@Arslan6and6
2016-08-29T02:27:21.000000Z
字数 7477
阅读 964
【作业二十三】殷杰
第十四章、分布式数据库HBase基本使用
---HBase 功能配置及Shell基本使用
作业描述:
大数据(Hadoop)数据库 HBase 功能、表的设计、环境配置与 Shell 基本使用练习,最好与
RDBMS 数据中的数据库和表进行对比,以下几点要注意:
1) 企业中海量数据存储和实时查询的需求
2) HBase 功能,与 RDBMS 相比,优势在哪
3) HBase 服务组件的说明、配置部署启动
4) HBase Shell 中基本命令的使用
5) HBase 数据存储模型理解,结合实际操作
1 HBase 概述
HBase是一个数据库
--可提供给业务直接访问.适合于非结构化数据存储的数据库 --适合于非结构化数据存储的数据库 --适合海量数据(上亿条) --k-v,列式存储 (redis mogondb) --HBase技术可在廉价PC Server上搭建起大规模结构化存储集群 --存储数据和检索数据 --没有复制的数据类型,字节数组 --没有insert和update ==> put传统的RDBMS关系型数据库(例如SQL)存储一定量数据时进行数据检索没有问题,可当数据量上升到非常巨大规模的数据(TB或PB)级别时,传统的RDBMS已无法支撑,这时候就需要一种新型的数据库系统更好更快的处理这些数据。我们可以选择HBase。
2 HBase 服务组件
Master:
为HBase的主节点,用来协调客户端应用程序和RegionServer的关系,同时用来监控和记录元数据的变化和管理。
RegionServer:
是从节点,用region的形式处理实际的表。region是HBase表的基础单元组件,它存储了分布式表。所以HBase表和HBase集群利用Master和RegionServer来协同工作。
ZooKeeper:
是一个高性能、集中化、分布式应用程序协调服务,它为HBase提供了分布式同步和组服务。
在HBase中,它用来选举集群主节点Master,以便跟踪可用的在线服务器,同时维护集群的元数据。一般安装多个,用于提供Master的高可用性。
通常,Master和Hadoop的NameNode进程运行在同一台主机上,与DataNode通信以读写HDFS的数据。RegionServer跟Hadoop的DataNode运行在同一台主机上。
3 在分布式模式中配置 HBase
HBase安装目录下conf中:
* 启用并修改hbase-env.sh配置文件中的JAVA_HOME
* 启用并修改hbase-env.sh配置文件中的 export HBASE_MANAGES_ZK=false
* 根据官网举例添加 hbase-site.xml 配置,
http://hbase.apache.org/book.html#standalone_dist
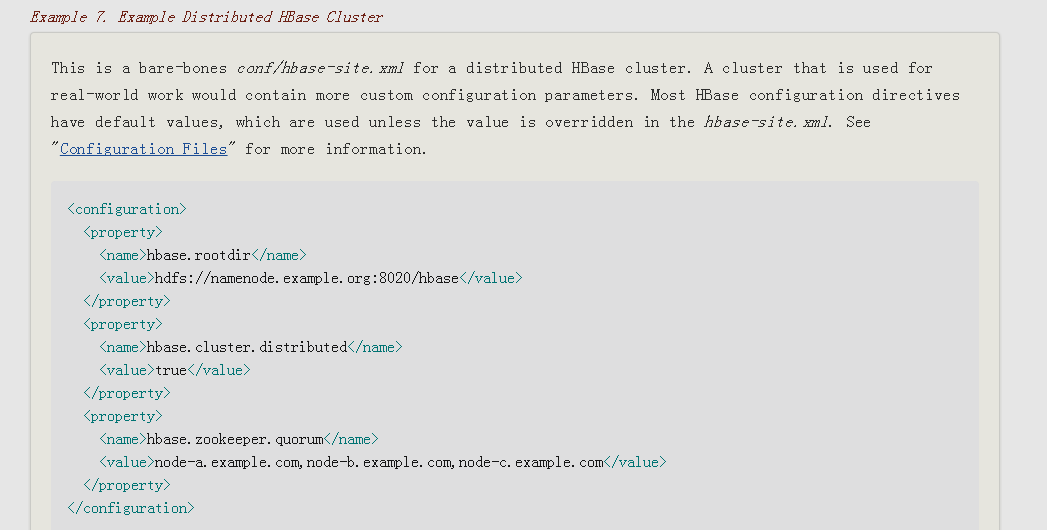
<configuration><property><name>hbase.rootdir</name><value>hdfs://hadoop-senior.ibeifeng.com:8020/hbase</value></property><property><name>hbase.cluster.distributed</name><value>true</value></property><property><name>hbase.zookeeper.quorum</name><value>hadoop-senior.ibeifeng.com</value></property></configuration>
修改regionservers文件,将内容修改为hostname本机名。
替换lib目录关于hadoop和zookeeper的jar包
pwd/opt/modules/hbase-0.98.6-hadoop2/librm -rf hadoop-*rm -rf zookeeper-3.4.6.jar
上传已准备好的jar包
hadoop-annotations-2.5.0.jar
hadoop-auth-2.5.0.jar
hadoop-common-2.5.0.jar
hadoop-hdfs-2.5.0.jar
hadoop-mapreduce-client-app-2.5.0.jar
hadoop-mapreduce-client-common-2.5.0.jar
hadoop-mapreduce-client-core-2.5.0.jar
hadoop-mapreduce-client-jobclient-2.5.0.jar
hadoop-mapreduce-client-shuffle-2.5.0.jar
hadoop-yarn-api-2.5.0.jar
hadoop-yarn-client-2.5.0.jar
hadoop-yarn-common-2.5.0.jar
hadoop-yarn-server-common-2.5.0.jar
hadoop-yarn-server-nodemanager-2.5.0.jar
zookeeper-3.4.5.jar
*启动Hadoop及zookeeper 服务后在 HBase 安装目录启动 HBase,命令为:
bin/start-hbase.sh
