@sambodhi
2017-12-05T06:15:10.000000Z
字数 6708
阅读 5506

TensorFlow的多平台基准测试
作者|TensorFlow团队
编辑|Vincent
AI前线导语:为了选择图像分类模型,TensorFlow团队日前在多个平台上进行了基准测试[1],为TensorFlow社区提供一个参考。本文中的“方法”一节,详细介绍了如何进行测试,并给出了所用脚本的链接。
更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
图像分类模型的结果
InceptionV3[2]、ResNet-50[3]、ResNet-152[4]、VGG16[5]和AlexNet[6]使用ImageNet[7]数据集进行测试。测试环境为Google Compute Engine、Elastic Compute Cloud (Amazon EC2)和NVIDIA® DGX-1™。大部分测试使用了合成数据和真实数据。使用合成数据进行测试是通过一个tf.Variable完成的,它被设置为与ImageNet的每个模型预期的数据相同的形状。我们认为,在基准测试平台中,包含真实数据的测量非常重要。这个负载测试底层硬件和框架,用来准备实际训练的数据。我们从合成数据开始,将磁盘I/O作为一个变量移除,并设置一个基线。然后,用真实数据来验证TensorFlow输入管道和底层磁盘I/O是否饱和的计算单元。
使用 NVIDIA® DGX-1™ (NVIDIA® Tesla® P100) 进行训练
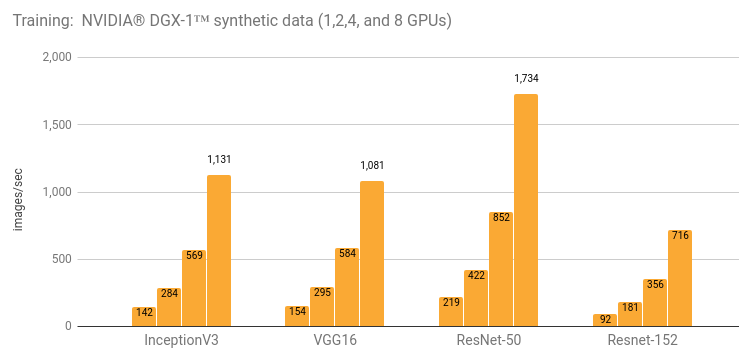
详情和额外的结果请参阅“NVIDIA® DGX-1™ (NVIDIA® Tesla® P100)”一节。
使用 NVIDIA® Tesla® K80进行训练
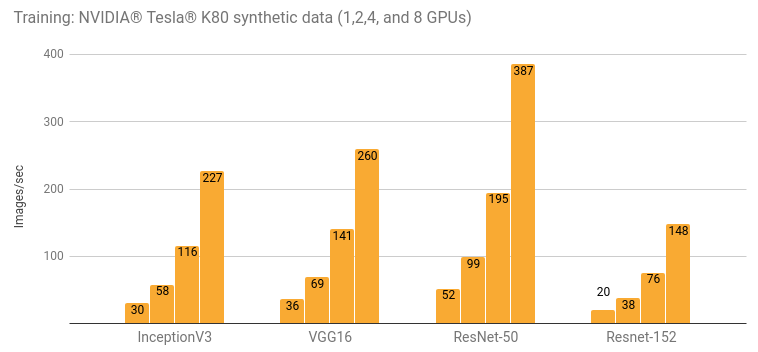
详情和额外的结果请参阅“Google Compute Engine (NVIDIA® Tesla® K80)”一节和“Amazon EC2 (NVIDIA® Tesla® K80)”一节。
使用NVIDIA® Tesla® K80进行分布式训练
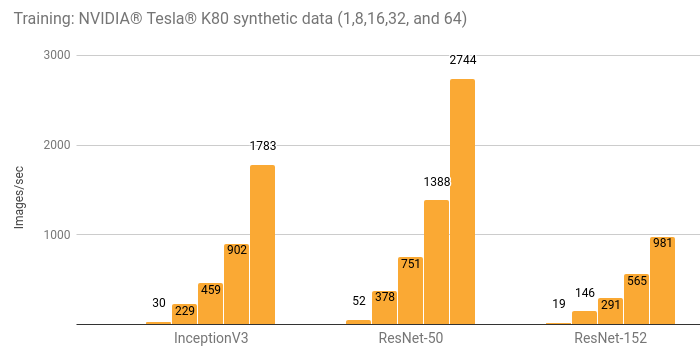
详情和额外的结果请参阅“Amazon EC2 Distributed (NVIDIA® Tesla® K80)”一节。
使用合成数据和真实数据进行训练的比较
NVIDIA® Tesla® P100
NVIDIA® Tesla® K80
NVIDIA® DGX-1™ (NVIDIA® Tesla® P100)详情
环境
- Instance type: NVIDIA® DGX-1™
- GPU: 8x NVIDIA® Tesla® P100
- OS: Ubuntu 16.04 LTS with tests run via Docker
- CUDA / cuDNN: 8.0 / 5.1
- TensorFlow GitHub hash: b1e174e
- Benchmark GitHub hash: 9165a70
- Build Command:
bazel build -c opt --copt=-march="haswell" --config=cuda //tensorflow/tools/pip_package:build_pip_package - Disk: Local SSD
- DataSet: ImageNet
- Test Date: May 2017
每个模型所使用的批量大小及优化器,如下表所示。除下表所列的批量大小外,InceptionV3、ResNet-50、ResNet-152和VGG16使用批量大小为32进行测试。这些结果在“其他结果”一节中。
| Options | InceptionV3 | ResNet-50 | ResNet-152 | AlexNet | VGG16 |
|---|---|---|---|---|---|
| Batch size per GPU | 64 | 64 | 64 | 512 | 64 |
| Optimizer | sgd | sgd | sgd | sgd | sgd |
用于每个模型的配置如下表:
| Model | variable_update | local_parameter_device |
