@Arslan6and6
2016-05-04T14:46:00.000000Z
字数 4760
阅读 661
【作业八】殷杰
第五章、高级Hadoop2.x(一)
---Hadoop 2.x分布式集群部署
作业描述:
依据上课讲解的【Hadoop 2.x 分布式环境部署】步骤,自己在机器中完成,将核心步骤通过截
图软件(比如 QQ 截图)截取图片,粘贴到文档中。以下几点必须在截图中体现:
1)集群机器配置(内存、硬盘、CPU 核),合理规划 Hadoop 服务组件部署的几点(表格规划、形象生动)。
2)对克隆虚拟机进行修改网卡名称和配置IP地址与主机名,配置集群中三台机器的IP地址和主机名称的映射。
3)以【Hadoop 2.x 伪分布式部署】为模板,理解各个服务组件部署节点的配置,配置部署安装集群。
4)启动 HDFS、YARN 以后,对集群进行基本测试,如上传文件,运行 WordCount 程序等。
1)集群机器配置(内存、硬盘、CPU 核),合理规划 Hadoop 服务组件部署的几点(表格规划、形象生动)。
集群硬件规划:
按需求:
作业量(测试) --基准测试:测IO、测磁盘内存 --基本测试

按角色:
namenode建议使用raid1/raid5
datanode不建议使用raid。
arid1用作镜像备份,datanode已有副本,再做备份多余,影响效率。
arid0起加速作用,但是受最慢磁盘影响,整个集群会降低读写效率。且单个磁盘损坏,整个raid0失效。
2)对克隆虚拟机进行修改网卡名称和配置IP地址与主机名,配置集群中三台机器的IP地址和主机名称的映射。
(a)用root用户在每台服务器上固定主机名
vi /etc/sysconfig/network
第一台服务器:HOSTNAME=hadoop-senior.ibeifeng.com
第二台服务器:HOSTNAME=hadoop-senior02.ibeifeng.com
第三台服务器:HOSTNAME=hadoop-senior03.ibeifeng.com
(b)用root用户添加hosts文件
在每台服务器上 # vi /etc/hosts
