@sambodhi
2018-08-22T11:39:20.000000Z
字数 8497
阅读 4759
如何通过深度学习轻松实现自动化监控

作者 | Bharath Raj
译者 | Zhiyong Liu
编辑 | Vince Chen
AI前线导读:本文是一篇快速上手指南,讲述了如何使用基于深度学习的对象检测(Object Detection)实现监控系统,并对使用GPU多处理器进行推理的不同对象检测模型在行人检测中的性能进行了比较。
监控包含安全和巡逻。在多数情况下,这项工作需要长时间进行,才能发现不希望发生的事。这项工作固然很重要,但同时也是一项平淡无奇的任务。
如果说,有什么东西能够为我们“观察和等待”,那生活不就简单多了吗?嗯,你很幸运。过去几年,随着技术的进步,我们可以为上述任务编写一些脚本来实现自动化,要做到这点非常容易。但是,在深入探讨之前,让我们先扪心自问:
机器是否做得跟人类一样好?
任何熟悉深度学习的人,都知道图像分类器的准确率超过了人类。
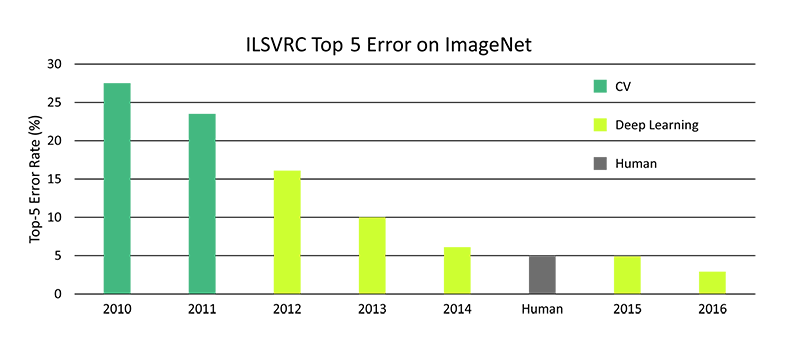
人类、传统计算机视觉和深度学习在ImageNet数据集上随时间的错误率
那么想啊,当机器和人类相比时,它能够以同样(或更好)的标准来监控对象。话虽如此,如果真的能够使用技术进行监控的话,效率会高得很多。
- 监控是一项重复而平凡的任务,让人类执行的话,很可能会导致表现下降。但如果让技术来监控,我们就可以集中精力,在出现问题时采取行动。
- 要监控大片区域的话,你就需要很多人力。而且固定摄像机的视野范围也很有限。如果使用移动监控机器人(如微型无人机),那么这些问题就可以得到缓解。
此外,同样的技术,也可用于不限于安全的各种应用,例如婴儿监控器或自动化产品交付。
有道理。但是我们该如何实现自动化呢?
在我们设计复杂的理论之前,让我们先思考一下监控的正常运作方式。我们在看视频的时候,如果发现有异常情况,就会采取行动。因此,从本质上说,我们的技术应该能够仔细检查视频的每一帧,希望能够发现一些异常的情况。这样的过程是不是听起来非常熟悉?