|---|---|---|
| InceptionV3 | parameter_server | cpu |
| ResNet50 | parameter_server | cpu |
| ResNet152 | parameter_server | cpu |
| AlexNet | replicated (with NCCL) | n/a |
| VGG16 | replicated (with NCCL) | n/a |
结果
训练合成数据
| GPUs | InceptionV3 | ResNet-50 | ResNet-152 | AlexNet | VGG16 |
|---|---|---|---|---|---|
| 1 | 142 | 219 | 91.8 | 2987 | 154 |
| 2 | 284 | 422 | 181 | 5658 | 295 |
| 4 | 569 | 852 | 356 | 10509 | 584 |
| 8 | 1131 | 1734 | 716 | 17822 | 1081 |
训练真实数据
| GPUs | InceptionV3 | ResNet-50 | ResNet-152 | AlexNet | VGG16 |
|---|---|---|---|---|---|
| 1 | 142 | 218 | 91.4 | 2890 | 154 |
| 2 | 278 | 425 | 179 | 4448 | 284 |
| 4 | 551 | 853 | 359 | 7105 | 534 |
| 8 | 1079 | 1630 | 708 | N/A | 898 |
在上述图标和表格中,排除了在8个GPU上使用真实数据训练的AlexNet,因为它将输入管线最大化了。
其他结果
下面的结果,都是批量大小为32。
训练合成数据
| GPUs | InceptionV3 | ResNet-50 | ResNet-152 | VGG16 |
|---|---|---|---|---|
| 1 | 128 | 195 | 82.7 | 144 |
| 2 | 259 | 368 | 160 | 281 |
| 4 | 520 | 768 | 317 | 549 |
| 8 | 995 | 1485 | 632 | 820 |
训练真实数据
| GPUs | InceptionV3 | ResNet-50 | ResNet-152 | VGG16 |
|---|---|---|---|---|
| 1 | 130 | 193 | 82.4 | 144 |
| 2 | 257 | 369 | 159 | 253 |
| 4 | 507 | 760 | 317 | 457 |
| 8 | 966 | 1410 | 609 | 690 |
Google Compute Engine (NVIDIA® Tesla® K80)详情
环境
- Instance type: n1-standard-32-k80x8
- GPU: 8x NVIDIA® Tesla® K80
- OS: Ubuntu 16.04 LTS
- CUDA / cuDNN: 8.0 / 5.1
- TensorFlow GitHub hash: b1e174e
- Benchmark GitHub hash: 9165a70
- Build Command:
bazel build -c opt --copt=-march="haswell" --config=cuda //tensorflow/tools/pip_package:build_pip_package - Disk: 1.7 TB Shared SSD persistent disk (800 MB/s)
- DataSet: ImageNet
- Test Date: May 2017
如下表所示,列出了每种模型使用的批量大小及优化器。除去表中所列的批量之外,Inception V3和ResNet-50的批量大小为32。这些结果在“其他结果”一节。
| Options | InceptionV3 | ResNet-50 | ResNet-152 | AlexNet | VGG16 |
|---|---|---|---|---|---|
| Batch size per GPU | 64 | 64 | 32 | 512 | 32 |
