@Arslan6and6
2016-05-30T16:26:40.000000Z
字数 15371
阅读 717
【作业十九】殷杰
第九章、大数据仓库Hive高级案例
---Hive日志分析案例二
作业描述:
在【日志分析案例一】基础之上,加强业务需求进行数据分析,具体需求见课程说明。
需求表如下:

track_log表中字段描述如下
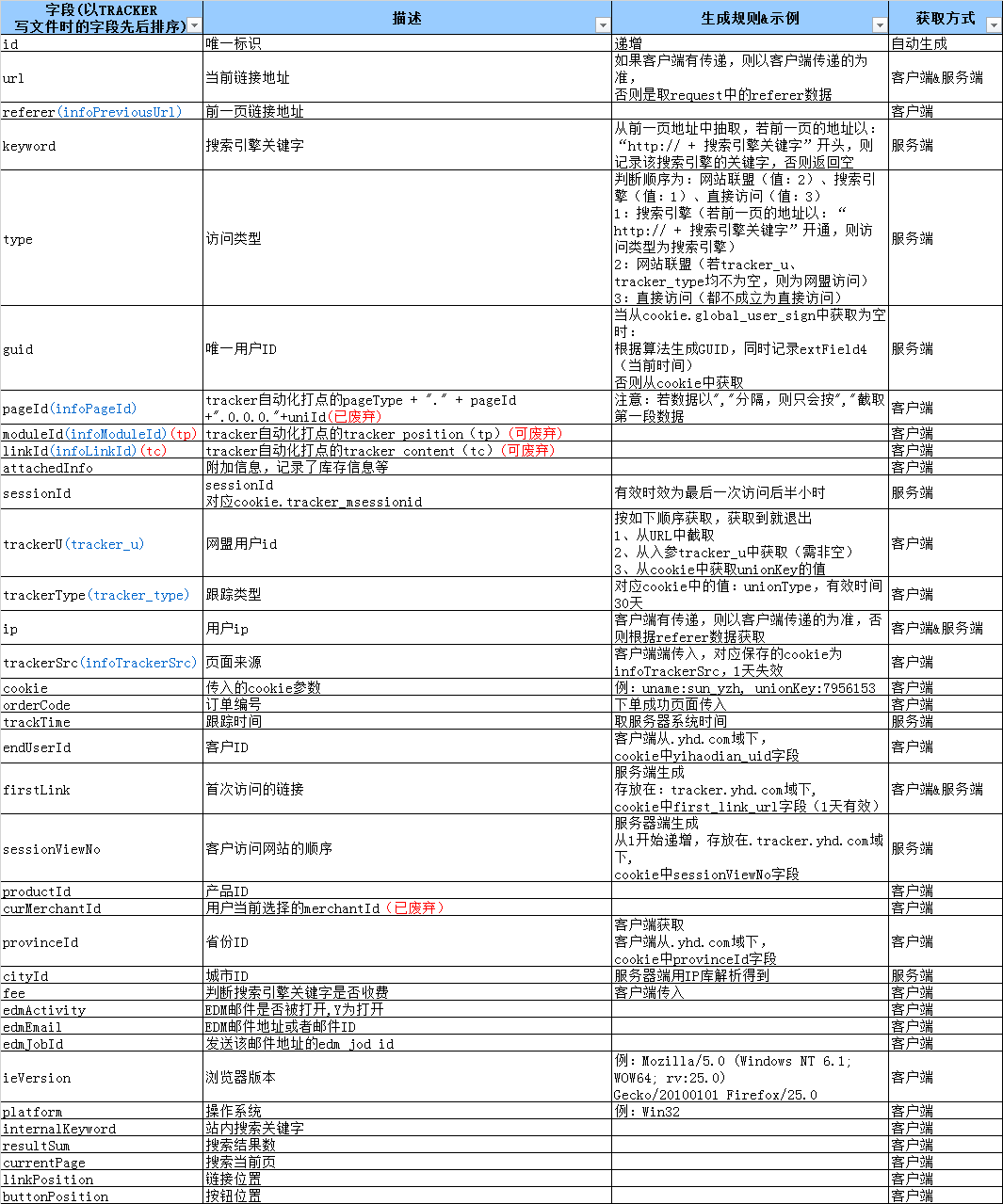
需求:将track_log表中各字段按照需求表字段数据提取并统计
思路:
1.需求表字段对应track_log表字段编写会话信息表描述,会话信息表体现需求键名与track_log表对应关系
举例如下
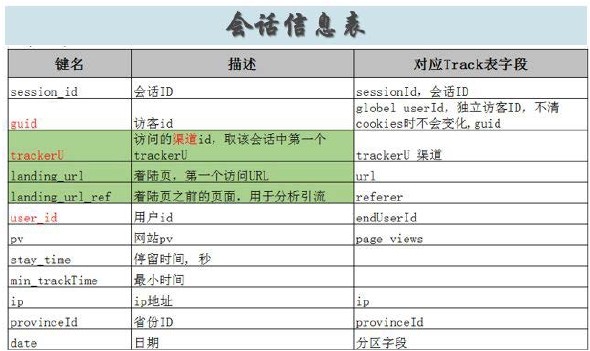
2.按会话信息表描述在Hive中建立会话信息表空表
3.按需求字段从track_log表抽取数据到会话信息表
4.抽取会话信息表数据到新建需求表中进行统计
实现步骤:
1.建立会话信息表session
hive (db_track)> create table session_info(> session_id string,> guid string,> trackerU string,> landing_url string,> landing_url_ref string,> user_id string,> pv string,> stay_time string,> min_trackTime string,> ip string,> provinceId string> )> partitioned by (date string)> row format delimited fields terminated by '\t' ;OKTime taken: 0.859 seconds
2.创建临时表 session_info_tmp1 ,把所需字段信息从 track_log 表导入
hive (db_track)> create table session_info_tmp1 as select> sessionId session_id,> max(guid) guid,> max(endUserId) user_id,> count(url) pv,> (max(unix_timestamp(trackTime)) - min(unix_timestamp(trackTime))) stay_time,> min(trackTime) min_trackTime ,> max(ip) ip,> max(provinceId) provinceId> from track_log where date='20150828'> group by sessionId ;Total jobs = 1Launching Job 1 out of 1Number of reduce tasks not specified. Estimated from input data size: 1In order to change the average load for a reducer (in bytes):set hive.exec.reducers.bytes.per.reducer=<number>In order to limit the maximum number of reducers:set hive.exec.reducers.max=<number>In order to set a constant number of reducers:set mapreduce.job.reduces=<number>Starting Job = job_1464600726756_0001, Tracking URL = http://hadoop-senior.ibeifeng.com:8088/proxy/application_1464600726756_0001/Kill Command = /opt/modules/hadoop-2.5.0-cdh5.3.6/bin/hadoop job -kill job_1464600726756_0001Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 12016-05-30 17:34:36,735 Stage-1 map = 0%, reduce = 0%2016-05-30 17:34:56,812 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.07 sec2016-05-30 17:35:16,548 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2.69 secMapReduce Total cumulative CPU time: 2 seconds 690 msecEnded Job = job_1464600726756_0001Moving data to: hdfs://hadoop-senior.ibeifeng.com:8020/user/hive/warehouse/db_track.db/session_info_tmp1Table db_track.session_info_tmp1 stats: [numFiles=1, numRows=0, totalSize=0, rawDataSize=0]MapReduce Jobs Launched:Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 2.69 sec HDFS Read: 429 HDFS Write: 52 SUCCESSTotal MapReduce CPU Time Spent: 2 seconds 690 msecOKsession_id guid user_id pv stay_time min_tracktime ip provinceidTime taken: 69.668 seconds
3.创建临时表session_info_tmp2