你可能已经猜到,这不就是对象检测本地化的本质吗?与分类稍有不同的是,我们需要知道对象的确切位置。而且可能会出现单个图像中存在多个对象的情况。

为了找到确切的位置,我们的算法应该检查图像的每一部分,以找到一个类的存在。说着容易做着难。但是,自2014年以来,深度学习领域中的连续迭代研究引入了可实时监控目标的重度工程神经网络。
请注意,在短短两年内性能是如何提高的。
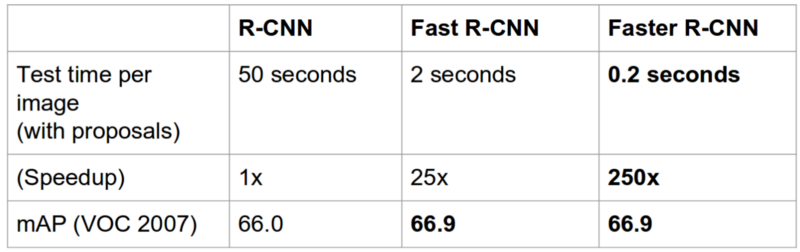
有几种深度学习体系结构,它们在内部使用不同的方法来执行相同的任务。最流行的变种是Faster RCNN、YOLO和SSD网络。
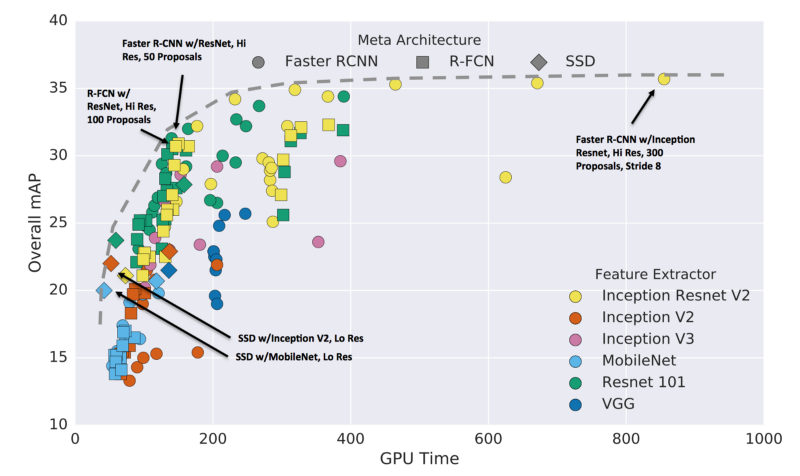
速度和准确率之间需要权衡。更高的mAP和更低的GPU时间是最理想的。
每个模型都依赖于基分类器,这极大影响了最终的准确率和模型的大小。此外,对象探测器的选择,也会严重影响计算复杂度和最终准确率。
在选择对象检测算法时,总是要在速度、准确率和大小进行权衡。
在本文中,我们将介绍如何使用对象检测来构建一个简单但有效的监控系统。让我们先讨论一下由于监控任务的性质而受到的约束。
监控深度学习的约束
我们经常希望能够在一大片区域上密切监控。这就带来了几个因素,是在自动化监控之前我们可能需要考虑的因素。
1. 视频
为了能够在一大片区域上保持监控,我们可能需要多个摄像机。此外,这些摄像机需要在某处存放视频数据:要么是本地的,要么是远程的。

典型的监控摄像机。
高质量的视频比低质量的视频需要更多的内存。此外,RGB输入流比BW输入流大3倍。由于我们只能存储有限的输入流,所以,为了最大限度地存储输入流,通常会降低视频的质量。
因此,可扩展的监控系统应该能够解释低质量的图像。所以我们的深度学习算法也必须在如此低质量的图像上训练。
2. 处理能力
现在我们已经解决输入约束的问题,那么就可以解决更大的问题了。我们在哪里处理从摄像机源获得的数据?有两种方法可以做到这一点。
- 在集中式服务器上处理:
摄像机的视频流在远程服务器或集群上逐帧处理。该方法具有较强的健壮性,使我们能够获得高精度复杂模型的优点。不过,这方法有一个明显的问题就是延迟。你需要网络延迟比较低的快速Internet连接。此外,如果你不使用商业API的话,那么服务器的设置、维护的成本可能会很高。
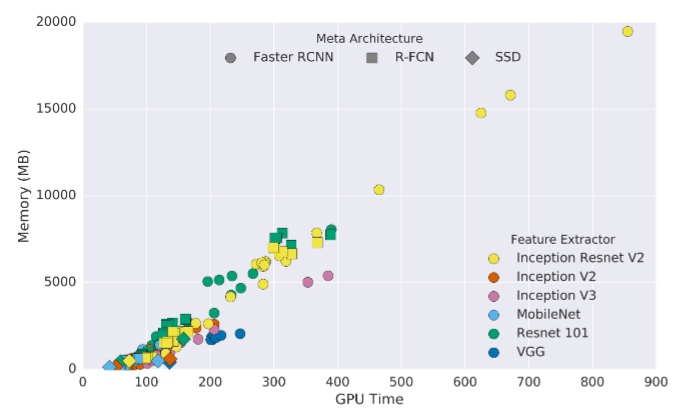
内存占用与推理GPU时间(毫秒)。大多数高性能模型都会占用大量内存。
- 边缘的处理:
通过连接小型微控制器,我们就可以对摄像机本身进行实时推理。这样就没有传输延迟,而且异常报告的速度比以前的方法更快。此外,对于移动机器人来说,这是一个很好的补充,因此它们无需受WiFi或蓝牙可用范围的限制。
