@Arslan6and6
2016-06-14T03:53:29.000000Z
字数 4422
阅读 778
【作业十七】殷杰
第八章、大数据协作框架之Sqoop
---sqoop导入导出
作业描述:
依据课堂讲解,练习使用 sqoop 操作 mysql 与 HDFS、Hive 的数据导入导出,整理文档,要求
如下:
(1) SQOOP 功能与架构概述;
(2) 使用 SQOOP 把关系型数据库 mysql 数据导入 Hive 表;
(3) 使用 SQOOP 把关系型数据库 mysql 数据导入 HDFS;
(4) 使用 SQOOP 把 Hive 表数据导入关系型数据库 mysql;
(1) SQOOP 功能与架构概述;
SQOOP 功能:
连接传统关系型数据库和Hadoop的桥梁
——把关系型数据库的数据导入到Hadoop与其相关的系统(HBase和Hive)中
——把数据从Hadoop系统里抽取并导出到关系型数据库里
利用MapReduce加快数据传输速度,批处理方式进行数据传输
Sqoop 架构主要由三个部分组成:Sqoop client、HDFS/HBase/Hive、Database。下面我们来看一下 Sqoop 的架构图。
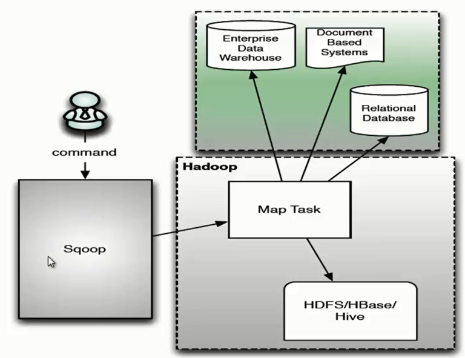
用户向 Sqoop 发起一个命令之后,这个命令会转换为一个基于 Map Task 的 MapReduce 作业。Map Task 会访问数据库的元数据信息,通过并行的 Map Task 将数据库的数据读取出来,然后导入 Hadoop 中。 当然也可以将 Hadoop 中的数据,导入传统的关系型数据库中。它的核心思想就是通过基于 Map Task (只有 map)的 MapReduce 作业,实现数据的并发拷贝和传输,这样可以大大提高效率。