hive (db_track)> create table session_info_tmp2 as select> sessionId session_id,> trackTime trackTime,> trackeru trackerU,> url landing_url,> referer landing_url_ref> from track_log where date='20150828' ;Total jobs = 3Launching Job 1 out of 3Number of reduce tasks is set to 0 since there's no reduce operatorStarting Job = job_1464600726756_0002, Tracking URL = http://hadoop-senior.ibeifeng.com:8088/proxy/application_1464600726756_0002/Kill Command = /opt/modules/hadoop-2.5.0-cdh5.3.6/bin/hadoop job -kill job_1464600726756_0002Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 02016-05-30 18:16:10,956 Stage-1 map = 0%, reduce = 0%2016-05-30 18:16:33,069 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 0.91 secMapReduce Total cumulative CPU time: 910 msecEnded Job = job_1464600726756_0002Stage-4 is selected by condition resolver.Stage-3 is filtered out by condition resolver.Stage-5 is filtered out by condition resolver.Moving data to: hdfs://hadoop-senior.ibeifeng.com:8020/user/hive/warehouse/db_track.db/.hive-staging_hive_2016-05-30_18-15-55_162_8334205732777417774-1/-ext-10001Moving data to: hdfs://hadoop-senior.ibeifeng.com:8020/user/hive/warehouse/db_track.db/session_info_tmp2Table db_track.session_info_tmp2 stats: [numFiles=1, numRows=0, totalSize=0, rawDataSize=0]MapReduce Jobs Launched:Stage-Stage-1: Map: 1 Cumulative CPU: 0.91 sec HDFS Read: 429 HDFS Write: 52 SUCCESSTotal MapReduce CPU Time Spent: 910 msecOKsession_id tracktime trackeru landing_url landing_url_refTime taken: 41.865 seconds
4.导入会话表数据
hive (db_track)> insert overwrite table session_info partition (date='20150828')> select> a.session_id,> a.guid,> b.trackerU,> b.landing_url,> b.landing_url_ref,> a.user_id,> a.pv,> a.stay_time,> a.min_trackTime,> a.ip,> a.provinceId> from session_info_tmp1 a join session_info_tmp2 b> on a.session_id=b.session_id> and a.min_trackTime=b.trackTime ;Total jobs = 116/05/30 18:26:08 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable16/05/30 18:26:09 WARN conf.HiveConf: DEPRECATED: hive.metastore.ds.retry.* no longer has any effect. Use hive.hmshandler.retry.* insteadExecution log at: /tmp/beifeng/beifeng_20160530182626_42ba565a-123f-477d-b626-0c1dfe3c4b88.log2016-05-30 06:26:11 Starting to launch local task to process map join; maximum memory = 5189795842016-05-30 06:26:13 Dump the side-table into file: file:/tmp/beifeng/hive_2016-05-30_18-26-00_624_1665288294433606603-1/-local-10002/HashTable-Stage-4/MapJoin-mapfile00--.hashtable2016-05-30 06:26:13 Uploaded 1 File to: file:/tmp/beifeng/hive_2016-05-30_18-26-00_624_1665288294433606603-1/-local-10002/HashTable-Stage-4/MapJoin-mapfile00--.hashtable (260 bytes)2016-05-30 06:26:13 End of local task; Time Taken: 1.67 sec.Execution completed successfullyMapredLocal task succeededLaunching Job 1 out of 1Number of reduce tasks is set to 0 since