也可以按照角色启动
bin/hbase-daemon.sh start master
bin/hbase-daemon.sh start regionserver
jps3081 ResourceManager3178 NodeManager2663 NameNode4830 Jps3649 QuorumPeerMain4617 HRegionServer3560 JobHistoryServer2759 DataNode4518 HMaster2942 SecondaryNameNode
4 HBase Shell 中基本命令的使用
连接HBase 安装目录下
bin/hbase shell
创建一个表格
使用create命令来创建一个新的表格,你必须指明表名和列族名。
【注】可用help+’命令名’查询该命令的用法。例如:help ‘create’
语法格式为:
create , {NAME => , VERSIONS => }
create ‘表名’,’列族名’
例题:create 'user','info'查看有哪些表
hbase(main)> list
describe命令
利用describe显示表格描述信息
语法格式如下:describe ‘表名’
例题:describe ‘user’插入数据
使用put命令插入数据
语法如下:put '表名','行键','列族:列名','值'
例题如下:为表格user插入以下数据如表
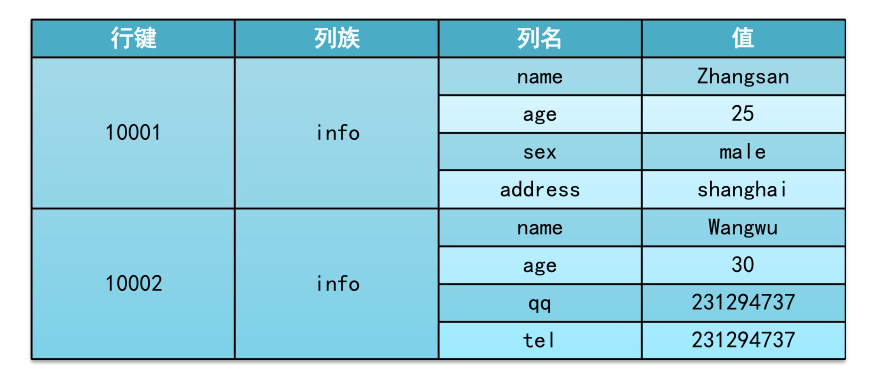
hbase(main):002:0> create 'user','info'0 row(s) in 3.8660 secondshbase(main):003:0> listTABLEuser1 row(s) in 0.0510 secondshbase(main):004:0> put 'user','10001','info:name','zhangsan'0 row(s) in 0.3190 secondshbase(main):005:0> put 'user','10001','info:age','25'0 row(s) in 0.0470 secondshbase(main):006:0> put 'user','10001','info:sex','male'0 row(s) in 0.0250 secondshbase(main):007:0> put 'user','10001','info:address','shanghai'0 row(s) in 0.0090 secondshbase(main):009:0> put 'user','10002','info:name','wanwu'0 row(s) in 0.0460 secondshbase(main):010:0> put 'user','10002','info:age','30'0 row(s) in 0.0150 secondshbase(main):011:0> put 'user','10002','info:qq','231294737'0 row(s) in 0.0240 secondshbase(main):012:0> put 'user','10002','info:tel','231294737'0 row(s) in 0.0090 seconds
- HBase中数据查询方式
① 依据rowkey使用get命令查询
查询某行
语法格式:get ‘表名’,行键名’,例:
hbase(main):008:0> get 'user','10001'
COLUMN CELL
info:address timestamp=1465738977261, value=shanghai
info:age timestamp=1465738895275, value=25
info:name timestamp=1465738817359, value=zhangsan
info:sex timestamp=1465738927672, value=male
4 row(s) in 0.0530 seconds查询某行某列
语法格式:get ‘表名’,行键名’,‘列族:列名’,例:
hbase(main):013:0> get 'user','10001','info:age'
COLUMN CELL
info:age timestamp=1465738895275, value=25
1 row(s) in 0.1100 seconds
hbase(main):014:0> get 'user','10001','info:address'
COLUMN CELL
info:address timestamp=1465738977261, value=shanghai
1 row(s) in 0.0360 seconds② 使用scan命令全表查询,
语法格式如下:scan '表名',例:
hbase(main):015:0> scan 'user'
ROW COLUMN+CELL
10001 column=info:address, timestamp=1465738977261, value=shanghai
10001 column=info:age, timestamp=1465738895275, value=25