192.168.5.130 hadoop-senior.ibeifeng.com
192.168.5.131 hadoop-senior02.ibeifeng.com
192.168.5.132 hadoop-senior03.ibeifeng.com
(c)用root用户固定各台服务器IP和DNS地址
方式1: 在console窗口修改 命令setup
方式2:vi /etc/sysconfig/network-scripts/ifcfg-eth0
BOOTPROTO=none
HWADDR=00:0c:29:93:75:7a
IPADDR=192.168.5.130
NETMASK=255.255.255.0
DNS2=8.8.8.8
GATEWAY=192.168.5.2
DNS1=202.96.209.5
注意:如是克隆虚拟机,HWADDR行应该删除。手动安装服务器不必修改。
修改完毕,重启网络。命令:service network restart
3)以【Hadoop 2.x 伪分布式部署】为模板,理解各个服务组件部署节点的配置,配置部署安装集群。
在hadoop-senior02 hadoop-senior03上搭建Hadoop环境:
$ su - root
# mkdir /opt/modules/
# chown -R beifeng:beifeng /opt/modules/
// 配置JDK环境
# vi /etc/profile
JAVA_HOME=/opt/modules/jdk1.7.0_67
export PATH=$PATH:$JAVA_HOME/bin
# exit 退出root用户
把伪分布环境下jdk复制到第二台、第三台服务器上
$ scp -r jdk1.7.0_67/ beifeng@hadoop-senior02.ibeifeng.com:/opt/modules/
$ scp -r jdk1.7.0_67/ beifeng@hadoop-senior03.ibeifeng.com:/opt/modules/
在hadoop-senior第一台服务器上:
core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml
$ rm -rf data/ --删除之前的data/目录
======================core-site.xml=====================
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-senior.ibeifeng.com:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/beifeng/hadoop_tmp</value>
<description>A base for other temporary directories.</description>
</property>
</configuration>
======================core-site.xml=====================
======================hdfs-site.xml=====================
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop-senior.ibeifeng.com:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-senior03.ibeifeng.com:50090</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>true</value>
</property>
</configuration>
======================hdfs-site.xml============
======================slaves===================
hadoop-senior.ibeifeng.com
hadoop-senior02.ibeifeng.com
hadoop-senior03.ibeifeng.com
======================slaves===================
======================yarn-site.xml============
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-senior02.ibeifeng.com</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
</configuration>
======================yarn-site.xml=====================
======================mapred-site.xml===================
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-senior03.ibeifeng.com:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-senior03.ibeifeng.com:19888</value>
</property>
</configuration>
======================mapred-site.xml===================
复制Hadoop安装目录到第二台、第三台服务器
$scp -r hadoop-2.5.0/ beifeng@hadoop-senior02.ibeifeng.com:/opt/modules/ ;scp -r hadoop-2.5.0/ beifeng@hadoop-senior03.ibeifeng.com:/opt/modules/
查看新装Java服务器是否有多余冲突安装包 rpm -qa|grep java
如有多余安装包则切换root用户使用命令删除 # rpm -e --nodeps
用普通用户刷新配置 $source /etc/profile
验证Java安装完成 java -version
第一次启动Hadoop前:
重建hadoop.tmp.dir。mkdir /home/beifeng/hadoop_tmp
