@Arslan6and6
2016-10-10T06:56:23.000000Z
字数 6488
阅读 1219
IDEA 14.1.1 导入 SPARK 1.6.1 源码 并测试
spark
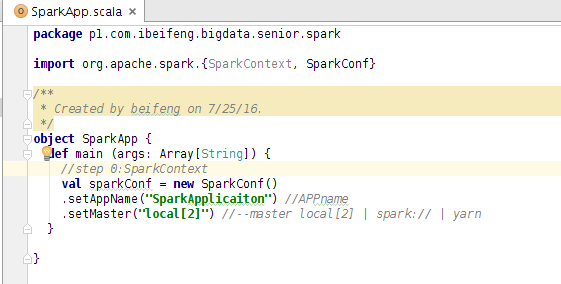

package p1.com.ibeifeng.bigdata.senior.sparkimport org.apache.spark.{SparkContext, SparkConf}/*** Driver Program*/object SparkApp {def main (args: Array[String]) {//step 0:SparkContextval sparkConf = new SparkConf().setAppName("SparkApplicaiton") //APPname.setMaster("local[2]") //--master local[2] | spark:// | yarn//Create SparkContextval sc = new SparkContext(sparkConf)/**======================================================================================*///step 1:input dataval rdd = sc.textFile("hdfs://hadoop-senior.ibeifeng.com:8020/input/page_views.data")//step 2:porcess dataval sessionCountTop10= rdd.map(line=>line.split("\t")).map(x=>(x(2),1)).reduceByKey(_+_).map(tuple=>(tuple._2,tuple._1)).sortByKey(false).take(10)//step 3:output datasessionCountTop10.foreach(println(_))/**======================================================================================*/sc.stop()}}16/07/25 16:03:07 INFO DAGScheduler: Job 1 finished: take at SparkApp.scala:30, took 0.995711 s(65,32d99014d80e5b683dc87e7c93f7c422)(65,2FF3QB5Z1ZYMFTQKCM6DUCUDDZXX1NAX)(59,3697499e2a4bc361c29d8e0652408915)(59,9364b2b10e1397e4673d77a37eb16b6e)(55,78e20c225db1e478727d51d7f23f1381)(51,edf91bcfd29523b0ba65367807ba3585)(50,784aaaaa4d570e9fb9d448f45eba2617)(44,74c300ab78b78337fb9a7ef5a12462f5)(43,53701e01643c9939ce492e0f5a60eb27)(42,1.2.4)
文件默认读取路径设置为HDFS ,代码可以写为 val rdd = sc.textFile("/input/page_views.data")
cp /opt/modules/hadoop-2.5.0-cdh5.3.6/etc/hadoop/core-site.xml /home/beifeng/IdeaProjects/scala_demo1/p1/src/main/resourcescp /opt/modules/hadoop-2.5.0-cdh5.3.6/etc/hadoop/hdfs-site.xml /home/beifeng/IdeaProjects/scala_demo1/p1/src/main/resources
打包jar包
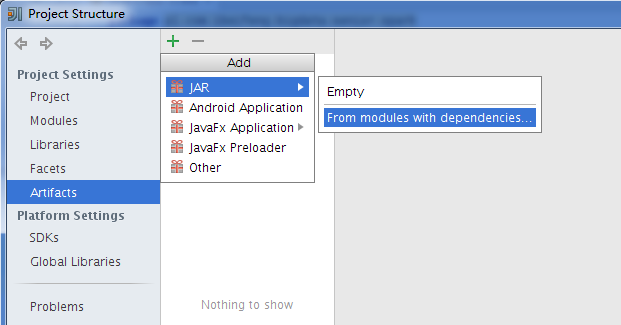
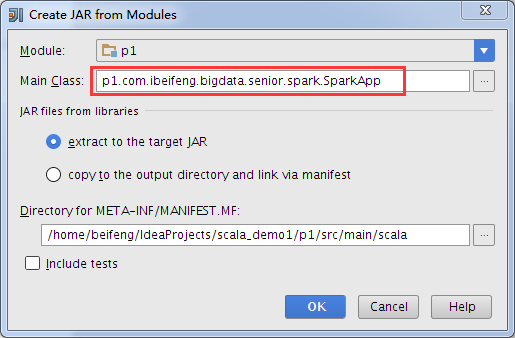
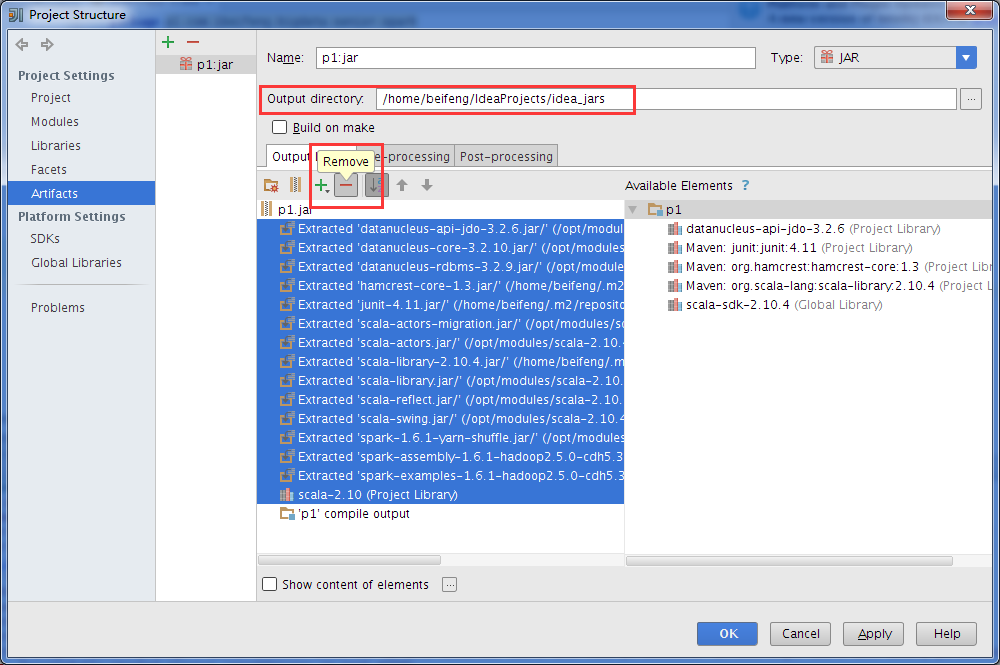
