@sambodhi
2017-04-06T08:30:54.000000Z
字数 8371
阅读 3454
Automated Data Science & Machine Learning: An Interview with the Auto-sklearn Team
自动化数据科学与机器学习:Auto-sklearn开发团队访谈
机器学习
This is an interview with the authors of the recent winning KDnuggets Automated Data Science and Machine Learning blog contest entry, which provided an overview of the Auto-sklearn project. Learn more about the authors, the project, and automated data science.
在最近由Kdnuggets举办的自动化数据科学与机器学习博客大赛中,Auto-sklearn开发团队勇夺了冠军。Matthew Mayo采访了Auto-sklearn开发团队,了解了Auto-sklearn项目的基本情况,以及开发人员的背景和自动化数据科学的动态。
KDnuggets recently ran an Automated Data Science and Machine Learning blog contest, which garnered numerous entries and lots of appreciation for the winning posts and a pair of honorable mentions.
KDnuggets最近举办了一个自动数据科学和机器学习博客比赛,获得了众多参赛者的作品提交,涌现了许多获奖作品以及一系列的荣誉称号。
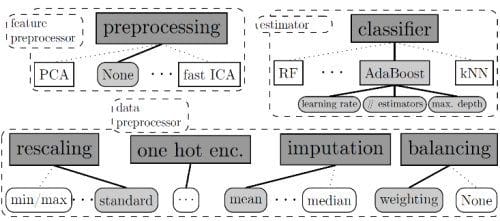
The winning post, titled Contest Winner: Winning the AutoML Challenge with Auto-sklearn, written by Matthias Feurer, Aaron Klein, and Frank Hutten, all of the University of Freiburg, provides an overview of Auto-sklearn, an open-source Python tool that automatically determines effective machine learning pipelines for classification and regression datasets. The project is built around the successful scikit-learn library and won the recent AutoML challenge.
来自弗莱堡大学的Matthias Feurer、Aaron Klein和Frank Hutten撰写的题为“Contest Winner: Winning the AutoML Challenge with Auto-sklearn”获奖作品,概要介绍了Auto-sklearn,一个可以自动确定有效的机器学习管道进行分类和回归数据集的开源Python工具。这个项目围绕成功的scikit-learn库而构建,并赢得了最新的AutoML挑战。
Given the popularity of the post, we asked the authors if they would be interested in answering a few followup questions on themselves, their project, and automated data science in general. What follows is the result of this conversation.
鉴于这篇文章如此受欢迎,我们询问了作者是否有兴趣谈谈关于自己和项目的轶事,以及自动化数据科学的一些后续问题。以下是采访的记录。
Matthew Mayo: First off, congratulations on winning the KDnuggets Automated Data Science and Machine Learning Blog Contest, with your entry outlining your project Auto-sklearn. What if we start by having you introduce the members of the team and provide a little information on each of your backgrounds?
Mattew Mayo:首先祝贺你们的Auto-sklearn项目在KDnuggest自动化数据科学和机器学习博客大赛获胜!你们能为读者介绍一下团队成员,并讲述你们每个人的背景情况吗?
Matthias Feurer: I am a 2nd year PhD student in Frank’s group, working on hyperparameter optimization and automated machine learning. Mostly, I’m interested in optimizing pre-defined machine learning pipelines. I started working for Frank during my Master’s studies, being annoyed by hyperparameter tuning in most of my study projects up to that point.
Matthias Feurer:我是Frank集团的二年级博士生,致力于超参数优化和自动化机器学习。大多时间,我的兴趣在优化预定义的机器学习管道。在我硕士研究生期间,就开始为Frank工作,在我的大部分学习项目中,经常为超参数的调整而感到烦恼。
Aaron Klein: I am also a 2nd year PhD student working on automated deep learning. Like Matthias, I was a master student at the University of Freiburg before I joined Frank’s group.
