@sambodhi
2018-07-05T09:29:45.000000Z
字数 3908
阅读 3834
在此处输入标题
CSDN
Google Chrome # Learning to drive in a day.
The first example of reinforcement learning on-board an autonomous car.
强化学习在自动驾驶的应用一例
你还记得小时候学骑自行车的情景吗?又兴奋,又有一点点焦虑。你可能是第一次坐在自行车上,踩着踏板,大人跟随在你身边,准备在你失去平衡的时候扶住你。在一些摇摆不定的尝试之后,你可能设法保持了几米的平衡。几个小时过去了,你可能在公园里的沙砾和草地上飞驰。
大人只会给你一些简短的提示。你不需要一张公园的密集3D地图,也不需要在头上装一个高保真激光摄像头。你也不需要遵循一长串的规则就能在自行车上保持平衡。大人只是为你提供了一个安全的环境,让你学会如何根据你所见来决定你的行为,从而成功学会骑车。
如今,自动驾驶汽车安装了大量的传感器,并通过缓慢的开发周期中被告知如何通过一长串精心设计的规则来驾驶车辆。在本文中,我们将回到基础,让汽车从零开始学会如何通过试错法来学会自动驾驶,就像你学骑自行车一样。看看我们做了什么:
只用了15~20分钟,我们就能够教会一辆汽车从零开始沿着一条车道行驶,而这只有当安全驾驶员接手时作为训练反馈才使用。
无需密集3D地图,无需手绘规则
这是自动驾驶汽车在网上学习的第一个例子,每一次尝试都会让它变得更好。那么,我们是怎么做到的呢?
我们采用了一种流行的无模型深度强化学习算法(深度确定性策略梯度:deep deterministic policy gradients,DDPG)来解决车道跟踪问题。我们的模型输入是单目镜摄像头图像。我们的系统迭代了三个过程:探索、优化和评估。
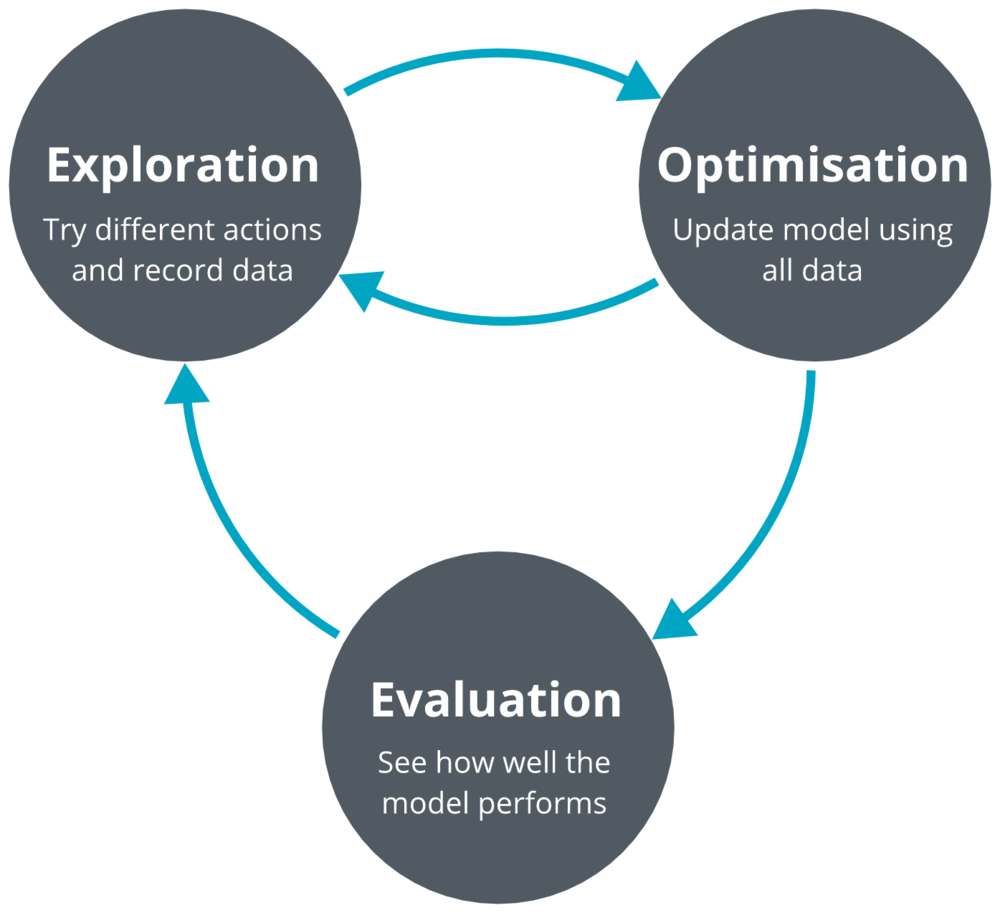
我们的网络架构是一个深度网络,有4个卷积层和3个完全连接的层,总共略低于10k个参数。为了比较,现有技术的图像分类体系结构有数百万个参数。

