@coder-pig
2018-08-26T08:14:39.000000Z
字数 4963
阅读 3355
小猪的Python学习之旅 —— 4.Scrapy爬虫框架初体验
Python
引言:
经过前面两节的学习,我们学会了使用urllib去模拟请求,使用
Beautiful Soup和正则表达式来处理网页以获取我们需要的数据。
对于经常重复用到的代码,我们都会单独抽取成自己的模块,
比如代理池模块:自动爬代理,校验代理ip是否可用,存取ip,
又或者文件下载等,手撕爬虫代码是挺爽的蛤!不过今天并不用
手撕爬虫,而是学习一个很出名的爬虫框架——Scrapy(西瓜皮)。
1.官方文档与简介
官方文档:https://docs.scrapy.org/en/latest/
简介:
Scrapy,谐音西瓜皮,Python开发的一个快速、高层次的屏幕抓取和
web抓取框架,用于抓取web站点并从页面中提取结构化的数据。
Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求
方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、
sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
2.Scrapy安装
- Window:
网上的安装教程都很繁琐,偶然间发现一种傻瓜式的,直接安装:Anaconda
选择对应的windows版本,然后傻瓜式下一步就可以了,安装完成后,
点击开始找到并打开:

键入下述命令进行安装
conda install scrapy
安装完成后,后面想执行Scrapy相关命令都可以在这里执行:

- Ubuntu:
系统与Python版本:Ubuntu 14.04 Python 3.4
sudo pip3 install Scrapy
中途出现一个错误:fatal error: 'Python.h' file not found
需要另外安装python-dev,该库中包含Python的头文件与静态库包,
要根据自己的Python版本进行安装:
sudo apt-get install python3.4-dev
- Mac:
系统与Python版本:OS 10.13.2 Python 3.6
pip install Scrapy
3.Scrapy框架的大概了解
Scrapy的架构图

各个模块的介绍:
Scrapy Engine(Scrapy引擎)
核心,负责控制数据流在系统中所有的组件中流动,
并在相应的动作发生时触发事件。Scheduler(调度器)
从引擎接受request并让其入队,以便之后引擎请求
它们时提供给引擎。Downloader(下载器)
获取页面数据并提供给引擎,而后提供给Spider。Spiders(蜘蛛...)
编写用于分析由下载器返回的response,并提取出item
和额外跟进的URL的类。Item Pipeline(项目管道)
负责处理处理被Spider提取出来的item。常见的处理有:
清理、验证和持久化。Download Middlewares(下载器中间件)
引擎与下载器间的特定钩子,处理下载器传递给引擎的Response。Spider Middlewares(Spider中间件)
引擎与Spider间的特定钩子,处理Spider输入(下载器的Response)和
输出(发送给items给Item Pipeline,以及发送Request给调度器)
执行流程
- Step 1:
引擎打开一个网站,找到处理该网站的Spider并向该Spider
请求第一个要爬取的URL; - Step 2:
引擎从Spider中获取到第一个要爬取的URL,并在Scheduler
以Request调度; - Step 3:
引擎向Scheduler请求下一个要爬取的URL; - Step 4:
Scheduler返回下一个要爬取的URL给引擎,引擎将URL通过
下载中间件(请求Request方向)转发给Downloader; - Step 5:一旦页面下载完成,
Downloader生成一个该页面的Response,
并将其通过下载中间件(返回response方向)发送给引擎; - Step 6:
引擎从Downloader中接收Response并通过Spider中间件
(输出方向)发送给Spider处理; - Step 7:
Spider处理Response并返回爬取到的Item及(跟进的新
的Request)给引擎; - Step 8:
引擎将(Spider返回的)爬取到的Item给Item Pipeline,
将(Spider返回的)Request给Scheduler; - Step 9:继续重复从Step2开始,直到
Scheduler里没有更多的Request,
然后引擎关闭该网站。
4.新建并了解Scrapy项目结构
执行下述命令可以生成一个Scrapy项目
scrapy startproject 项目名
新建的项目结构如下:
ScrapyStudy/scrapy.cfg # 项目的配置文件ScrapyStudy/ # 该项目的python模块,代码都加在里面__init__.pyitems.py # 项目中的item文件pipelines.py # 项目中pipelines文件settings.py # 项目的设置文件spiders/ # 方式spider代码的目录__init__.py
5.Scrapy使用初体验
1.编写Spider类爬取到网页
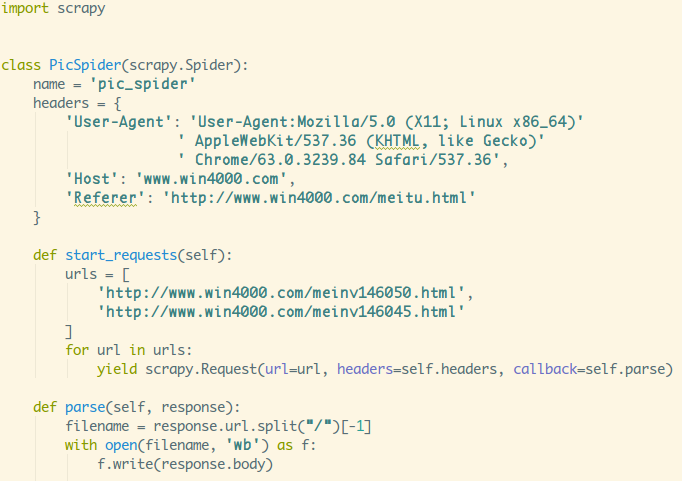
自定义Spider时,需 继承scrapy.Spider类,且必须有以下三个成员:
name:用于区分不同的Spider,名字要唯一!!!- parse(response):Spider的一个回调函数,当Downloader返回Response时会被调用,
每个初始URL完成下载后生成的response对象将会作为唯一的参数传递
给该函数。该函数负责解析返回的数据(response),提取数据(生成item)
以及生成需要进一步处理的URL的Request对象。 - start_requests():Spider刚启动时,生成需要爬去的链接,写这个
就不用写start_urls了。
使用示例:
命令行键入:scrapy crawl pic_spider 执行PicSpider,执行完成后可以
看到,Spider已经把这两个网站给扒下来了,厉害了:

2.取出网页中想要的信息
Scrapy中使用一种基于XPath和CSSDE表达式机制:Scrapy Selectors
来提取出网页中我们所需的数据。
Selector是一个选择,有四个基本方法:
- xpath():传入xpath表达式,返回该表达式对应的所有节点的selector list列表;
- css():传入CSS表达式,返回该表达式对应的所有及诶点的selector list列表;
- extract():序列化该节点为unicode字符串并返回list;
- re():根据传入的正则表达式对数据进行提取,返回unicode字符串list列表;
这里顺道学下XPath的基本语法:(更多可见:http://www.w3school.com.cn/xpath/)
首先XPath中的路径分为绝对路径与相对路径:
绝对路径:用/,表示从根节点开始选取;
相对路径:用//,表示选择任意位置的节点,而不考虑他们的位置;
另外可以使用*通配符来表示未知的元素;除此之外还有两个选取节点的:
.:选取当前节点;..:当前节点的父节点;
接着就是选择分支进行定位了,比如存在多个元素,想唯一定位,
可以使用[]中括号来选择分支,下标是从1开始算的哦!
比如可以有下面这些玩法:
/tr/td[1]:取第一个td/tr/td[last()]:取最后一个td/tr/td[last()-1]:取倒数第二个td/tr/td[position()<3]:取第一个和第二个td/tr/td[@class]:选取拥有class属性的td/tr/td[@class='xxx']:选取拥有class属性为xxx的td/tr/td[count>10]:选取 price 元素的值大于10的td
然后是选择属性,其实就是上面的这个@
可以使用多个属性定位,可以这样写:/tr/td[@class='xxx'][@value='yyy']
或者/tr/td[@class='xxx' and @value='yyy']
再接着是常用函数:除了上面的last(),position(),外还有:
contains(string1,string2):如果前后匹配返回True,不匹配返回False;
text():获取元素的文本内容
start-with():从起始位置匹配字符串
更多的自己去翻文档吧~
最后是轴,当上面的操作都不能定位时,这个时候可以考虑根据元素
的父辈节点或者兄弟节点来定位了,这个时候就会用到Xpath轴,
利用轴可定位某个相对于当前节点的节点集,语法:轴名称::标签名
规则列表如下:
| 轴名称 | 作用 |
|---|---|
| ancestor | 选取当前节点的所有先辈(父、祖父等)。 |
| ancestor-or-self | 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 |
| attribute | 选取当前节点的所有属性。 |
| child | 选取当前节点的所有子元素。 |
| descendant | 选取当前节点的所有后代元素(子、孙等)。 |
| descendant-or-self | 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 |
| following | 选取文档中当前节点的结束标签之后的所有节点。 |
| following-sibling | 选取当前节点之后的所有兄弟节点 |
| namespace | 选取当前节点的所有命名空间节点。 |
| parent | 选取当前节点的父节点。 |
| preceding | 选取文档中当前节点的开始标签之前的所有节点。 |
| preceding-sibling | 选取当前节点之前的所有同级节点。 |
| self | 选取当前节点。 |
大概规则了解到这里,接下来就用Xpath来获取我们想要的东西~
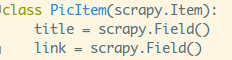
在开始解析之前我们还要写一个Item,就是拿来装我们爬取筛选
过后数据的容器,使用方法和Python中的字典类似,并且提供了
额外的保护机制来避免因拼写错误导致的未定义字段错误。
打开项目中的items.py文件进行编辑,比如我这里只需要两个
字段,图片的标题以及链接:
编写完后着手来修改我们的PicSpider类,选用的网址是:
http://www.win4000.com/meitu.html
F12看下网页结构,圈住的就是我们的入手点和想要获取的数据了:
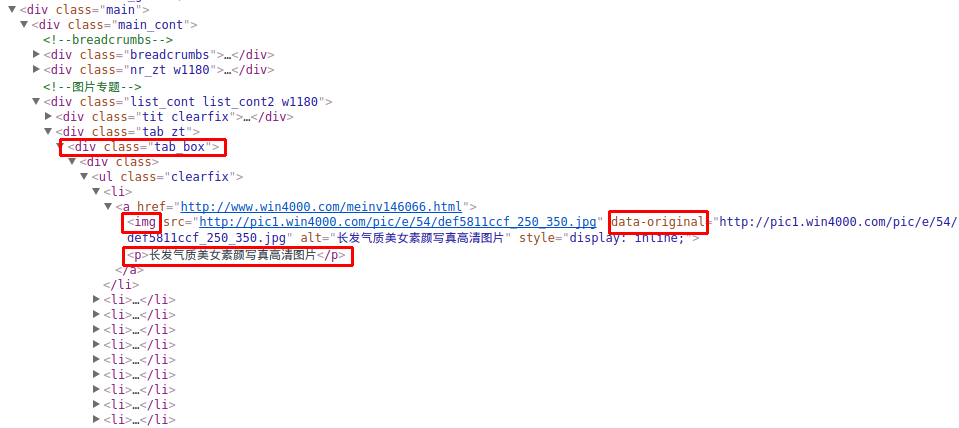
从tab_box开始一层层定位到我们想要的地方,不难写出下面的代码:

3.存储数据
得到我们的结果啦,最简单的存储数据的方式就是使用Feed exports,
支持四种导出格式:JSON,JSON lines,XML和CSV
使用也很简单,只是在平时执行scrapy脚本的后面加点东西:
scrapy crawl spider名字 -o 导出文件名 -t 导出格式
比如我这里导出xml:

输出结果:

4.下载图片
图片URL都有了,接下来肯定是把图片都download到本地啦~
这里就可以直接使用Scrapy中内置的ImagePipeline啦!
我们另外实现ImagePipeline,做下url校验,已经图片生成规则,
把图片下载到我们想下载的地方,编辑下pipelines.py,新增:

然后settings.py,找到ITEM_PIPELINES把注释去掉,启用pinelines,
把我们自定义的PicPipeLine加上,还有顺道设置下下载图片的存放位置:

接着命令行运行我们的spider
scrapy crawl pic_spider
图片都哗哗哗地下载到本地了:
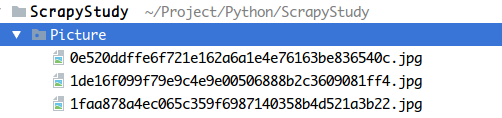
嘻嘻,略爽,比起之前那种手写的方式~
6.小结
本节对Python里很出名的爬虫框架Scrapy进行了初步的学习
后面还会更深入地去了解Scrapy,这里先放一放。下一节我们
学习的是通过自动化测试框架Selenium来爬取使用JS动态生成
数据的场景,敬请期待~

参考文献:
来啊,Py交易啊
想加群一起学习Py的可以加下,智障机器人小Pig,验证信息里包含:
Python,python,py,Py,加群,交易,屁眼 中的一个关键词即可通过;

验证通过后回复 加群 即可获得加群链接(不要把机器人玩坏了!!!)~~~
欢迎各种像我一样的Py初学者,Py大神加入,一起愉快地交流学♂习,van♂转py。