Aaron Klein:我也是Frank集团的二年级博士生,研究方向是超参数优化和自动化机器学习。像Matthias一样,在加入Frank集团之前,我是弗赖堡大学的硕士生。
Frank Hutter: I’m an Assistant Professor in Computer Science at the University of Freiburg, with main interests in artificial intelligence, machine learning, and automated algorithm design. Before moving to Freiburg, I spent nine years at the University of British Columbia in Vancouver, Canada.
Frank Hutter:我是弗莱堡大学计算机科学系的助理教授,主要从事人工智能、机器学习和自动化算法设计。在来到弗赖堡大学之前,我在加拿大温哥华不列颠哥伦比亚大学工作了九年。
All: Besides the three of us (who wrote the blog post for the KDnuggets Blog Contest), the team for our winning submission also consisted of a few more PhD students and postdocs from the University of Freiburg: Katharina Eggensperger, Jost Tobias Springenberg, Hector Mendoza, Manuel Blum, Stefan Falkner, and Marius Lindauer.
所有:除了我们三个人(撰写了KDnuggets博客大赛的博文),我们的团队还包括来自弗赖堡大学的博士生和博士后:Katharina Eggensperger、Jost Tobias Springenberg、Hector Mendoza、Manuel Blum、Stefan Falkner和Marius Lindauer。
The post was very informative and described Auto-sklearn quite well. Is there anything additional of note you would like our readers to know about Auto-sklearn, or any developments that have occurred since this post? Is there anything you can share about future development plans?
这篇文章非常翔实,很好地描述了Auto-sklearn。您希望我们的读者在了解Auto-sklearn或自发布以来的任何进展有什么需要额外注意的吗?对于它的未来发展计划,有什么可以分享给读者吗?
One short-term goal is regression, where we can do a lot more. In the long term we would like Auto-sklearn to become a flexible extension of scikit-learn, which helps users optimize their machine learning pipelines. We also want to do lots more work along the lines of Auto-Net, and want to speed up the optimization process dramatically by more reasoning across datasets, across subsets of data, and over time (for anytime algorithms).
我们的短期目标是回归,以便我们可以做更多的工作。而我们的长期目标,是希望Auto-sklearn能够成为scikit-learn灵活的扩展,能够帮助用户优化机器学习管道。我们还要沿着Auto-Net的方向进行更多的工作,通过考虑跨数据集、跨数据子集和基于时间的任意时间算法(anytime algorithms)来显著地加速优化过程。
To what extent do you think machine learning and data science can be automated, and what degree of human interaction will be required for so-called fully automated systems?
那么,你认为机器学习和数据科学在多大程度上可以自动化?所谓的全自动化系统需要何种程度的人机交互?
While there are several approaches for tuning the hyperparameters of machine learning pipelines, so far there is only little work on discovering new pipeline building blocks. Auto-sklearn uses a predefined set of preprocessors and classifiers in a fixed order. An efficient way to also come up with new pipelines would be helpful. One can of course continue this line of thinking and try to automate the discovery of new algorithms as done in several recent papers, such as Learning to learn by gradient descent by gradient descent. Humans can also still tune hyperparameters better than automated methods when machine learning models are very expensive to train, such as state-of-the-art deep neural networks for large datasets. We’re working on ways to transform human expert heuristics into fully formalized algorithms; e.g., our Fabolas approach optimizes the hyperparameters of a neural network on small subsets of the data to speed up learning about the best hyperparameters for the full data set.