在第一台服务器(namenode节点服务器)格式化namenode
$ bin/hdfs namenode format
在第一台服务器启动HDFS服务
$ sbin/start-dfs.sh
在第二台服务器启动YARN服务
$ sbin/start-yarn.sh
在第二台服务器启动history服务
$ sbin/mr-jobhistory-daemon.sh start historyserver
全部启动后,在各服务器查看服务进程。



与预先安排服务器角色一致。Hadoop2.5.0分布式环境部署完毕。

4)启动 HDFS、YARN 以后,对集群进行基本测试,如上传文件,运行 WordCount 程序等。
在namenode服务器的HDFS中创建输入文件目录 bin/hdfs dfs -mkdir /input
向HDFS中/input目录上传文件并查看 bin/hdfs dfs -put sort.txt /input
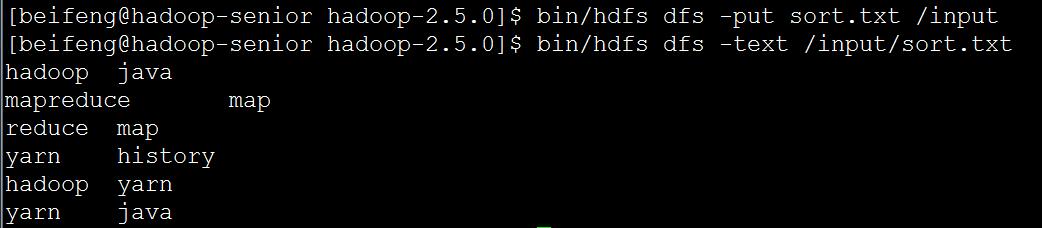
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /input/sort.txt /output
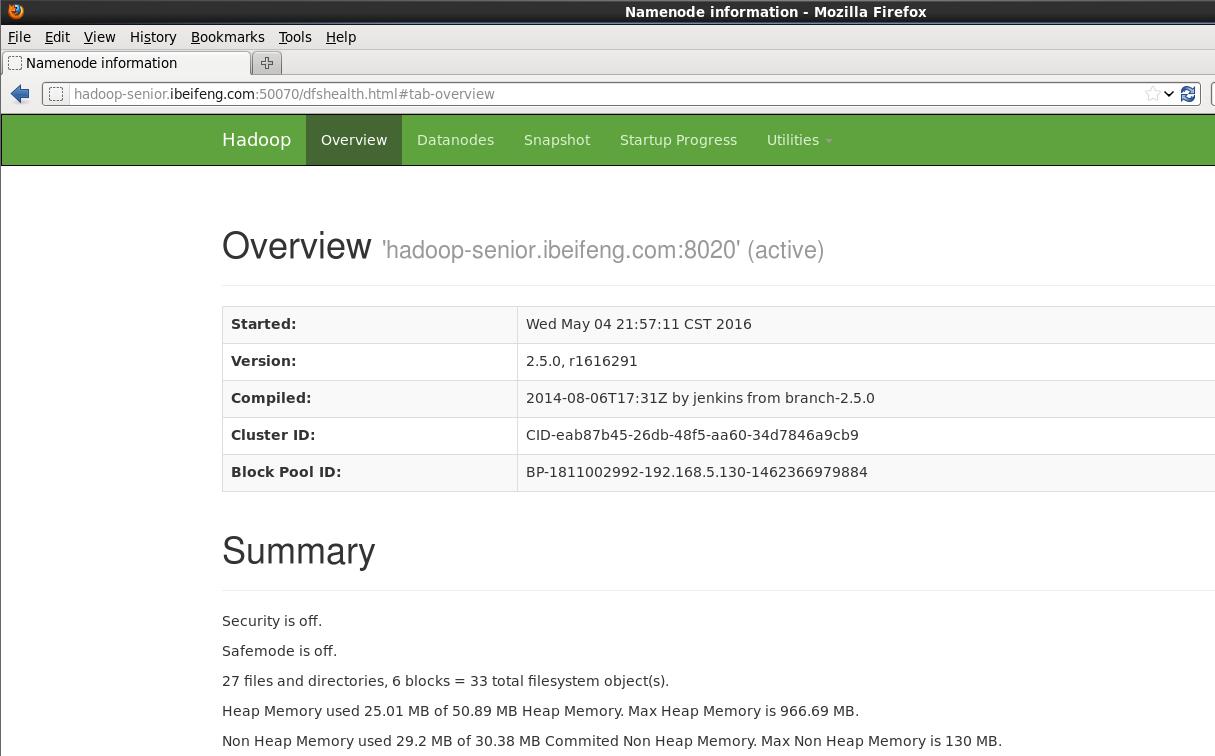
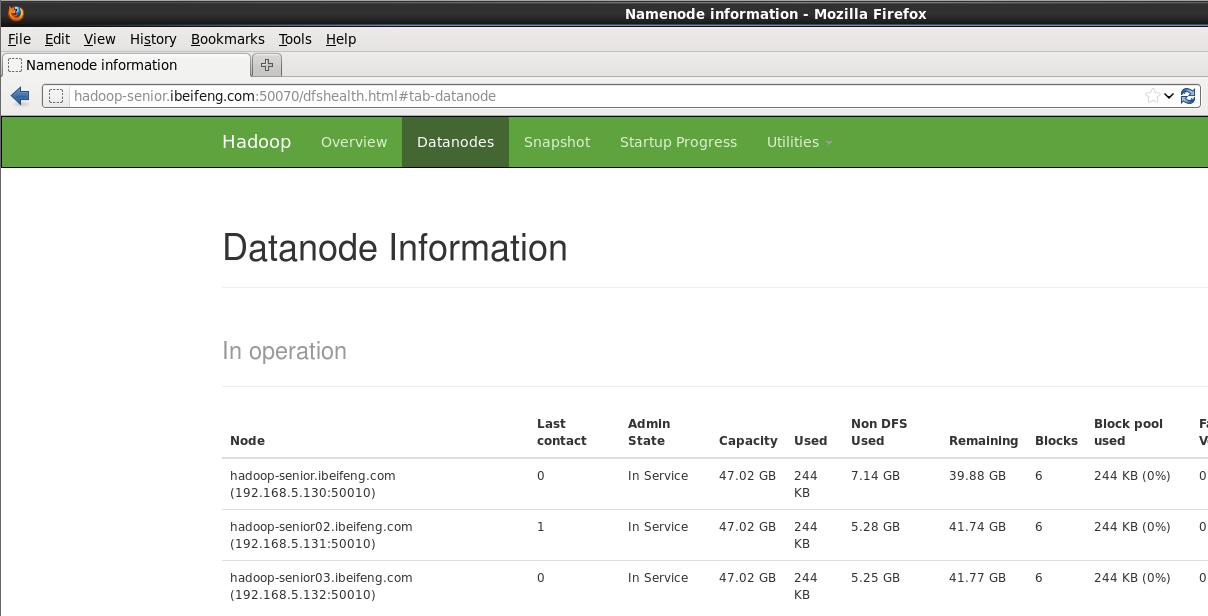
查看网页
http://hadoop-senior.ibeifeng.com:50070/
http://hadoop-senior02.ibeifeng.com:8088/
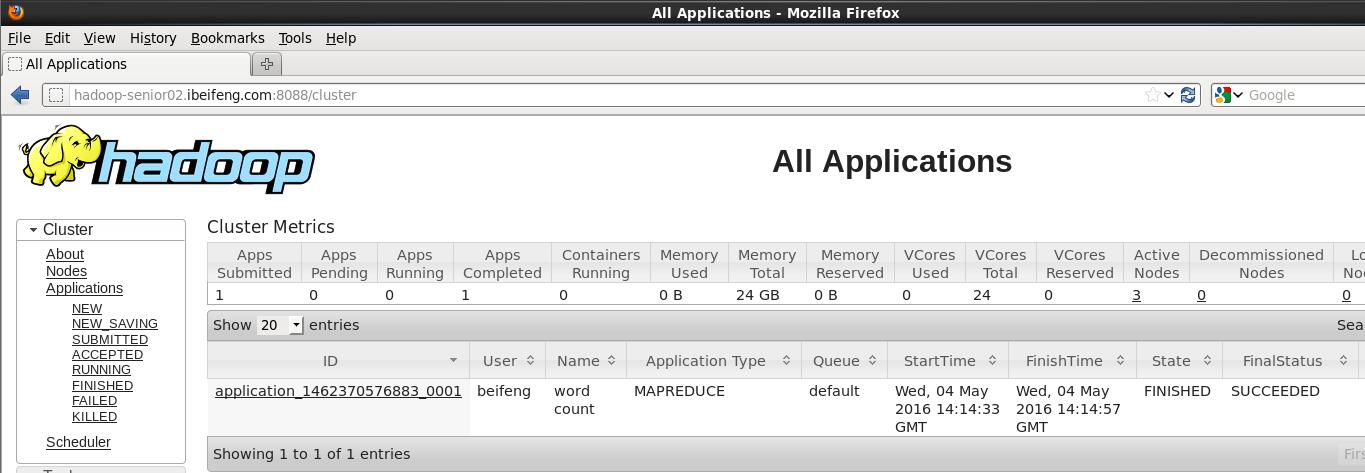
http://hadoop-senior03.ibeifeng.com:19888/
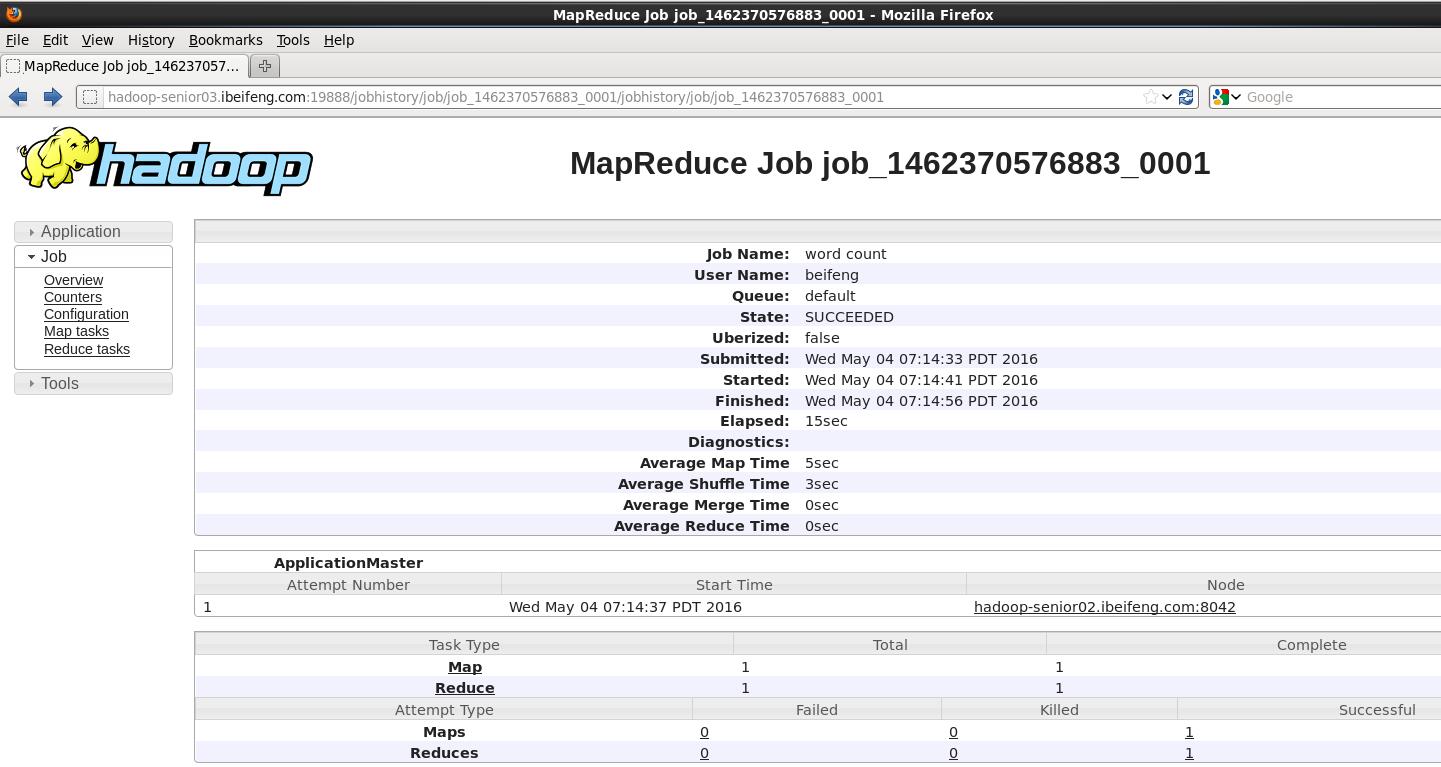
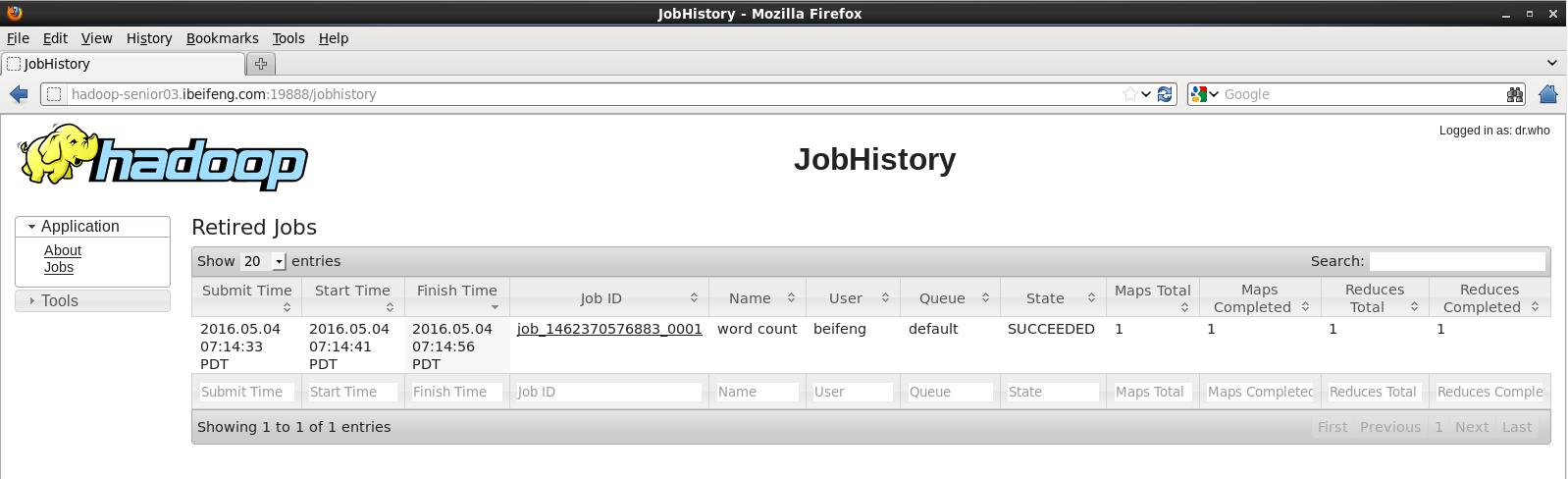
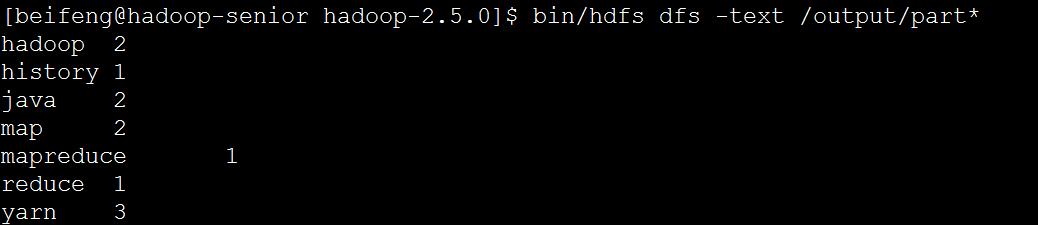
查看程序运行结果
bin/hdfs dfs -text /output/part*