@Arslan6and6
2016-10-10T07:02:18.000000Z
字数 7946
阅读 1312
spark集成Hbase
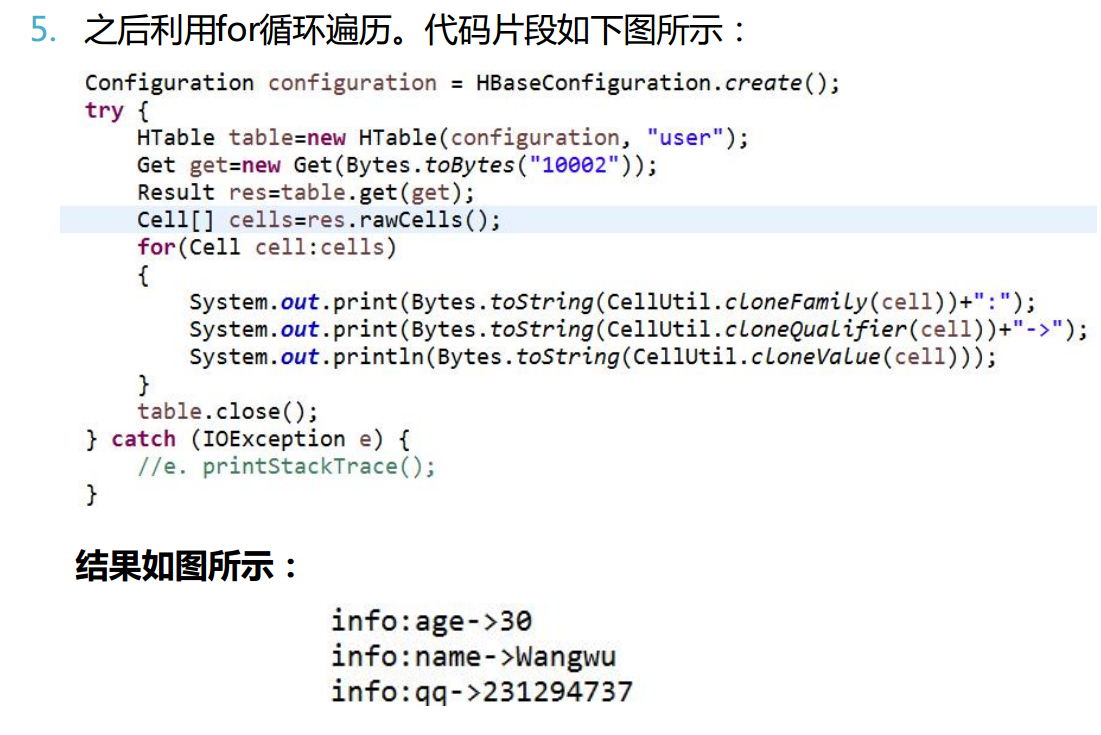
spark
Spark如何与HBase进行集成?
在pom.xml添加 Hbase 依赖
<properties><encoding>UTF-8</encoding><hadoop.version>2.5.0</hadoop.version><spark.version>1.6.1</spark.version><hbase.version>0.98.6-hadoop2</hbase.version></properties><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>${hbase.version}</version><scope>compile</scope></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>${hbase.version}</version><scope>compile</scope></dependency>
//启动zookeeper[beifeng@hadoop-senior zookeeper-3.4.5-cdh5.3.6]$ bin/zkServer.sh start//启动 HBase[beifeng@hadoop-senior hbase-0.98.6-hadoop2]$ bin/hbase-daemon.sh start master[beifeng@hadoop-senior hbase-0.98.6-hadoop2]$ bin/hbase-daemon.sh start regionserver[beifeng@hadoop-senior hbase-0.98.6-hadoop2]$ bin/hbase shellhbase(main):001:0> listTABLE1 row(s) in 1.8460 seconds=> ["user"]hbase(main):002:0> scan 'user'ROW COLUMN+CELL10001 column=info:name, timestamp=1472717309575, value=king10003 column=info:size, timestamp=1472717622108, value=852 row(s) in 0.1950 seconds//复制 hbase-site.xml 到项目 resources 文件夹下cp /opt/modules/hbase-0.98.6-hadoop2/conf/hbase-site.xml /home/beifeng/IdeaProjects/log-analyzer/src/main/resources
参照HBase集成mapreduce案例
package com.beifeng.senior.hadoop.beifenghbase;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.conf.Configured;import org.apache.hadoop.hbase.Cell;import org.apache.hadoop.hbase.CellUtil;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.client.Result;import org.apache.hadoop.hbase.client.Scan;import org.apache.hadoop.hbase.io.ImmutableBytesWritable;import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;import org.apache.hadoop.hbase.mapreduce.TableMapper;import org.apache.hadoop.hbase.mapreduce.TableReducer;import org.apache.hadoop.hbase.util.Bytes;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.util.Tool;import org.apache.hadoop.util.ToolRunner;public class User2StudentMapReduce extends Configured implements Tool{// step 1: Mapperpublic static class ReadUserMapper //extends TableMapper<ImmutableBytesWritable, Put>{@Overrideprotected void map(ImmutableBytesWritable key, Result value,Context context)throws IOException, InterruptedException {// user: name & age -> student: name & age : put// create PutPut put = new Put(key.get()) ;// add columnfor(Cell cell: value.rawCells()){// add family: infoif("info".equals(Bytes.toString(CellUtil.cloneFamily(cell)))){// add column: nameif("name".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))){put.add(cell) ;// CellUtil.cloneValue(cell)// put.add(family, qualifier, value) ;}// add column: ageelse if("age".