@Arslan6and6
2016-05-13T05:50:26.000000Z
字数 5432
阅读 716
【作业十一】殷杰
第五章、高级Hadoop2.x
---MapReduce 倒排索引
作业描述:
依据上课讲解【MapReduce执行流程】和【MapReduce高级案例:倒排索引】进行编码实现,
以下几点必须在作业中体现:
1)理解【倒排索引】功能
2)熟悉MapReduce中的Combiner功能
3)依据需求编码实现【倒排索引】功能,旨在对MapReduce的理解。
1)理解【倒排索引】功能
倒排索引是一种索引方法,根据文件内容确定文件名称、地址等信息
2)熟悉MapReduce中的Combiner功能
MapReduce是分为Mapper任务和Reducer任务,Mapper任务的输出,通过网络传输到Reducer任务端,作为输入。
在Reducer任务中,通常做的事情是对数据进行归约处理。既然数据来源是Mapper任务的输出,那么是否可以在Mapper端对数据进行归约处理,业务逻辑与Reducer端做的完全相同。处理后的数据再传送到Reducer端,再做一次归约。这样的好处是减少了网络传输的数量。
在Mapper进行归约后,数据量变小了,这样再通过网络传输时,传输时间就变短了,减少了整个作业的运行时间。
Reducer端接收的数据就是来自于Mapper端。我们在Mapper进行归约处理,无非就是把归约操作提前到Mapper端做而已。
Mapper端的数据仅仅是本节点处理的数据,而Reducer端处理的数据是来自于多个Mapper任务的输出。因此在Mapper不能归约的数据,在Reducer端有可能归约处理。
在Mapper进行归约的类称为Combiner。是继承自Reducer类的自定义类。job.setCombinerClass(InvertedIndexCombiner.class); public static class InvertedIndexCombiner extends Reducer<T>{...} 。类名InvertedIndexCombiner为自定义。
要注意的是,Combiner只在Mapper任务所在的节点运行,不会跨Mapper任务运行。Reduce端接收所有Mapper端的输出来作为输入。虽然两边的归约类是同一个,但是执行的位置完全不一样。
并不是所有的归约工作都可以使用Combiner来做。比如求平均值就不能使用Combiner。因为对于平均数的归约算法不能多次调用。
3)依据需求编码实现【倒排索引】功能,旨在对MapReduce的理解
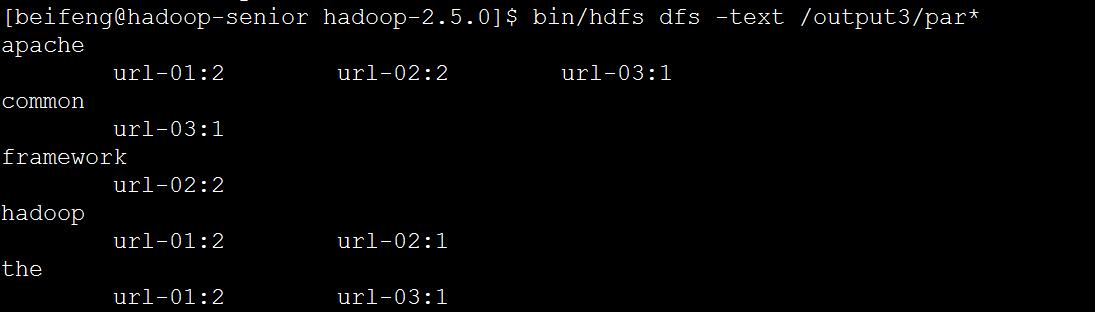
以案例说明
案例文件内容为

需要统计出每个单词在各个URL出现的次数,如下图所示
package org.apache.hadoop.index;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.conf.Configured;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Mapper.Context;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.Tool;import org.apache.hadoop.util.ToolRunner;/**** @author beifeng**/public class InvertedIndexMapReduce extends Configured implements Tool {// step 1 : mapper/*** public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>*/public static class WordCountMapper extends //Mapper<LongWritable, Text, Text, Text> {private Text mapOutputKey = new Text();private Text mapOutputValue = new Text("1");@Overridepublic void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {// split1 分割每行内容,分割后lines[0]为url,lines[1]为入 url后所有内容String[] lines = value.toString().split("##");// get urlString url = lines[0];// split2 将"the apache hadoop"以空格分割String[] strs = lines[1].split(" ");//遍历[the, apache, hadoop]for (String str : strs) {mapOutputKey.set(str + "," + url);context.write(mapOutputKey, mapOutputValue);// mapOutputKey为// the,url-01 apache,url-01 hadoop,url-01// apache,url-02 framwor,url-02 hadoop,url-02// the,url-03 commmon,url-03 apache,url-03// apache,url-01 the,url-01 hadoop,url-01// apache,url-02 frmework,url-02// mapOutputValue为1}}}//// set combiner classpublic static class InvertedIndexCombiner extends //Reducer<Text, Text, Text, Text> {private Text CombinerOutputKey = new Text();private Text CombinerOutputValue = new Text();@Overridepublic