@Arslan6and6
2016-08-29T02:12:24.000000Z
字数 13676
阅读 722
【作业十】殷杰
第五章、高级Hadoop2.x
---MapReduce高级应用练习 【二次排序案例】和【MapReduce Join案例】
作业描述:
依据上课讲解【二次排序案例】和【MapReduce Join案例】进行编码实现和要点分析,以下几点必须在作业中体现:
1) 理解【二次排序】功能,使用自己理解的方式表达(包括自定义数据类型、分区、分组、排序)。
2) 编码实现二次排序功能,提供源代码文件
3) 理解 MapReduce Join 的几种方式,编码实现 Reduce Join,提供源代码,说出思路。
1) 理解【二次排序】功能,使用自己理解的方式表达(包括自定义数据类型、分区、分组、排序)。
1.二次排序概念:
首先按照第一字段排序,然后再对第一字段相同的行按照第二字段排序,注意不能破坏第一次排序的结果 。
例如:将下列内容的文件用二次排序程序执行

要得到下列结果

2、思路
将键设为综合原始键和值的复合键。
键comparator应该以复合键排序,即原本的键和值组合。
partitioner和复合键comparator的分组只考虑本来键的分区和分组。
3、实现分析
(1)自定义复合键key,由第一个字段即原本的key和第二个字段value组成,数据类型设定为PairWritable,即第一个字段Text和第二个字段IntWritable数据类型组合。并设定一个PairWritable继承WritableComparable接口,以实现序列化和反序列化。
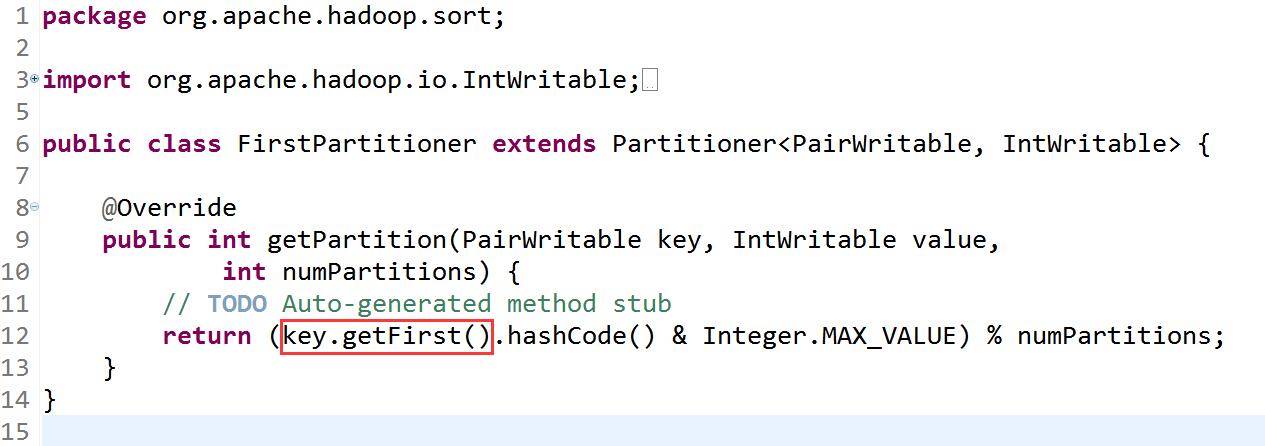
(2)为程序调优设置map端shuffle分区。并创建FirstPartitioner分区类。

该过程以第一个字段key进行分区,以key为依据自然就是比较key。为整个MR过程中第一次比较。本例中,设置分区类后a,1 a,100 a,3被分到一个reducetast,以此类推。如不设置分区类则按行分区。
(3)为程序调优设置reduce端shuffle分组。并创建FirstPartitioner分组类。如不设置分组则按默认复合键个数分组。
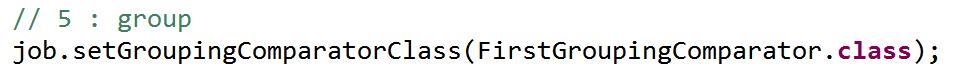
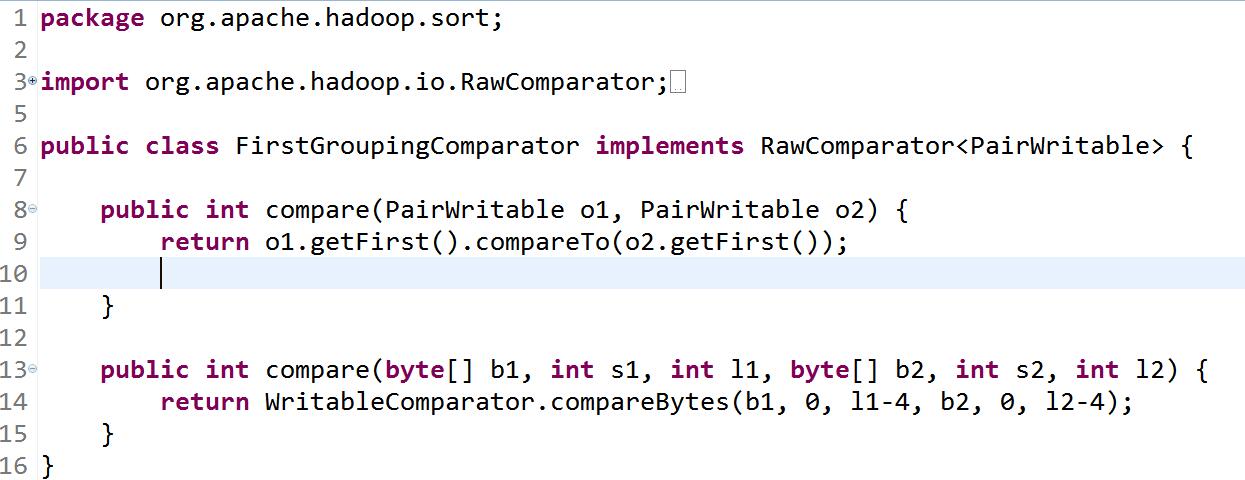
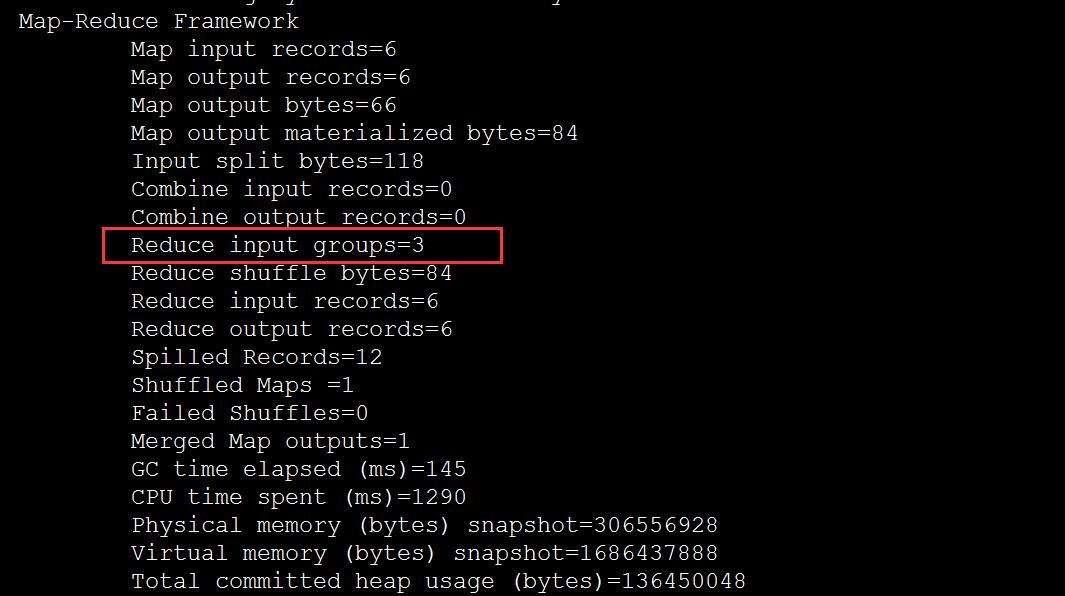
只要第一个字段key相同,而不是复合健相同。就把对于的value放进同一个组。
(4)在PairWritable类中以第一个字段为key为value排序,而不是以复合键。

2) 编码实现二次排序功能,提供源代码文件
SecondarySortMapReduce.java
package org.apache.hadoop.sort;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.conf.Configured;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Mapper.Context;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.Tool;import org.apache.hadoop.util.ToolRunner;public class SecondarySortMapReduce extends Configured implements Tool {// step 1 : mapper/*** public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>*/public static class WordCountMapper extends //Mapper<LongWritable, Text, PairWritable, IntWritable> {private PairWritable mapOutputKey = new PairWritable();private IntWritable mapOutputValue = new IntWritable();@Overridepublic void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {// line -- splitString[] strs = value.toString().split(",");// map output keymapOutputKey.set(strs[0], Integer.valueOf(strs[1]));// map output valuemapOutputValue.set(Integer.valueOf(strs[1]));context.write(mapOutputKey, mapOutputValue);}}// step 2 : reducer/**** a#1 1 a#3 3 a#100 100** @author beifeng**/public static class WordCountReducer extends //Reducer<PairWritable, IntWritable, Text, IntWritable> {private Text outputKey = new Text();@Overridepublic void reduce(PairWritable key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {// set output keyoutputKey.set(key.getFirst());for (IntWritable value : values) {context.write(outputKey, value);}}}// step 3 : jobpublic int run(String[] args) throws Exception {// 1 : get configurationConfiguration configuration = super.getConf();// 2 : create jobJob