there's no reduce operatorStarting Job = job_1464600726756_0003, Tracking URL = http://hadoop-senior.ibeifeng.com:8088/proxy/application_1464600726756_0003/Kill Command = /opt/modules/hadoop-2.5.0-cdh5.3.6/bin/hadoop job -kill job_1464600726756_0003Hadoop job information for Stage-4: number of mappers: 1; number of reducers: 02016-05-30 18:26:28,466 Stage-4 map = 0%, reduce = 0%2016-05-30 18:26:44,721 Stage-4 map = 100%, reduce = 0%, Cumulative CPU 0.96 secMapReduce Total cumulative CPU time: 960 msecEnded Job = job_1464600726756_0003Loading data to table db_track.session_info partition (date=20150828)Partition db_track.session_info{date=20150828} stats: [numFiles=1, numRows=0, totalSize=0, rawDataSize=0]MapReduce Jobs Launched:Stage-Stage-4: Map: 1 Cumulative CPU: 0.96 sec HDFS Read: 251 HDFS Write: 61 SUCCESSTotal MapReduce CPU Time Spent: 960 msecOKa.session_id a.guid b.trackeru b.landing_url b.landing_url_ref a.user_id a.pv a.stay_time a.min_tracktima.ip a.provinceidTime taken: 48.044 seconds
5.统计 session_info 表如下字段数据,并导入到 vistor_users_info 需求表
date UV PV 登录人数 游客人数 平均访问时长 二跳率 独立IP
hive (db_track)> create table vistor_users_info as> select> date,> count(distinct guid) UV,> sum(pv) PV,> count(case when user_id != '' then user_id else null end) login_users,> count(case when user_id = '' then user_id else null end) vistor_users,> avg(stay_time) avg_stay_time,> count(case when pv>=2 then session_id else null end)/count(session_id) sec_ratio,> count(distinct ip) ip> from session_info where date='20150828'> group by date ;Total jobs = 1Launching Job 1 out of 1Number of reduce tasks not specified. Estimated from input data size: 1In order to change the average load for a reducer (in bytes):set hive.exec.reducers.bytes.per.reducer=<number>In order to limit the maximum number of reducers:set hive.exec.reducers.max=<number>In order to set a constant number of reducers:set mapreduce.job.reduces=<number>Starting Job = job_1464600726756_0004, Tracking URL = http://hadoop-senior.ibeifeng.com:8088/proxy/application_1464600726756_0004/Kill Command = /opt/modules/hadoop-2.5.0-cdh5.3.6/bin/hadoop job -kill job_1464600726756_0004Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 12016-05-30 18:44:05,804 Stage-1 map = 0%, reduce = 0%2016-05-30 18:44:26,410 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.04 sec2016-05-30 18:44:41,263 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.24 secMapReduce Total cumulative CPU time: 3 seconds 240 msecEnded Job = job_1464600726756_0004Moving data to: hdfs://hadoop-senior.ibeifeng.com:8020/user/hive/warehouse/db_track.db/vistor_users_infoTable db_track.vistor_users_info stats: [numFiles=1, numRows=0, totalSize=0, rawDataSize=0]MapReduce Jobs Launched:Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.24 sec HDFS Read: 260 HDFS Write: 52 SUCCESSTotal MapReduce CPU Time Spent: 3 seconds 240 msecOKdate uv pv login_users vistor_users avg_stay_time sec_ratio ipTime taken: 52.767 seconds
