@Arslan6and6
2016-10-10T06:58:09.000000Z
字数 9243
阅读 875
Spark 功能、编译及安装部署测试 CORE [殷杰]
Spark
---Spark 功能、编译及安装部署测试
作业描述
基于内存的大数据计算框架Spark,尤其特有的处理数据的功能和数据分析栈,受到很多互联网和各行各业的喜爱,对于初学者,以下几点大家要注重,打好基础为后续深入使用做好铺垫:
1)Spark 功能、优势,尤其与MapReduce相比较
2)Spark 源码编译,针对不同版本的Hadoop 版本
3)Spark 提供交互性工具spark-shell基本使用,以及初步理解RDD的功能
4)Spark Cluster的理解,如何提交Spark Application及运行
5)Spark Standalone 安装部署启动及测试、编写实现WordCount程序
1)Spark 功能、优势,尤其与MapReduce相比较
spark是海量数据处理计算框架
相同数据,相同逻辑,不同的编码,在内存中运算比MapReduce速度快100倍以上,而在磁盘中运算比MapReduce速度快10倍以上。
Spark 在内存中处理数据,而 Hadoop MapReduce 是通过 map 和 reduce 操作在磁盘中处理数据。因此从这个角度上讲 Spark 的性能应该是超过 Hadoop MapReduce 的。
然而,既然在内存中处理,Spark 就需要很大的内存容量。就像一个标准的数据库系统操作一样, Spark 每次将处理过程加载到内存之中,然后该操作作为缓存一直保持在内存中直到下一步操作。如果 Spark 与其它资源需求型服务一同运行在 Hadoop YARN 上,又或者数据块太大以至于不能完全读入内存,此时 Spark 的性能就会有很大的降低。
与此相反, MapReduce 会在一个工作完成的时候立即结束该进程,因此它可以很容易的和其它服务共同运行而不会产生明显的性能降低。
当涉及需要重复读取同样的数据进行迭代式计算的时候,Spark 有着自身优势。 但是当涉及单次读取、类似 ETL (抽取、转换、加载)操作的任务,比如数据转化、数据整合等时,MapReduce 绝对是不二之选,因为它就是为此而生的。
小结:当数据大小适于读入内存,尤其是在专用集群上时,Spark 表现更好;Hadoop MapReduce 适用于那些数据不能全部读入内存的情况,同时它还可以与其它服务同时运行。spark确实在一定方面比mapreduce快,比如机器学习的迭代过程,spark是把中间的数据保存在内存中,在每次迭代的时候直接从内存中提取,而mapreduce一直是IO传输,速度比spark慢。但是在相对的比较大,长时间处理与存储的数据来说,还是hadoop相对来说有可取的地方,所以很多企业都是结合起来用,或者更改源代码来获得更大效率
2)Spark 源码编译,针对不同版本的Hadoop 版本
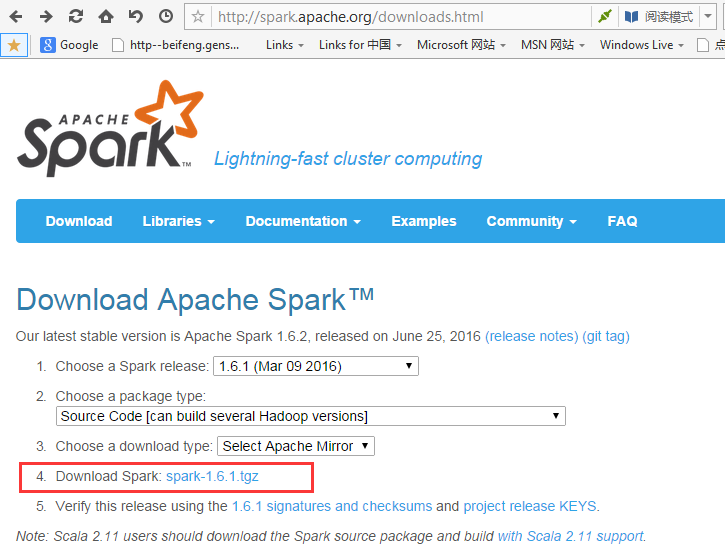
1,在官网下载spark
http://spark.apache.org/downloads.html
在此我我们选择1.6.1版本
2,根据官方文档进行编译

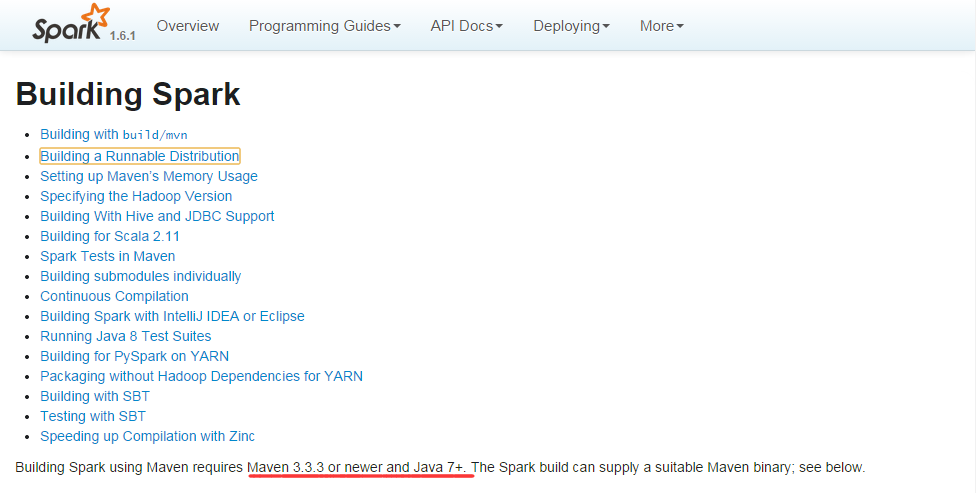
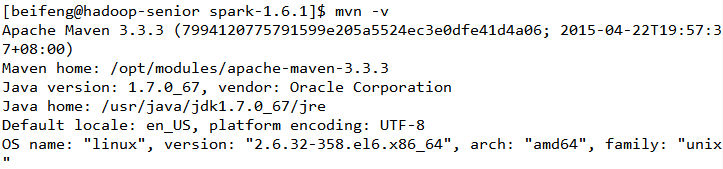
3,根据官网要求配置对应maven及jdk版本
4,打包编译make-distribution.sh

./make-distribution.sh --name custom-spark --tgz -Psparkr -Phadoop-2.4 -Phive -Phive-thriftserver -Pyarn
逐条参数设置:
--name custom 一般不指定
--tgz 把编译好的文件打包成tar包
-Phadoop-2.4 指定Hadoop版本
-Phive-thriftserver 支持hive
-Pyarn 支持yarn
上面语句参数不全
对于CDH版本需要加如下参数
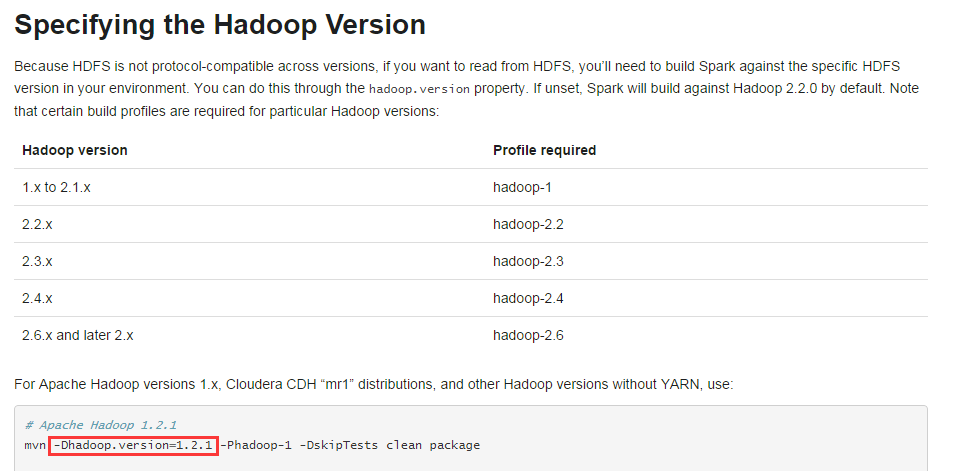
对于本例,使用2.5.0
参数为 -Dhadoop.version=2.5.0-mr1-cdh5.3.6
还需组合如下参数

针对 aparche hadoop 编译:
./make-distribution.sh --tgz -Phadoop-2.4 -Dhadoop.version=2.5.0 -Pyarn -Phive -Phive-thriftserver mvn clean package -DskipTests-Phadoop-2.4 -Dhadoop.version=2.5.0 -Pyarn -Phive -Phive-thriftserver