$ pwd/home/beifeng/IdeaProjects/idea_jars[beifeng@hadoop-senior idea_jars]$ lltotal 12-rw-rw-r-- 1 beifeng beifeng 9688 Jul 25 17:16 p1.jar[beifeng@hadoop-senior idea_jars]$ cp p1.jar /opt/modules/spark-1.6.1-bin-2.5.0-cdh5.3.6/
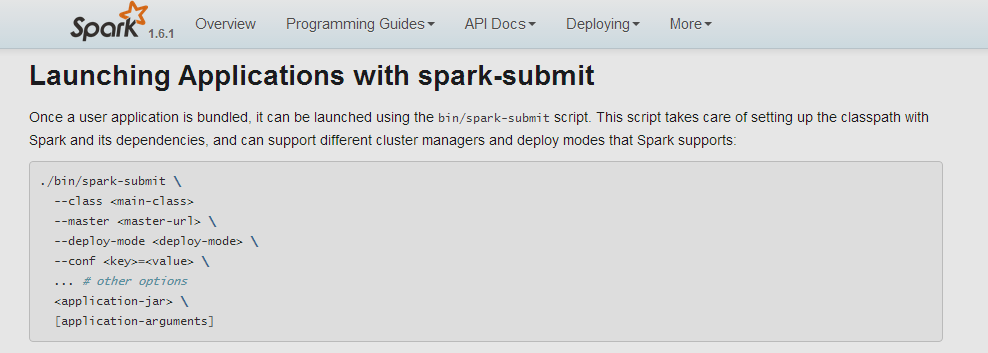
[beifeng@hadoop-senior spark-1.6.1-bin-2.5.0-cdh5.3.6]$ bin/spark-submit --helpUsage: spark-submit [options] <app jar | python file> [app arguments]Usage: spark-submit --kill [submission ID] --master [spark://...]Usage: spark-submit --status [submission ID] --master [spark://...]Options:--master MASTER_URL spark://host:port, mesos://host:port, yarn, or local.--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") oron one of the worker machines inside the cluster ("cluster")(Default: client).--class CLASS_NAME Your application's main class (for Java / Scala apps).--name NAME A name of your application.--jars JARS Comma-separated list of local jars to include on the driverand executor classpaths.--packages Comma-separated list of maven coordinates of jars to includeon the driver and executor classpaths. Will search the localmaven repo, then maven central and any additional remoterepositories given by --repositories. The format for thecoordinates should be groupId:artifactId:version.--exclude-packages Comma-separated list of groupId:artifactId, to exclude whileresolving the dependencies provided in --packages to avoiddependency conflicts.--repositories Comma-separated list of additional remote repositories tosearch for the maven coordinates given with --packages.--py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to placeon the PYTHONPATH for Python apps.--files FILES Comma-separated list of files to be placed in the workingdirectory of each executor.--conf PROP=VALUE Arbitrary Spark configuration property.--properties-file FILE Path to a file from which to load extra properties. If notspecified, this will look for conf/spark-defaults.conf.