(2) 使用 SQOOP 把关系型数据库 mysql 数据导入 Hive 表;
在MySQL生成数据
mysql> CREATE TABLE `my_user` (-> `id` tinyint(4) NOT NULL AUTO_INCREMENT,-> `account` varchar(255) DEFAULT NULL,-> `passwd` varchar(255) DEFAULT NULL,-> PRIMARY KEY (`id`)-> );mysql> INSERT INTO `my_user` VALUES ('1', 'admin', 'admin');mysql> INSERT INTO `my_user` VALUES ('2', 'pu', '12345');mysql> INSERT INTO `my_user` VALUES ('3', 'system', 'system');mysql> INSERT INTO `my_user` VALUES ('4', 'zxh', 'zxh');mysql> INSERT INTO `my_user` VALUES ('5', 'test', 'test');mysql> INSERT INTO `my_user` VALUES ('6', 'pudong', 'pudong');mysql> INSERT INTO `my_user` VALUES ('7', 'qiqi', 'qiqi');mysql> select * from my_user;+----+---------+--------+| id | account | passwd |+----+---------+--------+| 1 | admin | admin || 2 | pu | 12345 || 3 | system | system || 4 | zxh | zxh || 5 | test | test || 6 | pudong | pudong || 7 | qiqi | qiqi |+----+---------+--------+
步骤一:在hive中建立数据库,与MySQL保持同名
步骤二:将MySQL数据导入hive
语法: import导入数据
--connect jdbc:关系型数据库名称://授权连接地址:连接端口/导入数据库名称
--username 连接关系型数据库用户名称
--password 连接密码
--table 导入表名称
--delete-target-dir 导入文件存在则删除
--hive-import 指定导入Hive
--hive-database 导入Hive使用的数据库名称
--hive-table 导入Hive使用的表名称
--fields-terminated-by '分隔符'
--as-parquetfile 指定导入文件格式为parquet文件
--compress 导入Hive时启动压缩
指定压缩设置:
--compresion-codec org.apache.hadoop.io.compress.DefaultCodec
