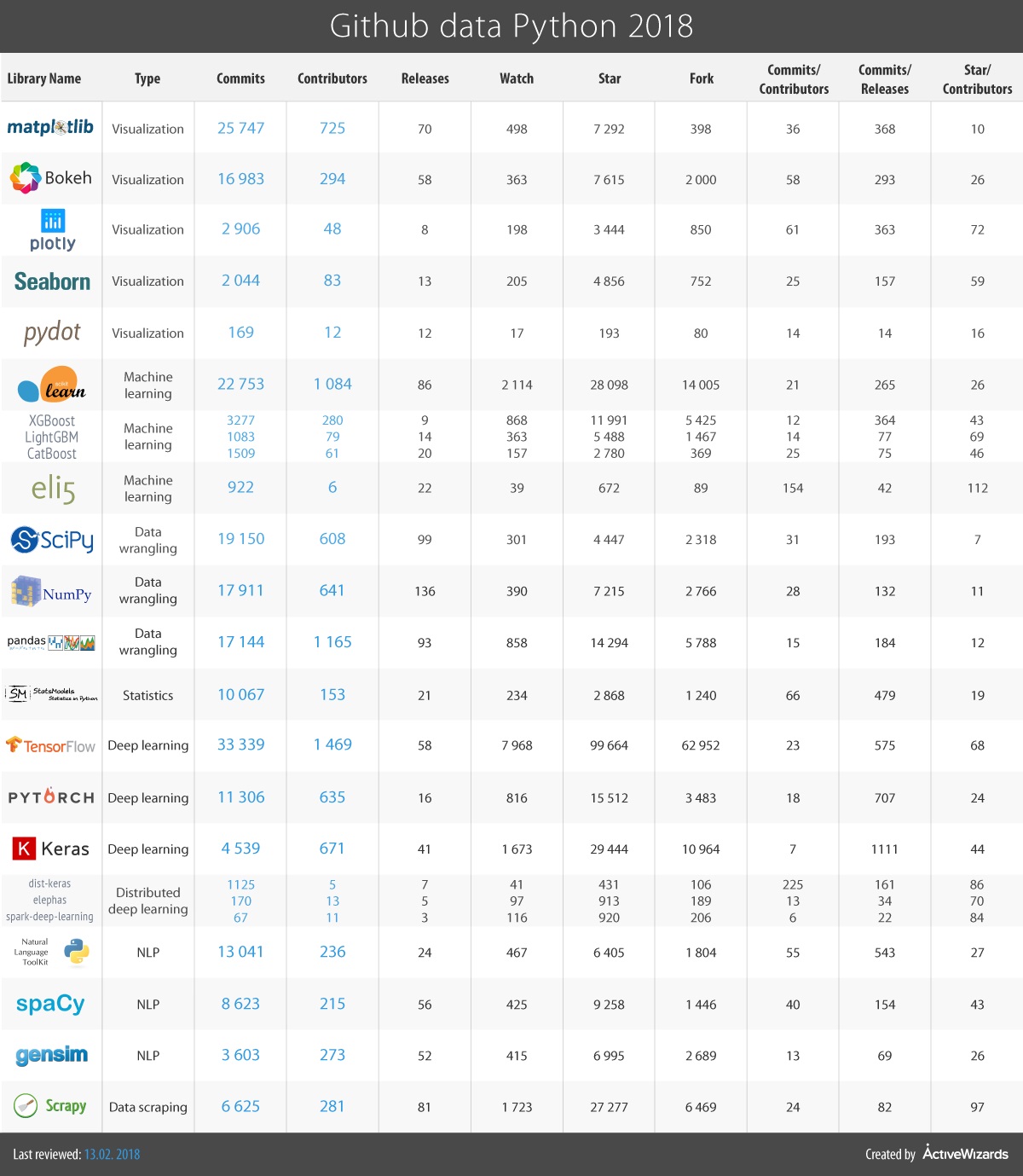
尽管今年我们扩展了这份清单,但它并不能涵盖所有其他一些值得关注的库。
