@Arslan6and6
2016-05-06T12:58:46.000000Z
字数 4487
阅读 743
【作业九】殷杰
第五章、高级Hadoop2.x(一)
---NameNode HA 和YARN RM HA 配置
作业描述:
依据上课讲解的【Hadoop2.xHDFSNNameNodeHA和YARNRMHA】安装部署配置的步骤,自己在机器中完成,将核心步骤通过截图粘贴到文档中。以下几点必须作业要体现:
1) Zookeeper 集群几个配置项,以及启动 Zookeeeper 各个节点
2) HDFS HA(高可用性)原理(把握四大要点),最好自己作图
3) YARN ResoouceManagger HA 和 ResouceMannager Restaart 功能及配置部署
4) 测试 YARNN ResouceMManager HA 和 ResoucceManager Restart 功能
5) 步骤清晰,必要时配图
1) Zookeeper 集群几个配置项,以及启动 Zookeeeper 各个节点
a)安装jdk
b)安装Zookeeper:
上传zookeeper-3.4.5.jar到第一台服务器/opt/softwares,解压tar -zxf zookeeper-3.4.5.tar.gz -C /opt/modules/
c)配置:
配置数据存储目录:
在解压目录下mkdir data,该data目录为 Zookeeeper 数据物理存储位置。
cd /opt/modules/zookeeper-3.4.5/conf
cp -a zoo_sample.cfg zoo.cfg
利用nodepad++修改zoo.cfg第12行为dataDir=/opt/modules/zookeeper-3.4.5/data
配置 Zookeeeper 各台服务器 myid ,在 zoo.cfg 中添加服务器IP与myid对应关系及服务器间通信端口:
server.1=192.168.5.130:2888:3888
server.2=192.168.5.131:2888:3888
server.3=192.168.5.132:2888:3888
格式为server.A =B:C:D :其中A是一个数字即myid,表示这个是第几号服务器;B是这个服务器的ip地址;C表示的是这个服务器与集群中的Leader服务器交换信息的端口;D表示的是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是 用来执行选举时服务器相互通信的端口。