所有的处理都是在汽车上的一个图形处理单元(GPU)上执行的。
在危险的真实环境中使用真正的机器人会带来很多新问题。为了更好地理解手头的任务,并找到合适的模型架构和超参数,我们进行了大量的仿真测试。

上面动图所示,是我们的车道跟随不同角度显示的模拟环境的示例。这个算法只能看到驾驶员的视角,也就是图中有青色边框的图像。在每一次模拟中,我们都会随机生成一条弯曲的车道,以及道路纹理和车道标记。智能体会一直探索,直到模拟终止时它才离开。然后根据手机到的数据进行策略优化,我们重复这样的步骤。

在安全驾驶员接管之前,汽车行驶的距离与模拟探索的数量有关。
我们使用模拟测试来尝试不同的神经网络架构和超参数,直到我们找到一致的设置,这些设置在很少的训练集中,也就是几乎没有数据的情况下,始终如一地解决了车道跟随的任务。例如,我们的发现之一,是使用自动编码器重构损失训练卷积层可以显著提高训练的稳定性和数据效率。更多详情请参阅我们完整的技术报告。
我们的方法的潜在影响是巨大的。
想象一下,部署一支自动驾驶车队,使用一种最初只有人类司机95%质量的驾驶算法。这样一个系统将不会像我们的演示视频中的随机初始化模型那样摇摇晃晃地行驶,而是几乎能够处理交通信号灯、环形交叉路口、十字路口等道路情况。经过一天的驾驶和人类安全驾驶员接管的在线改进后,系统也许可以提高到96%。一个星期以后,提高到98%。一个月以后,提高到99%。几个月以后,这个系统可能会变得超人类,因为它从许多不同的安全驾驶员的反馈中受益得以提高。
Today’s self-driving cars are stuck at good but not good enough performance levels. Here, we have provided evidence for the first viable framework to quickly improving driving algorithms from being mediocre to being roadworthy. The ability to quickly learn to solve tasks through clever trial and error is what has made humans incredibly versatile machines capable of evolution and survival. We learn through a mixture of imitation, and lots of trial and error for everything from riding a bicycle, to learning how to cook.
今天的自动驾驶汽车仍停留在良好的状态,但性能水平还不够好。在本文中,我们为第一个可行的框架提供了证据,以便快速改善驾驶算法,使其从不堪造就变为
如今的自动驾驶汽车仍停留在良好的状态,但性能水平还不够好。在这里,我们为第一个可行的框架提供了证据,以快速改进驾驶算法,使其从平庸到具有道路价值。通过巧妙的尝试和错误快速学习解决问题的能力,使人类拥有进化和生存能力的万能机器。我们通过各种各样的模仿来学习,从骑自行车到学习烹饪,我们经历了很多尝试和错误。
DeepMind have shown us that deep reinforcement learning methods can lead to super-human performance in many games including Go, Chess and computer games, almost always outperforming any rule based system. We here show that a similar philosophy is also possible in the real world, and in particular, in autonomous vehicles. A crucial point to note is that DeepMind’s Atari playing algorithms required millions of trials to solve a task. It is remarkable that we consistently learnt to lane-follow in under 20 trials.
DeepMind已经向我们展示了深度强化学习方法可以在许多游戏中导致超人的表现,包括围棋、象棋和电脑游戏,几乎总是比任何基于规则的系统表现得更好。我们在这里展示了一种类似的哲学在现实世界中也是可能的,特别是在自动驾驶汽车中。需要注意的一点是,DeepMind的Atari的算法需要数百万次试验才能解决一个任务。值得注意的是,我们在不到20次的试验中始终学会了“走单行道”。
We learnt to follow lanes from scratch in 20 minutes.
我们在20分钟内学会了从无到有。
Imagine what we could learn to do in a day…?
想象一下,我们一天可以学到什么?
Wayve has a philosophy that to build robotic intelligence we do not need massive models, fancy sensors and endless data. What we need is a clever training process that learns rapidly and efficiently, like in our video above. Hand-engineered approaches to the self-driving problem have reached an unsatisfactory glass ceiling in performance. Wayve is attempting to unlock autonomous driving capabilities with smarter machine learning.
Wayve的理念是,要构建机器人智能,我们不需要庞大的模型、花哨的传感器和无穷无尽的数据。我们需要的是一个聪明的训练过程,快速有效地学习,就像我们上面的视频。人工设计的自动驾驶技术在性能上达到了令人不满意的玻璃天花板。Wayve正试图用更智能的机器学习来开发自动驾驶功能。

- We’re hiring! wayve.ai/careers/
- Sign up to our newsletter below
- Full research paper: arXiv paper link
- Follow us: twitter / linkedin
Special thanks: We would like to thank StreetDrone for building us an awesome robotic vehicle, Admiral for insuring our vehicle trials and the Cambridge Polo Clubfor granting us access to their private land for our lane-following research.


全文完本文由 简悦 SimpRead 优化,用以提升阅读体验。Learning to drive in a day.The first example of reinforcement learning on-board an autonomous car.No dense 3D map.No hand-written rules.The potential implications of our approach are huge.We learnt to follow lanes from scratch in 20 minutes.Imagine what we could learn to do in a day…?