--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).--driver-java-options Extra Java options to pass to the driver.--driver-library-path Extra library path entries to pass to the driver.--driver-class-path Extra class path entries to pass to the driver. Note thatjars added with --jars are automatically included in theclasspath.--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).--proxy-user NAME User to impersonate when submitting the application.--help, -h Show this help message and exit--verbose, -v Print additional debug output--version, Print the version of current SparkSpark standalone with cluster deploy mode only:--driver-cores NUM Cores for driver (Default: 1).Spark standalone or Mesos with cluster deploy mode only:--supervise If given, restarts the driver on failure.--kill SUBMISSION_ID If given, kills the driver specified.--status SUBMISSION_ID If given, requests the status of the driver specified.Spark standalone and Mesos only:--total-executor-cores NUM Total cores for all executors.Spark standalone and YARN only:--executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode,or all available cores on the worker in standalone mode)YARN-only:--driver-cores NUM Number of cores used by the driver, only in cluster mode(Default: 1).--queue QUEUE_NAME The YARN queue to submit to (Default: "default").--num-executors NUM Number of executors to launch (Default: 2).--archives ARCHIVES Comma separated list of archives to be extracted into theworking directory of each executor.--principal PRINCIPAL Principal to be used to login to KDC, while running onsecure HDFS.--keytab KEYTAB The full path to the file that contains the keytab for theprincipal specified above. This keytab will be copied tothe node running the Application Master via the SecureDistributed Cache, for renewing the login tickets and thedelegation tokens periodically.