针对 CDH aparche 编译
./make-distribution.sh --tgz -Phadoop-2.4 -Dhadoop.version=2.5.0-cdh5.3.6 -Pyarn -Phive -Phive-thriftserver
修改 make-distribution.sh 文件
VERSION=1.6.1SCALA_VERSION=2.10.4SPARK_HADOOP_VERSION=2.5.0-cdh5.3.6SPARK_HIVE=1
如果针对CDH版本Hadoop
删除 $MAVEN_HOME/conf/settings 文件中的如下标签
<mirror><id>nexus-osc</id><mirrorOf>*</mirrorOf><name>Nexus osc</name><url>http://maven.oschina.net/content/groups/public/</url></mirror>
配置域名解析服务器
# vi /etc/resolv.conf
内容:
nameserver 8.8.8.8
nameserver 8.8.4.4
进入$SPARK_HOME,执行组合了参数的 make-distribution.sh 文件
./make-distribution.sh --tgz -Phadoop-2.4 -Dhadoop.version=2.5.0-cdh5.3.6 -Pyarn -Phive -Phive-thriftserver[INFO] ------------------------------------------------------------------------[INFO] Reactor Summary:[INFO][INFO] Spark Project Parent POM ........................... SUCCESS [ 6.923 s][INFO] Spark Project Test Tags ............................ SUCCESS [ 4.033 s][INFO] Spark Project Launcher ............................. SUCCESS [ 15.463 s][INFO] Spark Project Networking ........................... SUCCESS [ 11.982 s][INFO] Spark Project Shuffle Streaming Service ............ SUCCESS [ 6.390 s][INFO] Spark Project Unsafe ............................... SUCCESS [ 8.195 s][INFO] Spark Project Core ................................. SUCCESS [01:56 min][INFO] Spark Project Bagel ................................ SUCCESS [ 5.070 s][INFO] Spark Project GraphX ............................... SUCCESS [ 13.118 s][INFO] Spark Project Streaming ............................ SUCCESS [ 36.047 s][INFO] Spark Project Catalyst ............................. SUCCESS [ 49.638 s][INFO] Spark Project SQL .................................. SUCCESS [01:08 min][INFO] Spark Project ML Library ........................... SUCCESS [01:07 min][INFO] Spark Project Tools ................................ SUCCESS [ 2.873 s][INFO] Spark Project Hive ................................. SUCCESS [ 44.103 s][INFO] Spark Project Docker Integration Tests ............. SUCCESS [ 2.803 s][INFO] Spark Project REPL ................................. SUCCESS [ 8.310 s][INFO] Spark Project YARN Shuffle Service ................. SUCCESS [ 8.097 s][INFO] Spark Project YARN ................................. SUCCESS [ 12.728 s][INFO] Spark Project Hive Thrift Server ................... SUCCESS [ 8.788 s][INFO] Spark Project Assembly ............................. SUCCESS [02:02 min][INFO] Spark Project External Twitter ..................... SUCCESS [ 9.430 s][INFO] Spark Project External Flume Sink .................. SUCCESS [ 11.433 s][INFO] Spark Project External Flume ....................... SUCCESS [ 18.304 s][INFO] Spark Project External Flume Assembly .............. SUCCESS [ 4.526 s][INFO] Spark Project External MQTT ........................ SUCCESS [ 28.436 s][INFO] Spark Project External MQTT Assembly ............... SUCCESS [ 4.794 s][INFO] Spark Project External ZeroMQ ...................... SUCCESS [ 8.104 s][INFO] Spark Project External Kafka ....................... SUCCESS [ 11.387 s][INFO] Spark Project Examples ............................. SUCCESS [06:02 min][INFO] Spark Project External Kafka Assembly .............. SUCCESS [ 6.001 s][INFO] ------------------------------------------------------------------------[INFO] BUILD SUCCESS[INFO] ------------------------------------------------------------------------[INFO] Total time: 18:06 min[INFO] Finished at: 2016-07-19T18:25:49+08:00[INFO] Final Memory: 468M/1649M[INFO] ------------------------------------------------------------------------+ rm -rf /opt/modules/spark-1.6.1/dist+ mkdir -p /opt/modules/spark-1.6.1/dist/lib+ echo 'Spark 1.6.1 built for Hadoop 2.5.0-cdh5.3.6'+ echo 'Build flags: -Phadoop-2.4' -Dhadoop.version=2.5.0-cdh5.3.6 -Pyarn -Phive -Phive-thriftserver+ cp /opt/modules/spark-1.6.1/assembly/target/scala-2.10/spark-assembly-1.6.1-hadoop2.5.0-cdh5.3.6.jar /ob/+ cp /opt/modules/spark-1.6.1/examples/target/scala-2.10/spark-examples-1.6.1-hadoop2.5.0-cdh5.3.6.jar /ob/+ cp /opt/modules/spark-1.6.1/network/yarn/target/scala-2.10/spark-1.6.1-yarn-shuffle.jar /opt/modules/sp+ mkdir -p /opt/modules/spark-1.6.1/dist/examples/src/main+ cp -r /opt/modules/spark-1.6.1/examples/src/main /opt/modules/spark-1.6.1/dist/examples/src/+ '[' 1 == 1 ']'+ cp /opt/modules/spark-1.6.1/lib_managed/jars/datanucleus-api-jdo-3.2.6.jar /opt/modules/spark-1.6.1/lib-3.2.10.jar /opt/modules/spark-1.6.1/lib_managed/jars/datanucleus-rdbms-3.2.9.jar /opt/modules/spark-1.6.+ cp /opt/modules/spark-1.6.1/LICENSE /opt/modules/spark-1.6.1/dist+ cp -r /opt/modules/spark-1.6.1/licenses /opt/modules/spark-1.6.1/dist+ cp /opt/modules/spark-1.6.1/NOTICE /opt/modules/spark-1.6.1/dist+ '[' -e /opt/modules/spark-1.6.1/CHANGES.txt ']'+ cp /opt/modules/spark-1.6.1/CHANGES.txt /opt/modules/spark-1.6.1/dist+ cp -r /opt/modules/spark-1.6.1/data /opt/modules/spark-1.6.1/dist+ mkdir /opt/modules/spark-1.6.1/dist/conf+ cp /opt/modules/spark-1.6.1/conf/docker.properties.template /opt/modules/spark-1.6.1/conf/fairschedulerrk-1.6.1/conf/log4j.properties.template /opt/modules/spark-1.6.1/conf/metrics.properties.template /opt/motemplate /opt/modules/spark-1.6.1/conf/spark-defaults.conf.template /opt/modules/spark-1.6.1/conf/spark-eark-1.6.1/dist/conf+ cp /opt/modules/spark-1.6.1/README.md /opt/modules/spark-1.6.1/dist+ cp -r /opt/modules/spark-1.6.1/bin /opt/modules/spark-1.6.1/dist+ cp -r /opt/modules/spark-1.6.1/python /opt/modules/spark-1.6.1/dist+ cp -r /opt/modules/spark-1.6.1/sbin /opt/modules/spark-1.6.1/dist+ cp -r /opt/modules/spark-1.6.1/ec2 /opt/modules/spark-1.6.1/dist+ '[' -d /opt/modules/spark-1.6.1/R/lib/SparkR ']'+ '[' false == true ']'+ '[' true == true ']'+ TARDIR_NAME=spark-1.6.1-bin-2.5.0-cdh5.3.6+ TARDIR=/opt/modules/spark-1.6.1/spark-1.6.1-bin-2.5.0-cdh5.3.6+ rm -rf /opt/modules/spark-1.6.1/spark-1.6.1-bin-2.5.0-cdh5.3.6+ cp -r /opt/modules/spark-1.6.1/dist /opt/modules/spark-1.6.1/spark-1.6.1-bin-2.5.0-cdh5.3.6+ tar czf spark-1.6.1-bin-2.5.0-cdh5.3.6.tgz -C /opt/modules/spark-1.6.1 spark-1.6.1-bin-2.5.0-cdh5.3.6+ rm -rf /opt/modules/spark-1.6.1/spark-1.6.1-bin-2.5.0-cdh5.3.6
