@Arslan6and6
2016-10-10T06:33:38.000000Z
字数 4782
阅读 1395
JVM调优
系统调优
内存:
CDH HADOOP JVM默认配置
[beifeng@hadoop-senior hadoop-2.5.0-cdh5.3.6]$ sbin/hadoop-daemon.sh start namenodestarting namenode, logging to /opt/modules/hadoop-2.5.0-cdh5.3.6/logs/hadoop-beifeng-namenode-hadoop-senior.ibeifeng.com.out[beifeng@hadoop-senior hadoop-2.5.0-cdh5.3.6]$ ps -ef | grep javabeifeng 2688 1 3 21:53 pts/0 00:00:06 /usr/java/jdk1.7.0_67/bin/java -Dproc_namenode -Xmx1000m -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=/opt/modules/hadoop-2.5.0-cdh5.3.6/logs -Dhadoop.log.file=hadoop.log -Dhadoop.home.dir=/opt/modules/hadoop-2.5.0-cdh5.3.6 -Dhadoop.id.str=beifeng -Dhadoop.root.logger=INFO,console -Djava.library.path=/opt/modules/hadoop-2.5.0-cdh5.3.6/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=/opt/modules/hadoop-2.5.0-cdh5.3.6/logs -Dhadoop.log.file=hadoop-beifeng-namenode-hadoop-senior.ibeifeng.com.log -Dhadoop.home.dir=/opt/modules/hadoop-2.5.0-cdh5.3.6 -Dhadoop.id.str=beifeng -Dhadoop.root.logger=INFO,RFA -Djava.library.path=/opt/modules/hadoop-2.5.0-cdh5.3.6/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS org.apache.hadoop.hdfs.server.namenode.NameNodebeifeng 2786 2442 0 21:55 pts/0 00:00:00 grep java
可以在 hadoop-env.sh 中修改配置
# The maximum amount of heap to use, in MB. Default is 1000.#export HADOOP_HEAPSIZE=#export HADOOP_NAMENODE_INIT_HEAPSIZE=""...
-Xmx:最大堆大小
-Xms:初始堆大小
使用 CM 安装的CDH HADOOP