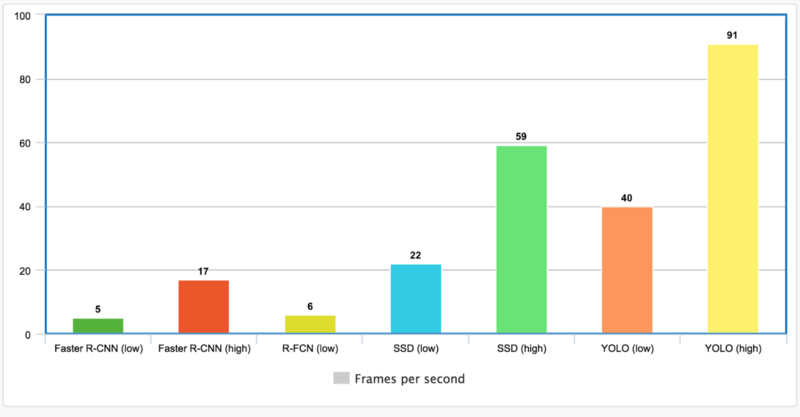
各种对象探测器的FPS能力。
至于缺点,就是微控制器不如GPU那么强大,因此你可能会被迫使用精度较低的模型。通过板载GPU可以避免这个问题,但这种解决方案非常昂贵。一种有趣的解决方案就是使用TensorRT之类的软件,可以优化程序进行推理。
训练监控系统
在本节中,我们将演示如何使用对象检测(Object Detection)来识别行人。我们会使用TensorFlow对象检测API来创建对象检测模块,并简要探讨如何设置API,为我们的监控任务进行训练。要获得更为详细的说明,你可以阅读这篇博文《How to play Quidditch using the TensorFlow Object Detection API》(http://u6.gg/evcTu)
整个过程可以概括为三个阶段:
- 数据准备
- 训练模型
- 推理

训练对象检测模型所涉及的工作流程。
阶段1:数据准备
步骤1:获取数据集
过去拍摄的监控录像可能就是你能得到最准确的数据集。但是,对于大多数情况来说,人们很难获得这样的监控录像。在这种情况下,我们可以训练对象探测器从普通图像中识别目标。

从数据集中注释图像的样本。
如前文所述,摄像机中的图像质量可能比较低。因此,必须训练模型能够在这种条件下工作。一种非常优雅的方法是执行数据增强,这篇博文《Data Augmentation | How to use Deep Learning when you have Limited Data — Part 2》(http://u6.gg/evd73)进行了详细的说明。说到底,我们必须添加一些噪声来降低数据集中的图像质量。我们还可以尝试模糊和侵蚀的效果。
我们将使用TownCentre数据集来完成对象检测任务。我们使用视频的前3600帧进行训练和验证,剩下的900帧用于测试。你可以使用我的GitHub repo(https://github.com/thatbrguy/Pedestrian-Detector)中的脚本来提取数据集。
步骤2:注释数据集
你可以使用LabelImg之类的工具来执行注释。这虽然是一项非常乏味的任务,但也同等重要。注释将保存为XML文件。
幸运的是,TownCentre数据集(http://u6.gg/evyVw)的所有者提供了csv格式的注释。我编写了一个快速脚本,用于将注释转换为所需的XML格式。你可以在我的GitHub repo(https://github.com/thatbrguy/Pedestrian-Detector)中找到它。
步骤3:克隆存储库
克隆存储库(https://github.com/thatbrguy/Pedestrian-Detector)。运行一下命令来安装需求,编译一些Protobuf库并设置路径变量:
pip install -r requirements.txtsudo apt-get install protobuf-compilerprotoc object_detection/protos/*.proto --python_out=.export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
步骤4:准备支持输入
我们需要为目标分配一个ID。我们在名为label_map.pbtxt文件中定义ID如下所示:
item {id: 1name: ‘target’}
接下来,你必须创建一个包含XML和图像文件名称的文本文件。例如,如果你的数据集中有img1.jpg、img2.jpg和img1.xml、img2.xml,那么trainval.txt文件应该如下所示:
img1img2
将数据集分成两个文件夹,即images文件夹和annotations文件夹。将label_map.pbtxt和trainval.txt放在annotations文件夹中。在annotations文件夹中创建一个名为xmls的文件夹,并将所有的XML都放入其中。你的目录层次结构应该如下所示:
-base_directory|-images|-annotations||-xmls||-label_map.pbtxt||-trainval.txt
步骤5:创建TF记录
API接受TFRecords文件格式的输入。使用我的repo中提供的create_tf_record.py文件,可将数据集转换为TFRecords。你应该在基目录中执行如下命令:
python create_tf_record.py \--data_dir=`pwd` \--output_dir=`pwd`
程序完成执行之后,你将会发现两个文件train.record和val.record。
阶段2:训练模型
步骤1:选择模型
正如我在前文所提到的,速度和准确性之间需要权衡。此外,从头开始构建和训练对象检测器也会非常耗时。因此,TensorFlow对象检测API提供了一系列预训练模型,你可以根据自己的使用情况对这些模型进行微调。这一过程称为迁移学习,极大加速了你的训练过程。
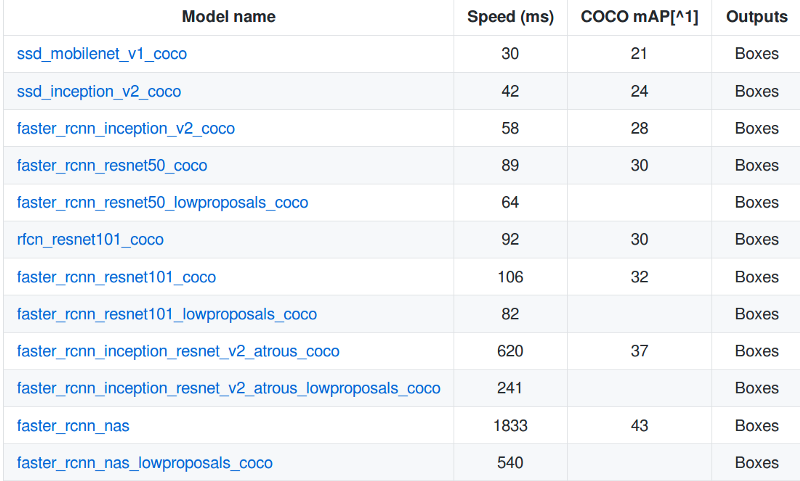
一组模型在MS COCO数据集上进行预训练
下载其中一个模型,并将内容解压缩到基目录中。你将会得到模型检查点、冻结的推理图和pipeline.confi文件。
步骤2:定义训练作业
你必须在pipeline.config中定义“训练作业”。将文件放入基目录中。真正重要的是文件的最后几行,你只需将突出显示的值设置为你鸽子的文件位置即可,如下所示:
gradient_clipping_by_norm: 10.0fine_tune_checkpoint: "**model.ckpt**"from_detection_checkpoint: truenum_steps: 200000}train_input_reader {label_map_path: "**annotations/label_map.pbtxt**"tf_record_input_reader {input_path: "**train.record**"}}eval_config {num_examples: 8000max_evals: 10use_moving_averages: false}eval_input_reader {label_map_path: "**annotations/label_map.pbtxt**"shuffle: falsenum_epochs: 1num_readers: 1tf_record_input_reader {input_path: "**val.record**"}}
步骤3:开始训练
执行以下命令启动训练作业。我建议使用一个足够强的GPU(如果你安装了GPU版的TensorFlow)的机器来加速训练的过程。
python object_detection/train.py \--logtostderr \--pipeline_config_path=pipeline.config \--train_dir=train
阶段3:推理
步骤1:导出经训练的模型
在使用模型之前,需要将经训练的检查点文件导出到冻结的推理图。实际上,说当然比做容易,只需执行以下代码(用检查点编号来替换‘xxxxx’):
python object_detection/export_inference_graph.py \--input_type=image_tensor \--pipeline_config_path=pipeline.config \--trained_checkpoint_prefix=train/model.ckpt-xxxxx \--output_directory=output
你将会得到名为frozen_inference_graph.pb的文件以及一些检查点文件。
步骤2:在视频流上使用模型
我们需要从视频源中提取单个帧。可以通过OpenCV的VidroCapture方法来做到,如下所示:
cap = cv2.VideoCapture()flag = Truewhile(flag):flag, frame = cap.read()## -- Object Detection Code --
阶段1中使用的数据提取代码,会自动使用我们的测试集图像创建一个名为“test_imges”文件夹。通过执行以下命令,可在测试集上运行模型:
python object_detection/inference.py \--input_dir=**{PATH}** \--output_dir=**{PATH}** \--label_map=**{PATH}** \--frozen_graph=**{PATH}** \--num_output_classes=1 **\** --n_jobs=1 \--delay=0
实验
如前所述,在选择对象检测模型时,速度和准确性之间需要进行权衡。我进行了一些实验,测量了使用三种不同的模型检测到人员的FPS和计数准确率。此外,我还对不同的资源约束(GPU并行约束)进行了实验。这些实验的结果,可以为你在选择对象检测模型时提供一些有价值的见解。
设置
我们选择了以下模型进行实验。这些可以在TensorFlow对象检测API的Modle Zoo中找到。
- Faster RCNN with ResNet 50
- SSD with MobileNet v1
- SSD with InceptionNet v2
所有模型都在Google Colab上进行了10000步的训练(或直到它们的损失饱和)。为了进行推理,使用了AWS p2.8xlarge实例。通过比较模型检测到的人数和基础事实来测量技术的准确性。在以下约束条件下测试美妙帧数(FPS)的推理速度:
- Single GPU
- Two GPUs in parallel
- Four GPUs in parallel
- Eight GPUs in parallel
结果
以下是我们在测试集上使用FasterRCNN生成的输出的节选。我还在文末附上了一段视频,比较了每个模型产生的输出。

训练时间
下图显示了每个模型训练10000步(以小时为单位)所需的时间。这不包括超参数搜索所需的时间。
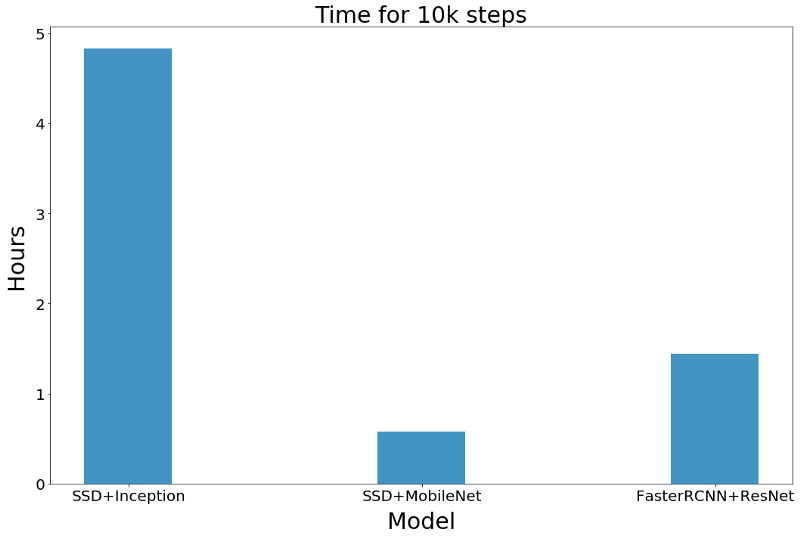
当你的应用和用于迁移学习的预训练模型差异较大时,你可能需要大量调整超参数。但是,如果你的应用与预训练模型相差不大,就不必进行大量的搜索。尽管如此,你可能仍然需要尝试训练参数,例如学习率和优化器的选择。
速度(每秒帧数,FPS)
这是我们实验中最有趣的部分。如前所述,我们在5种不同的资源约束下测量了我们的3个模型的FPS性能。结果如下图所示:
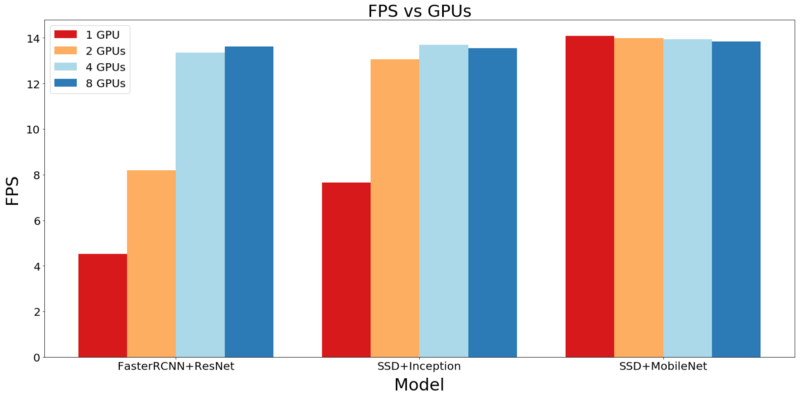
当我们使用单GPU时,SSD速度极快,很轻松超过了RCNN的速度。但是,当我们增加GPU(并行工作)的数量时,Faster RCNN就会很快赶上SSD。更不用说,在低GPU的环境下,使用MobilNet的SSD要比使用InceptionNet的SSD要快得多了。
从上面的图中,有一个值得注意的特征是,当我们使用MobileNet增加SSD的GPU数量时,FPU会略微下降。对于这种明显的悖论,其实有一个简单的答案。一般来说,我们的设置处理图像比他们提供的图像读取功能更快!