4)Spark Cluster的理解,如何提交Spark Application及运行
Standalone类似于YARN这样的框架
分布式
主节点:
Master - ResourceManager
从节点:
Works - NodeManagers
只要资源足够,一台服务器可以分配多个Works
start-slaves.sh
启动所有的从节点,也就是Work
注意:使用此命令时,运行此命令的机器,必须要配置与其他机器的SSH无密钥登录,否则启动的时候会出现一些问题,比如说输入密码之类的。
配置 Standalon
$SPARK_HOME/conf/spark-env.sh 添加以下信息
JAVA_HOME=/usr/java/jdk1.7.0_67SCALA_HOME=/opt/modules/scala-2.10.4HADOOP_CONF_DIR=/opt/modules/hadoop-2.5.0-cdh5.3.6/etc/hadoopSPARK_MASTER_IP=hadoop-senior.ibeifeng.comSPARK_MASTER_PORT=7077SPARK_MASTER_WEBUI_PORT=8080SPARK_WORKER_CORES=2SPARK_WORKER_MEMORY=2gSPARK_WORKER_PORT=7078SPARK_WORKER_WEBUI_PORT=8081SPARK_WORKER_INSTANCES=1
$SPARK_HOME/conf/slaves localhost 改为 hadoop-senior.ibeifeng.com
$HADOOP_HOME $ sbin/hadoop-daemon.sh start namenode$HADOOP_HOME $sbin/hadoop-daemon.sh start datanode$SPARK_HOME $ sbin/start-master.shstarting org.apache.spark.deploy.master.Master, logging to /opt/modules/spark-1.6.1/logs/spark-beifeng-org.apache.spark.deploy.master.Master-1-hadoop-senior.ibeifeng.com.out$SPARK_HOME $ sbin/start-slaves.shlocalhost: starting org.apache.spark.deploy.worker.Worker, logging to /opt/modules/spark-1.6.1/logs/spark-beifeng-org.apache.spark.deploy.worker.Worker-1-hadoop-senior.ibeifeng.com.out$ jps4115 NameNode4527 Jps4308 Master4203 DataNode4456 Worker
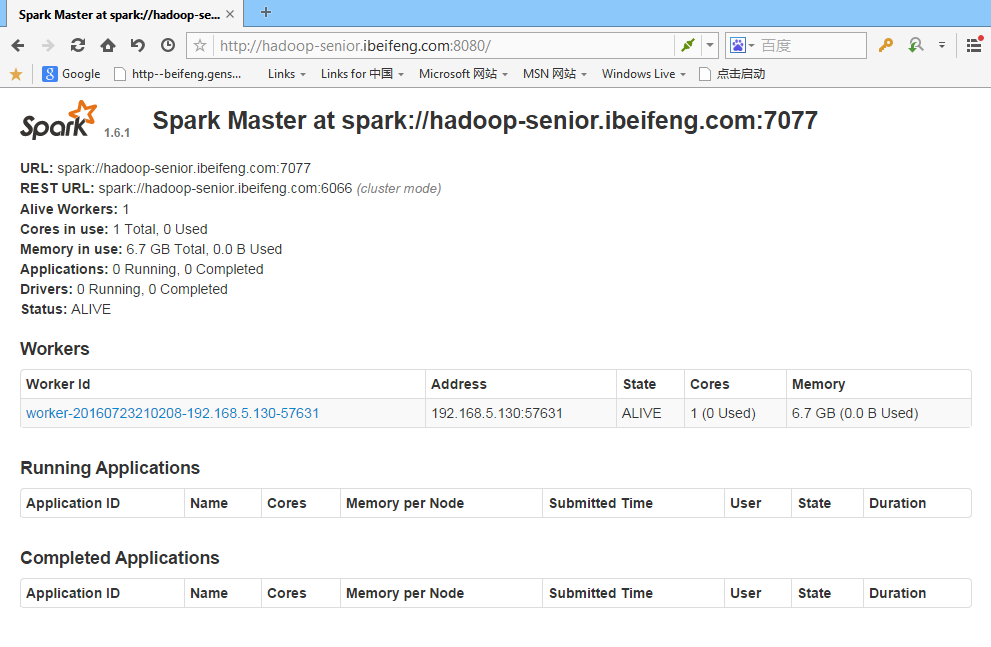
查看master网页 http://hadoop-senior.ibeifeng.com:8080/
SPARK_MASTER_WEBUI_PORT=8080
[beifeng@hadoop-senior spark-1.6.1]$ bin/spark-shell --helpUsage: ./bin/spark-shell [options]Options:--master MASTER_URL spark://host:port, mesos://host:port, yarn, or local.SPARK_MASTER_PORT=7077spark://hadoop-senior.ibeifeng.com:7077$ bin/spark-shell --master spark://hadoop-senior.ibeifeng.com:7077scala> val rdd = sc.textFile("hdfs://hadoop-senior.ibeifeng.com:8020/input")rdd: org.apache.spark.rdd.RDD[String] = hdfs://hadoop-senior.ibeifeng.com:8020/input MapPartitionsRDD[1] at textFile at <console>:27scala> rdd.countres0: Long = 100000