| Optimizer | sgd | sgd | sgd | sgd | sgd |
用于每个模型的配置的variable_update、 parameter_server、local_parameter_device 和cpu,它们是相等的。
结果
训练合成数据
| GPUs | InceptionV3 | ResNet-50 | ResNet-152 | AlexNet | VGG16 |
|---|---|---|---|---|---|
| 1 | 30.5 | 51.9 | 20.0 | 656 | 35.4 |
| 2 | 57.8 | 99.0 | 38.2 | 1209 | 64.8 |
| 4 | 116 | 195 | 75.8 | 2328 | 120 |
| 8 | 227 | 387 | 148 | 4640 | 234 |
训练真实数据
| GPUs | InceptionV3 | ResNet-50 | ResNet-152 | AlexNet | VGG16 |
|---|---|---|---|---|---|
| 1 | 30.6 | 51.2 | 20.0 | 639 | 34.2 |
| 2 | 58.4 | 98.8 | 38.3 | 1136 | 62.9 |
| 4 | 115 | 194 | 75.4 | 2067 | 118 |
| 8 | 225 | 381 | 148 | 4056 | 230 |
其他结果
训练合成数据
| GPUs | InceptionV3 (batch size 32) | ResNet-50 (batch size 32) |
|---|---|---|
| 1 | 29.3 | 49.5 |
| 2 | 55.0 | 95.4 |
| 4 | 109 | 183 |
| 8 | 216 | 362 |
训练真实数据
| GPUs | InceptionV3 (batch size 32) | ResNet-50 (batch size 32) |
|---|---|---|
| 1 | 29.5 | 49.3 |
| 2 | 55.4 | 95.3 |
| 4 | 110 | 186 |
| 8 | 216 | 359 |
Amazon EC2 (NVIDIA® Tesla® K80)详情
环境
- Instance type: p2.8xlarge
- GPU: 8x NVIDIA® Tesla® K80
- OS: Ubuntu 16.04 LTS
- CUDA / cuDNN: 8.0 / 5.1
- TensorFlow GitHub hash: b1e174e
- Benchmark GitHub hash: 9165a70
- Build Command:
bazel build -c opt --copt=-march="haswell" --config=cuda //tensorflow/tools/pip_package:build_pip_package - Disk: 1TB Amazon EFS (burst 100 MiB/sec for 12 hours, continuous 50 MiB/sec)
- DataSet: ImageNet
- Test Date: May 2017
下标列出了每种模型所使用的批量大小和优化器。除去表中所列的批量大小外,InceptionV3和ResNet-50的批量大小为32。这些结果都在“其他结果”一节中。
| Options | InceptionV3 | ResNet-50 | ResNet-152 | AlexNet | VGG16 |
|---|---|---|---|---|---|
| Batch size per GPU | 64 | 64 | 32 | 512 | 32 |
| Optimizer | sgd | sgd | sgd | sgd | sgd |
用于每个模型的配置。
| Model | variable_update | local_parameter_device |
|---|---|---|
| InceptionV3 | parameter_server | cpu |
| ResNet-50 | replicated (without NCCL) | gpu |
| ResNet-152 | replicated (without NCCL) | gpu |