10001 column=info:name, timestamp=1465738817359, value=zhangsan
10001 column=info:sex, timestamp=1465738927672, value=male
10002 column=info:age, timestamp=1465739729967, value=30
10002 column=info:name, timestamp=1465739699945, value=wanwu
10002 column=info:qq, timestamp=1465739780191, value=231294737
10002 column=info:tel, timestamp=1465739802184, value=231294737
2 row(s) in 0.1160 seconds③ 使用scan命令查询表格中某范围数据
查询列范围
语法格式如下:scan ‘表名’,{COLUMN => [‘列族:列名’,’列族:列名’]}
在表中再插入一个用户信息,命令如下:put 'user','10003','info:name','mutouliu'
hbase(main):011:0> scan 'user',{COLUMNS=>['info:name','info:age']}
ROW COLUMN+CELL
10001 column=info:age, timestamp=1465738895275, value=25
10001 column=info:name, timestamp=1465738817359, value=zhangsan
10002 column=info:age, timestamp=1465739729967, value=30
10002 column=info:name, timestamp=1465739699945, value=wanwu
10003 column=info:name, timestamp=1465742476875, value=mutouliu
3 row(s) in 0.0510 seconds查询行范围,结果包头不包尾
语法格式如下:scan ‘表名’,{STARTROW =>'10002'},例:
hbase(main):008:0> scan 'user',{STARTROW=>'10001',STOPROW=>'10003'}
ROW COLUMN+CELL
10001 column=info:address, timestamp=1465738977261, value=shanghai
10001 column=info:age, timestamp=1465738895275, value=25
10001 column=info:name, timestamp=1465738817359, value=zhangsan
10001 column=info:sex, timestamp=1465738927672, value=male
10002 column=info:age, timestamp=1465739729967, value=30
10002 column=info:name, timestamp=1465739699945, value=wanwu
10002 column=info:qq, timestamp=1465739780191, value=231294737
10002 column=info:tel, timestamp=1465739802184, value=231294737
2 row(s) in 0.0580 seconds④ 查询表中的数据行数
语法:count , {INTERVAL => intervalNum, CACHE => cacheNum}
INTERVAL 设置多少行显示一次及对应的 rowkey,默认 1000;CACHE 每
次去取的缓存区大小,默认是 10,调整该参数可提高查询速度
例如,查询表 t1 中的行数,每 100 条显示一次,缓存区为 500
hbase(main)> count 't1', {INTERVAL => 100, CACHE => 500}
- 删除数据
① delete命令:删除表中某行键下的某列信息,语法格式:delete ‘表名’,’行键’,’列族:列名’,例:
hbase(main):016:0> delete 'user','10001','info:address'② deleteall命令:删除表中某行键下的所有列信息,语法格式:deleteall ‘表名’,’行键’,例:
hbase(main):018:0> deleteall 'user','10002'③删除表
分两步:首先 disable,然后 drop。例如:
hbase(main)> disable 't1'
hbase(main)> drop 't1'④清空表内数据
truncate
其具体过程是:disable table -> drop table -> create table
例如:删除表 t1 的所有数据
hbase(main)> truncate 't1'
- 权限管理
1)分配权限
语法 : grant <user> <permissions> <table> <column family><column qualifier> 参数后面用逗号分隔权限用五个字母表示: "RWXCA".