void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException {// split 以逗号分割"the,url-01" [the, url-01]String[] strs = key.toString().split(",");// set keyCombinerOutputKey.set(strs[0] + "\n");// set value mapOutputValue输入的value为1//将该行the为key的value加总int sum = 0;for (Text value : values) {sum += Integer.valueOf(value.toString());}//Combiner输出的key为the value设置为url-01:1CombinerOutputValue.set(strs[1] + ":" + sum);context.write(CombinerOutputKey, CombinerOutputValue);// combiner合并后输出// <the, url-01:2> <the, url-03:1>// <apache, url-01:1> <apache, url-02:2>// <hadoop, url-01:2> <hadoop, url-02:1>// ...}}// step 2 : reducer 由于combiner已经计算好各单词即key在各url出现的次数// Reducer只需按照key把对应的value拼接即完成第二次合并。public static class WordCountReducer extends //Reducer<Text, Text, Text, Text> {private Text outputValue = new Text();@Overridepublic void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException {// TODOString result = new String();for (Text value : values) {result += value.toString() + "\t";}outputValue.set(result);context.write(key, outputValue);}}// step 3 : jobpublic int run(String[] args) throws Exception {// 1 : get configurationConfiguration configuration = super.getConf();// 2 : create jobJob job = Job.getInstance(//configuration,//this.getClass().getSimpleName());job.setJarByClass(InvertedIndexMapReduce.class);// job.setNumReduceTasks(tasks);// 3 : set job// input --> map --> reduce --> output// 3.1 : inputPath inPath = new Path(args[0]);FileInputFormat.addInputPath(job, inPath);// 3.2 : mapperjob.setMapperClass(WordCountMapper.class);// TODOjob.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(Text.class);// ====================shuffle==========================// 1: partition// job.setPartitionerClass(cls);// 2: sort// job.setSortComparatorClass(cls);// 3: combinejob.setCombinerClass(InvertedIndexCombiner.class);// 4: compress// set by configuration// 5 : group// job.setGroupingComparatorClass(cls);// ====================shuffle==========================// 3.3 : reducerjob.setReducerClass(WordCountReducer.class);// TODOjob.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);// 3.4 : outputPath outPath = new Path(args[1]);FileOutputFormat.setOutputPath(job, outPath);// 4 : submit jobboolean isSuccess = job.waitForCompletion(true);return isSuccess ? 0 : 1;}public static void main(String[] args) throws Exception {args = new String[] {"hdfs://hadoop-senior.ibeifeng.com:8020/input/index.txt","hdfs://hadoop-senior.ibeifeng.com:8020/output6/"};// get configurationConfiguration configuration = new Configuration();// configuration.set(name, value);// run jobint status = ToolRunner.run(//configuration,//new InvertedIndexMapReduce(),//args);// exit programSystem.exit(status);}}