job = Job.getInstance(//configuration,//this.getClass().getSimpleName());job.setJarByClass(SecondarySortMapReduce.class);// job.setNumReduceTasks(tasks);// 3 : set job// input --> map --> reduce --> output// 3.1 : inputPath inPath = new Path(args[0]);FileInputFormat.addInputPath(job, inPath);// 3.2 : mapperjob.setMapperClass(WordCountMapper.class);// TODOjob.setMapOutputKeyClass(PairWritable.class);job.setMapOutputValueClass(IntWritable.class);// ====================shuffle==========================// 1: partitionjob.setPartitionerClass(FirstPartitioner.class);// 2: sort// job.setSortComparatorClass(cls);// 3: combine// job.setCombinerClass(cls);// 4: compress// set by configuration// 5 : groupjob.setGroupingComparatorClass(FirstGroupingComparator.class);// ====================shuffle==========================// 3.3 : reducerjob.setReducerClass(WordCountReducer.class);// TODOjob.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);// 3.4 : outputPath outPath = new Path(args[1]);FileOutputFormat.setOutputPath(job, outPath);// 4 : submit jobboolean isSuccess = job.waitForCompletion(true);return isSuccess ? 0 : 1;}public static void main(String[] args) throws Exception {//args = new String[] {// "hdfs://hadoop-senior.ibeifeng.com:8020/input/sort.txt",// "hdfs://hadoop-senior.ibeifeng.com:8020/output2/"// };// get configurationConfiguration configuration = new Configuration();// configuration.set(name, value);// run jobint status = ToolRunner.run(//configuration,//new SecondarySortMapReduce(),//args);// exit programSystem.exit(status);}}
PairWritable.java
package org.apache.hadoop.sort;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;import org.apache.hadoop.io.WritableComparable;public class PairWritable implements WritableComparable<PairWritable> {private String first ;private int second ;public PairWritable() {}public PairWritable(String first, int second) {this.set(first, second);}public void set(String first, int second) {this.setFirst(first);this.setSecond(second);}public String getFirst() {return first;}public void setFirst(String first) {this.first = first;}public int getSecond() {return second;}public void setSecond(int second) {this.second = second;}@Overridepublic int hashCode() {final int prime = 31;int result = 1;result = prime * result + ((first == null) ? 0 : first.hashCode());result = prime * result + second;return result;}@Overridepublic boolean equals(Object obj) {if (this == obj)return true;if (obj == null)return false;if (getClass() != obj.getClass())return false;PairWritable other = (PairWritable) obj;if (first == null) {if (other.first != null)return false;} else if (!first.equals(other.first))return false;if (second != other.second)return false;return true;}public void