2)查看权限
语法:user_permission <table>例如,查看表 t1 的权限列表hbase(main)> user_permission 't1'
3)收回权限
与分配权限类似,语法:revoke <user> <table> <column family><column qualifier>例如,收回 test 用户在表 t1 上的权限hbase(main)> revoke 'test','t1'
5 HBase 数据存储模型
HBase不是以关系设计为中心,它是根据用户需求更灵活的开放设计。它提供了在行键上的单一索引,这在关系世界里称为主键。我们可以通过把行划分为列族和列来避免大的读取和写入操作,并且这种方式支持水平切分和垂直切分。
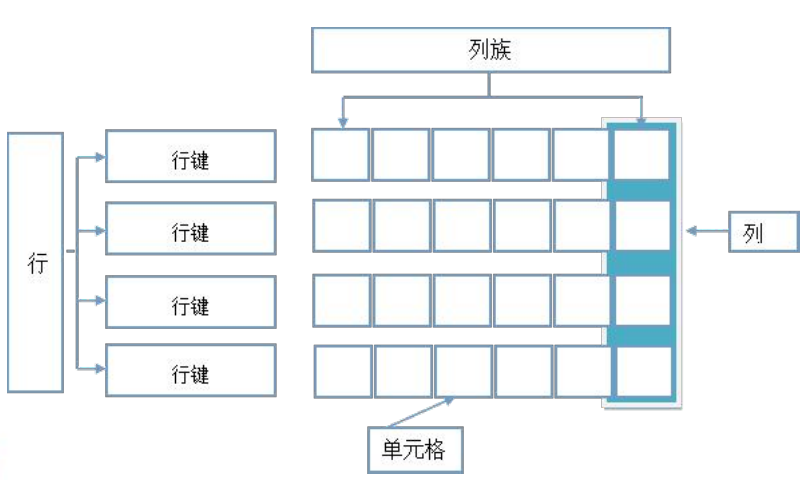
一个HBase表由以下几部分组成:
5.1 HBase的数据类型
- HBase中没有花哨的数据类型,它所有都是字节数组。它是一种字节进字节出的数据库,其特征在于,当插入一个值时,HBase隐式地通过序列号框架将数据转换成字节数组,然后存储进单元格,或者给出字节数组。
- 当添加或者获取数值时,它隐式地转换成等价的数据展示出来。
- HBase的单元格只能容纳字节数组。任何可以转换成字节的数据都可以存储在HBase中。
- 可以存储10-15MB的值到HBase的单元格中,但如果值太大,可以将文件存储到HDFS中,然后在HBase中存储文件的路径。
- 不建议将一个巨大的文件或值转换成字节数组存储在HBase中;但是HDFS用到的主机文件和文件元数据可以存储到HBase中。
5.2 HBase数据模型术语
- 行键
这是HBase表中每个记录的唯一键,无论选择什么类型数据作为行健,它在内部、磁盘或内存里,都将转换为 字节数组进行存储。
表中的每条数据有唯一的标识符,即rowkey,类似于关系型数据库的主键。- 列簇
一张HBase表由表的不同列集合在一起。将相同功能或类型的列分类组合在一起,
这样做的好处是可以更快的分开存储在HBase磁盘上的列族中检索出所需的列。- 列
列属于某一个column family列族。- 版本
HBase能够为一个单元格元组(行、列族和列)保存多个值,每个单元格被称为一个记录的版本。版本制定为基于时间戳的长整形。默认情况下,HBase保留3个版本的记录。当然,我们也可以改变保留版本的数量,我们也可以通过指定来获取某个特定的版本。- 时间戳
对于每个插入的数据,当前的时间戳与值是相关的,它表示了数值插入到表中的时间。- 单元格
最小或基本的存储单元,在内部是一个列的实际值存储。故插单元格数据时必须包含 rowkey+columnfamily(列族名)+columnname(列名)+timestamp:value。