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))){put.add(cell) ;}}}// context outputcontext.write(key, put);}}// step 2: Reducerpublic static class WriteStudentReducer //extends TableReducer<ImmutableBytesWritable, Put, NullWritable>{@Overrideprotected void reduce(ImmutableBytesWritable key, Iterable<Put> values,Context context) throws IOException, InterruptedException {for(Put put : values){context.write(NullWritable.get(), put);}}}// step 3: Driverpublic int run(String[] args) throws Exception {// 1) ConfigurationConfiguration conf = this.getConf();// 2) create jobJob job = Job.getInstance(conf, this.getClass().getSimpleName()) ;job.setJarByClass(User2StudentMapReduce.class);// 3) set job// input -> mapper -> shuffle -> reducer -> outputScan scan = new Scan() ;scan.setCacheBlocks(false);scan.setCaching(500); // 1 is the default in Scan, which will be bad for MapReduce jobsTableMapReduceUtil.initTableMapperJob("user", // input tablescan, // Scan instance to control CF and attribute selectionReadUserMapper.class, // mapper classImmutableBytesWritable.class, // mapper output keyPut.class, // mapper output valuejob //);TableMapReduceUtil.initTableReducerJob("student", // output tableWriteStudentReducer.class, // reducer classjob //);job.setNumReduceTasks(1); // at least one, adjust as requiredboolean isSuccess = job.waitForCompletion(true);if (!isSuccess) {throw new IOException("error with job!");}return isSuccess ? 0 : 1;}public static void main(String[] args) throws Exception {Configuration conf = HBaseConfiguration.create();int status = ToolRunner.run(//conf, //new User2StudentMapReduce(), //args //);System.exit(status);}}
- 由上述案例解读:
map 输入 key 类型为 ImmutableBytesWritable
map 输入 value 类型为 Result
初始化类TableMapReduceUtil中有方法:
public static void initTableMapperJob(String table, Scan scan, Class mapper, Class outputKeyClass, Class outputValueClass, Job job, boolean addDependencyJars) throws IOException {
initTableMapperJob(table, scan, mapper, outputKeyClass, outputValueClass, job, addDependencyJars, TableInputFormat.class);
从中得知 TableInputFormat 类实例为输入对象
再查看 package org.apache.hadoop.hbase.mapreduce.TableInputFormat
有方法:
public static final String INPUT_TABLE = "hbase.mapreduce.inputtable";
创建 HBaseConfiguration 就可以写为
1.依照HBase集成mapreduce案例:
val conf = HBaseConfiguration.create()
2.依照上述推理 HBase配置为:
val conf = HBaseConfiguration.create()conf.set(TableInputFormat.INPUT_TABLE, "user")
创建读取HBase数据RDD思路
依照 newAPIHadoopRDD 方法,
/* def newAPIHadoopRDD[K, V, F <: NewInputFormat[K, V]](conf: Configuration = hadoopConfiguration,fClass: Class[F],kClass: Class[K],vClass: Class[V]): RDD[(K, V)] = withScope {...}*/val hbaseRdd = sc.newAPIHadoopRDD(conf,classOf[TableInputFormat],classOf[ImmutableBytesWritable],classOf[Result])
读取HBase数据案例具体代码如下:
package com.ibeifeng.bigdata.spark.app.coreimport org.apache.hadoop.hbase.HBaseConfigurationimport org.apache.hadoop.hbase.client.Resultimport org.apache.hadoop.hbase.io.ImmutableBytesWritableimport org.apache.hadoop.hbase.mapreduce.TableInputFormatimport org.apache.spark.{SparkConf, SparkContext}/*** Created by beifeng on 9/4/16.*/object SparkReadHBase {def main(args: Array[String]) {//step 0 create SparkContextval sparkConf = new SparkConf().setAppName("SparkReadHBase Applicaiton").setMaster("local[2]")val sc = new SparkContext(sparkConf)//create HBaseConfiguration/*** conf: Configuration = hadoopConfiguration,fClass: Class[F],kClass: Class[K],vClass: Class[V]RDD[(K, V)]*/val conf = HBaseConfiguration.create()// INPUT_TABLE = "hbase.mapreduce.inputtable"conf.set(TableInputFormat.INPUT_TABLE, "user")val hbaseRdd = sc.newAPIHadoopRDD(conf,classOf[TableInputFormat],classOf[ImmutableBytesWritable],classOf[Result])println(hbaseRdd.count()+"===============================")sc.stop()}}
执行结果如下,与Hbase中user表2条数据相符
2===============================
在HBase shell命令行中向user表添加一条数据
hbase(main):003:0> put 'user','10002','info:name','mini'
再次执行程序,结果仍然相符
3===============================
读取HBase表中各cell案例:
CellUtil类:用于操作单元格的工具类。常用静态方法如下:
① CellUtil.cloneFamily(某列对象): 获取列族信息
② CellUtil.cloneQualifier(某列对象): 获取列信息
③ CellUtil.cloneValue(某列对象):获取值
对照HBase集成mapreduce
package com.ibeifeng.bigdata.spark.app.coreimport org.apache.hadoop.hbase.{CellUtil, HBaseConfiguration}import org.apache.hadoop.hbase.client.Resultimport org.apache.hadoop.hbase.io.ImmutableBytesWritableimport org.apache.hadoop.hbase.mapreduce.TableInputFormatimport org.apache.hadoop.hbase.util.Bytesimport org.apache.spark.{SparkConf, SparkContext}/*** Created by beifeng on 9/4/16.*/object SparkReadHBase {def main(args: Array[String]) {//step 0 create SparkContextval sparkConf = new SparkConf().setAppName("SparkReadHBase Applicaiton").setMaster("local[2]")val sc = new SparkContext(sparkConf)//create HBaseConfiguration/*** conf: Configuration = hadoopConfiguration,fClass: Class[F],kClass: Class[K],vClass: Class[V]RDD[(K, V)]*/val conf = HBaseConfiguration.create()// INPUT_TABLE = "hbase.mapreduce.inputtable"conf.set(TableInputFormat.INPUT_TABLE, "user")val hbaseRdd = sc.newAPIHadoopRDD(conf,classOf[TableInputFormat],classOf[ImmutableBytesWritable],classOf[Result])println(hbaseRdd.count()+"===============================")hbaseRdd.map(tuple => {val rowkey = Bytes.toString(tuple._1.get())val result = tuple._2var rowStr = rowkey + ","for (cell <- result.rawCells()){rowStr += Bytes.toString( CellUtil.cloneFamily(cell)) + ":" +Bytes.toString(CellUtil.cloneQualifier(cell)) +"->" +Bytes.toString(CellUtil.cloneValue(cell)) + "---------"}//returnrowStr}).foreach(println)sc.stop()}}
执行结果如下
10001,info:name->king---------10002,info:name->mini---------10003,info:size->85---------