6.查看该需求表得到分析信息
hive (db_track)> select * from vistor_users_info;OKvistor_users_info.date vistor_users_info.uv vistor_users_info.pv vistor_users_info.login_users vistor_users_info.vistor_usersvistor_users_info.avg_stay_time vistor_users_info.sec_ratio vistor_users_info.ip20150828 38985 131668.0 18548 21902 750.7895179233622 0.5238813349814586 29668Time taken: 0.523 seconds, Fetched: 1 row(s)
注意:使用 create table 表名 as select 字段属性 from 会话信息表; ,创建的统计结果表vistor_users_info,就算在创建会话信息表session时指定分隔符,统计结果表vistor_users_info在text查看时仍然显示方框分割,导致sqoop导入MySQL时不能解析。

解决办法,删除as select建立的分析结果表vistor_users_info,单独创建并指定分割符,在用insert into table 导入数据。即可正常使用sqoop导入MySQL。
hive (db_track)> create table vistor_users_info(> date string,> UV string,> PV string,> login_users string,> vistor_users string,> avg_stay_time string,> sec_ratio string,> ip string> )> row format delimited fields terminated by '\t' ;OKTime taken: 0.147 seconds
将会话信息表数据加入 vistor_users_info 进行统计
hive (db_track)> insert into table vistor_users_info select> date,> count(distinct guid) UV,> sum(pv) PV,> count(case when user_id != '' then user_id else null end) login_users,> count(case when user_id = '' then user_id else null end) vistor_users,> avg(stay_time) avg_stay_time,> count(case when pv>=2 then session_id else null end)/count(session_id) sec_ratio,> count(distinct ip) ip> from session_info where date='20150828'> group by date ;Total jobs = 1Launching Job 1 out of 1Number of reduce tasks not specified. Estimated from input data size: 1In order to change the average load for a reducer (in bytes):set hive.exec.reducers.bytes.per.reducer=<number>In order to limit the maximum number of reducers:set hive.exec.reducers.max=<number>In order to set a constant number of reducers:set mapreduce.job.reduces=<number>Starting Job = job_1464600726756_0030, Tracking URL = http://hadoop-senior.ibeifeng.com:8088/proxy/application_1464600726756_0030/Kill Command = /opt/modules/hadoop-2.5.0-cdh5.3.6/bin/hadoop job -kill job_1464600726756_0030Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 12016-05-30 23:21:18,203 Stage-1 map = 0%, reduce = 0%2016-05-30 23:21:46,752 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.6 sec2016-05-30 23:22:17,900 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 7.68 secMapReduce Total cumulative CPU time: 7 seconds 680 msecEnded Job = job_1464600726756_0030Loading data to table db_track.vistor_users_infoTable db_track.vistor_users_info stats: [numFiles=1, numRows=1, totalSize=79, rawDataSize=78]MapReduce Jobs Launched:Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 7.68 sec HDFS Read: 9121608 HDFS Write: 161 SUCCESSTotal MapReduce CPU Time Spent: 7 seconds 680 msecOKdate uv pv login_users vistor_users avg_stay_time sec_ratio ipTime taken: 73.532 seconds