在/opt/modules/zookeeper-3.4.5/data下,vi myid , 内容仅为1。对应server.1=192.168.5.130:2888:3888
将复制到第二、第三台服务器,并修改/opt/modules/zookeeper-3.4.5/data下myid内容为对应的2和3
[beifeng@hadoop-senior modules]$ scp -r zookeeper-3.4.5/ beifeng@hadoop-senior02.ibeifeng.com:/opt/modules/ ;
scp -r zookeeper-3.4.5/ beifeng@hadoop-senior03.ibeifeng.com:/opt/modules/
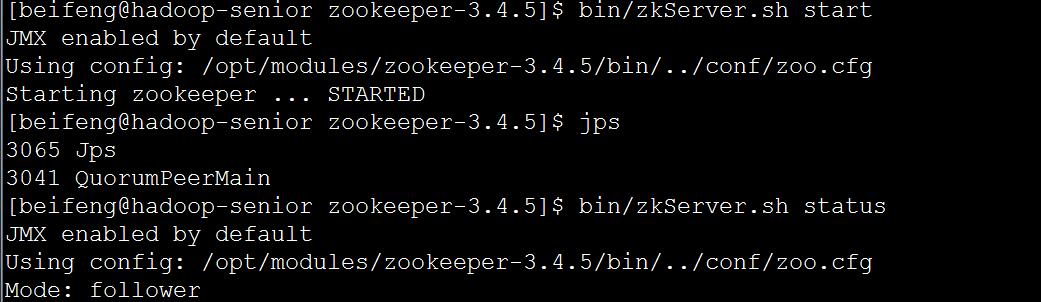
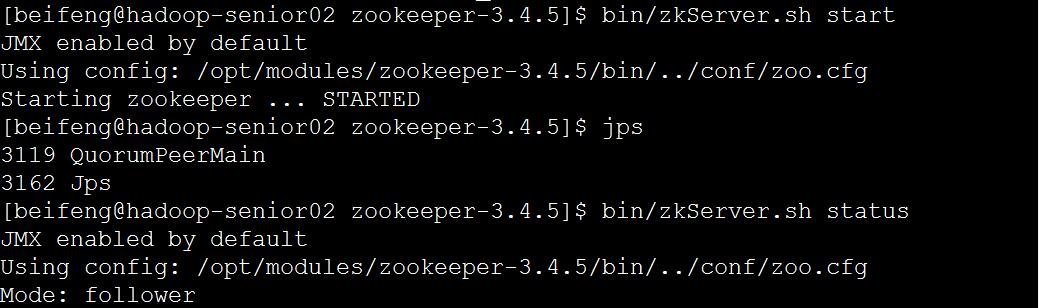
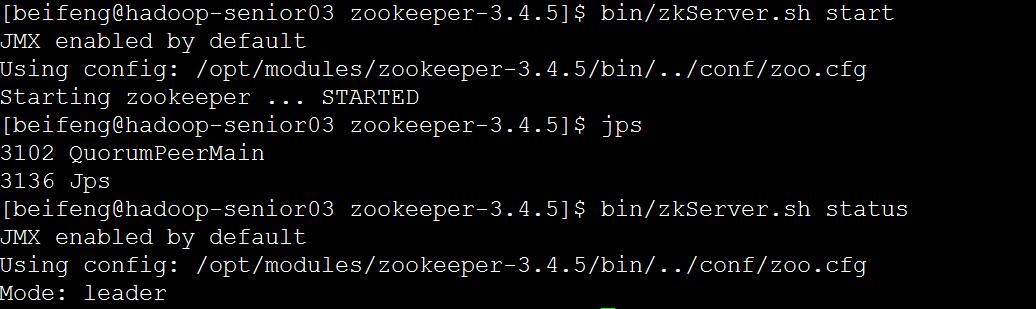
d)启动
bin/zkServer.sh start 三台都要执行
bin/zkServer.sh status 查看状态
2) HDFS HA(高可用性)原理(把握四大要点),最好自己作图
在Hadoop2.0.0之前,NameNode(NN)在HDFS集群中存在单点故障(single point of failure),每一个集群中存在一个NameNode,如果NN所在的机器出现了故障,那么将导致整个集群无法利用,直到NN重启或者在另一台主机上启动NN守护线程。
主要在两方面影响了HDFS的可用性:
(1)、在不可预测的情况下,如果NN所在的机器崩溃了,整个集群将无法利用,直到NN被重新启动;
(2)、在可预知的情况下,比如NN所在的机器硬件或者软件需要升级,将导致集群宕机。
HDFS的高可用性将通过在同一个集群中运行两个NN(activeNN&standbyNN)来解决上面两个问题,这种方案允许在机器破溃或者机器维护快速地启用一个新的NN来恢复故障。
在典型的HA集 群中,通常有两台不同的机器充当NN。在任何时间,只有一台机器处于Active状态;另一台机器是处于Standby状态。Active NN负责集群中所有客户端的操作;而Standby NN主要用于备用,它主要维持足够的状态,如果必要,可以提供快速的故障恢复。