write(DataOutput out) throws IOException {out.writeUTF(this.getFirst());out.writeInt(this.getSecond());}public void readFields(DataInput in) throws IOException {this.setFirst(in.readUTF());this.setSecond(in.readInt());}public int compareTo(PairWritable o) {// firstint comp = this.getFirst().compareTo(o.getFirst()) ;if( 0 != comp ){return comp;}// secondreturn Integer.valueOf(this.getSecond()).compareTo(Integer.valueOf(o.getSecond()));}@Overridepublic String toString() {return first + "," + second ;}}
FirstPartitioner.java
package org.apache.hadoop.sort;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.mapreduce.Partitioner;public class FirstPartitioner extends Partitioner<PairWritable, IntWritable> {@Overridepublic int getPartition(PairWritable key, IntWritable value,int numPartitions) {// TODO Auto-generated method stubreturn (key.getFirst().hashCode() & Integer.MAX_VALUE) % numPartitions;}}
FirstGroupingComparator.java
package org.apache.hadoop.sort;import org.apache.hadoop.io.RawComparator;import org.apache.hadoop.io.WritableComparator;public class FirstGroupingComparator implements RawComparator<PairWritable> {public int compare(PairWritable o1, PairWritable o2) {return o1.getFirst().compareTo(o2.getFirst());}public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {return WritableComparator.compareBytes(b1, 0, l1-4, b2, 0, l2-4);}}
3) 理解 MapReduce Join 的几种方式,编码实现 Reduce Join,提供源代码,说出思路。
a)不同方式
map join :两个待连接的表,其中一个非常大,另一个非常小,可将小表直接放于内存中,DistributeCache实现。
reduce join:两个待连接的大表
semi join:map 端Join和reduce 端Join结合。
b):案例及思路
表文件信息:
customers.txt 按字段顺序排列 顾客编号 顾客姓名 顾客电话
以下为文件内容
1,Stephanie Leung,555-555-5555
2,Edward Kim,123-456-7890
3,Jose Madriz,281-330-8004
4,David Stork,408-555-0000
orders.txt 按字段顺序排列 顾客编号 商品名称 交易价格 交易时间
以下为文件内容
3,A,12.95,02-Jun-2008
1,B,88.25,20-May-2008
2,C,32.00,30-Nov-2007
3,D,25.02,22-Jan-2009
需求:把两个文件的内容按关联信息列示在一个虚拟表文件中。如
1,Stephanie Leung,555-555-5555,B,88.25,20-May-2008
2,Edward Kim,123-456-7890,C,32.00,30-Nov-2007
...
分析思路:
map端:用关联字段作为key输出,本例中关联字段均为第一列顾客编号,用flag标签标记文件内容来源。
reduce端: 区分标签文件内容,按key关联2文件内容,输出到1个表文件。同一顾客编号多条订单信息按该顾客订单数量分行列示。
代码:
DistributedCacheWCMapReduce.java
package com.ibeifeng.hadoop.mapreduce.cache;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStream;import java.io.InputStreamReader;import java.net.URI;import java.util.ArrayList;import java.util.List;import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.conf.Configured;import org.apache.hadoop.filecache.DistributedCache;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.Tool;import org.apache.hadoop.util.ToolRunner;public class DistributedCacheWCMapReduce extends Configured implements Tool{/*** Mapper*/public static class DistributedCacheWCMapper extendsMapper<LongWritable, Text, Text, IntWritable> {// cacheList<String> list = new ArrayList<String>();private final static IntWritable mapOutputValue = new IntWritable(1);private Text mapOutputKey = new Text();@SuppressWarnings("deprecation")@Overridepublic void setup(Context context) throws IOException,InterruptedException {// step 1: get configuraitonConfiguration conf = context.getConfiguration();// step 2: get cache uriURI[] uris = DistributedCache.getCacheFiles(conf);// step 3: pathPath paht = new Path(uris[0]);// step 4: file systemFileSystem fs = FileSystem.get(conf);// step 5: in streamInputStream inStream = fs.open(paht);// step 6: read dataInputStreamReader isr = new InputStreamReader(inStream);BufferedReader bf = new BufferedReader(isr);String line ;while ((line = bf.readLine()) != null){if(line.trim().length() > 0){// add elementlist.add(line);}}bf.close();isr.close();inStream.close();// fs.close();}@Overridepublic void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {String lineValue = value.toString();StringTokenizer st = new StringTokenizer(lineValue);while(st.hasMoreTokens()){String wordValue = st.nextToken();if(list.contains(wordValue)){continue;}// set map output keymapOutputKey.set(wordValue);// outputcontext.write(mapOutputKey, mapOutputValue);}}@Overridepublic void cleanup(Context context) throws IOException,InterruptedException {super.cleanup(context);}}/*** Reducer*/public static class DistributedCacheWCReducer extendsReducer<Text, IntWritable, Text, IntWritable> {public IntWritable outputValue = new IntWritable();@Overridepublic void setup(Context context) throws IOException,InterruptedException {super.setup(context);}@Overridepublic void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {int sum = 0 ;// iteratorfor(IntWritable value : values){sum += value.get() ;}// setoutputValue.set(sum);// job outputcontext.write(key, outputValue);}@Overridepublic void cleanup(Context context) throws IOException,InterruptedException {super.cleanup(context);}}/*** Driver :Job create,set,submit,run,monitor*/public int run(String[] args) throws Exception {// step 1:get configurationConfiguration conf = this.getConf();// step 2:create jobJob job = this.parseInputAndOutput(this,conf,args);// step 4:set job// 2:mapper classjob.setMapperClass(DistributedCacheWCMapper.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);// 4:reducer classjob.setReducerClass(DistributedCacheWCReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);// step 5:submit jobboolean isSuccess = job.waitForCompletion(true);return isSuccess ? 