--compresion-codec org.apache.hadoop.io.compress.SnappyCodec
bin/sqoop import \--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/db_0521 \--username root \--password 123 \--table my_user \--delete-target-dir \--hive-import \--hive-database db_0521 \--hive-table mysql2hive2 \--fields-terminated-by '\t'
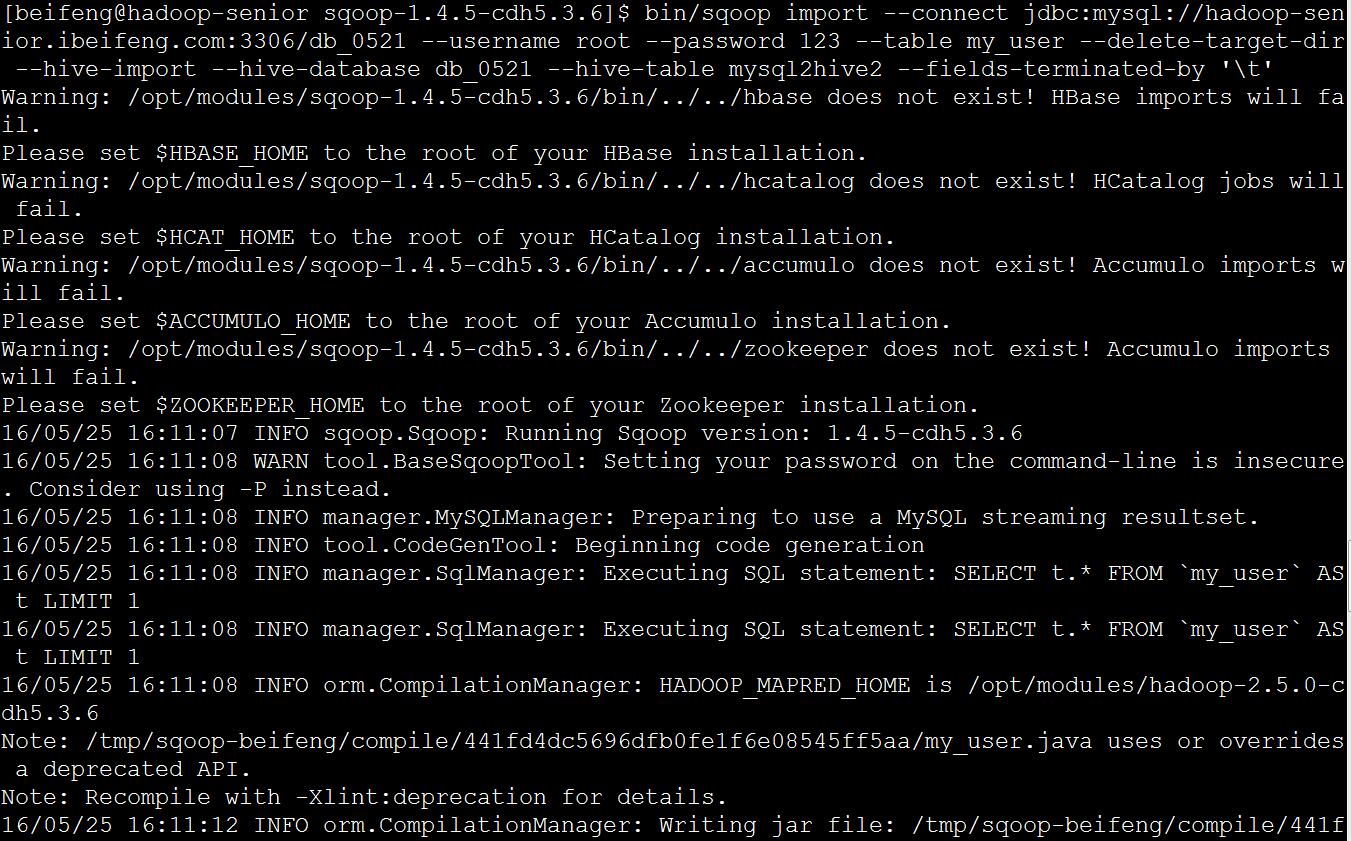
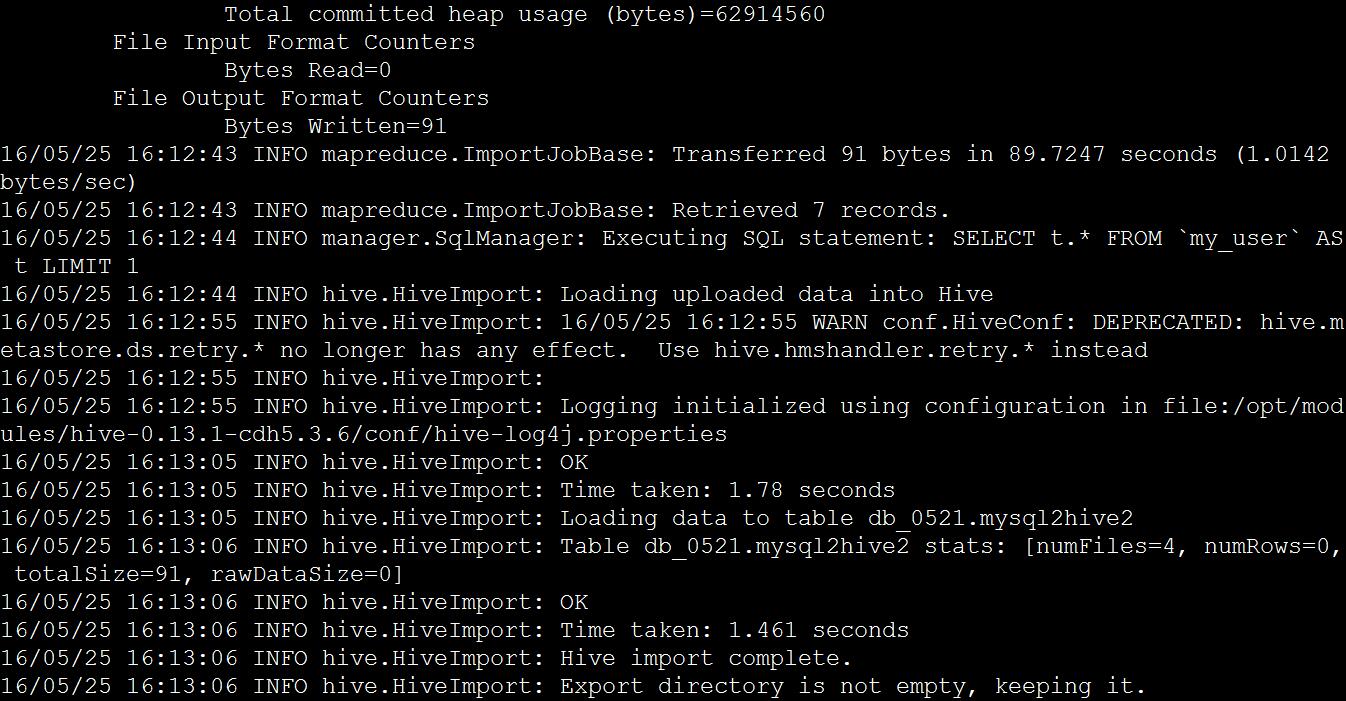
(3) 使用 SQOOP 把关系型数据库 mysql 数据导入 HDFS
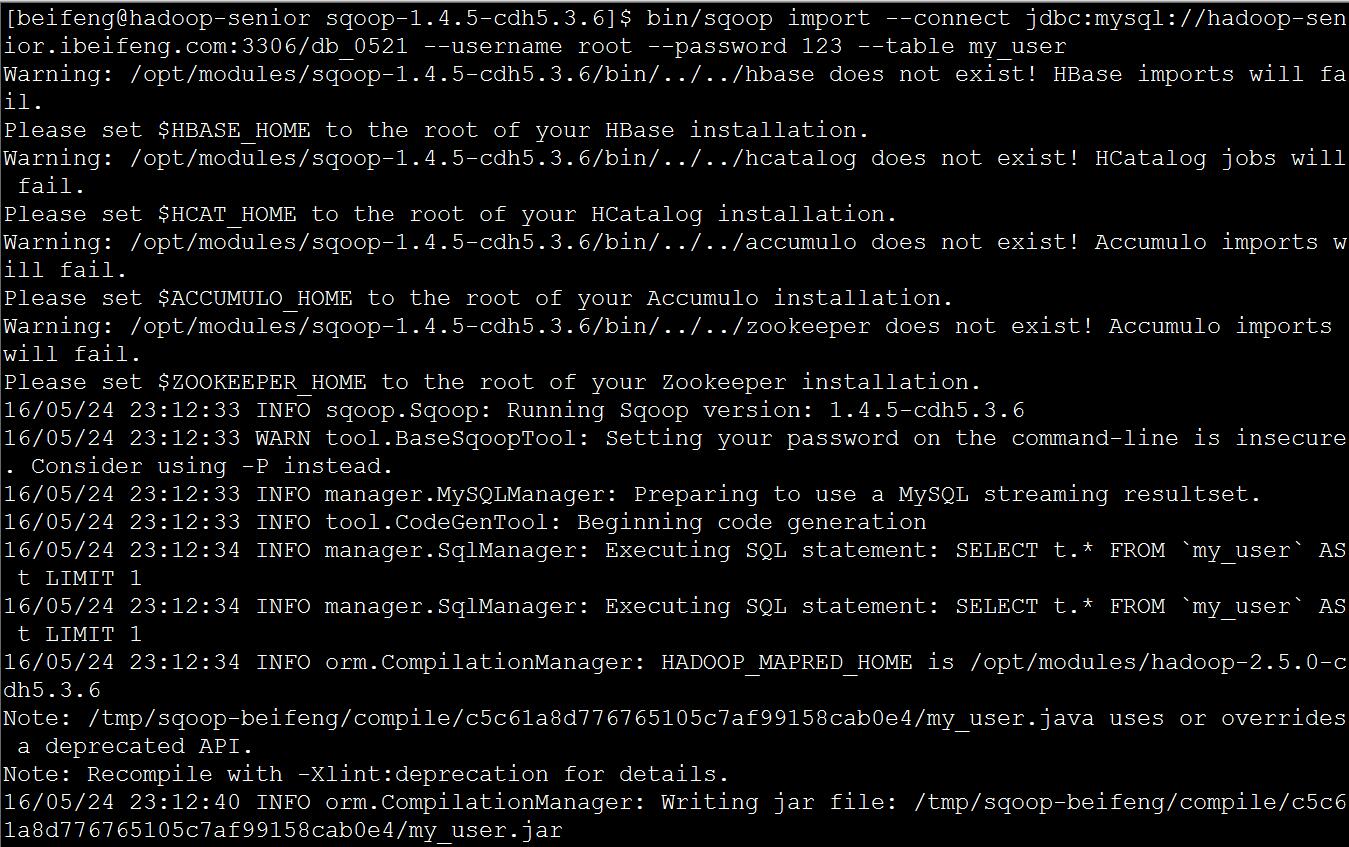
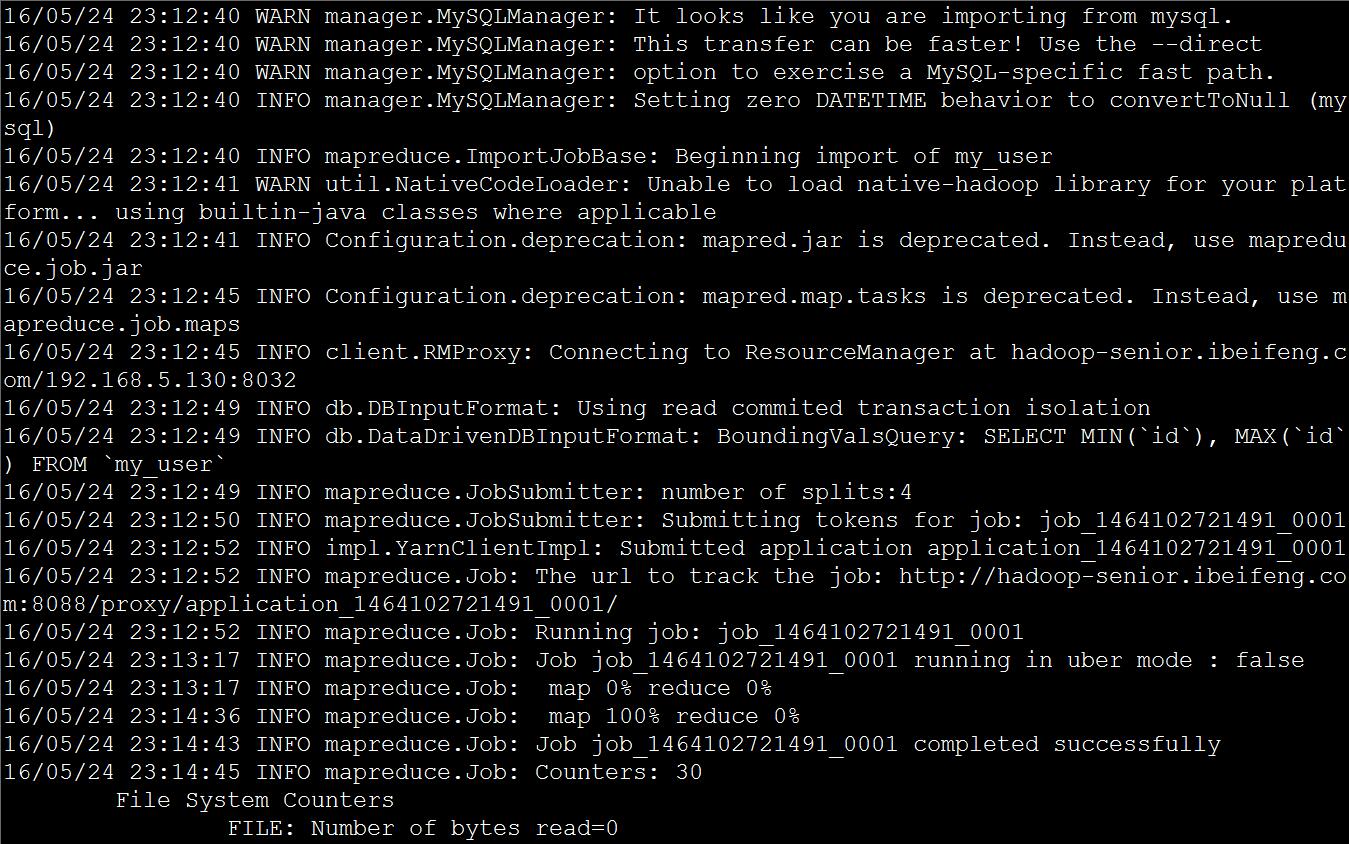
使用sqoop导入
bin/sqoop import \--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/db_0521 \--username root \--password 123 \--table my_user
注意:
不指定导入目录,默认情况是导入到hdfs上面用户家目录下面。