--master 由setMaster("local2")指定
--name 由setAppName("SparkApplicaiton")指定
--class 指定jar包
[beifeng@hadoop-senior spark-1.6.1-bin-2.5.0-cdh5.3.6]$ bin/spark-submit --class p1.com.ibeifeng.bigdata.senior.spark.SparkApp p1.jar...(65,32d99014d80e5b683dc87e7c93f7c422)(65,2FF3QB5Z1ZYMFTQKCM6DUCUDDZXX1NAX)(59,3697499e2a4bc361c29d8e0652408915)(59,9364b2b10e1397e4673d77a37eb16b6e)(55,78e20c225db1e478727d51d7f23f1381)(51,edf91bcfd29523b0ba65367807ba3585)(50,784aaaaa4d570e9fb9d448f45eba2617)(44,74c300ab78b78337fb9a7ef5a12462f5)(43,53701e01643c9939ce492e0f5a60eb27)(42,1.2.4)
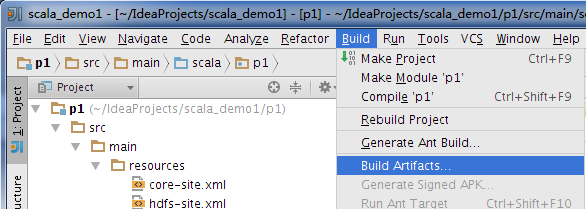
在集群上运行: 需要把 .setMaster("local2")注释,删除原jar包,并在idea点击Build=>Bulid Artifacts=>Rebuild,重新生成jar包,改jar包运行位置与提交运行位置一致