在Hive中查看统计结果
hive (db_track)> select * from vistor_users_info;OKvistor_users_info.date vistor_users_info.uv vistor_users_info.pv vistor_users_info.login_users vistor_users_info.vistor_usersvistor_users_info.avg_stay_time vistor_users_info.sec_ratio vistor_users_info.ip20150828 38985 131668.0 18548 21902 750.7895179233622 0.5238813349814586 29668Time taken: 0.183 seconds, Fetched: 1 row(s)
在MySQL中创建接收结果表 vistor_users_info
create table vistor_users_info(date varchar(20),uv varchar(50),pv varchar(50),login_users varchar(50),vistor_users varchar(50),avg_stay_time varchar(50),sec_ratio varchar(50),ip varchar(50));
使用sqoop将导入MySQL
bin/sqoop export \> --connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/db_0521 \> --username root \> --password 123 \> --table vistor_users_info \> --export-dir /user/hive/warehouse/db_track.db/vistor_users_info \> --input-fields-terminated-by '\t'Warning: /opt/modules/sqoop-1.4.5-cdh5.3.6/bin/../../hbase does not exist! HBase imports will fail.Please set $HBASE_HOME to the root of your HBase installation.Warning: /opt/modules/sqoop-1.4.5-cdh5.3.6/bin/../../hcatalog does not exist! HCatalog jobs will fail.Please set $HCAT_HOME to the root of your HCatalog installation.Warning: /opt/modules/sqoop-1.4.5-cdh5.3.6/bin/../../accumulo does not exist! Accumulo imports will fail.Please set $ACCUMULO_HOME to the root of your Accumulo installation.Warning: /opt/modules/sqoop-1.4.5-cdh5.3.6/bin/../../zookeeper does not exist! Accumulo imports will fail.Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.16/05/30 23:24:50 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5-cdh5.3.616/05/30 23:24:50 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.16/05/30 23:24:51 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.16/05/30 23:24:51 INFO tool.CodeGenTool: Beginning code generation16/05/30 23:24:51 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `vistor_users_info` AS t LIMIT 116/05/30 23:24:51 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `vistor_users_info` AS t LIMIT 116/05/30 23:24:51 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /opt/modules/hadoop-2.5.0-cdh5.3.6Note: /tmp/sqoop-beifeng/compile/d59d0a6ed5ece911a523a321474bffbb/vistor_users_info.java uses or overrides a deprecated API.Note: Recompile with -Xlint:deprecation for details.16/05/30 23:24:55 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-beifeng/compile/d59d0a6ed5ece911a523a321474bffbb/vistor_users_info.jar16/05/30 23:24:55 INFO mapreduce.ExportJobBase: Beginning export of vistor_users_info16/05/30 23:24:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable16/05/30 23:24:55 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar16/05/30 23:24:57 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative16/05/30 23:24:57 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative16/05/30 23:24:57 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps16/05/30 23:24:57 INFO client.RMProxy: Connecting to ResourceManager at hadoop-senior.ibeifeng.com/192.168.5.130:803216/05/30 23:25:02 INFO input.FileInputFormat: Total input paths to process : 116/05/30 23:25:02 INFO input.FileInputFormat: Total input paths to process : 116/05/30 23:25:03 INFO mapreduce.JobSubmitter: number of splits:416/05/30 23:25:03 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative16/05/30 23:25:03 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1464600726756_003116/05/30 23:25:04 INFO impl.YarnClientImpl: Submitted application application_1464600726756_003116/05/30 23:25:04 INFO mapreduce.Job: The url to track the job: http://hadoop-senior.ibeifeng.com:8088/proxy/application_1464600726756_0031/16/05/30 23:25:04 INFO mapreduce.Job: Running job: job_1464600726756_003116/05/30 23:25:19 INFO mapreduce.Job: Job job_1464600726756_0031 running in uber mode : false16/05/30 23:25:19 INFO mapreduce.Job: map 0% reduce 0%16/05/30 23:26:04 INFO mapreduce.Job: map 100% reduce 0%16/05/30 23:26:12 INFO mapreduce.Job: Job job_1464600726756_0031 completed successfully16/05/30 23:26:15 INFO mapreduce.Job: Counters: 30File System CountersFILE: Number of bytes read=0FILE: Number of bytes written=525728FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=1054HDFS: Number of bytes written=0HDFS: Number of read operations=19HDFS: Number of large read operations=0HDFS: Number of write operations=0Job CountersLaunched map tasks=4Data-local map tasks=4Total time spent by all maps in occupied slots (ms)=175923Total time spent by all reduces in occupied slots (ms)=0Total time spent by all map tasks (ms)=175923Total vcore-seconds taken by all map tasks=175923Total megabyte-seconds taken by all map tasks=180145152Map-Reduce FrameworkMap input records=1Map output records=1Input split bytes=826Spilled Records=0Failed Shuffles=0Merged Map outputs=0GC time elapsed (ms)=272CPU time spent (ms)=2810Physical memory (bytes) snapshot=358006784Virtual memory (bytes) snapshot=3356164096Total committed heap usage (bytes)=62914560File Input Format CountersBytes Read=0File Output Format CountersBytes Written=016/05/30 23:26:15 INFO mapreduce.ExportJobBase: Transferred 1.0293 KB in 78.1854 seconds (13.4808 bytes/sec)16/05/30 23:26:15 INFO mapreduce.ExportJobBase: Exported 1 records.
在 MySQL 查看 vistor_users_info 表接收的统计结果