视频处理系统的速度不能高于图像输入系统的速度。
为证明这条假设,我让图像读取函数先行一步。下图显示了在添加延迟时,FPS在带有MobileNet的SSD上的改进情况。在前面的图中,FPS的轻微下降是由于多GPU请求输入所带来的开销所致。
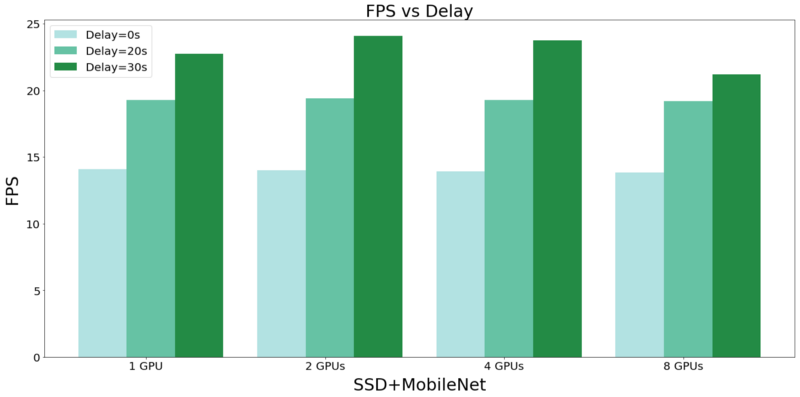
如果引入延迟,FPS将会急剧增加。最重要的是,我们需要一个优化的图像传输管道,以防出现速度瓶颈。但由于我们的预期用例是监控,因此我们还有一个另外的瓶颈。监控摄像机的FPS设置了我们系统FPS的上限。
计数的准确率
我们将计数的准确率定义为对象检测系统正确识别的人数百分比。但是我觉得它更倾向于监控方面。以下是我们的每个模型的性能:
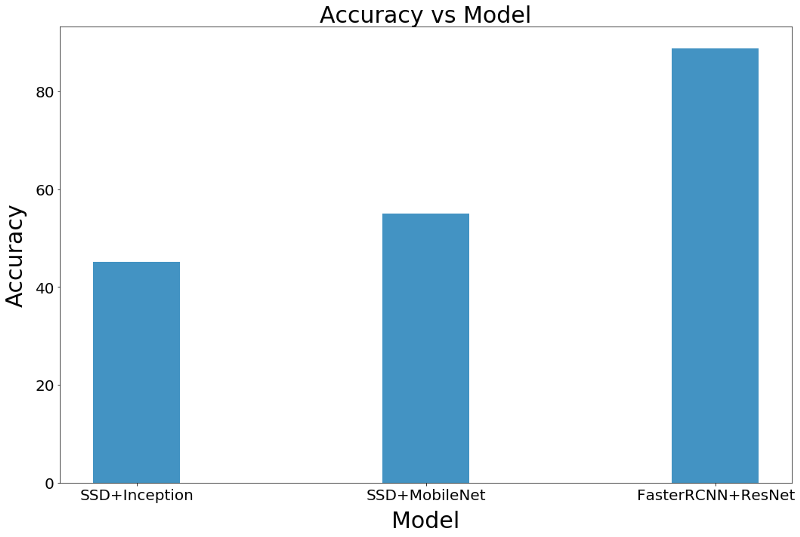
毋庸置疑,Faster RCNN是最准确的模型。同样令人惊讶的是,MobileNet的性能优于InceptionNet。
根据实验结果来看,很显然,速度和准确率之间确实需要进行权衡。但是,如果我们有足够的资源,完全可以以良好的FPS率使用高精度的模型。我们观察到,使用ResNet-50的Faster RCNN可提供最好的准确率,且在4+ GPU上并行部署时,具有非常好的FPS评级。
步骤太多了!
嗯,我不会争辩的,因为确实是有很多步骤。此外,为这种模型实时工作而设置云实例是一项非常繁琐、费时费力的活儿。
更好的解决方案,是使用已部署在服务器上的API服务,这样你就可以只专注于开发产品了。这就是Nanonets价值所在。他们将API部署在带有GPU的优质硬件上,这样你就可以在没有任何麻烦的情况下,获得疯狂的性能。
我将现有的XML注释转换为JSON格式,并将其提供给Nanonets API。事实上,如果你不想手动注释数据集的话,可以请求他们为你添加注释。下图所示是Nanonets处理繁琐作业时的简化工作流程示意图。
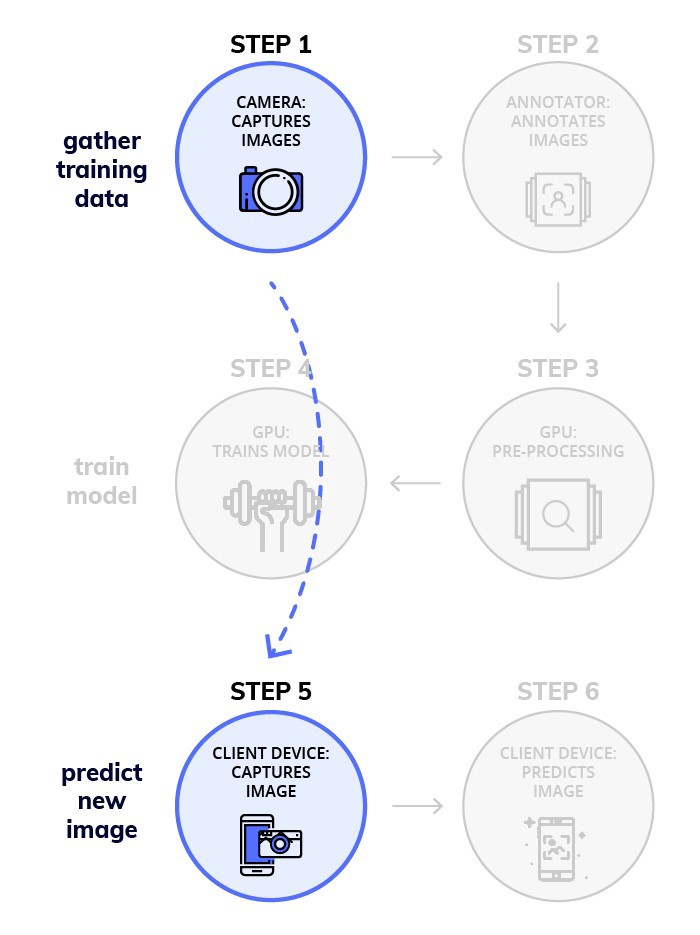
简化工作流的Nanonets
早些时候,我曾提到过微型无人机等移动监控设备可以大幅提高效率。我们可以使用像树莓派那样的微控制器轻松创建这种无人机,可以使用API调用来执行推理。
使用Nanonets API for Object Detection非常简单,但如果你想要清晰的指南,你可查阅这篇博文《How to easily Detect Objects with Deep Learning on Raspberry Pi》(http://u6.gg/evkHJ)。
使用Nanonets的结果