默认导入到HDFS里面,分隔符是,

注意:
不指定导入目录,默认情况是导入到hdfs上面用户家目录下面。
默认导入到HDFS里面,分隔符是,
参数解释
--target-dir /user/hive/warehouse/db_0521/ 指定HDFS中的存储路径
-m 1 指定maptask数量
--delete-target-dir 目标路径文件夹存在则删除,用于覆盖导入
--fields-terminated-by '\t' 指定导入分隔符
--direct 省略sqoop在RDBMS中的预览过程,使导入更快
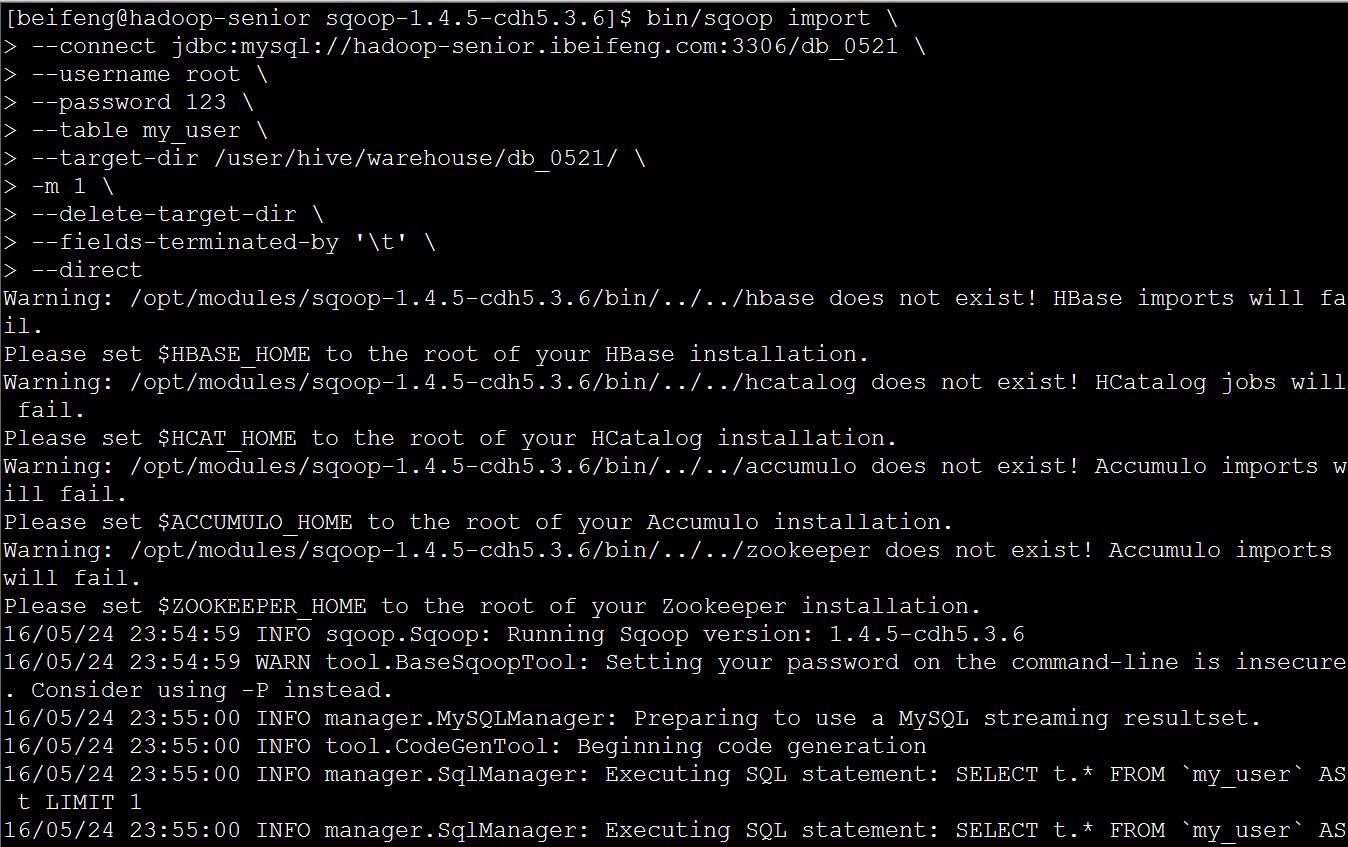
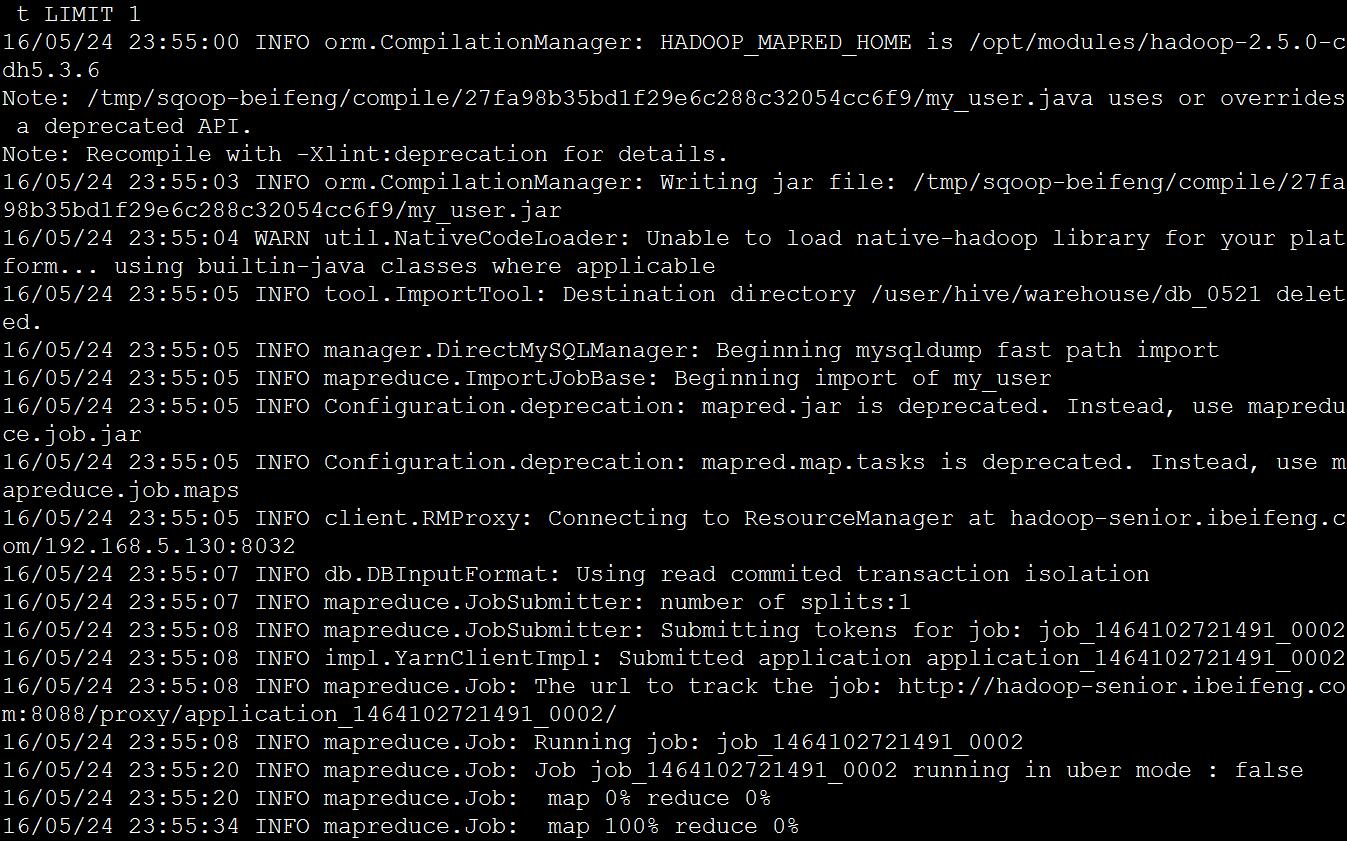
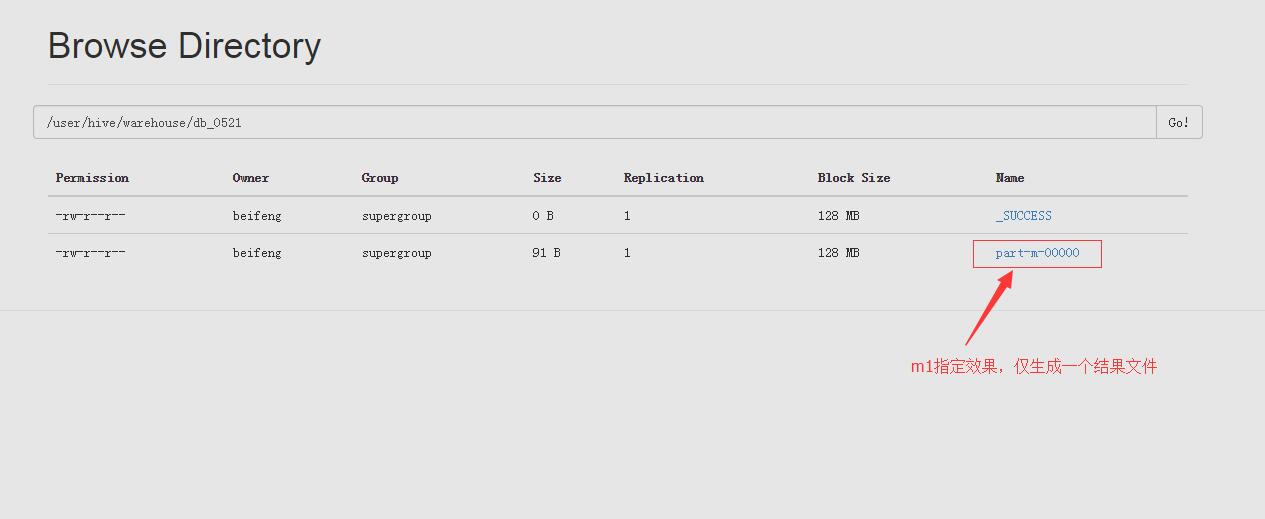
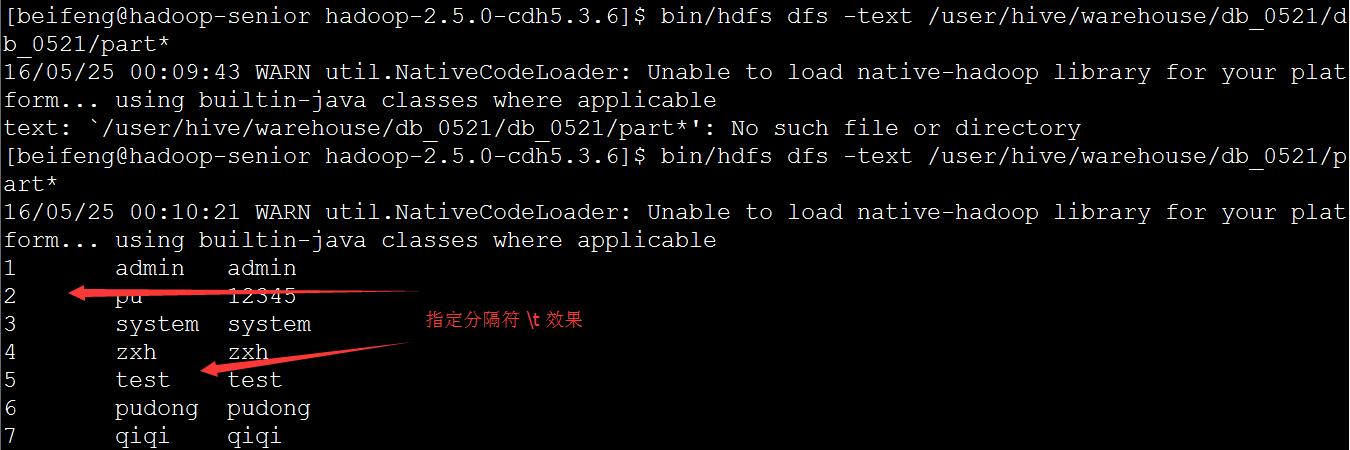
* mysql 数据增量导入HDFS
bin/sqoop import \--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/db_0521 \--username root \--password 123 \--table my_user \--target-dir /user/hive/warehouse/db_0521/ \-m 1 \--fields-terminated-by '\t' \--direct \--check-column id \--incremental append \--last-value 4