/usr/java/jdk1.7.0_67-cloudera/bin/java -Dproc_namenode -Xmx1000m -Dhdfs.audit.logger=INFO,RFAAUDIT -Dsecurity.audit.logger=INFO,RFAS -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=/var/log/hadoop-hdfs -Dhadoop.log.file=hadoop-cmf-hdfs-NAMENODE-bigdata-cdh02.ibeifeng.com.log.out -Dhadoop.home.dir=/opt/cloudera/parcels/CDH-5.3.6-1.cdh5.3.6.p0.11/lib/hadoop -Dhadoop.id.str=hdfs -Dhadoop.root.logger=INFO,RFA -Djava.library.path=/opt/cloudera/parcels/CDH-5.3.6-1.cdh5.3.6.p0.11/lib/hadoop/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Xms1073741824 -Xmx1073741824 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:-CMSConcurrentMTEnabled -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:OnOutOfMemoryError=/usr/lib64/cmf/service/common/killparent.sh -Dhadoop.security.logger=INFO,RFAS org.apache.hadoop.hdfs.server.namenode.NameNode
其中:
//初始堆大小 与 最大堆大小-Xms1073741824 -Xmx1073741824//GC 垃圾回收机制-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:-CMSConcurrentMTEnabled -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:OnOutOfMemoryError=/usr/lib64/cmf/service/common/killparent.sh
GC垃圾回收策略配置位置:
可以在 CM 中修改GC回收机制: 配置 ——> 类别(选择服务)如:NameNode Default Group ——> 高级 ——> NameNode的Java配置选项
JVM体系结构
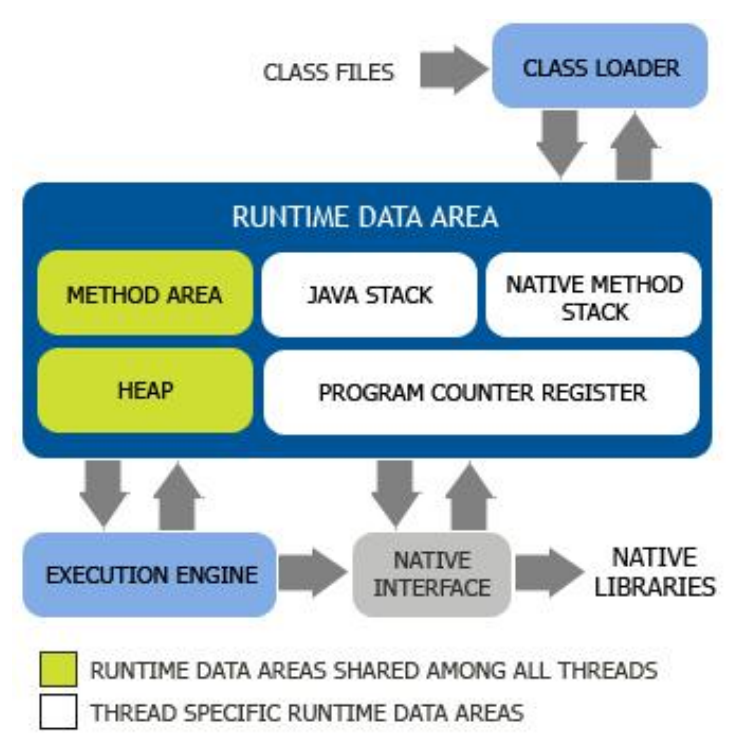
类加载(Class Loader)子系统
执行引擎(Execution Engine)子系统
本地接口(Native Interface)组件
运行数据域(Running Data Area)组件
——Java Stack(栈)
——Java Heap(堆)
——Method Area(方法区)
——PC Register(程序计数器)
——Native Method Stack(本地方法栈)
方法区和堆由所有线程共享,其他区域都是
线程私有的
Java Stack(栈)
栈也叫栈内存,是Java程序的运行区,是在线程创建时创建,它的生命期是跟随
线程的生命期,线程结束栈内存也就释放,对于栈来说不存在垃圾回收问题,只
要线程一结束,该栈就Over。
Java Heap(堆)
** 一个 JVM 实例只存在一个堆内存,堆内存的大小是可以调节的。
** 虚拟机中用于存放对象与数组实例的地方,垃圾回收的主要区域就是这里(还可
能有方法区)。
** 类加载器读取了类文件后,需要把类、方法、常变量放到堆内存中,以方便执行
器执行,堆内存分为三部分:
* Permanent Space 永久存储区