尽管有一些方法可以用来调试机器学习管道的超参数,但是目前为止,很少有工作能发现新管道。Auto-sklearn以固定的顺序使用一系列的预定义的预处理器和分类器。加入一个方法对于找到新管道很有效,那么这个方法将会很有用处。当然,人们可以继续这种思路,并尝试自动寻找新的算法。最近,已经有几篇论文这样做了。比如 Learning to learn by gradient descent by gradient descent。当机器学习模型进行训练过于费时费钱时,人们可以调整超参数,比自动化方法做得更好,例如最先进的用于大型数据集的深层神经网络。我们正在努力将专家的启发式方法转换为完全形式化的算法,比如我们的Fabolas方法先从较小数据子集上开始优化神经网络的超参数,从而加快了解全部数据集的最佳超参数。
Considering the previous question, will data scientists be unemployed anytime soon? Or, if too drastic an idea, will the current hype surrounding data scientists be tempered by automation in the near future, and if so, to what degree?
考虑到先前的问题,短期之内数据科学家是否会失业?或者,如果让脑洞大开,目前被媒体大肆炒作的数据科学家,将来会不会被自动化压制?如果是这样的话,会有什么样的程度?
Certainly not. All the methods of automated machine learning are developed to support data scientists, not to replace them. Such methods can free the data scientist from nasty, complicated tasks (like hyperparameter optimization) that can be solved better by machines. But analysing and drawing conclusions still has to be done by human experts -- and in particular data scientists who know the application domain will remain extremely important. We do believe, though, that automation will make individual data scientists a lot more productive, so this might indeed affect the number of data scientists needed to do the job.
当然不是,我们发展自动化机器学习方法是为了向数据科学家提供帮助,而不是代替他们。这些方法使数据科学家摆脱了讨厌复杂的任务(比如说超参数优化),机器可以很好地解决这些任务。然而数据分析与结论获取仍然需要人类专家来完成,尤其是通晓应用领域的数据科学家仍然非常重要。然而我们相信,自动化将会提高数据科学家的工作效率,因此,这有可能确实会影响到数据科学家需要做的工作量。
What, if anything, can data scientists do to avoid being rendered obsolete? The question, of course, being directed toward adding value as opposed to being mischievous.
数据科学家能够做什么来避免被淘汰的命运?当然,提出这个问题并非捣乱,而是为了增加本次采访的价值。
It will always take data scientists to analyze and interpret the results of a statistical analysis -- so for young graduates starting data science jobs such skills might be more future-proof than some others (e.g., manual hyperparameter tuning to get the most out of your neural network).
分析和解释统计分析的结果,总得由数据科学家来完成,因此,对于开始数据科学工作的年轻毕业生来说,掌握这个技能可能比其他技能更为永不过时(例如,手动调整超参数以充分利用神经网络)。
As you have been active in machine learning competitions in the past, do you have any interesting tips, tricks, or insights to share?
您过去一直积极参与机器学习比赛,您有什么有趣的技巧、诀窍或见解与读者分享吗?
Automation and careful resampling strategies. Automation allows to run a lot of experiments, while resampling strategies such as careful cross-validation are needed to prevent against overfitting. It's also often important to go in with an open mind and just let the data speak about which method works best on which dataset.
自动化和仔细的重采样策略。由于自动化允许进行大量实验,为防出现过拟合(overfitting),因此需要像仔细的交叉验证那样的重采样策略。进一步开放思想也是非常重要的,只需让数据来说明哪种方法对数据集效果最好。
Finally, where do you think machine learning technology will be in 5 years?
最后一个问题,你认为在五年内,机器学习技术将会到达什么样的水平?
It is hard to predict what will happen in the future, especially in a field that’s changing as quickly as machine learning. E.g., five years ago not many foresaw the rise of deep learning. But we’re fairly confident that machine learning will be used ever more and will be embedded in commercial tools everyone uses.
未来会怎么样,这很难预测,这点在机器学习领域尤为如此。要知道在五年前,并没有人预见到深度学习的兴起。但是我们相信,机器学习将会越来越普遍,在大家都使用的商业工具将会见到机器学习的身影。
Thank you for your time. I'm sure that your time is at a premium, and we appreciate you taking a few moments for our readers.
非常感谢您百忙之中抽出这一点宝贵的时间接受我的采访。
Related:
