@Arslan6and6
2016-05-02T06:05:52.000000Z
字数 3969
阅读 742
作业五】殷杰
第四章、深入Hadoop 2.x
---依据【八股文】格式编写MapReduce案例词频统计WorrdCount程序
依据课堂讲解的【八股文】格式编写 MapReduce 经典案例词频统计 WorrdCount 程序
以下几点注意,必须在作业文档中体现:
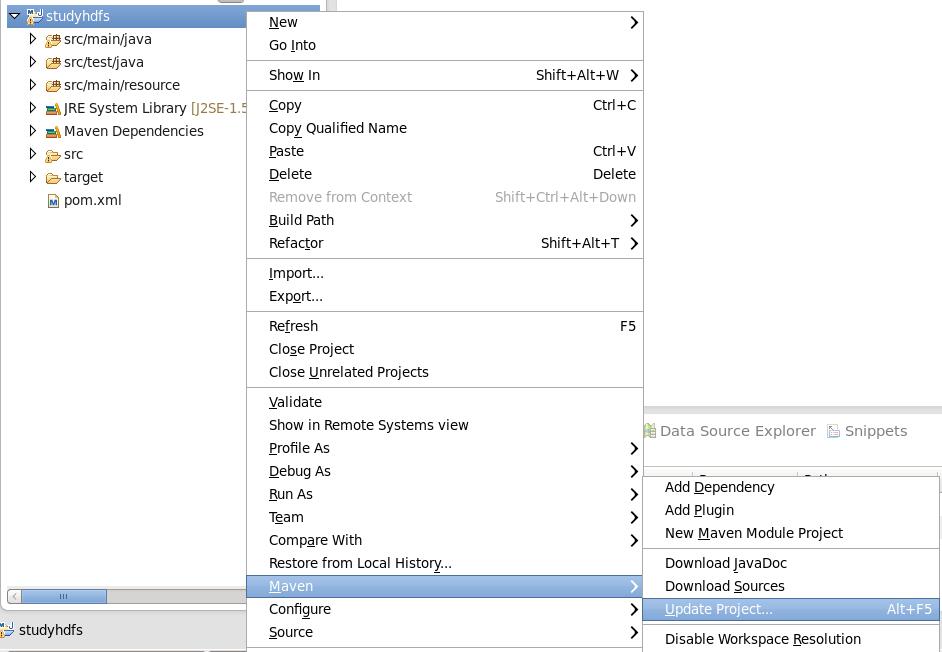
1) 在 Linux 系统中搭建 Eclipse 和 Maven 环境,创建 Maven Projectt
2) 基于【八股文】格式编写 WordCount 程序
3) 打包 JAR,在 YARN 运行测试
4) 以 WordCount 程序为例,理解 MapReduce 如何并行分析数据
1) 搭建 Eclipse 和 Maven 环境
解压eclipse和Maven压缩包
创建 Maven Project
在eclipse中操作如下:
File ---> New ---> Maven Project ---> Next ---> maven-archetype-quickstart Next ---> 输入Group ID 、Artifact ID等信息 ---> Finish
新建资源包并指定路径
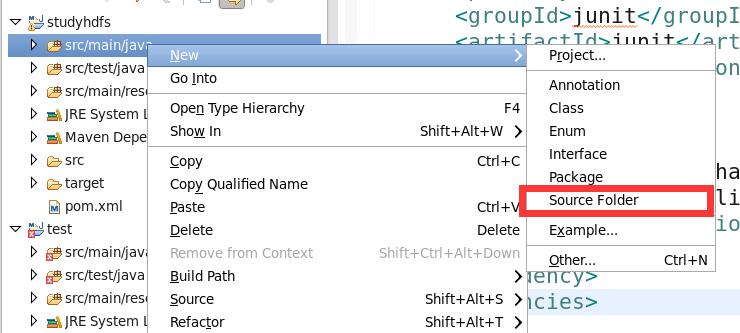
src/main/resource 选定路径后添加新建包名resource

改变默认输出路径
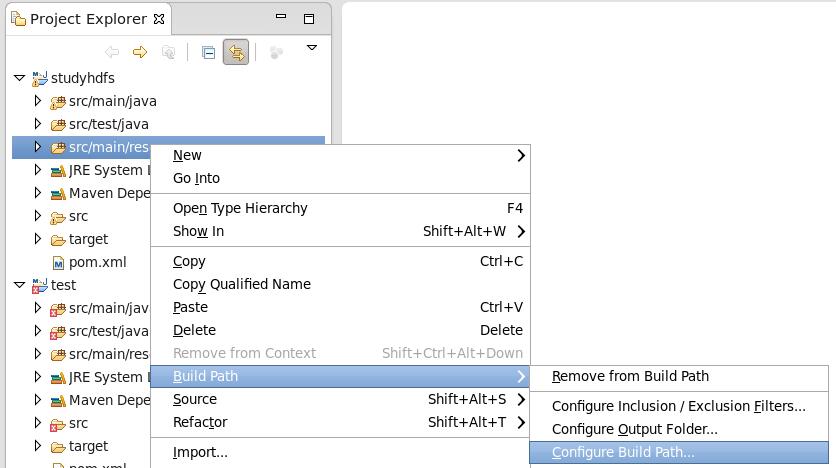
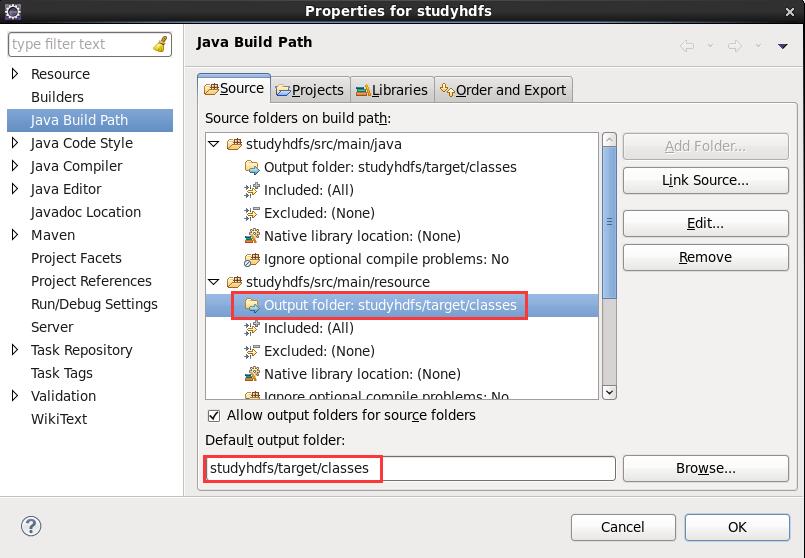
解压repository压缩包至新建的.m2文件夹,repository包含众多maven依赖包。
在eclipse中操作如下:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.5.0</version>
<scope>test</scope>
</dependency>
</dependencies>
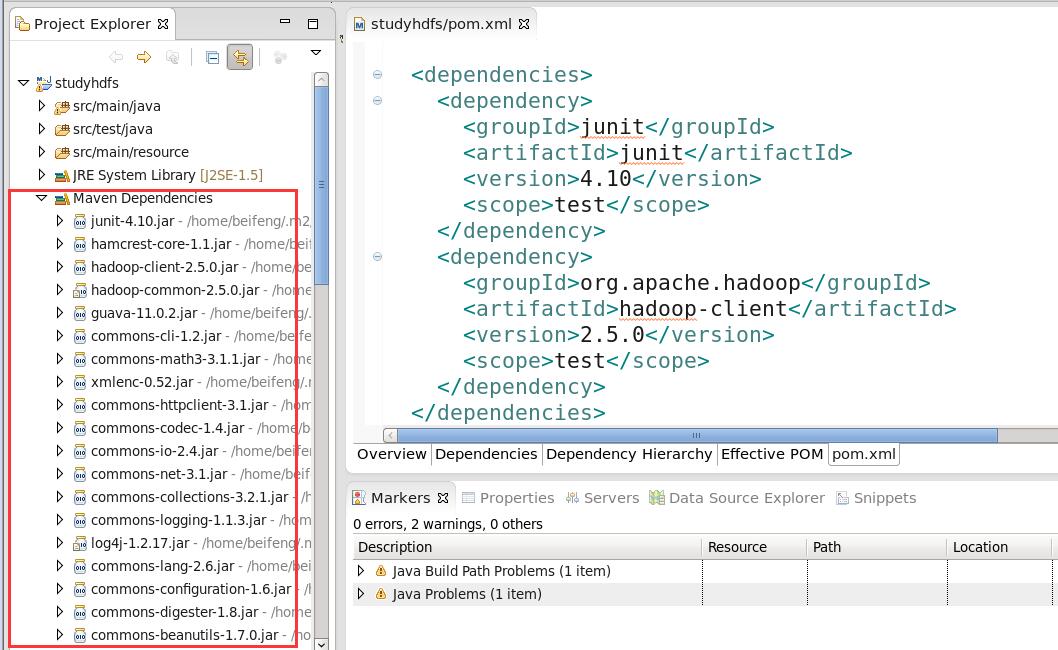
Windows--->preferences---->Maven---->Installations。选择add配置已安装maven目录!可以看到配置文件为settings.xml
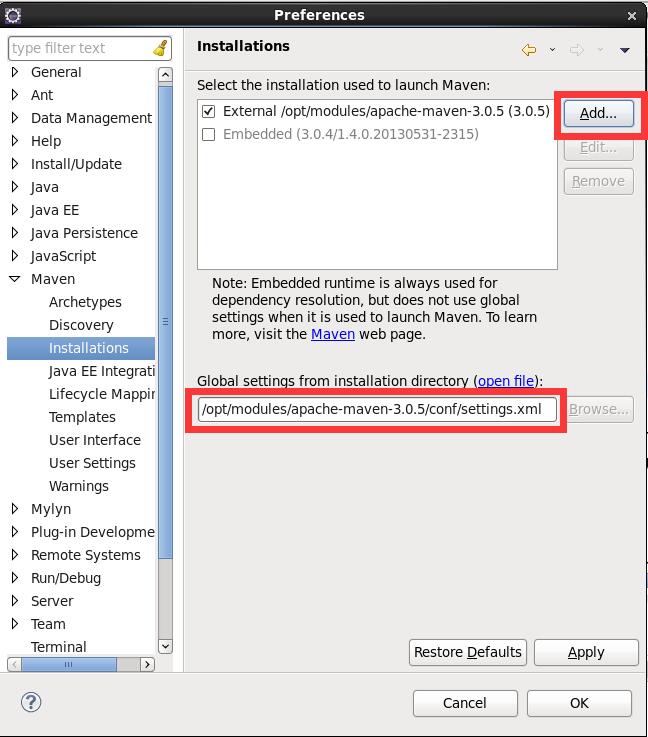
复制maven解压目录下conf/settings.xml至.m2文件夹,与eclipse中maven配置保持一致。
在eclipse中操作如下:
Windows--->preferences---->Maven---->User Settings。选择本地user配置文件位置。
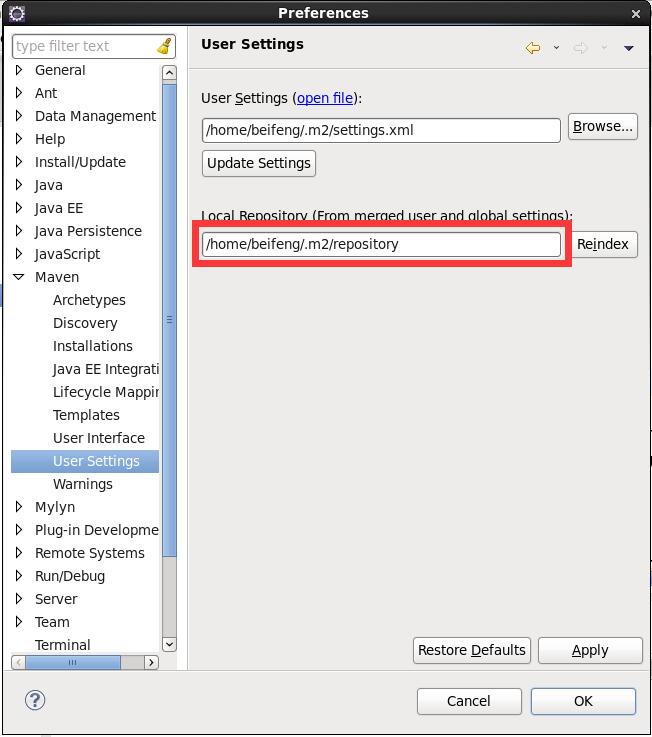
如无已下载maven依赖包,可自动下载更新:
配置代码补齐快捷键为习惯按键 ATL+/
Windows--->preferences--->搜索keys--->搜索content--->改变快捷键为ATL+/

2) 基于【八股文】格式编写 WordCount 程序
package org.apache.hadoop.studyhdfs;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCountMapReduce {//step 1public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {private Text mapOutpuKey = new Text ();private final static IntWritable mapOutputValue = new IntWritable(1);@Overridepublic void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {String lineValue = value.toString();String [] strs = lineValue.split(":");for(String str : strs) {mapOutpuKey.set(str);context.write(mapOutpuKey, mapOutputValue);}}}//step 2public static class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable outputValue = new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context )throws IOException, InterruptedException {//temp sumint sum = 0 ;for (IntWritable value : values) {sum += value.get();}outputValue.set(sum);//outputcontext.write(key, outputValue);}}//step 3public int run (String[] args) throws Exception {Configuration config = new Configuration();// 2 : Create jobJob job =Job.getInstance(config, this.getClass().getSimpleName());job.setJarByClass(WordCountMapReduce.class);//3 : set job//input---> map ---> reduce ---> output//3.1 : inputPath inPath = new Path(args[0]);FileInputFormat.addInputPath(job, inPath);//3.1 mapperjob.setMapperClass(WordCountMapper.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);//3.2 reducejob.setReducerClass(WordCountReduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);//3.3 outputPath outPath = new Path(args[1]);FileOutputFormat.setOutputPath(job, outPath);//3.4 sumbmit jobboolean isSuccess = job.waitForCompletion(true);return isSuccess ? 0 : 1 ;}public static void main(String[] args) throws Exception {int status = new WordCountMapReduce().run(args);System.exit(status);}}
3) 打包 JAR,在 YARN 运行测试
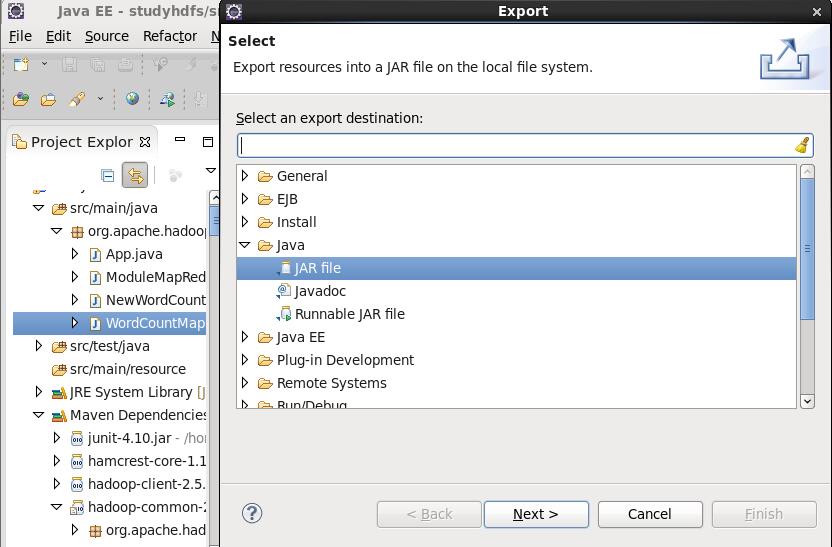
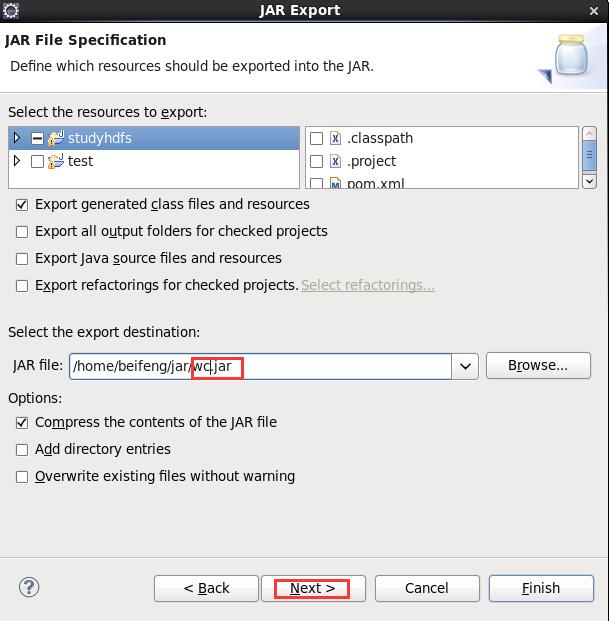
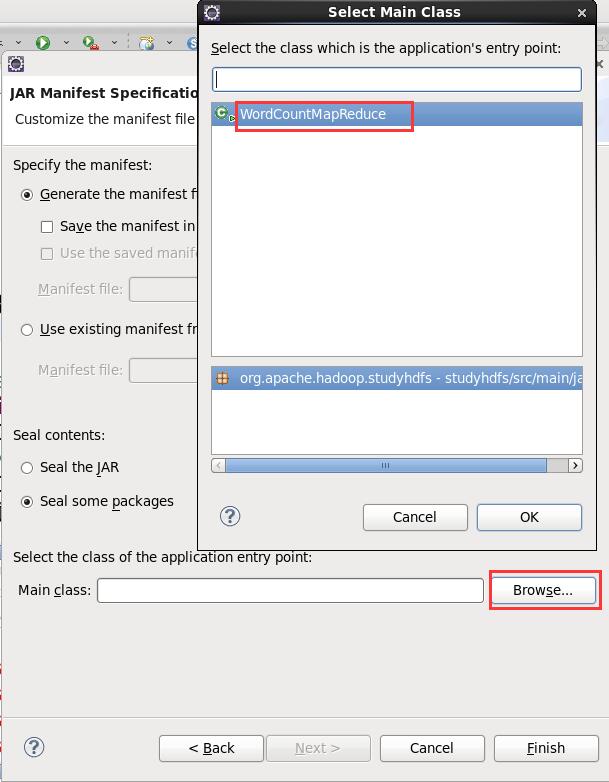
[beifeng@hadoop-senior hadoop-2.5.0]$ bin/yarn jar /home/beifeng/jar/wc.jar /input/sort.txt /output
查看运行结果
[beifeng@hadoop-senior hadoop-2.5.0]$ bin/hdfs dfs -text /output/part*
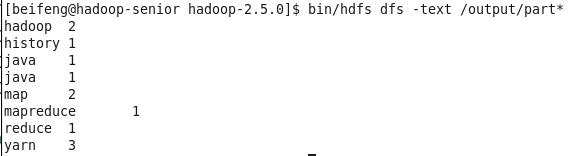
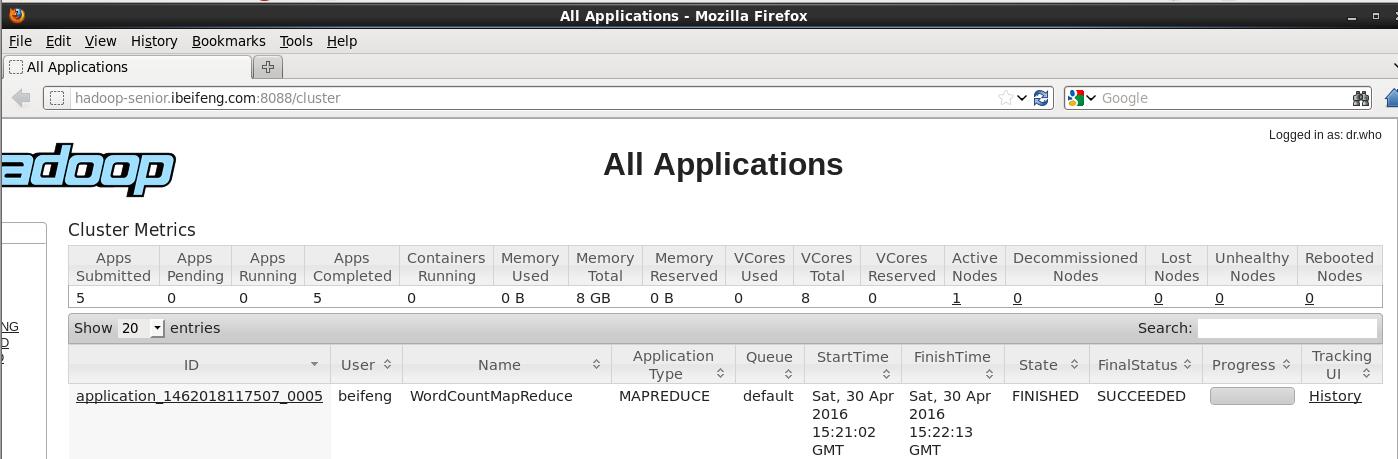
在YARN运行成功
4) 以 WordCount 程序为例,理解 MapReduce 如何并行分析数据
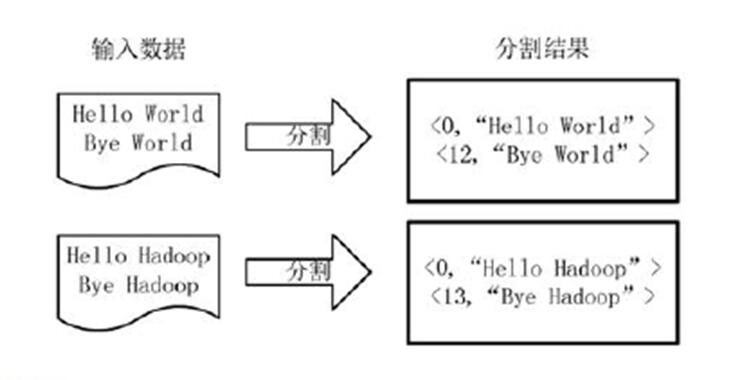
将文件拆分成splits,由于测试用的文件较小,所以每个文件为一个split,并将文件按行分割形成<key,value>对,下图所示。这一步由MapReduce框架自动完成,其中偏移量(即key值)包括了回车所占的字符数(Windows/Linux环境不同)。
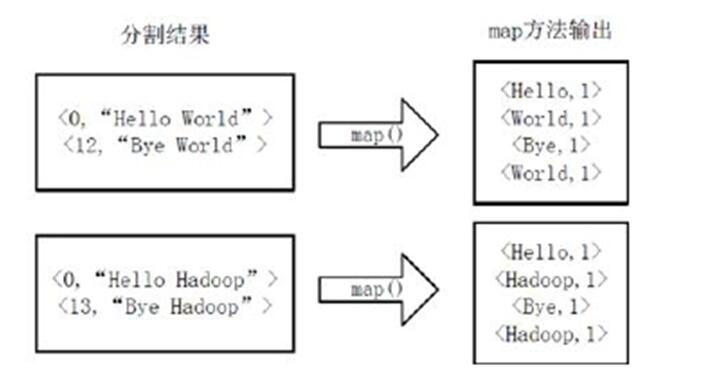
将分割好的<key,value>对交给用户定义的map方法进行处理,生成新的<key,value>对,下图所示。
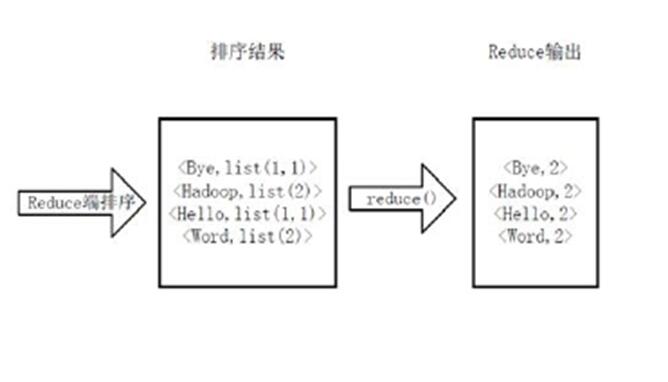
得到map方法输出的<key,value>对后,Mapper会将它们按照key值进行排序,得到Mapper的最终输出结果。下图所示。

Reducer先对从Mapper接收的数据进行排序、分组,再交由用户自定义的reduce方法进行处理,得到新的<key,value>对,并作为WordCount的输出结果,下图所示。