@Arslan6and6
2016-08-29T02:34:20.000000Z
字数 679
阅读 719
shuffle理解
mapreduce
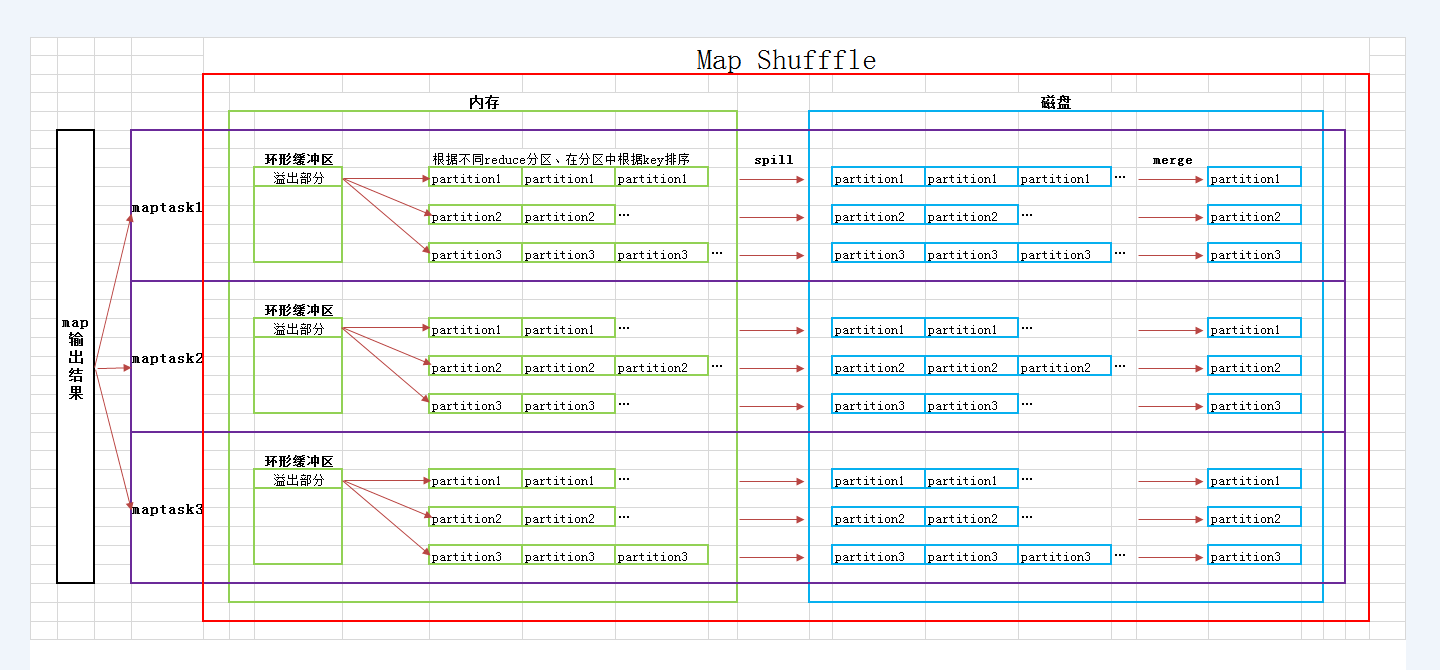
map端
1.maptask将数据写入内存环形缓冲区2.持续写入,数据从内存环形缓冲区溢出,根据不同reduce分区,在分区中排序,以减轻reduce排序负担job.setPartitionerClass(cls)job.setSortComparatorClsss(cls)3.将不同次数溢写的生成的小文件按分区合并成大文件 得到如 <hadoop,1> <hadoop,1> <hadoop, 1>的map端输出数据
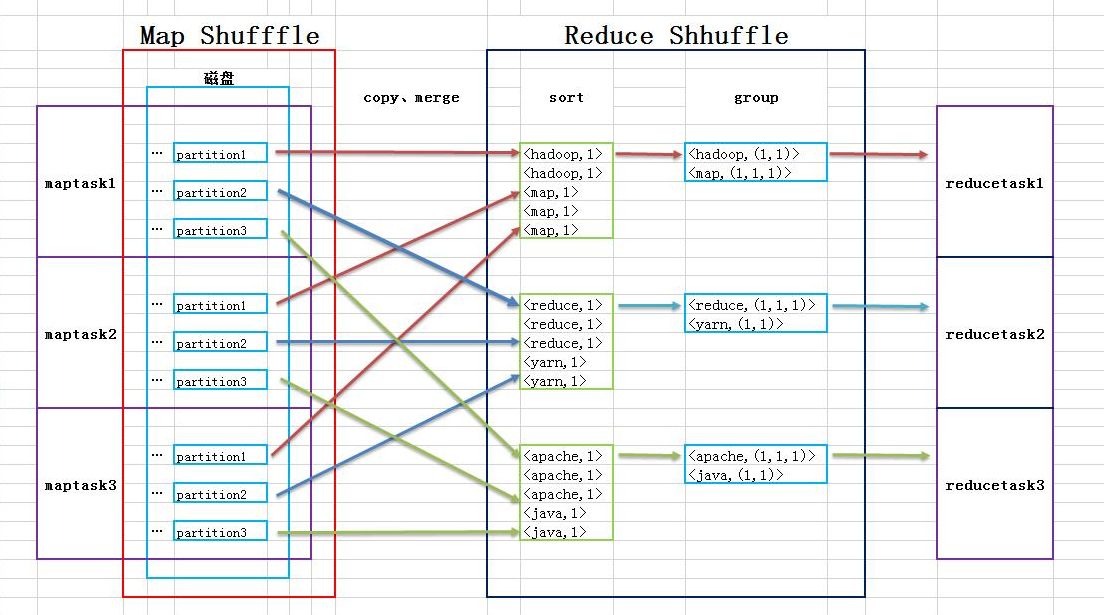
reduce端
4.将不同map端数据按分区copy到reduce端,在每个reduce端合并成一个大文件5.将每个reduce端的数据进行排序6.件排序后的数据按照key分组,value组合在一起 得到如 <hadoop, (1, 1, 1)> 数据 输出给reducetaskjob.setGroupingComparatorClass(cls)
combine (map端) 一个maptask中的 key相同数据合并,如词频统计<world, 1>,<world, 1> 合并成 <world, 2>取最大值<a, 23>,<a, 78> 合并成 <a, 78>--map端的reduce(合并)操作--不是所有程序都适合(求平均值)job.setCombinerClass(cls) 看实际情况能否传入reduce类compress 传输给reduce端前压缩,传输到reduce端数据量减少1、vi mapred-site.xml (全局生效)2、configuration.set(mapreduce.map.output.compress,true)