0 : 1;}public Job parseInputAndOutput(Tool tool,Configuration conf,String[] args) throws Exception {// validate argsif(args.length != 2){System.err.println("Usage : " + tool.getClass().getSimpleName() + " [generic options] <input> <output>");ToolRunner.printGenericCommandUsage(System.err);return null;}// step 2:create jobJob job = Job.getInstance(conf, tool.getClass().getSimpleName());// job.addCacheFile(uri);// step 3:set job run classjob.setJarByClass(tool.getClass());// 1:input formatPath inputPath = new Path(args[0]);FileInputFormat.addInputPath(job, inputPath);// 5:output formatPath outputPath = new Path(args[1]);FileOutputFormat.setOutputPath(job, outputPath);return job;}@SuppressWarnings("deprecation")public static void main(String[] args) throws Exception {//args = new String[]{// "hdfs://hadoop-yarn.beifeng.com:8020/user/beifeng/mr/distributedcache/input",//// "hdfs://hadoop-yarn.beifeng.com:8020/user/beifeng/mr/distributedcache/ouput"//};// mapreduce-default.xml,mapreduce-site.xmlConfiguration conf = new Configuration();// set distributed cache// ===============================================================URI uri = new URI("/user/beifeng/cachefile/cache.txt");DistributedCache.addCacheFile(uri, conf);// ===============================================================// run mapreduceint status = ToolRunner.run(conf, new DistributedCacheWCMapReduce(), args);// exit programSystem.exit(status);}}
map输出value数据类型为自定义数据类型,命名为DataJoinWritable。 故创建DataJoinWritable类。
package org.apache.hadoop.join;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;import org.apache.hadoop.io.Writable;public class DataJoinWritable implements Writable {private String tag ;private String data ;public DataJoinWritable() {}public DataJoinWritable(String tag, String data) {this.set(tag, data);}public void set(String tag, String data) {this.setTag(tag);this.setData(data);}public String getTag() {return tag;}public void setTag(String tag) {this.tag = tag;}public String getData() {return data;}public void setData(String data) {this.data = data;}@Overridepublic int hashCode() {final int prime = 31;int result = 1;result = prime * result + ((data == null) ? 0 : data.hashCode());result = prime * result + ((tag == null) ? 0 : tag.hashCode());return result;}@Overridepublic boolean equals(Object obj) {if (this == obj)return true;if (obj == null)return false;if (getClass() != obj.getClass())return false;DataJoinWritable other = (DataJoinWritable) obj;if (data == null) {if (other.data != null)return false;} else if (!data.equals(other.data))return false;if (tag == null) {if (other.tag != null)return false;} else if (!tag.equals(other.tag))return false;return true;}public void write(DataOutput out) throws IOException {out.writeUTF(this.getTag());out.writeUTF(this.getData());}public void readFields(DataInput in) throws IOException {this.setTag(in.readUTF());this.setData(in.readUTF());}@Overridepublic String toString() {return tag + "," + data ;}}