Nanonets大约花了两个小时完成训练过程,这其中包括超参数搜索所需的时间。就训练所花费的时间而言,Nanonets无意是个赢家。而且在计数准确性方面上,Nanonets也击败了FasterRCNN。
FasterRCNN Count Accuracy = 88.77%Nanonets Count Accuracy = **89.66%**
下面是我们的测试数据集中所有四个模型的性能。很明显,两种SSD模型都有点不稳定,且精度较低。此外,尽管FasterRCNN和Nanonets具有类似的准确度,但后者有更为稳定的边界框,从下面的视频能看出这一点。
https://v.qq.com/x/page/e0762xti925.html
可以认为自动监控是负有责任的吗?
深度学习是一种令人惊叹的工具,它可以轻松地提供典型的结果。但我们能在多大程度上可以相信我们的监控系统能够独立行动呢?在一些情况下,自动化还是有些问题的。
更新:鉴于GDPR及下述原因,我们必须思考有关监控自动化的合法性和伦理问题。本文仅用于教学目的,它使用了公开的数据集。你有责任确保自动化系统符合你所在地区的法律要求。
1. 可疑的结论
我们并不知道深度学习算法是如何得出结论的。即使数据输入的过程完美无缺,也有可能出现很多错误的结果。例如,英国警察使用的这款人工智能猥亵内容过滤器,它一直删除沙丘的照片,因为沙丘被认为是淫秽图片。引导反向传播等技术可以在一定程度上解释决策,但是“路漫漫其修远兮,吾将上下而求索”。
2. 对抗性攻击
深度学习系统是很脆弱的。对抗性攻击类似于图像分类器的视错觉。但可怕的是,计算出来的不明显的扰动会迫使深度学习模型错误分类。利用同样的原理,研究人员已经能够通过使用“对抗性眼镜”来规避基于深度学习的监控系统。
3. 误报
另一个问题是,如果出现误报,我们该怎么做?问题的严重程度取决于应用本身。例如,边境巡逻系统的误报可能比花园监控系统的问题更严重。是应该有一些人为干预以避免出现意外。
4. 相似的面孔
遗憾的是,人类的相貌并不像指纹那么独特。两个或更多的人长得相像还是有可能的。同卵双胞胎就是最典型的例子之一。据报道,Apple Face ID就无法区分两名毫不相干的中国同事。这就使得监控、识别人员变得更加困难。
5. 数据集缺乏多样性
深度学习算法的表现好坏,取决于你所提供的数据。最受欢迎的人脸数据集,却只有白种人的样本。对一个孩子来说,人类有不同的肤色是显而易见的事儿,但深度学习算法却有点笨。事实上,Google就因为这事儿陷入了麻烦:它将黑人错误的归类为大猩猩。
原文链接: How to Automate Surveillance Easily with Deep Learning
https://medium.com/nanonets/how-to-automate-surveillance-easily-with-deep-learning-4eb4fa0cd68d