| AlexNet | parameter_server | gpu |
| VGG16 | parameter_server | gpu |
结果
训练合成数据
| GPUs | InceptionV3 | ResNet-50 | ResNet-152 | AlexNet | VGG16 |
|---|---|---|---|---|---|
| 1 | 30.8 | 51.5 | 19.7 | 684 | 36.3 |
| 2 | 58.7 | 98.0 | 37.6 | 1244 | 69.4 |
| 4 | 117 | 195 | 74.9 | 2479 | 141 |
| 8 | 230 | 384 | 149 | 4853 | 260 |
训练真实数据
| GPUs | InceptionV3 | ResNet-50 | ResNet-152 | AlexNet | VGG16 |
|---|---|---|---|---|---|
| 1 | 30.5 | 51.3 | 19.7 | 674 | 36.3 |
| 2 | 59.0 | 94.9 | 38.2 | 1227 | 67.5 |
| 4 | 118 | 188 | 75.2 | 2201 | 136 |
| 8 | 228 | 373 | 149 | N/A | 242 |
由于我们的EFS设置未能提供足够的吞吐量,因此在上述图标和表格中,排除了在8个GPU上使用真实数据来训练AlexNet。
其他结果
训练合成数据
| GPUs | InceptionV3 (batch size 32) | ResNet-50 (batch size 32) |
|---|---|---|
| 1 | 29.9 | 49.0 |
| 2 | 57.5 | 94.1 |
| 4 | 114 | 184 |
| 8 | 216 | 355 |
训练真实数据
| GPUs | InceptionV3 (batch size 32) | ResNet-50 (batch size 32) |
|---|---|---|
| 1 | 30.0 | 49.1 |
| 2 | 57.5 | 95.1 |
| 4 | 113 | 185 |
| 8 | 212 | 353 |
Amazon EC2 Distributed (NVIDIA® Tesla® K80)详情
环境
- Instance type: p2.8xlarge
- GPU: 8x NVIDIA® Tesla® K80
- OS: Ubuntu 16.04 LTS
- CUDA / cuDNN: 8.0 / 5.1
- TensorFlow GitHub hash: b1e174e
- Benchmark GitHub hash: 9165a70
- Build Command:
bazel build -c opt --copt=-march="haswell" --config=cuda //tensorflow/tools/pip_package:build_pip_package - Disk: 1.0 TB EFS (burst 100 MB/sec for 12 hours, continuous 50 MB/sec)
- DataSet: ImageNet
- Test Date: May 2017
下表列出了用于测试的批量大小和优化器。除去表中所列的批量大小之外,InceptionV3和ResNet-50的批量大小为32。这些结果包含在“其他结果”一节。
| Options | InceptionV3 | ResNet-50 | ResNet-152 |
|---|---|---|---|
| Batch size per GPU | 64 | 64 | 32 |
| Optimizer | sgd | sgd | sgd |
用于每个模型的配置。
| Model | variable_update | local_parameter_device | cross_replica_sync |
|---|---|---|---|
| InceptionV3 | distributed_replicated | n/a | True |
| ResNet-50 | distributed_replicated | n/a | True |
| ResNet-152 | distributed_replicated | n/a | True |
为简化服务器设置,运行工作服务器的EC2实例(p2.8xlarge)也运行着参数服务器。使用相同数量的参数服务器和工作服务器,不同之处在于:
- InceptionV3: 8 instances / 6 parameter servers
- ResNet-50: (batch size 32) 8 instances / 4 parameter servers
- ResNet-152: 8 instances / 4 parameter servers
结果
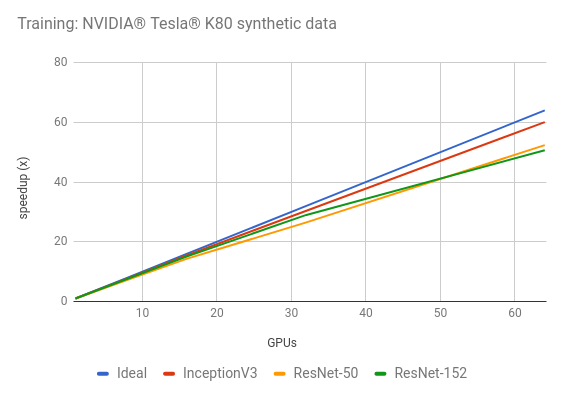
训练合成数据
| GPUs | InceptionV3 | ResNet-50 | ResNet-152 |
|---|---|---|---|
| 1 | 29.7 | 52.4 | 19.4 |
| 8 | 229 | 378 | 146 |
| 16 | 459 | 751 | 291 |
| 32 | 902 | 1388 | 565 |
| 64 | 1783 | 2744 | 981 |
其他结果
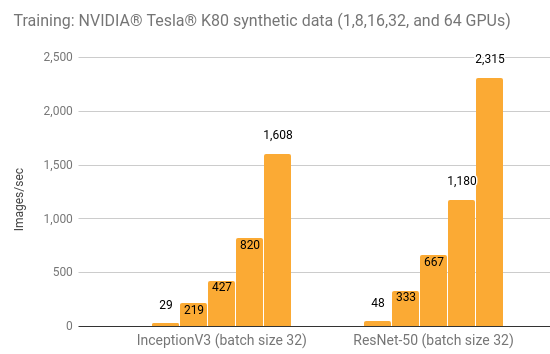
训练合成数据
| GPUs | InceptionV3 (batch size 32) | ResNet-50 (batch size 32) |
|---|---|---|
| 1 | 29.2 | 48.4 |
| 8 | 219 | 333 |
| 16 | 427 | 667 |
| 32 | 820 | 1180 |
| 64 | 1608 | 2315 |
方法
这个脚本[8]运行在不同的平台上,产生上述结果。高性能模型[9]详细介绍了脚本中的技巧及如何执行脚本的示例。
为了尽可能达到重复的结果,每个测试运行五次,然后平均一下时间。GPU在给定平台上,以缺省状态运行。对于NVIDIA®Tesla®K80,这意味着要离开GPU Boost[10]。每次测试,都要完成10个预热步骤,然后对接下来的100个步骤进行平均。
[1] Benchmarks:
https://www.tensorflow.org/performance/benchmarks ↩
[2] Rethinking the Inception Architecture for Computer Vision:
https://arxiv.org/abs/1512.00567 ↩
[3] Deep Residual Learning for Image Recognition:
https://arxiv.org/abs/1512.03385 ↩
[4] Deep Residual Learning for Image Recognition:
https://arxiv.org/abs/1512.03385 ↩
[5] Very Deep Convolutional Networks for Large-Scale Image Recognition:
https://arxiv.org/abs/1409.1556 ↩
[6] ImageNet Classification with Deep Convolutional Neural Networks:
http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf ↩
[7] ImageNet:
http://www.image-net.org/ ↩
[8] tf_cnn_benchmarks: High performance benchmarks:
https://github.com/tensorflow/benchmarks/tree/master/scripts/tf_cnn_benchmarks ↩
[9] High-Performance Models:
https://www.tensorflow.org/performance/benchmarks ↩
[10] Increase Performance with GPU Boost and K80 Autoboost:
https://devblogs.nvidia.com/parallelforall/increase-performance-gpu-boost-k80-autoboost/ ↩