[beifeng@hadoop-senior spark-1.6.1-bin-2.5.0-cdh5.3.6]$ bin/spark-submit --class p1.com.ibeifeng.bigdata.senior.spark.SparkApp --master spark://hadoop-senior.ibeifeng.com:7077 --deploy-mode cluster /home/beifeng/IdeaProjects/idea_jars/p1.jarRunning Spark using the REST application submission protocol.16/08/08 20:30:53 INFO rest.RestSubmissionClient: Submitting a request to launch an application in spark://hadoop-senior.ibeifeng.com:7077.16/08/08 20:31:04 WARN rest.RestSubmissionClient: Unable to connect to server spark://hadoop-senior.ibeifeng.com:7077.Warning: Master endpoint spark://hadoop-senior.ibeifeng.com:7077 was not a REST server. Falling back to legacy submission gateway instead.16/08/08 20:31:04 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
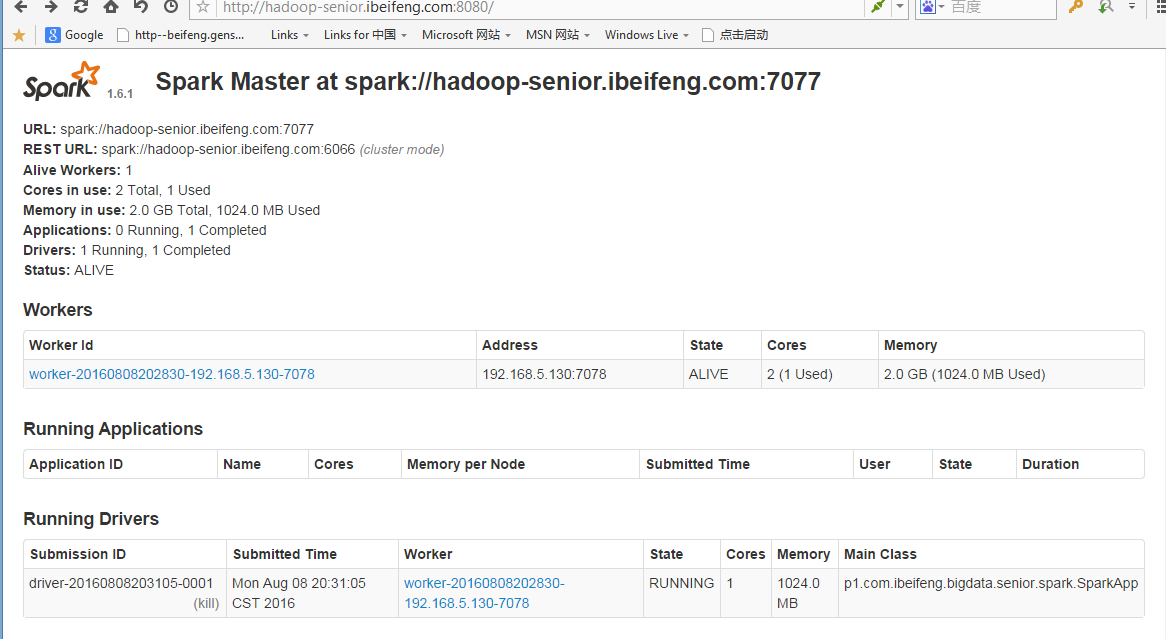
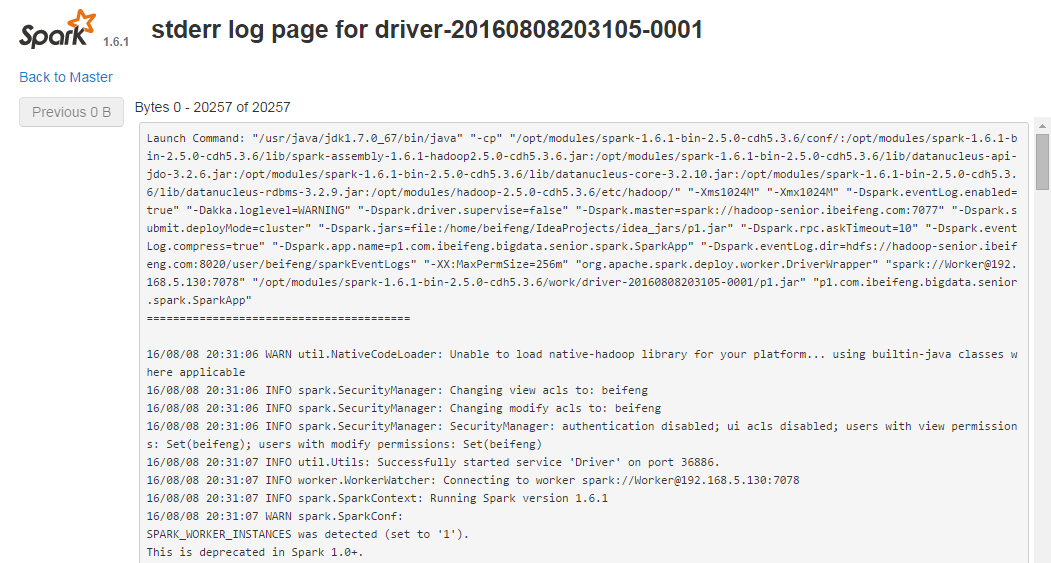
重载页面后
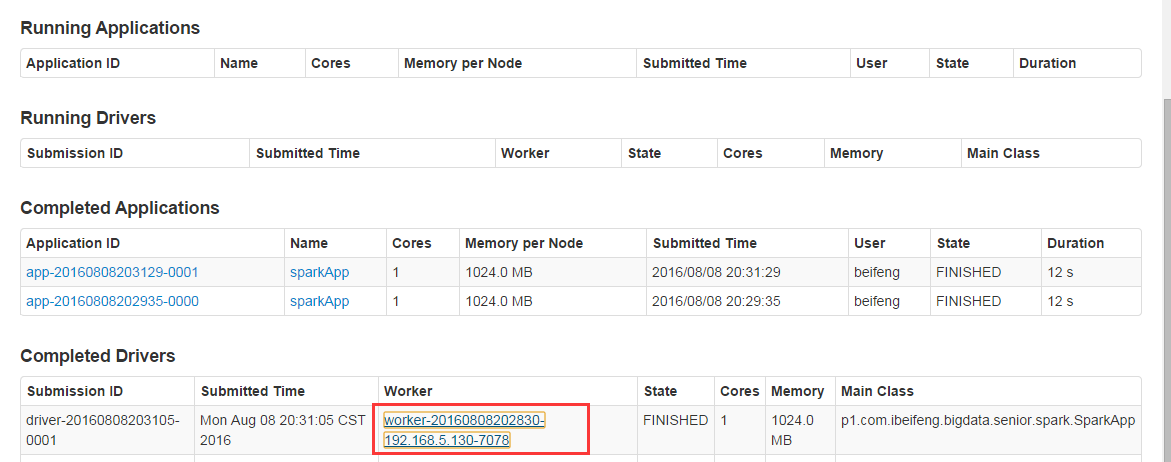
可以看到输出结果

以及日志信息,还可以再此查看已经加载的外部jar包