* Young Generation Space 新生区(New Generation)
* Tenure Generation Space 养老区(Old Generation)
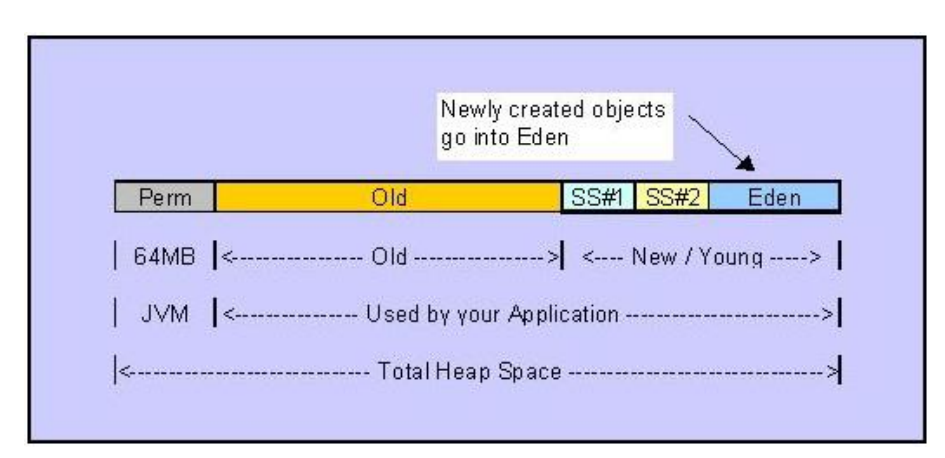
New Generation
又称为新生代,程序中新建的对象都将分配到新生代中,新生代又由Eden Space和两块Survivor Space构
成,可通过-Xmn参数来指定其大小,Eden Space的大小和两块Survivor Space的大小比例默认为8,即当New
Generation的大小为10M时,Eden Space的大小为8M,两块Survivor Space各占1M,这个比例可通过-
XX:SurvivorRatio来指定。Old Generation
又称为旧生代,用于存放程序中经过几次垃圾回收还存活的对象,例如缓存的对象等,旧生代所占用的内存大
小即为-Xmx指定的大小减去-Xmn指定的大小。- Permanent Space
一个常驻内存区域,用于存放 JDK 自身所携带的 Class, Interface 的元数据,就是说它存储的是运行环境
必须的类信息,被装载进此区域的数据是不会被垃圾回收器回收掉的,关闭 JVM 才会释放此区域所占用的内存。
-XX:NewSize=n:设置新生代大小。
-XX:NewRatio:设置新生代和年老代的比值。如为3,表示新生代与年老代的比值为1:3,新生代占整个新生代年老代和的1/4。
-XX:SurvivorRatio=n:新生代中Eden区与两个Survivor区的比值。注意Survivor区有2个。如为3,表示Eden:Survivor=3:2,一个Survivor区占整个新生代的1/5。
-XX:MaxPermSize=n:设置持久代大小。
———————————————————————分代垃圾回收—————————————————————
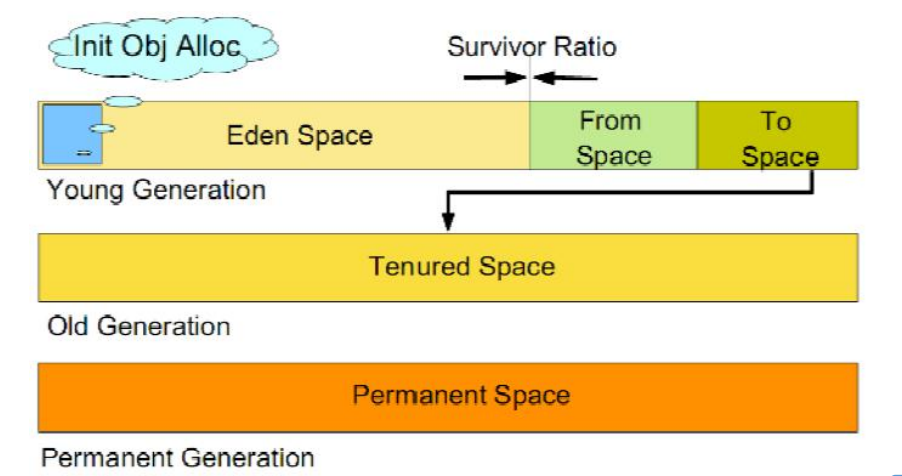
* 大部分新生成的对象会被放到 Eden 区,当该区满的时候进行垃圾回收,把仍然需要的对象随机放到 Survivor 区中的一个,当这个 Survivor 区满的时候,再把仍然需要的对象放进另一个 Survivor 区。另一个 Survivor 满的时候就把对象放进 Tenure Generation Space 养老区。
* 需要注意, Survivor 的两个区是对称的,没先后关系,所以同一个区中可能同时存在从 Eden 复制过来对象,和从前一个 Survivor 复制过来的对象,而复制到年老区的只有从第一个Survivor 去过来的对象。而且, Survivor 区总有一个是空的。同时,根据程序需要, Survivor 区是可以配置为多个的(多于两个), 这样可以增加对象在年轻代中的存在时间,减少被放到年老代的可能。
收集器设置
-XX:+UseSerialGc: 设置串行收集器
-XX:+UseParallelGC: 设置并行收集器
-XX:+UseParalledlOldGC:设置年老代并行收集器
-XX:+UseConcMarkSweepGC: 设置并发收集器
-XX:+UseParNewGC: 设置新生代并行收集器
-XX:+UseConcMarkSweepGC: 设置并发收集器
如何配置spark JVM GC
SPARK_DAEMON_JAVA_OPTS="-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:-CMSConcurrentMTEnabled -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled"