为了让 Standby NN的状态和ActiveNN保持同步,即元数据保持一致,它们都将会和JournalNodes守护进程通信。当Active NN执行任何有关命名空间的修改,它需要持久化到一半以上的JournalNodes上(通过edits log持久化存储),而Standby NN负责观察edits log的变化,它能够读取从JNs中读取edits信息,并更新其内部的命名空间。一旦Active NN出现故障,Standby NN将会保证从JNs中读出了全部的Edits,然后切换成Active状态。Standby NN读取全部的edits可确保发生故障转移之前,是和Active NN拥有完全同步的命名空间状态。
为了提供快速的故障恢复,StandbyNN也需要保存集群中各个文件块的存储位置。为了实现这个,集群中所有的Database将配置好Active NN和Standby NN的位置,并向它们发送块文件所在的位置及心跳,如下图所示:
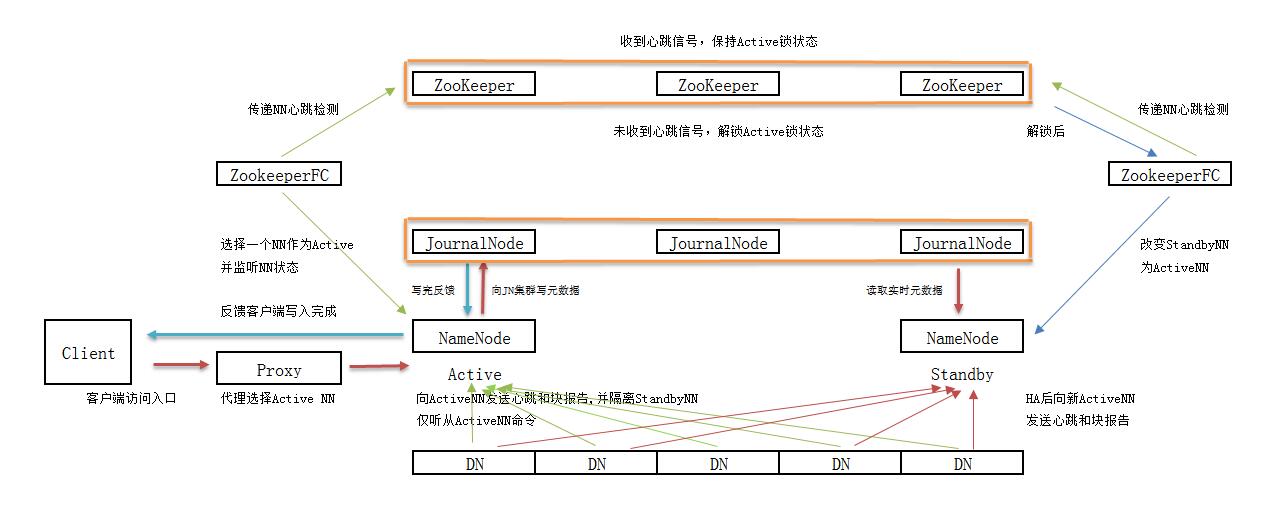
在任何时候,集群中只有一个NN处于Active 状态是极其重要的。否则,在两个Active NN的状态下NameSpace状态将会出现分歧,这将会导致数据的丢失及其它不正确的结果。为了保证这种情况不会发生,在任何时间,JNs只允许一个 NN充当writer。在故障恢复期间,将要变成Active 状态的NN将取得writer的角色,并阻止另外一个NN继续处于Active状态。
为了部署HA集群,你需要准备以下事项:
(1)、NameNode machines:运行Active NN和Standby NN的机器需要相同的硬件配置;
(2)、JournalNode machines:也就是运行JN的机器。JN守护进程相对来说比较轻量,所以这些守护进程可以可其他守护线程(比如NN,YARN ResourceManager)运行在同一台机器上。在一个集群中,最少要运行3个JN守护进程,这将使得系统有一定的容错能力。当然,你也可以运行3 个以上的JN,但是为了增加系统的容错能力,你应该运行奇数个JN(3、5、7等),当运行N个JN,系统将最多容忍(N-1)/2个JN崩溃。
在HA集群中,Standby NN也执行namespace状态的checkpoints,所以不必要运行Secondary NN、CheckpointNode和BackupNode;事实上,运行这些守护进程是错误的。
3) YARN ResoouceManagger HA 和 ResouceMannager Restaart 功能及配置部署
功能:
--监控resourcemanager
--切换active/standby
--保存状态 * 任务的状态 * 资源的状态
配置:
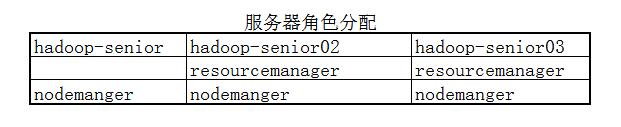
yarn-site.xml
先注释掉以前resourcemanager主机名称
再添加以下配置:
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop-senior02.ibeifeng.com</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop-senior03.ibeifeng.com</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop-senior.ibeifeng.com:2181,hadoop-senior02.ibeifeng.com:2181,hadoop-senior03.ibeifeng.com:2181</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
最后复制yarn-site.xml到其他2台服务器
scp etc/hadoop/yarn-site.xml beifeng@hadoop-senior02.ibeifeng.com:/opt/modules/hadoop-2.5.0/etc/hadoop/;
scp etc/hadoop/yarn-site.xml beifeng@hadoop-senior03.ibeifeng.com:/opt/modules/hadoop-2.5.0/etc/hadoop/
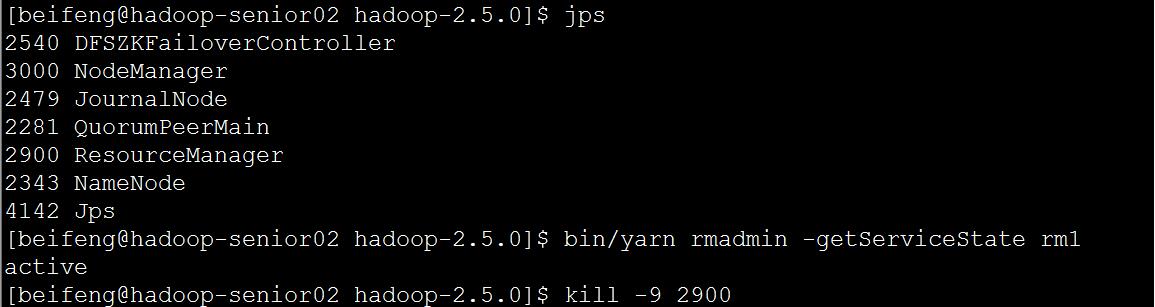
4) 测试 YARNN ResouceMManager HA 和 ResoucceManager Restart 功能
分别在第二台、第三台服务器上启动RM。sbin/yarn-daemon.sh start resourcemanager
并查看RM状态
bin/yarn rmadmin -getServiceState rm1

bin/yarn rmadmin -getServiceState rm2

在第一台服务器执行wordcount程序,以测试RM
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /input/sort.txt /output2
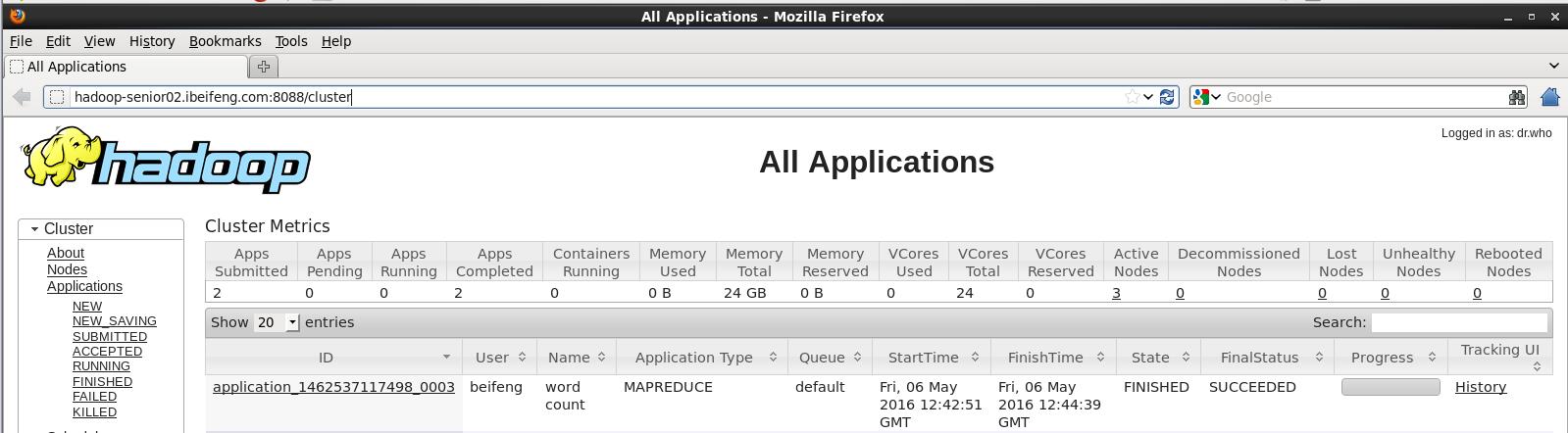

4) 测试 YARNN ResouceMManager HA 和 ResoucceManager Restart 功能