参数解释
--check-column id 根据指定增量字段导入
--incremental append 追加写入
--last-value 4 从增量字段值以后开始增量追加写入
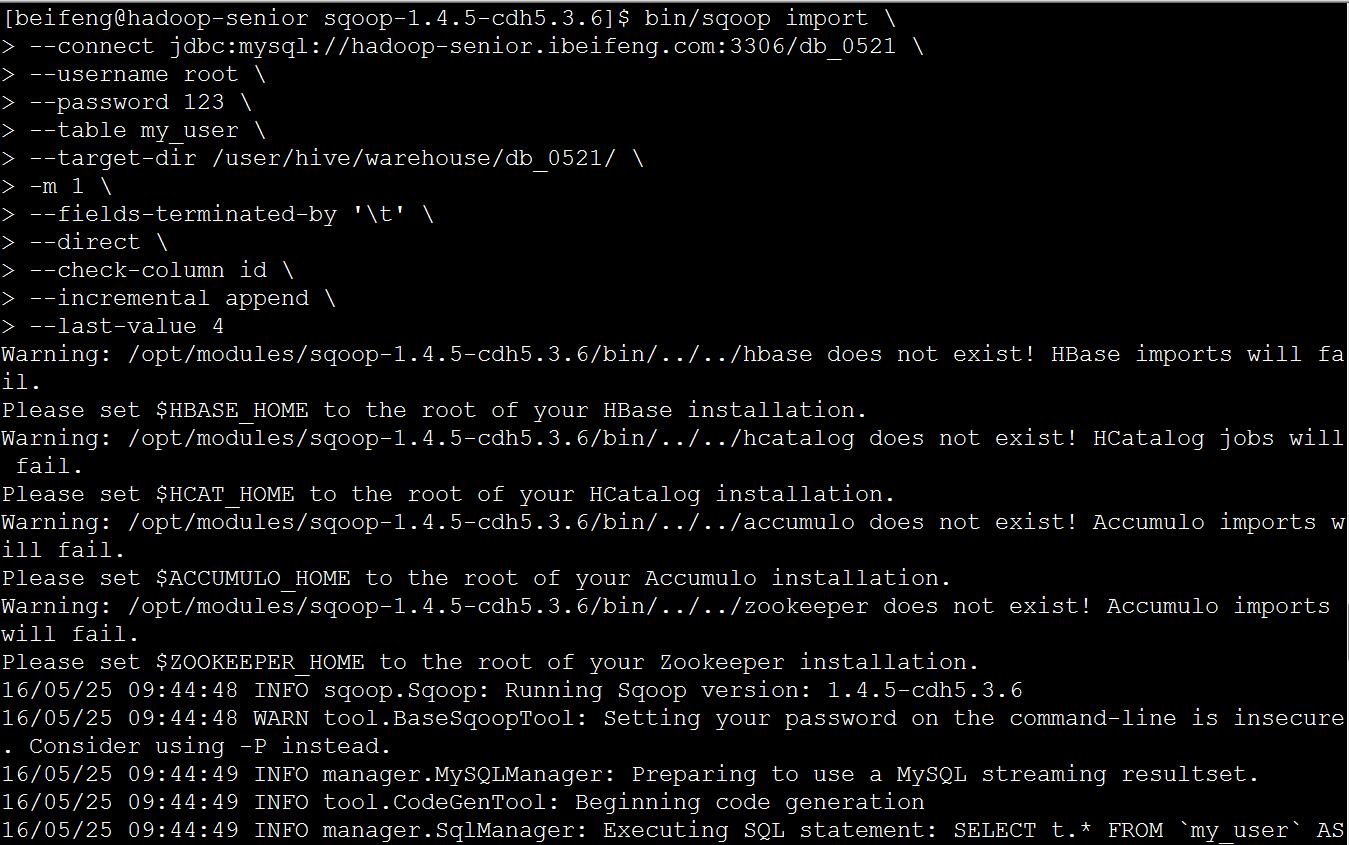
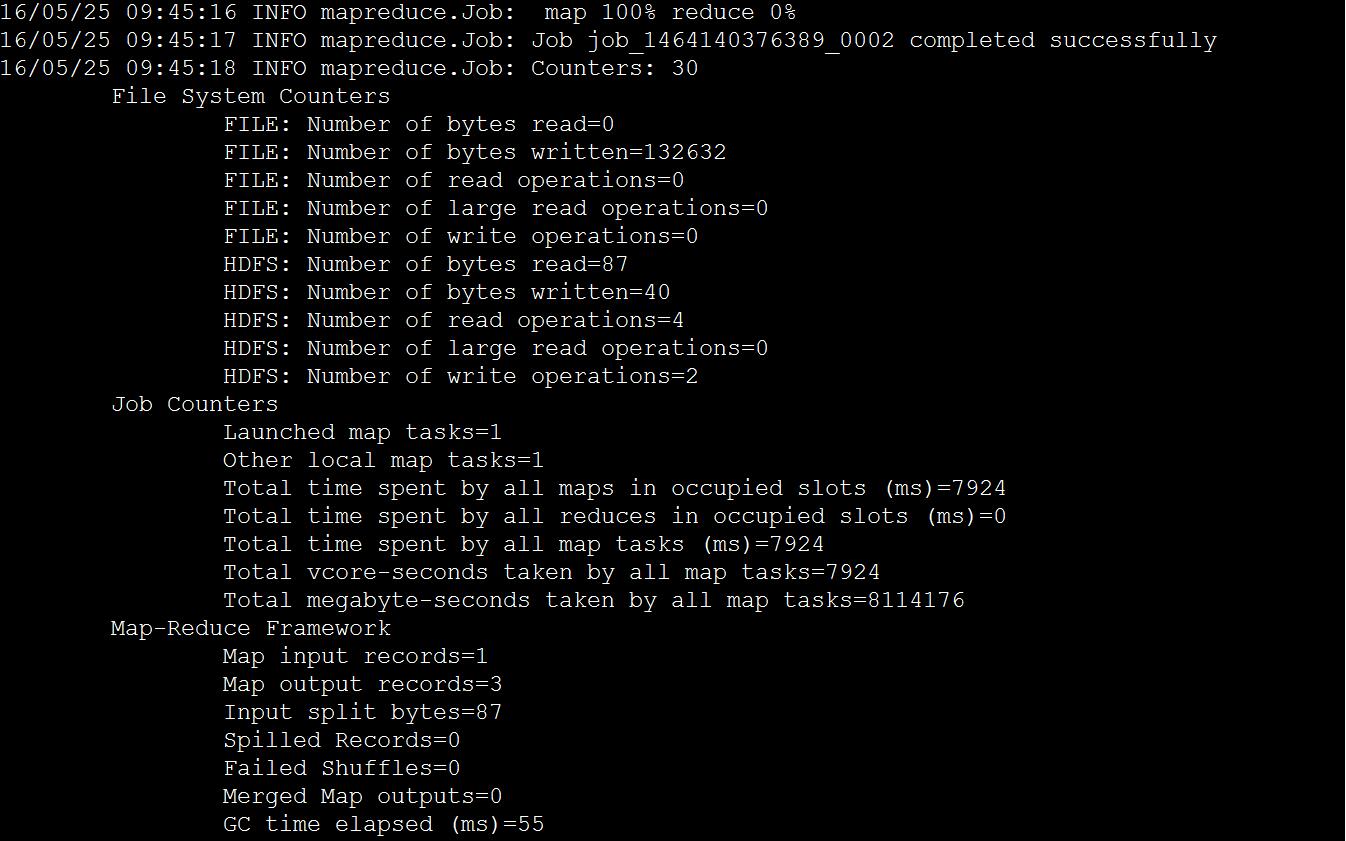
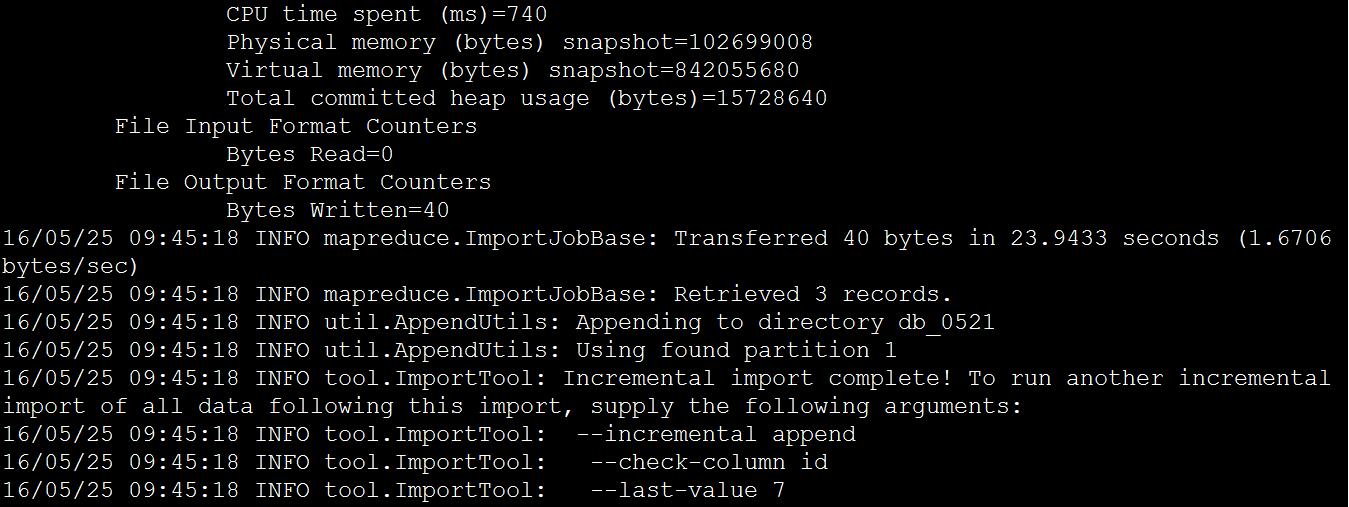
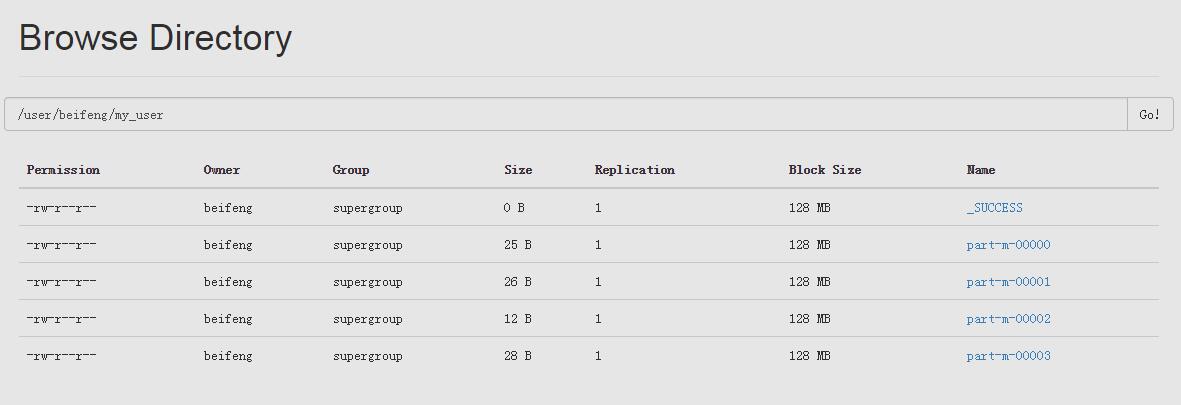
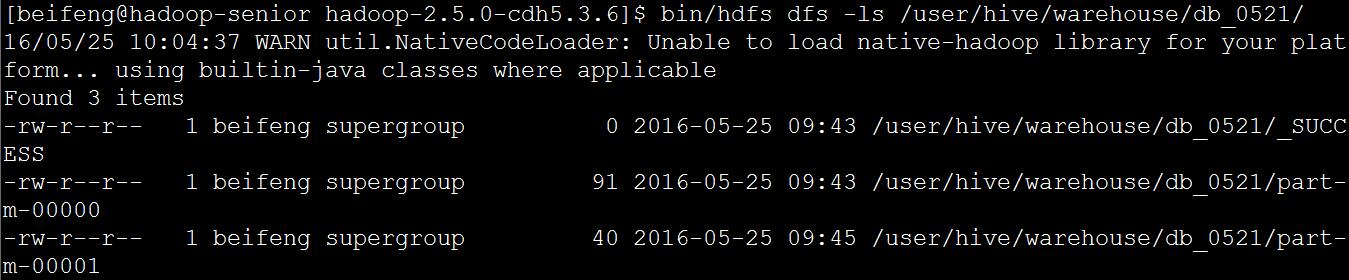
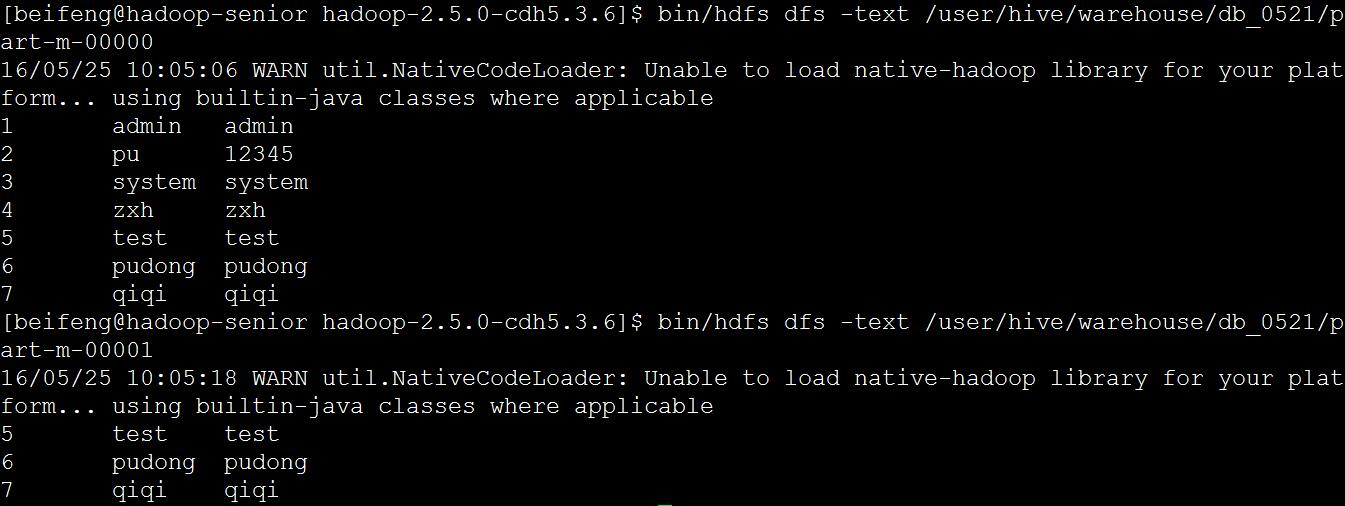
查看导入结果
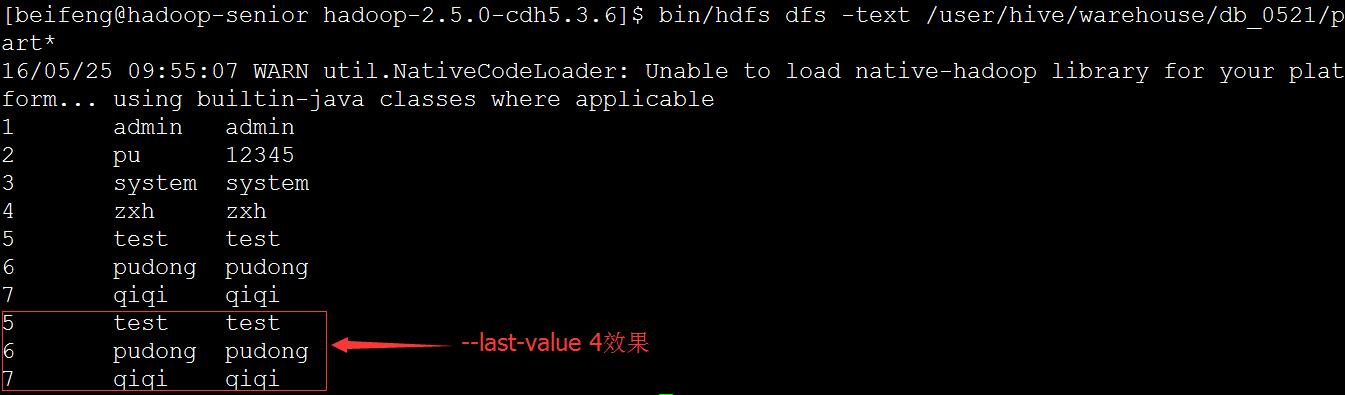
追加数据被写入另一文件 part-m-00001
(4) 使用 SQOOP 把 Hive 表数据导入关系型数据库 mysql;
步骤一:创建导出数据使用的空表
mysql> use db_0521;Reading table information for completion of table and column namesYou can turn off this feature to get a quicker startup with -ADatabase changedmysql> create table hdfs2mysql like my_user;Query OK, 0 rows affected (0.06 sec)mysql> desc hdfs2mysql;+---------+--------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+---------+--------------+------+-----+---------+----------------+| id | tinyint(4) | NO | PRI | NULL | auto_increment || account | varchar(255) | YES | | NULL | || passwd | varchar(255) | YES | | NULL | |+---------+--------------+------+-----+---------+----------------+3 rows in set (0.02 sec)mysql> select * from hdfs2mysql;Empty set (0.00 sec)
步骤二:把Hive表数据导入MySQL
bin/sqoop export \--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/db_0521 \--username root \--password 123 \--table hdfs2mysql \--export-dir /user/hive/warehouse/db_0521.db/mysql2hive2 \--input-fields-terminated-by '\t'
--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/db_0521 \
指定MySQL 连接方式:jdbc,连接地址,连接数据库
--table hdfs2mysql 指定导出数据表在MySQL中的表名称
--export-dir 指定导出数据在HDFS中的路径
bin/sqoop export \> --connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/db_0521 \> --username root \> --password 123 \> --table hdfs2mysql \> --export-dir /user/hive/warehouse/db_0521.db/mysql2hive2 \> --input-fields-terminated-by '\t'mysql> select * from hdfs2mysql;+----+---------+--------+| id | account | passwd |+----+---------+--------+| 1 | admin | admin || 2 | pu | 12345 || 3 | system | system || 4 | zxh | zxh || 5 | test | test || 6 | pudong | pudong || 7 | qiqi | qiqi |+----+---------+--------+7 rows in set (0.01 sec)
